

One of the trickier things in software is gradual degradation. Development that happens in the wrong direction slowly over time which never triggers any alarms or upset users. Then one day you suddenly take a closer look at it and you realize that this area that used to be so fine several years ago no longer is.
Memory use is one of those things. It is easy to gradually add more and larger allocations over time as we add features and make new cool architectural designs.
Memory use
curl and libcurl literally run in billions of installations and it is important for us that we keep memory use and allocation count to a minimum. It needs to run on small machines and it needs to be able to scale to large number of parallel connections without draining available resources.
So yes, even in 2026 it is important to keep allocations small and as few as possible.
A line in the sand
In July 2025 we added a test case to curl’s test suite (3214) that simply checks the sizes of fifteen important structs. Each struct has a fixed upper limit which they may not surpass without causing the test to fail.
Of course we can adjust the limits when we need to, as it might be entirely okay to grow them when the features and functionalities motivate that, but this check makes sure that we do not mistakenly grow the sizes simply because of a mistake or bad planning.
Do we degrade?
It’s of course a question of a balance. How much memory is a feature and added performance worth? Every libcurl user probably has their own answers to that but I decided to take a look at how we do today, and compare with data I blogged five years ago.
The point in time I decided to compare with here, curl 7.75.0, is fun to use because it was a point in time where I had given the size use in curl some focused effort and minimization work. libcurl memory use was then made smaller and more optimized than it had been for almost a decade before that.
struct sizes
The struct sizes always vary depending on which features that are enabled, but in my tests here they are “maximized”, with as many features and backends enabled as possible.
Let’s take a look at three important structs. The multi handle, the easy handle and the connectdata struct. Now compared to then, five years ago.
| 8.19.0-DEV (now) | 7.75.0 (past) | |
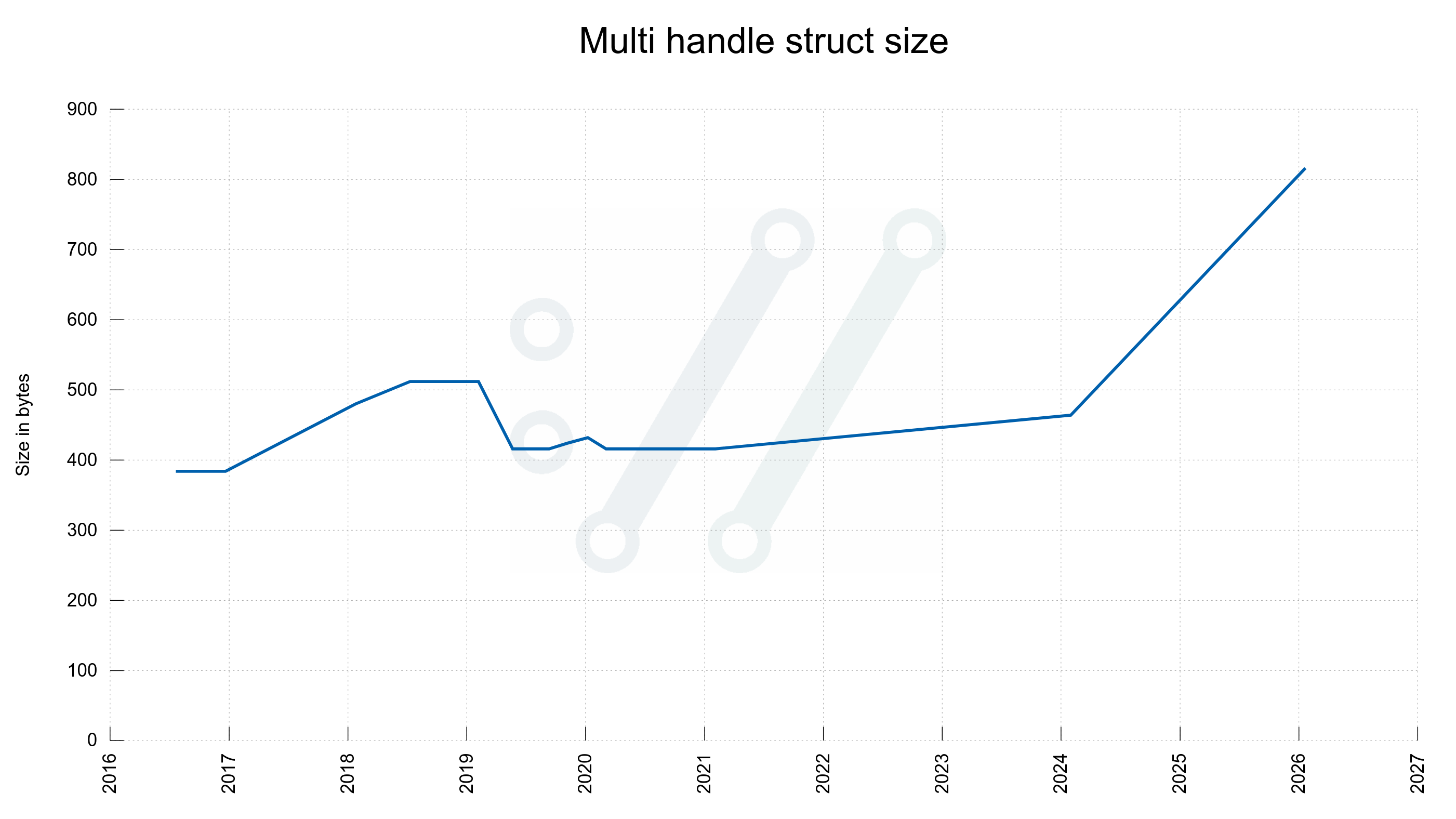
| multi | 816 | 416 |
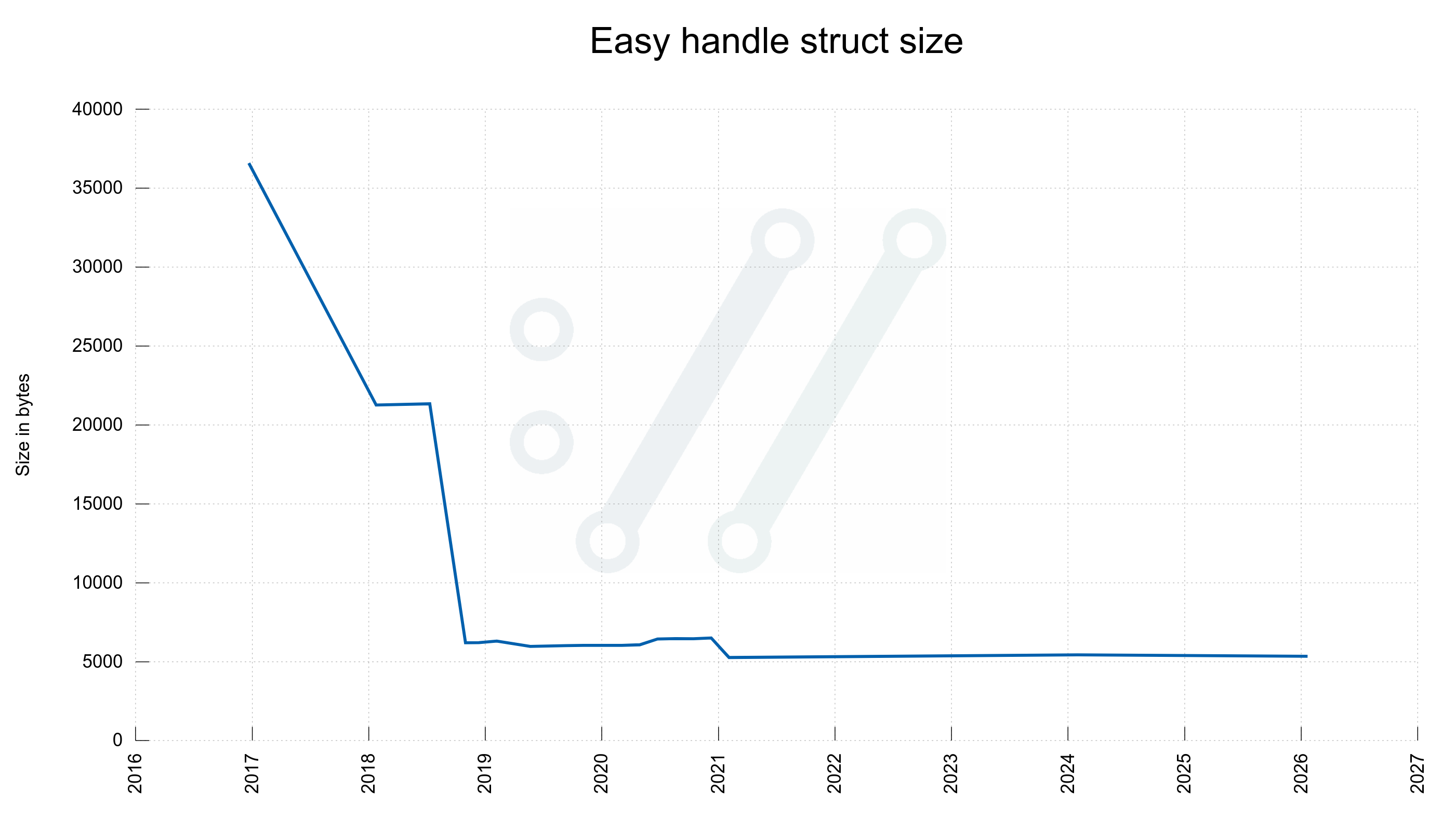
| easy | 5352 | 5272 |
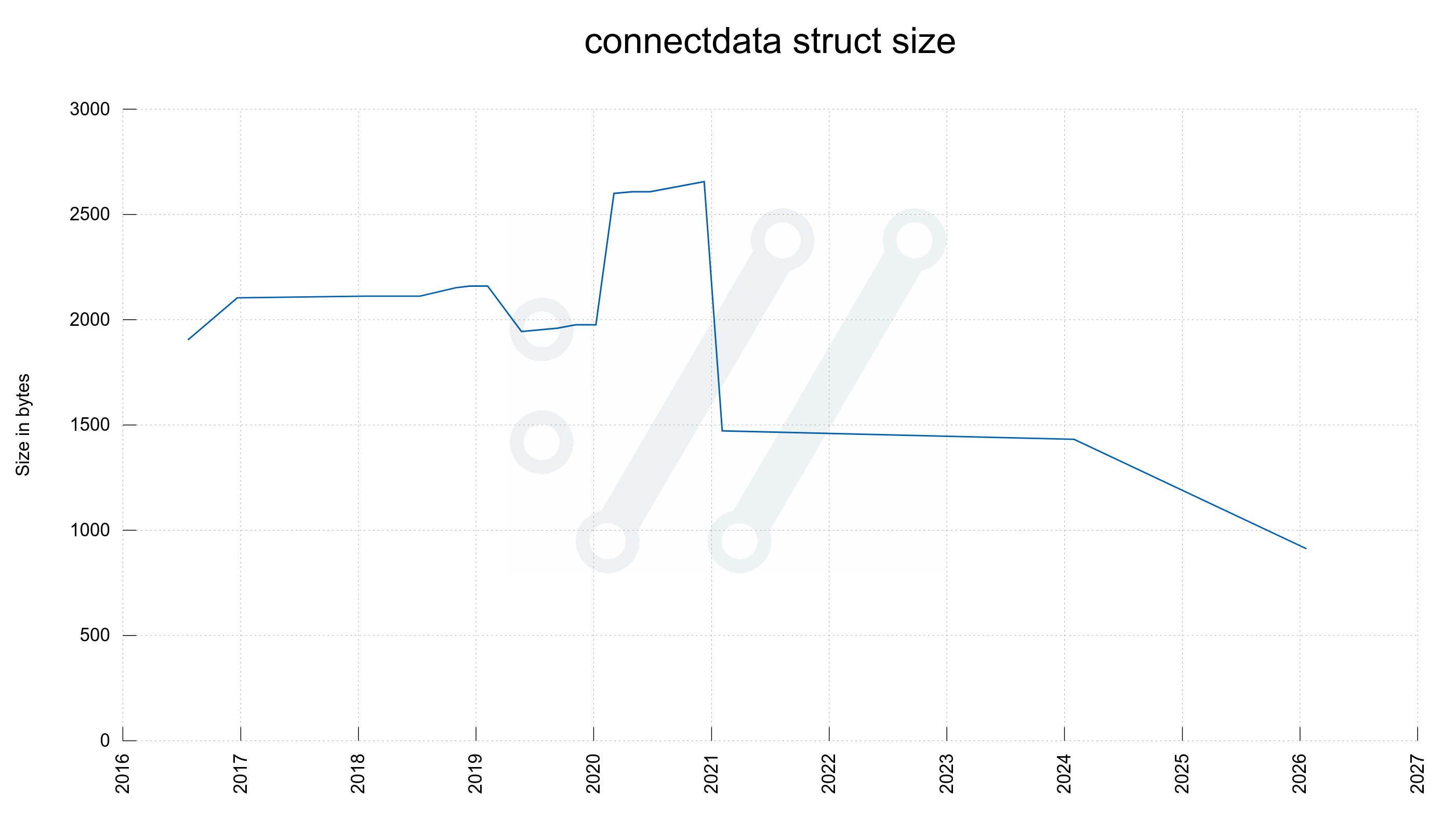
| connectdata | 912 | 1472 |
