
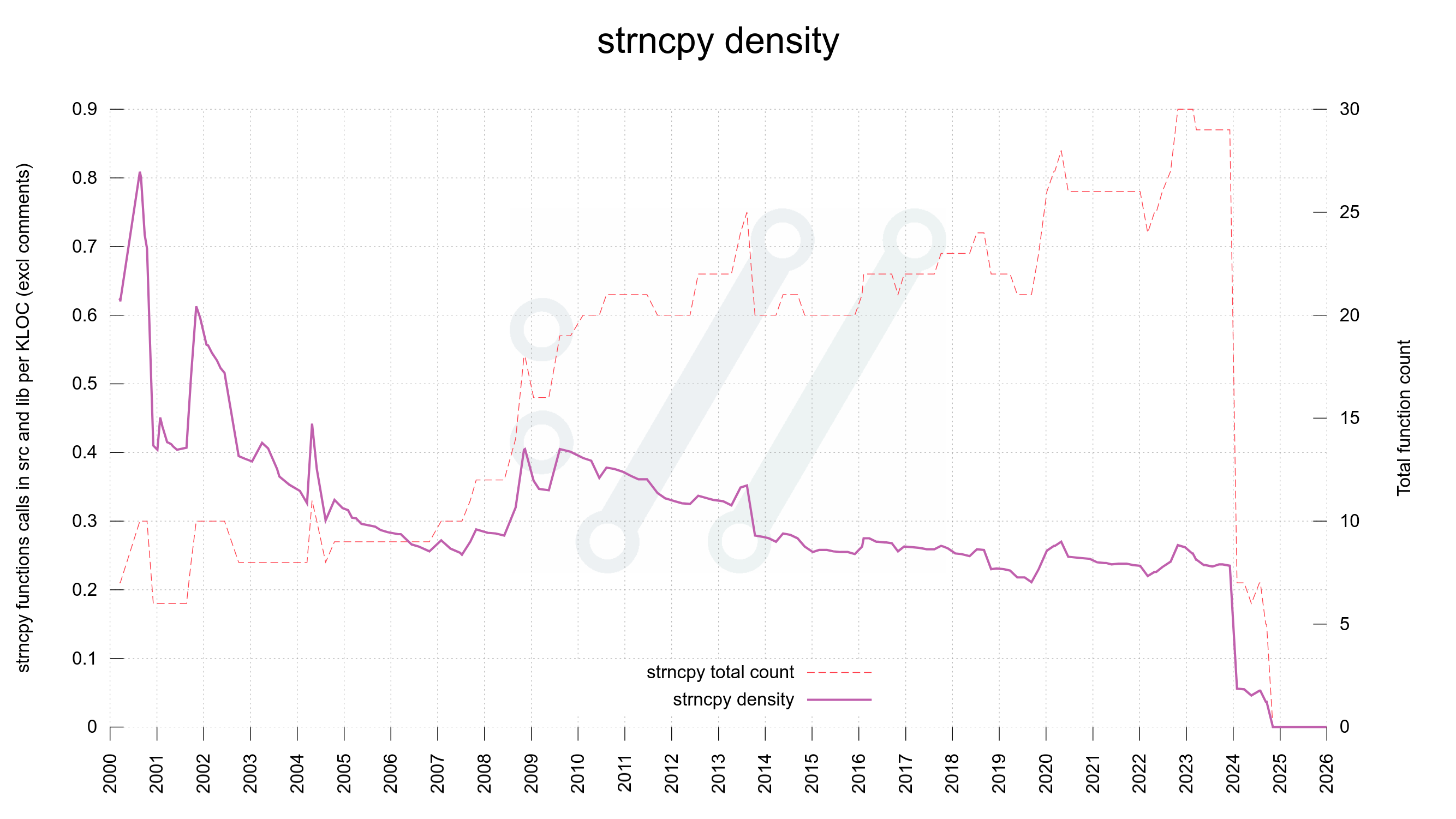
Some time ago I mentioned that we went through the curl source code and eventually got rid of all strncpy() calls.
strncpy() is a weird function with a crappy API. It might not null terminate the destination and it pads the target buffer with zeroes. Quite frankly, most code bases are probably better off completely avoiding it because each use of it is a potential mistake.
