What happens when you invoke curl. In a single picture.

Yes it is simplified and I chose to show a HTTP/1.1 transfer.

What happens when you invoke curl. In a single picture.
Yes it is simplified and I chose to show a HTTP/1.1 transfer.
Thank you everyone who has helped out in making curl into what it is today.
We make an effort to note the names of and say thanks to every single individual who ever reported bugs, fixed problems, ran tests, wrote code, polished the website, spell-fixed documentation, assisted debug sessions, helped interpret protocol standards, reported security problems or co-authored code etc.
In 2005 I decided to go back through the project history and make sure all names that had been involved up to that point in time would also be mentioned in the THANKS file. This is the reason for the visible bump in the graph.
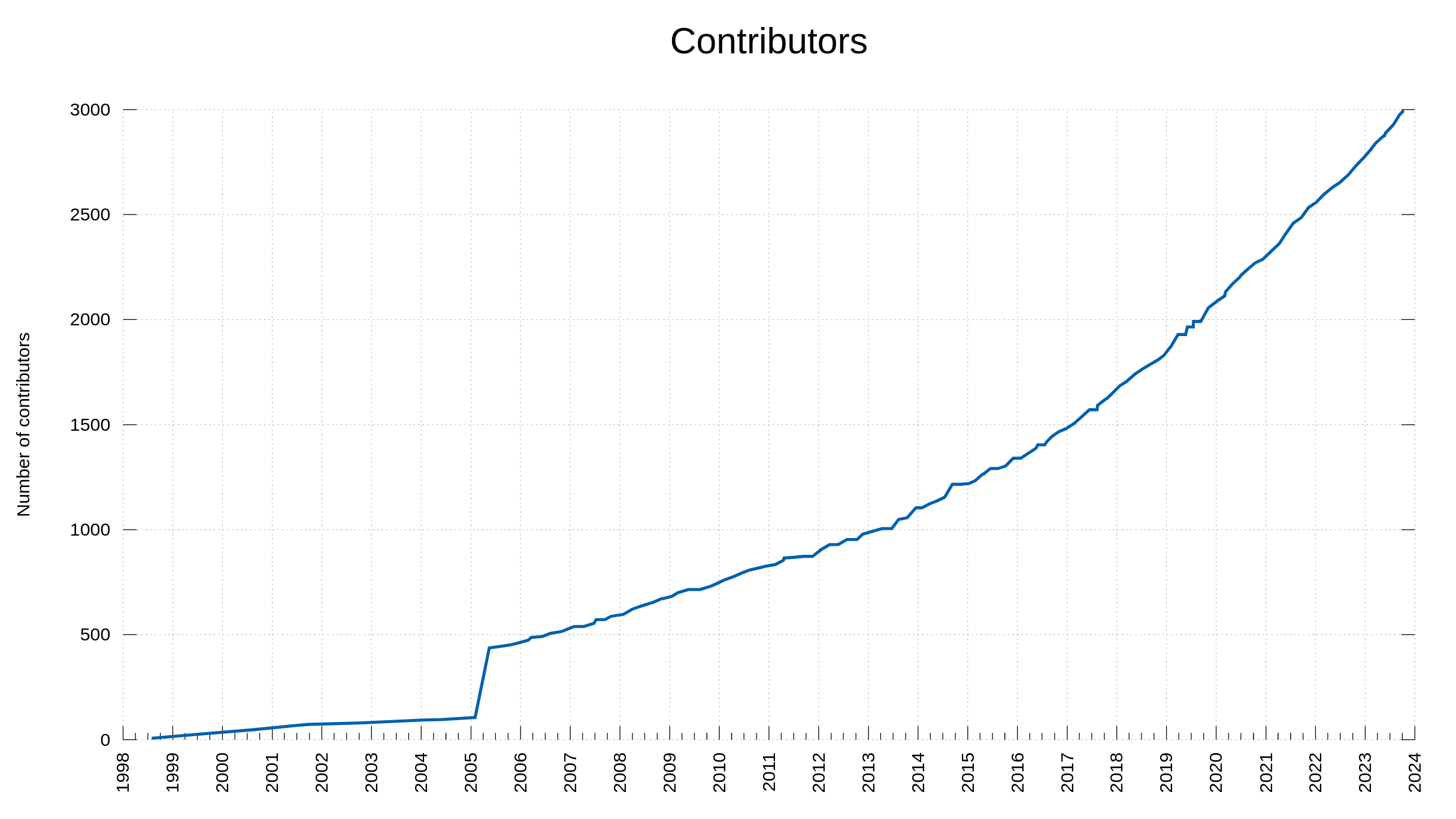
Since then, we add the names of all the helpers. We say thanks and give credits in commit messages and we have scripts to help us collect them and mention them as contributors. We probably miss occasional ones but I hope and believe that most of all the awesome people that ever helped us are recorded accordingly and given credit.