As seen in the table, two of the structs have grown and one has shrunken. Let’s see what impact that might have.
If we assume a libcurl-using application doing 10 parallel transfers that have 20 concurrent connections open, libcurl five ago needed:
1472 x 20 + 5272 x 10 + 416 = 82,576 bytes for that
While libcurl in current git needs:
912 x 20 + 5352 x 10 + 816 = 72,576 bytes.
Incidentally that is exactly 10,000 bytes less, five years and many new features later.
This said, part of the reason the structs change is that we move data between them and to other structs. The few mentioned here are not the whole picture.
Downloading a single HTTP 512MB file
curl http://localhost/512M --out-null
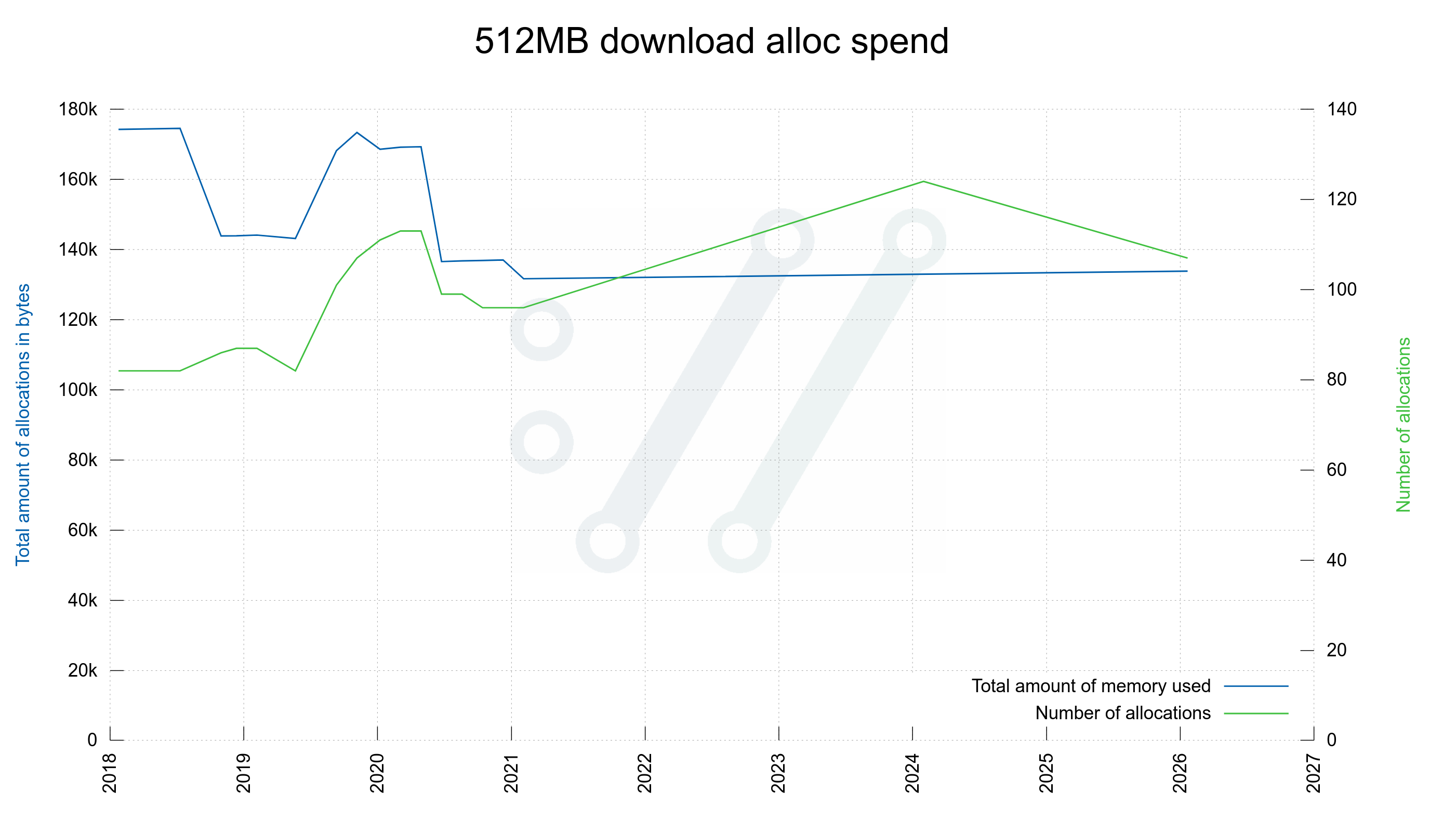
Using a bleeding edge curl build, this command line on my 64 bit Linux Debian host does 107 allocations, that needs at its maximum 133,856 bytes.
Compared to five years ago, where it needed 131,680 bytes done in a mere 96 allocations.
curl now needs 1.6% more memory for this, done with 11% more allocation calls.
I believe the current amounts are still okay considering we have refactored, developed and evolved the library significantly over the same period.
