This is a story consisting of several little building blocks and they occurred spread out in time and in different places. It is a story that shows with clarity how our current system with CVE Ids and lots of power given to NVD is a completely broken system.
CVE-2020-19909
On August 25 2023, we got an email to the curl-library mailing list from Samuel Henrique that informed us that “someone” had recently created a CVE, a security vulnerability identification number and report really, for a curl problem.
I wanted to let you know that there's a recent curl CVE published and it doesn't look like it was acknowledged by the curl authors since it's not mentioned in the curl website: CVE-2020-19909
We can’t tell who filed it. We just know that it is now there.
We own our curl issues
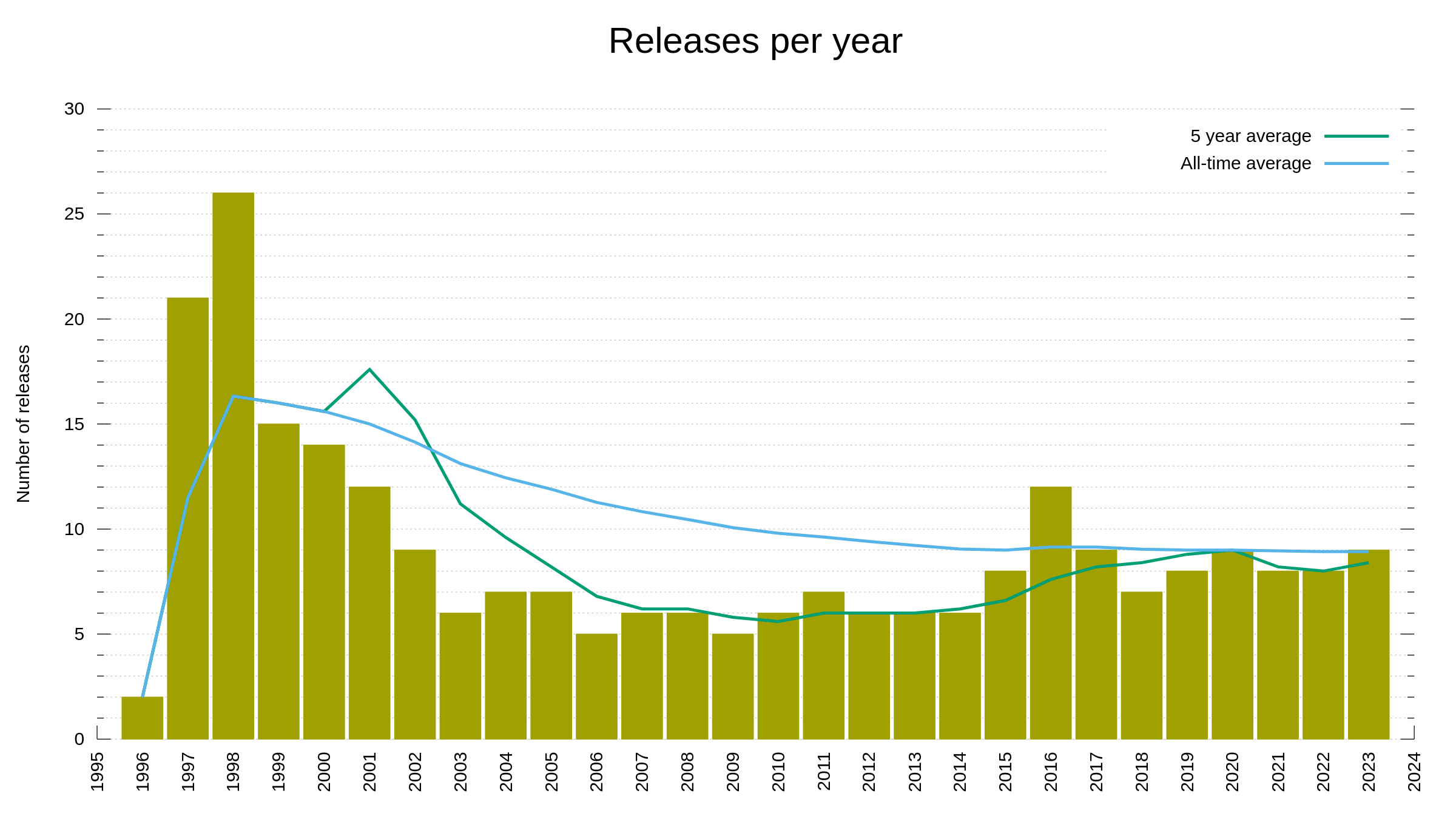
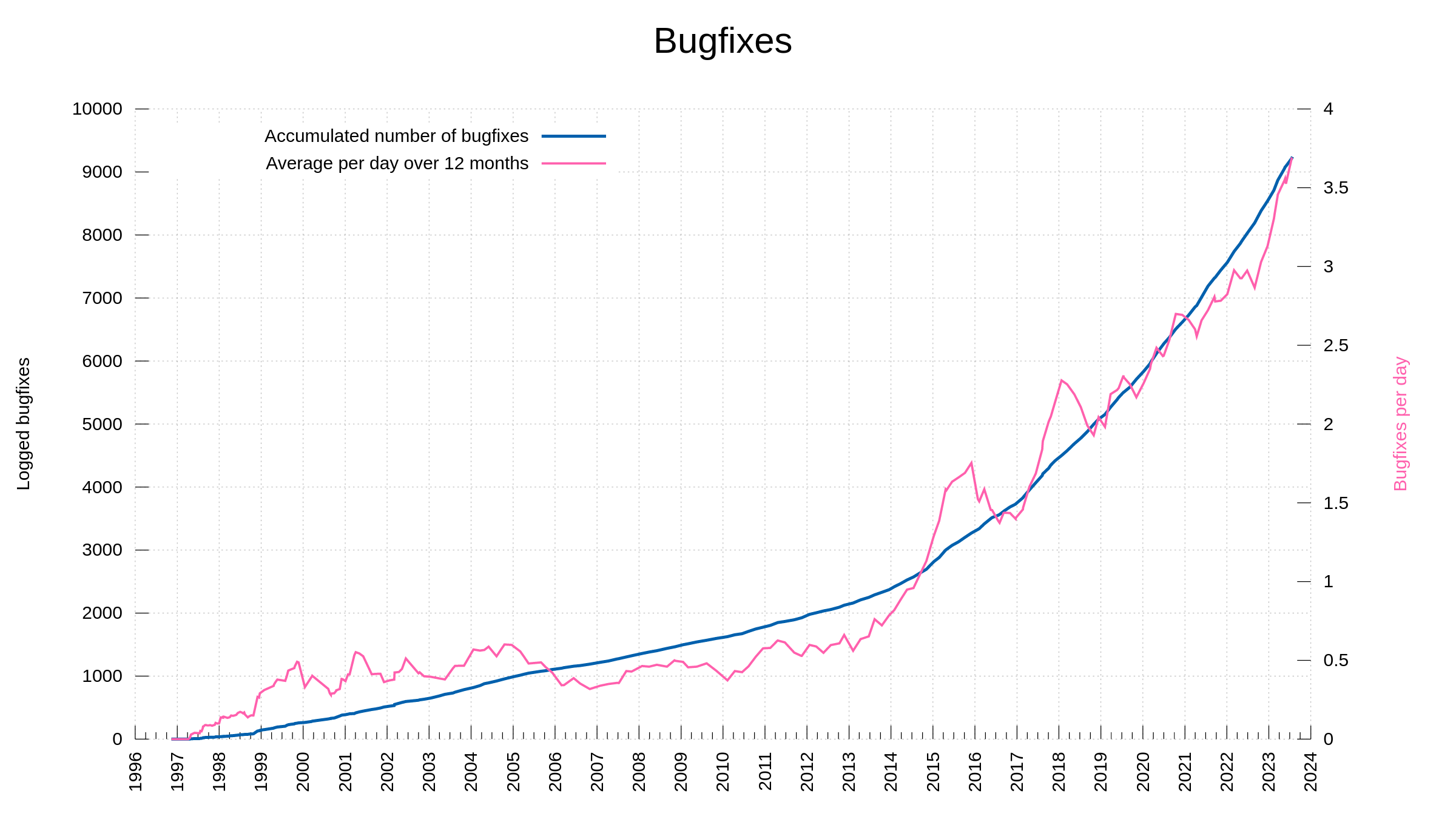
In the curl project we work hard and fierce on security and we always work with security researchers who report problems. We file our own CVEs, we document them and we make sure to tell the world about them. We list over 140 of them with every imaginable detail about them provided. We aim at providing gold-level documentation for everything and that includes our past security vulnerabilities.