In that particular rewrite when we made strncpy calls extinct, we made sure we would either copy the full string properly or return error. It is rare that copying a partial string is the right choice, and if it is, we can just as well memcpy it and handle the null terminator explicitly. This meant no case for using strlcpy or anything such either.
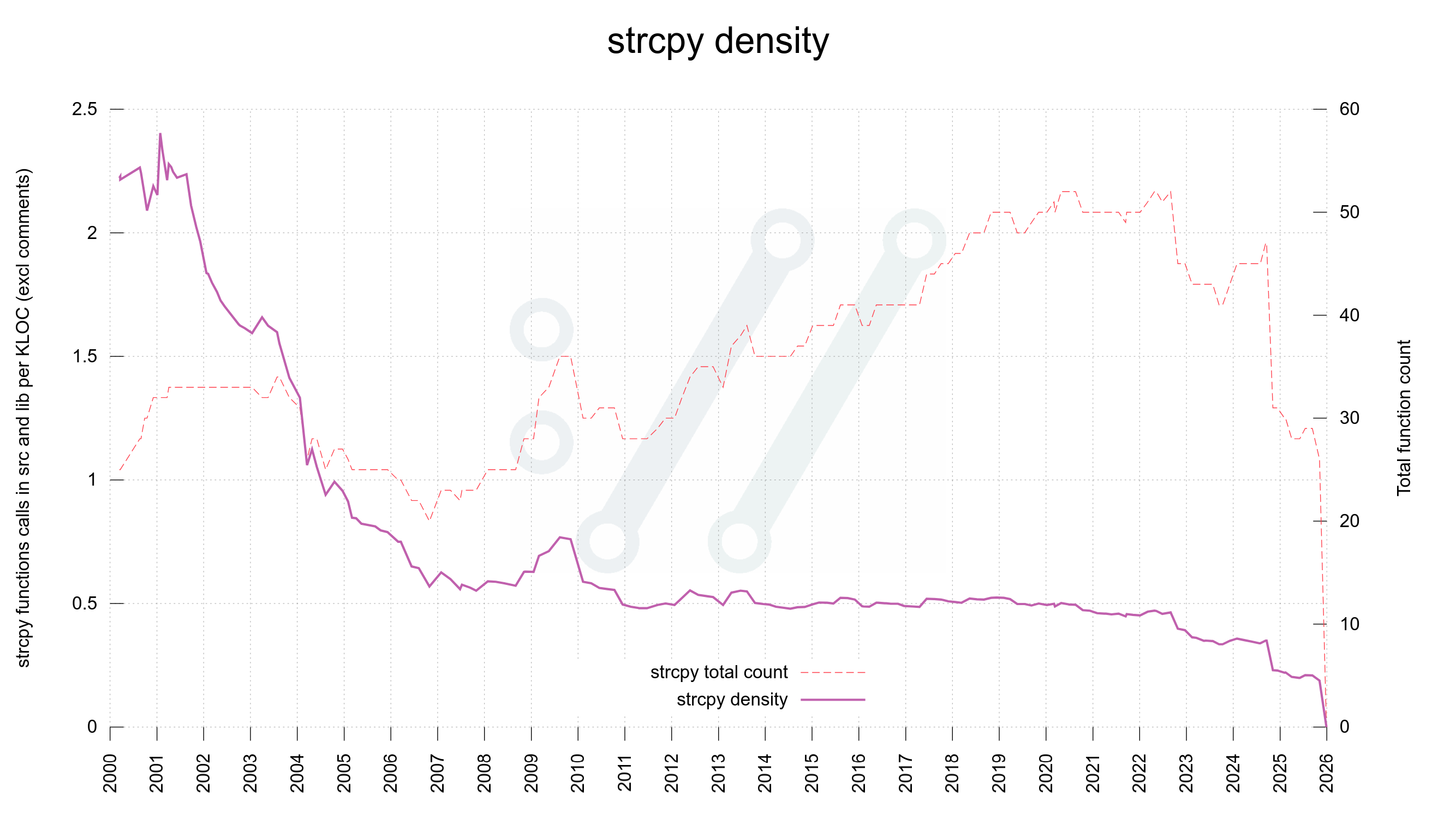
But strcpy?
strcpy however, has its valid uses and it has a less bad and confusing API. The main challenge with strcpy is that when using it we do not specify the length of the target buffer nor of the source string.