We are nothing without out dear contributors.
Today, this list of people we are thankful for, reached 3,000 entries when Alex Klyubin’s pull request was merged. (The list of names on the website is synced every once in a while so it actually typically shows slightly fewer people than we have logged in git.)
The team behind curl. 3,000 persons over almost 27 years.
We reached 2,000 contributors less than four years ago, in October 2019, so we have added about 250 new names per year to this list the last four years.
We reached 1,000 contributors in March 2013, meaning from then it took about 6.5 years to get the next 1,000. Roughly 150 new names per year.
The first 1,000 took over 16 years to reach.
You too can see it quite clearly in the graph above as well: the rate of which we get new contributors to help out in the project is increasing.
curl has existed for 9338 days. That equals one new contributor every 3.1 days for over 25 years, on average.
It is oftentimes said that Open Source projects in general have a hard time to properly recognize and appreciate non-code contributions. In the curl project, we try hard to not differentiate between help and help.
If a person helps out to take the curl project further, even if just by a little, we say thank you very much and add their name to the list. We need and are grateful for code and non-code contributions alike. One of the most important parts of the curl project is the documentation, and that is clearly not code.
We cannot say much about the contributors because in an effort to lower the bars and reduce friction, we also do not ask them about details. We only know the name they provide the help under, which could be a pseudonym and in some cases clearly are nicknames. We do not know where in the world they originate from or which company they work for, we can’t tell their gender, skin color, religion or other human “properties”. And we don’t care much about those specifics. Our job is to bring curl forward.
This said: there is a risk that we have added the same contributors twice or more, if they have helped out using several different names. That is just not something we can detect or avoid. Unless the contributor themself informs us.
There is also a risk that some of the persons that contributed to curl are not nice people or that they work for reprehensible organizations. We focus on the quality of their submissions and if they hide who they are, we will never know if they actually are animal-hurting nazis hiding behind pseudonyms.
As far as I can tell, we have a lousy contributor diversity. I am pretty sure the majority of all help come from old white middle-class western men. Like myself.