As a comparison, downloading the same file twenty times in parallel over HTTP/1 using the same curl build needs 2,222 allocations but only a total of 308,613 bytes allocated at peak. Twenty times the number of allocations but only three times the maximum size, compared to the single file download.
Caveat: this measures clear text HTTP downloads. Almost everything transferred these days is using TLS and if you add TLS to this transfer, curl itself does only a few additional allocations but more importantly the TLS library involved allocates much more memory and do many more allocations. I just consider those allocations to be someone else’s optimization work.
Visualized
I generated a few graphs that illustrate memory use changes in curl over time based on what I described above.
The “easy handle” is the handle an application creates and that is associated which each individual transfer done with libcurl.
The “multi handle” is a handle that holds one or more easy handles. An application has at least one of these and adds many easy handles to it, or the easy handles has one of its own internally.
The “connectdata” is an internal struct for each existing connection libcurl knows about. A normal application that makes multiple transfers, either serially or in parallel tends to make the easy handle hold at least a few of these since libcurl uses a connection pool by default to use for subsequent transfers.
Here is data from the internal tracking of memory allocations done when the curl tool is invoked to download a 512 megabyte file from a locally hosted HTTP server. (Generally speaking though, downloading a larger size does not use more memory.)
Conclusion
I think we are doing alright and none of these struct sizes or memory use have gone bad. We offer more features and better performance than ever, but keep memory spend at a minimum.
Your table reads “7.19.0-DEV” but presumably should read “8.19.0-DEV”
@David (and others): yes, the table had the wrong header for one of the columns and that is now fixed. Thanks!
In the table above that compares versions, did you mean to compare 7.75.0 to version 7.19.0-DEV or 8.19.0-DEV?
I love the fact that you’ve integrated memory usage measurement in your tests! Great way to fight Wirth’s Law 🙂 and planned obsolescence. See https://en.wikipedia.org/wiki/Wirth%27s_law .
If only other software engineers would do the same, we’d renew a lot less our hardware and massively reduce IT’s environmental footprint (it’s what I’m working on these days). Happy to talk about it if you want!