

I have this tradition of mentioning occasional network related quirks on Windows on my blog so here we go again.
This round started with a bug report that said
curl is slow to connect to localhost on Windows
It is also demonstrably true. The person runs a web service on a local IPv4 port (and nothing on the IPv6 port), and it takes over 200 milliseconds to connect to it. You would expect it to take no less than a number of microseconds, as it does on just about all other systems out there.
The command
curl http://localhost:4567
Connecting
Buckle up, this is getting worse. But first, let’s take a look at this exact use case and what happens.
The hostname localhost first resolves to ::1 and 127.0.0.1 by curl. curl actually resolves this name “hardcoded”, so it does this extremely fast. Hardcoded meaning that it does not actually use DNS or any resolver functionality. It provides this result “fixed” for this hostname.
When curl has both IPv6 and IPv4 addresses to connect to and the host supports both IP families, it will first start the IPv6 attempt(s) and only if it did not succeed to connect over IPv6 after two hundred millisecond does it start the IPv4 attempts. This way of connecting is called Happy Eyeballs and is the de-facto and recommended way to connect to servers in a dual-stack since years back.
On all systems except Windows, where the IPv6 TCP connect attempt sends a SYN to a TCP port where nothing is listening, it gets a RST back immediately and returns failure. ECONNREFUSED is the most likely outcome of that.
On all systems except Windows, curl then immediately switches over to the IPv4 connect attempt instead that in modern systems succeeds within a small fraction of a millisecond. The failed IPv6 attempt is not noticeable to a user.
A TCP reminder
This is how a working TCP connect can be visualized like:
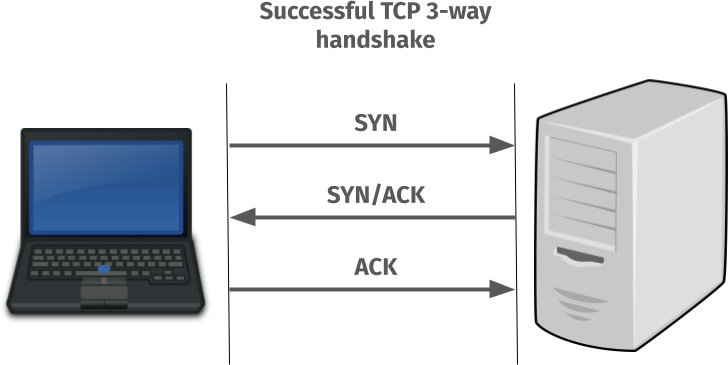
But when the TCP port in the server has no listener it actually performs like this
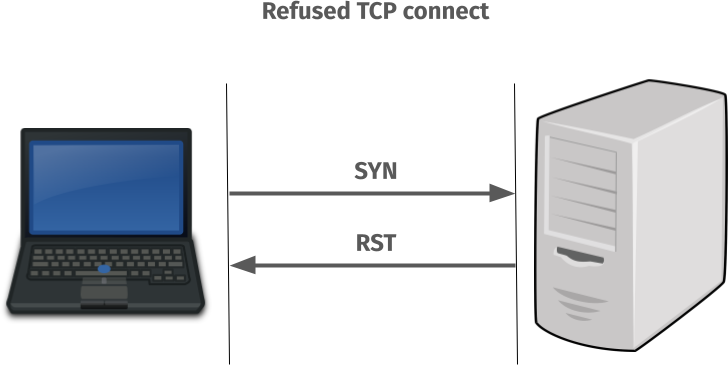
Connect failures on Windows
On Windows however, the story is different.
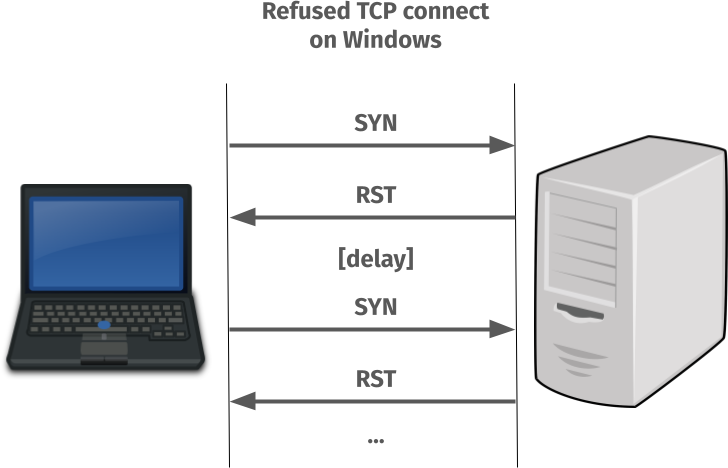
When the TCP SYN is sent to the port where nothing is listening and an RST is sent back to tell the client so, the client TCP stack does not return an error immediately.
Instead it decides that maybe the problem is transient and it will magically fix itself in the near future. It then waits a little and then keeps sending new SYN packets to see if the problem perhaps has fixed itself – until a maximum retry value is reached (set in the registry, this value defaults to 3 extra times).
Done on localhost, this retry-SYN process can easily take a few seconds and when done over a network, it can take even more seconds.
Since this behavior makes the leading IPv6 attempt not possible to fail within 200 milliseconds even when nothing is listening on that port, connecting to any service that is IPv4-only but has an IPv6 address by default delays curl’s connect success by two hundred milliseconds. On Windows.
Of course this does not only hurt curl. This is likely to delay connect attempts for countless applications and services for Windows users.