I cannot fully know this for sure because I only actually know a small fraction of all the contributors, but out of the ones I have met this is true and I believe I have met or at least communicated with the ones who have done the vast majority of all the changes.
I would much rather see us have many more contributors from other parts of the world, female, and with non-christian backgrounds, but I cannot control who comes to us. I can only do my best to take care of all and appreciate every contribution without discrimination.
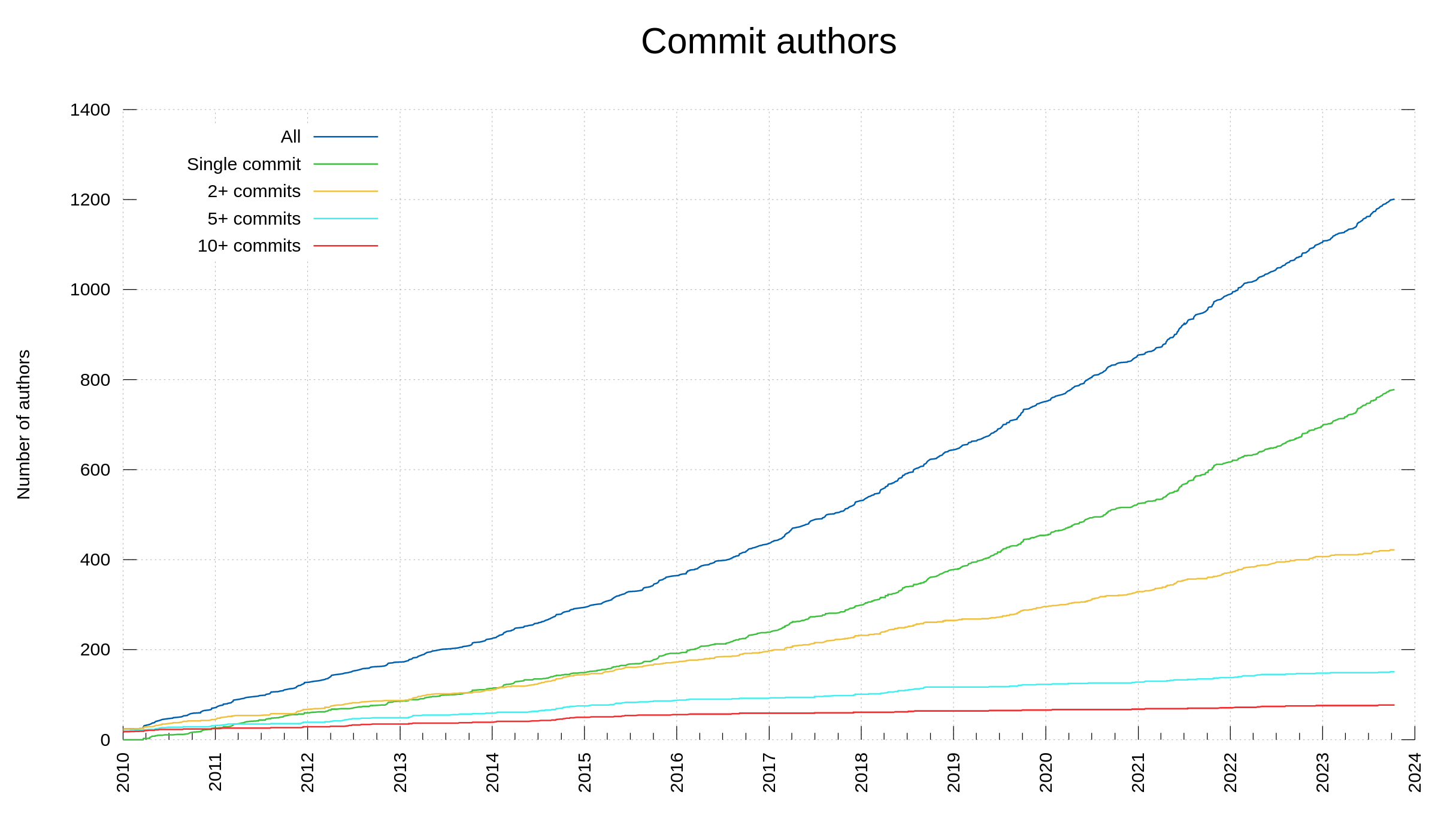
This day when we reach 3,000 contributors, we also count 1,201 commit authors. Persons with their names as authors of at least one commit in the curl source repository. 40% of the contributors are committers. Almost 65% of the committers only ever committed once.
The top image of this blog post is a photo from FOSDEM a few years back when I did a presentation in front of a packed room with some 1,400 attendees. The largest room at FOSDEM is said to fit 1415 persons. So not even two such giant rooms would be enough to hold all the curl contributors if it would have been possible to get them all in one place…
You too can be a curl contributor. We are friendly. It is not hard. There is lots to do. Your contributions can end up getting used by literally billions of humans.
In association with the release of curl 8.4.0, we publish a security advisory and all the details for CVE-2023-38545. This problem is the worst security problem found in curl in a long time. We set it to severity HIGH.
While the advisory contains all the necessary details. I figured I would use a few additional words and expand the explanations for anyone who cares to understand how this flaw works and how it happened.
curl has supported SOCKS5 since August 2002.
SOCKS5 is a proxy protocol. It is a rather simple protocol for setting up network communication via a dedicated “middle man”. The protocol is for example typically used when setting up communication to get done over Tor but also for accessing Internet from within organizations and companies.
SOCKS5 has two different host name resolver modes. Either the client resolves the host name locally and passes on the destination as a resolved address, or the client passes on the entire host name to the proxy and lets the proxy itself resolve the host remotely.
In early 2020 I assigned myself an old long-standing curl issue: to convert the function that connects to a SOCKS5 proxy from a blocking call into a non-blocking state machine. This is for example much noticeable when an application performs a large amount of parallel transfers that all go over SOCKS5.