This is normally not a problem because in a C program strcpy should only be used when we have full control of both.
But normally and always are not necessarily the same thing. We are but all human and we all do mistakes. Using strcpy implies that there is at least one or maybe two, buffer size checks done prior to the function invocation. In a good situation.
Over time however – let’s imagine we have code that lives on for decades – when code is maintained, patched, improved and polished by many different authors with different mindsets and approaches, those size checks and the function invoke may glide apart. The further away from each other they go, the bigger is the risk that something happens in between that nullifies one of the checks or changes the conditions for the strcpy.
Enforce checks close to code
To make sure that the size checks cannot be separated from the copy itself we introduced a string copy replacement function the other day that takes the target buffer, target size, source buffer and source string length as arguments and only if the copy can be made and the null terminator also fits there, the operation is done.
This made it possible to implement the replacement using memcpy(). Now we can completely ban the use of strcpy in curl source code, like we already did strncpy.
Using this function version is a little more work and more cumbersome than strcpy since it needs more information, but we believe the upsides of this approach will help us have an oversight for the extra pain involved. I suppose we will see how that will fare down the road. Let’s come back in a decade and see how things developed!
void curlx_strcopy(char *dest,
size_t dsize,
const char *src,
size_t slen)
{
DEBUGASSERT(slen < dsize);
if(slen < dsize) {
memcpy(dest, src, slen);
dest[slen] = 0;
}
else if(dsize)
dest[0] = 0;
}
AI slop
An additional minor positive side-effect of this change is of course that this should effectively prevent the AI chatbots to report strcpy uses in curl source code and insist it is insecure if anyone would ask (as people still apparently do). It has been proven numerous times already that strcpy in source code is like a honey pot for generating hallucinated vulnerability claims.
Still, this will just make them find something else to make up a report about, so there is probably no net gain. AI slop is not a game we can win.
Well, there are so many /safer/ variants of the standard library functions to get sick about it.
Targeting a “library-level” function, at least you should primarily check for `dest != NULL`, and also `src != NULL` would be nice.
Let me answer you with a question.
Do you think it makes more sense to check your pointers are not NULL once before you pass it to other functions, or to have every function you pass them to check it for you ?
Genius are you not. Failures: 1) Slen < 0; 2) dsize <= 0; 3) missing dest[0] = 0 as first stmt; also delete else if clause. Yikes! You should not create code for others.
@Mondo: thanks for your contribution. Truly “helpful”.
Mondo:
1) slen can’t be less than 0.
2) dsize can’t be less than 0 either and the code already has a check for if it’s 0 where it matters.
3) It’s not missing dest[0] = 0 as first statement. It’s not needed in the normal case (slen < dsize) and it also shouldn't be done before checking dsize, as the code does in the "else if".
Fwiw the strncpy and similar functions can also be troublesome when executed with string literals. People make those mistakes over and over where they want to copy or compare a literal of N bytes but mistakenly pass in N+-1 or other values… I made some research on it in the past which I detailed on https://github.com/disconnect3d/cstrnfinder
Isn’t this essentially strcpy_s() from Annex K (ISO C11)?
If so, the known issue of strcpy_s() would apply:
@Alejandro:
> Isn’t this essentially strcpy_s() from Annex K (ISO C11)?
I have no idea – it might be. I don’t study the C standards and we still use C89 in curl…
It seems it’s actually strncpy_s() from Annex K, except for the fact that strncpy_s() returns an error code on failure, while yours doesn’t.
I know you use C89 in curl, however, it’s good to be aware of development elsewhere. Especially of failed APIs. Annex K APIs are infamous for causing more bugs than they remove.
Please read carefully, as it documents known issues of this API.
D’oh, I can’t publish links. They get removed from my post.