Non-responding is different
I want to emphasize that there is a big difference when trying to connect to a host where the SYN packet is simply not answered. When the server is not responding. Because then it could be a case of the packet gotten lost on the way so then the TCP stack has to resend the SYN again a couple of times (after a delay) to see if it maybe works this time.
IPv4 and IPv6 alike
I want to stress that this is not an issue tied to IPv6 or IPv4. The TCP stack seems to treat connect attempts done over either exactly the same. The reason I even mention the IP versions is because how this behavior works counter to Happy Eyeballs in the case where nothing listens to the IPv6 port.
Is resending SYN after RST “right” ?
According to this exhaustive resource I found on explaining this Windows TCP behavior, this is not in violation of RFC 793. One of the early TCP specifications from 1981.
It is surprising to users because no one else does it like this. I have not found any other systems or TCP stacks that behave this way.
Fixing?
There is no way for curl to figure out that this happens under the hood so we cannot just adjust the code to error out early on Windows as it does everywhere else.
Workarounds
There is a registry key in Windows called TcpMaxConnectRetransmissions that apparently can be tweaked to change this behavior. Of course it changes this for all applications so it is probably not wise to do this without a lot of extra verification that nothing breaks.
The two hundred millisecond Happy Eyeballs delay that curl exhibits can be mitigated by forcibly setting –happy-eyballs-timeout-ms to zero.
If you know the service is not using IPv6, you can tell curl to connect using IPv4 only, which then avoids trying and wasting time on the IPv6 sinkhole: –ipv4.
Without changing the registry and trying to connect to any random server out there where nothing is listening to the requested port, there is no decent workaround. You just have to accept that where other systems can return failure within a few milliseconds, Windows can waste multiple seconds.
Windows version
This behavior has been verified quite recently on modern Windows versions.
Thank you Daniel for documenting this, I think I am done with today’s goal of – learning something new today.
The idea that an RST (Reset) packet might indicate a transient issue is indeed puzzling and not aligned with typical TCP behavior. In standard TCP/IP networking, an RST packet is a definitive indication that the connection attempt has been rejected because the port is closed or the service is unavailable. It’s a clear signal that further attempts to establish the connection should cease immediately.
The behavior described in the post, where Windows retries the SYN packets after receiving an RST, is unusual and contrary to the standard interpretation of TCP signals. This is why it stands out as an anomaly in Windows compared to other operating systems.
In typical scenarios, an RST from the peer is not considered a transient issue because it’s a deliberate response indicating that the connection should not be established. A transient issue, on the other hand, might be indicated by timeouts or network congestion, not by an explicit rejection from the peer.
Modern TCP behavior, which is widely implemented in most operating systems today, adheres to the principle that an RST (Reset) packet is a final and conclusive indication that the connection attempt has been rejected. The key points of modern TCP behavior regarding RST are:
1. Immediate Response to RST: Upon receiving an RST, the TCP stack should immediately cease attempting to connect and should return an error to the application, typically indicating that the connection was refused (e.g., ECONNREFUSED).
2. No Retries on RST: The TCP stack does not retry the connection after receiving an RST because it’s understood as a definitive signal that the destination is not accepting connections on the specified port.
3. Fast Failover in Dual-Stack Environments: In dual-stack (IPv4/IPv6) environments, modern implementations use techniques like “Happy Eyeballs” (RFC 8305) to quickly switch between IPv4 and IPv6 based on connection success. If an RST is received on one protocol, the stack typically tries the other protocol immediately, without delay.
Relevant RFCs:
1. RFC 1122 – “Requirements for Internet Hosts – Communication Layers”:
• This document, published in 1989, provides comprehensive guidelines for how TCP/IP should be implemented. It clarifies that an RST is a definitive error indicating that the peer has rejected the connection. The relevant section states:
• “RST is sent whenever a segment arrives which apparently is not intended for the current connection. This may be caused by a mistake in addressing or a failure in the network; it is also used to reject SYN segments when the port is not available.”
• Essentially, RFC 1122 reinforces that an RST should be taken as a clear signal to stop the connection attempt.
2. RFC 793 – “Transmission Control Protocol”:
• This original TCP specification from 1981 outlines the fundamental behavior of TCP, including the use of RST. While it allows for some flexibility in implementations, modern interpretations generally treat an RST as a hard stop to connection attempts.
3. RFC 5961 – “Improving TCP’s Robustness to Blind In-Window Attacks”:
• This RFC, published in 2010, updates some security aspects of TCP, including the handling of RSTs, to prevent certain types of attacks. It reinforces the importance of treating RST as an authoritative signal to terminate a connection.
4. RFC 8305 – “Happy Eyeballs Version 2: Better Connectivity Using Concurrency”:
• This document, published in 2018, describes best practices for handling connections in dual-stack environments. It emphasizes quick fallbacks and minimizing delays when switching between IPv4 and IPv6, which indirectly supports the idea that RST should not cause unnecessary delays.
Conclusion:
The modern approach to TCP connection handling treats an RST as an immediate and final indication that the connection cannot be established, with no retries. This behavior is outlined in several RFCs, particularly RFC 1122 and RFC 793, with modern practices for dual-stack connectivity further elaborated in RFC 8305. The behavior observed on Windows, as described in the post, deviates from these modern expectations and is not aligned with the recommended handling of RSTs.
That’s a very strange behavior from them. I hope at least they’re using a new source port when retrying so as not to indefinitely match a connection in a bad state or a blocking rule.