On February 14 2020 I landed the main commit for this change in master. It shipped in 7.69.0 as the first release featuring this enhancement. And by extension also the first release vulnerable to CVE-2023-38545.
The state machine is called repeatedly when there is more network data to work on until it is done: when the connection is established.
At the top of the function I made this:
bool socks5_resolve_local = (proxytype == CURLPROXY_SOCKS5) ? TRUE : FALSE;
This boolean variable holds information about whether curl should resolve the host or just pass on the name to the proxy. This assignment is done at the top and thus for every invocation while the state machine is running.
The state machine starts in the INIT state, in which the main bug for today’s story time lies. The flaw is inherited from the function from before it was turned into a state-machine.
if(!socks5_resolve_local && hostname_len > 255) {
socks5_resolve_local = TRUE;
}
SOCKS5 allows the host name field to be up to 255 bytes long, meaning a SOCKS5 proxy cannot resolve a longer host name. On finding a too long host name. the curl code makes the bad decision to instead switch over to local resolve mode. It sets the local variable for that purpose to TRUE. (This condition is a leftover from code added ages ago. I think it was downright wrong to switch mode like this, since the user asked for remote resolve curl should stick to that or fail. It is not even likely to work to just switch, even in “good” situations.)
The state machine then switches state and continues.
If the state machine cannot continue because it has no more data to work with, like if the SOCKS5 server is not fast enough, it returns. It gets called again when there is data available to continue working on. Moments later.
But now, look at the local variable socks5_resolve_local at the top of the function again. It again gets set to a value depending on proxy mode – not remembering the changed value because of the too long host name. Now it again holds a value that says the proxy should resolve the name remotely. But the name is too long…
curl builds a protocol frame in a memory buffer, and it copies the destination to that buffer. Since the code wrongly thinks it should pass on the host name, even though the host name is too long to fit, the memory copy can overflow the allocated target buffer. Of course depending on the length of the host name and the size of the target buffer.
The allocated memory area curl uses to build the protocol frame in to send to the proxy, is the same as the regular download buffer. It is simply reused for this purpose before the transfer starts. The download buffer is 16kB by default but can also be set to use a different size at the request of the application. The curl tool sets the buffer size to 100kB. The minimum accepted size is 1024 bytes.
If the buffer size is set smaller than 65541 bytes this overflow is possible. The smaller the size, the larger the possible overflow.
A host name in a URL has no real size limit, but libcurl’s URL parser refuses to accept names longer than 65535 bytes. DNS only accepts host names up 253 bytes. So, a legitimate name that is longer than 253 bytes is unusual. A real name that is longer than 1024 is virtually unheard of.
Thus it pretty much requires a malicious actor to feed a super-long host name into this equation to trigger this flaw. To use it in an attack. The name needs to be longer than the target buffer to make the memory copy overwrite heap memory.
The host name field of a URL can only contain a subset of octets. A range of byte values are plain invalid and would cause the URL parser to reject it. If libcurl is built to use an IDN library, that one might also reject invalid host names. This bug can therefore only trigger if the right set of bytes are used in the host name.
An attacker that controls an HTTPS server that a libcurl using client accesses over a SOCKS5 proxy (using the proxy-resolver-mode) can make it return a crafted redirect to the application via a HTTP 30x response.
Such a 30x redirect would then contain a Location: header in the style of:
Location: https://aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa/
… where the host name is longer than 16kB and up to 64kB
If the libcurl using client has automatic redirect-following enabled, and the SOCKS5 proxy is “slow enough” to trigger the local variable bug, it will copy the crafted host name into the too small allocated buffer and into the adjacent heap memory.
A heap buffer overflow has then occurred.
curl should not switch mode from remote resolve to local resolve due to too long host name. It should rather return an error and starting in curl 8.4.0, it does.
We now also have a dedicated test case for this scenario.
This issue was reported, analyzed and patched by Jay Satiro.
This is the largest curl bug-bounty paid to date: 4,660 USD (plus 1,165 USD to the curl project, as per IBB policy)

Yes, this family of flaws would have been impossible if curl had been written in a memory-safe language instead of C, but porting curl to another language is not on the agenda. I am sure the news about this vulnerability will trigger a new flood of questions about and calls for that and I can sigh, roll my eyes and try to answer this again.
The only approach in that direction I consider viable and sensible is to:
Such development is however currently happening in a near glacial speed and shows with painful clarity the challenges involved. curl will remain written in C for the foreseeable future.