Please read this (hopefully, this time will work):
www DOT open-std DOT org SLASH jtc1/sc22/wg14/www/docs/n1969.htm
Nobody ever actually implemented Annex K. glibc refuses to, Microsoft never can because our _s family don’t have the same signatures.
See also “Field Experience with Annex K” (N1967)
Regarding curlx_strcopy, some thoughts:
It seems to me a return value indicating failure would be desirable. Simply null terminating dest in the case if failure (when possible) isn’t enough; it’s not possible to determine if the size check failed, or if the source is legitimately an empty string. This could be particularly confusing in some cases e.g. an off-by-one where slen == dsize. It may not be apparent to the caller why they sre getting an empty string back. There’s also no way at all to detect cases where slen is not < dsize and dsize == 0.
Isn’t this more like a curlx_memcopy_and_add_trailing_zero() function?
I mean, the function does not treat source as a string (i.e. check for zero-ending). Most uses of the functions seems to set src_len to strlen(src) anyway (could almost be done by the function).
Another odd thing is that if the buffer sizes fails it just continue. So for example in https://github.com/curl/curl/blob/5f5e000278df1029db2ee3f4499b5ce27c1861b2/lib/mime.c#L605 it is assumed the copy succeeds (len is set to 3 regardless of success and this is would be a bad pattern).
Not worse than strcpy, and not a major problem in mime.c. It just made me thinking…. You can skip this comment if you think differently.
Also, why not returning something else than void? Perhaps something useful as srclen?
People ask about the return code:
This function is meant to always work – like strcpy. That’s also why the assert is there, because it is assumed that if we mess up somewhere we catch that in testing/fuzzing – not in production.
The idea is that this function is always used where it succeeds, thus checking for success is superfluous.
@Kjell: *most* invokes do strlen() yes, not all so we don’t do strlen within the function. And doing conditional strlen()s have turned out to be fragile in the past. I rather work on reducing the strlen() calls in the parent funtions.
We also banned it from haproxy years ago as well by defining this:
#undef strcpy
__attribute__warning(“\n”
” * WARNING! strcpy() must never be used, because there is no convenient way\n”
” * to use it that is safe. Use memcpy() or strlcpy2() instead!\n”)
extern char *strcpy(char *__restrict dest, const char *__restrict src);
It can start correctly and suddenly evolve into something that becomes uncontrollable. The C string API is a mess, and those who don’t understand C always criticize C developers for “reinventing their own strings” but the reason is that there’s nothing that’s at the same time convenient, safe and portable. So everyone recreates their own set of functions.
Convenience encourages adoption, and that should really be the first thing to think about when replacing string functions. In your case it looks OK 😉
If this function is designed to work always, why bother writing the case where it doesn’t? That’s a tacit admission that it’s not expected to do so. Proving this would be far too onerous in such a poor language as C.
It’s funny: I’m a Lisp hacker, so I know a great deal about linked lists; the C language string interface is effectively an unnecessary interface mimicking that for linked lists, in a language uniquely unsuited to it, exacerbating just about every other glaring problem in the language.
Wouldn’t it be a better idea to introduce a decent string type and slowly port over everything to use it, instead?
@Verisimilitude: is that really that hard to understand? There is no use of this function anywhere in curl code where it is expected that it *can* fail. The conditions in the code are there for when the function is used wrongly (after a future edit). That’s not really the function failing, that is the function being used the wrong way by the calling function and the conditions are there to limit the harm the function does.
A decent string type? Like the one in the LispOS kernel?
Inventing another API looks like total overkill.
You don’t have thousands of strcpy uses through the curl source: in curl-8.14.1 (from debian bookworm) there are just 32, of which *at least* 3/4 could be replaced with memcpy, since the source is either a literal string or you already have calculated its length and checked whether it fits into the destination buffer. Some of them look totally pointless: for instance, in the (compat?) implementation of inet_ntop, you could snprintf directly into the result buffer — the standard does not require inet_ntop to leave the destination buffer unchanged in case of error.
Since it’s the first time I look at the curl source code, much more troubling looks the wild use if (m)snprintf without *ever* checking for truncation: are all those strings really safe to truncate?
@spagoveanu: we welcome every improvement you can bring