That someone else suddenly has submitted a CVE for curl is a surprise. We have not been told about this and we would really have liked to. Now there is a new CVE out there reporting a curl issue and we have no details to say about it on the website. Not good.
I bet curl users soon would like to know the details about this.
Wait 2020?
The new CVE has an ID containing 2020 and that is weird. When you register a CVE you typically get it with the year you request it. Unless you get an ID for an old problem of the past. Is that what they did?
Sources seem to indicate that this was published just days ago.
What is this CVE?
Of course the top link when you search for this CVE is to NVD. Not the most reliable organization, but now we can’t be too picky. On their site they explain this with very few details:
Integer overflow vulnerability in tool_operate.c in curl 7.65.2 via crafted value as the retry delay.
And then the craziest statement of the year. They grade it a 9.8 CRITICAL issue. With 10 as a maximum, this is close to the worst case possible, right?
The code
Let’s pause NVD in their panic state for a moment because I immediately recognized this description. Brief as it is.
I spend a lot of time in the curl security team receiving reports, reviewing reports, reviewing source code, assessing claims and figuring out curl security issues. I had seen this claim before!
On July 27, 2019, a Jason Lee file an issue on hackerone, where he reported that there was an integer overflow problem in curl’s --retry-delay command line option. The option accepts number of seconds and then internally converts to milliseconds by multiplying the value by 1000. The option sets how long time curl should wait until it makes a retry if the previous transfer failed with a transient error.
This means that on a 64 bit machine, if you write
curl --retry-delay 18446744073709552 ...
The number will overflow the math and instead of waiting until the end of the universe, it might retry again within the next few seconds. The above example apparently made it 384 seconds instead. On Windows, which uses 32 bit longs, you can get the problem already by asking for more than two million seconds (roughly 25 days).
A bug, sure. Security problem? No. I told Jason that in 2019 and then we closed the security report. I then filed a pull-request and fixed the bug. Credits to Jason for the report. We moved on. The fix was shipped in curl 7.66.0, released in September 2019.
Grading issues
In previous desperate attempts from me to reason with NVD and stop their scaremongering and their grossly inflating the severity level of issues, they have insisted that they take in all publicly available data about the problem and make an assessment.
It was obvious already before that NVD really does not try very hard to actually understand or figure out the problem they grade. In this case it is quite impossible for me to understand how they could come up with this severity level. It’s like they saw “integer overflow” and figure that wow, yeah that is the most horrible flaw we can imagine, but clearly nobody at NVD engaged their brains nor looked at the “vulnerable” code or the patch that fixed the bug. Anyone that looks can see that this is not a security problem.
The issue listed by NVD even links to my pull request I mention above. There is no doubt that it is the exact same bug they refer to.
Spreading like a virus
NVD hosts a CVE database and there is an entire world and eco system now that pulls the records from them.
NVD now has this CVE-2020-19909 entry in there, rated 9.8 CRITICAL and now this disinformation spreads across the world. Now when we search for this CVE number we find numerous sites that repeats the same data. “This is a 9.8 CRITICAL problem in curl” – when it is not.
I will object
I learned about this slap in my face just a few hours ago (and I write this past Friday midnight), but I intend to do what I can to reject this CVE.
Update: I’m glad to see the Ubuntu took the lead and marked it as not-affected.
Update2: MITRE denied my request to reject the CVE. The full reason from them is now included in my description of CVE-2020-19909 on the curl site.
Update3: a follow-up post.