Everyone not happy about this are of course welcome to roll up their sleeves and get working.
Including the latest two CVEs reported for curl 8.4.0, the accumulated total says that 41% of the security vulnerabilities ever found in curl would likely not have happened should we have used a memory-safe language. But also: the rust language was not even a possibility for practical use for this purpose during the time in which we introduced maybe the first 80% of the C related problems.
Reading the code now it is impossible not to see the bug. Yes, it truly aches having to accept the fact that I did this mistake without noticing and that the flaw then remained undiscovered in code for 1315 days. I apologize. I am but a human.
It could have been detected with a better set of tests. We repeatedly run several static code analyzers on the code and none of them have spotted any problems in this function.
In hindsight, shipping a heap overflow in code installed in over twenty billion instances is not an experience I would recommend.
To learn how this flaw was reported and we worked on the issue before it was made public. Go check the Hackerone report.
I use his “I’m going to write myself a minivan”-strip above because it’s a classic. Adams himself has turned out to be a questionable person with questionable opinions and I do not condone or agree with what he says.
We cut the release cycle short and decided to ship this release now rather than later because of the heap overflow issue we found.
the 252nd release
3 changes
28 days (total: 9,336)
136 bug-fixes (total: 9,551)
216 commits (total: 31,158)
1 new public libcurl function (total: 93)
0 new curl_easy_setopt() option (total: 303)
1 new curl command line option (total: 258)
46 contributors, 20 new (total: 2,996)
21 authors, 7 new (total: 1,200)
2 security fixes (total: 148)
(CVE-2023-38545) This flaw makes curl overflow a heap based buffer in the SOCKS5 proxy handshake.
See also my separate detailed explainer about CVE-2023-38545.
(CVE-2023-38546) This flaw allows an attacker to insert cookies at will into a running program using libcurl, if the specific series of conditions are met and the cookies are put in a file called “none” in the application’s current directory.
The curl tool now supports IPFS URLs via gateway. I emphasize that it is the tool because this support is not libcurl. The URL needs to be a correct IPFS URL but curl only works with it if you provide an IPFS gateway, it has no actual native IPFS implementation. You want to read the new IPFS section on the curl website for details.
This is new and very simply function added to the libcurl API: it returns all the easy handles that were previously added to it.
The legacy mingw version is deprecated and by dropping support for this we can simplify code a little.
Some of the things we fixed in this release are…
Numerous smaller and larger fixes went in this cycle to make sure the cmake and configure configs are more aligned and create more similar default builds.
Iterating over IP addresses when connecting could accidentally do delays, making the process take longer time than necessary.
curl now keeps much less data in memory per cookie
All curl man pages got their references updated and they are now verified and checked in tests to remain accurate and well formatted.
The check that prevents too large accumulated HTTP response headers actually used the wrong counter so it kicked in too early.
Getting this authentication method to work in all cases turns out to be a real adventure and in this release we fix yet some minor issues.
Up until now, the maximum file size option only works on stopping transfers before it even began if libcurl knew the file size was too big. Starting now, it will also stop ongoing transfers if they reach the maximum limit. This should help users avoid unwanted surprises.
Rewinding files when doing multipart formbased transfers on 32 bit ARM using the legacy libcurl curl_formadd API did not work because of data size incompatibilities. It took some work to find and understand as it still worked fine on x86 32 bit for example!
The libssh library mostly passes on the data with the same size libcurl passes to it, it turns out. That is not compatible with the SFTP protocol so in order to make libcurl work better, it now caps how much data it can send in a single libssh send call. It probably makes SFTP uploads much slower.
The mime boundaries used for multipart formposts now use more random bits than before. Up from 64 to 130 bits. It now produces strings using alphanumerical characters instead of just hex.
The same style of support for setting TLS 1.3 ciphers and curves as for regular TLS were added to the QUIC code.
Improved handling of GOAWAY when wanting to use use connection and then move on to use another.
When using one of the WebSocket schemes, curl will now fall back and try the http_proxy and https_proxy environment variables if ws_proxy or wss_proxy is not set.
The variable --expand functionality did not work for command line options that accept file names, such as --output. It does now.
We have synced the coming release cycles on this release. The next one is thus planned to happen in exactly eight weeks time. On December 6, 2023.


