It started as just a test to see if I could use the existing advisory data we have for all curl CVEs to date and provide that as JSON. Maybe, I thought, if we provide it good enough it can be used to populate other databases automatically or even get queried easier by tools.
Information
In the curl project we have published 141 vulnerability advisories so far, each with its own registered CVE Id. We make an effort to provide all the details about all the flaws as good and thorough as possible, but also with easy overviews and tables etc so that users can quickly detect for example which curl versions are vulnerable to which flaws etc. It is our going the extra meticulous mile that makes it extra annoying when others override what we conclude.
More machine friendly
In a recent push I decided that all the info we have and provide could and should be offered in a more machine friendly format for whoever wants it.
After a first few test shots, fellow curl team mates pointed out to me that there is an existing effort called the Open Source Vulnerability format, an openly developed JSON schema designed for pretty much exactly what I was set out to do. I agreed that it made sense to follow something existing rather to make up my own format.
Can be improved
Of course we ran into some minor snags with this schema and there are still details in it that I think can be improved and we are discussing with the OSV team to see if there is merit to our ideas or not. Still, even without any changes we can now offer our data using this established format.
The two primary things I want to improve is how we provide project identification (whose issue is this) and how we convey the severity level of the issue.
Different sets
As of now, we offer a set of different ways to get the CVE data as JSON.
1. Everything all at once
On the fixed URL https://curl.se/docs/vuln.json, we provide a JSON array holding a number of JSON objects. One object per existing CVE. Right now, this is 349KB of data. (If you ask for it compressed it will be smaller!)
This URL will always contain the entire set and it will automatically update in the future as we published new CVEs. It also automatically updates when we correct or change any of the previously published advisories.
2. Single object per issue
If you prefer to get the exact metadata for a single specific curl CVE, you can get the JSON for an issue by replacing the .html extension to .json for any CVE documented on the website. You will also find a menu option the “related box” for each documented CVE that links to it.
For example the vulnerability CVE-2022-35260, that we published last year which is documented on https://curl.se/docs/CVE-2022-35260.html, has its corresponding JSON object at https://curl.se/docs/CVE-2022-35260.json.
3. Objects per release
On the curl website we already offer a way for users to get a list of all known vulnerabilities a certain specific release is known to be vulnerable to. Of course always updated with the latest publications.
For example, curl version 7.87.0 has all its vulnerability information detailed on https://curl.se/docs/vuln-7.87.0.html. When I write this, there are eight known vulnerabilities for this version.

Again, either by clicking the JSON link there on the page under the table, or simply by replacing html by json in the URL, the user can get a listing of all the CVEs this version is vulnerable to, as a JSON array with a number of JSON objects inside. In this case, eight objects as of now.
That info is thus available at https://curl.se/docs/vuln-7.87.0.json.
JSON
While I expect the format might still change a little bit going forward, and not all issues have all the metadata provided just yet (for example, the git commit ranges are still lacking on a number of issues from before 2017), here is an illustration screenshot of jq displaying the JSON object for CVE-2022-27780.
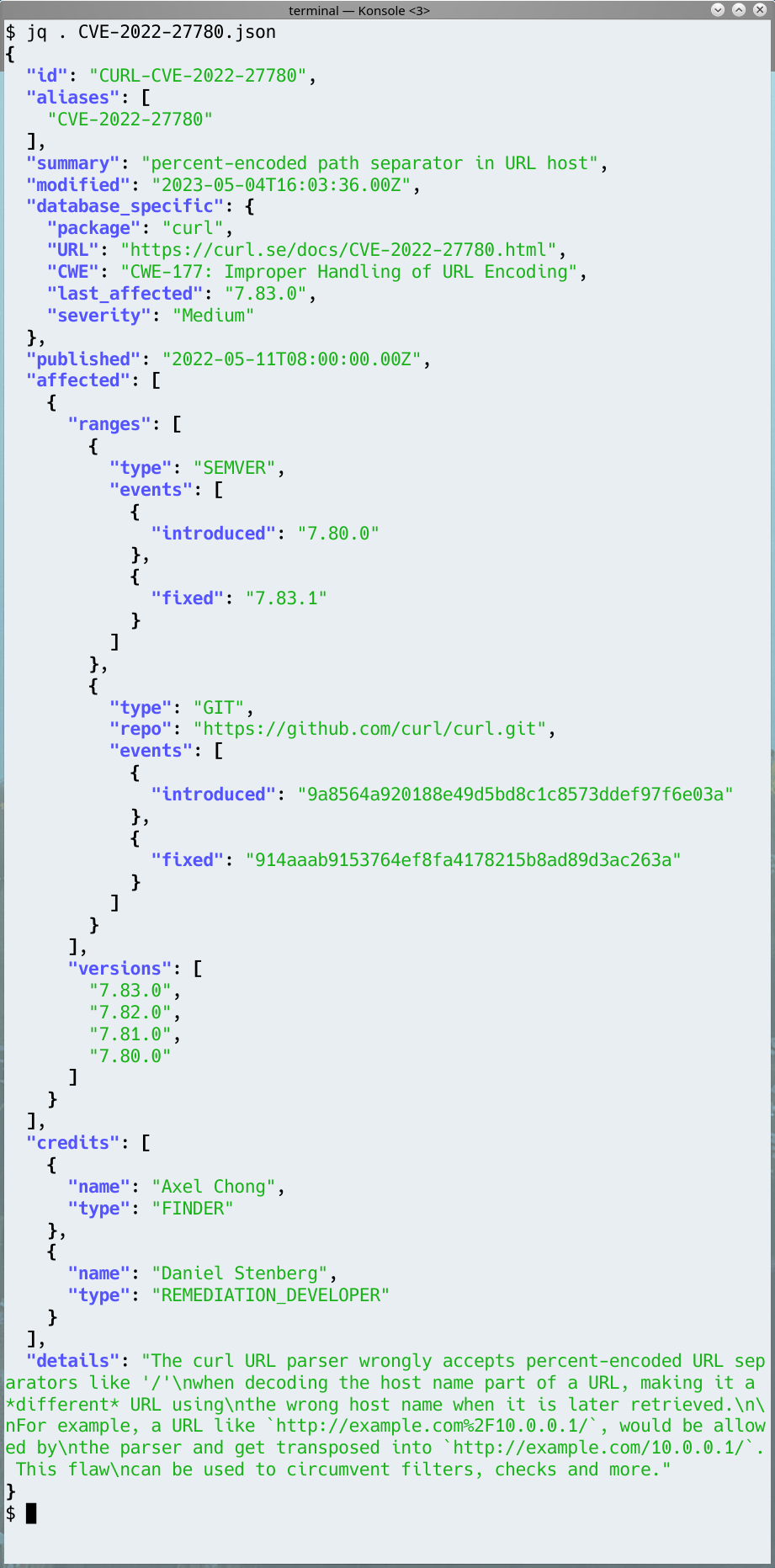
Object details
The database_specific object near the top is metadata that we have and believe belongs with the issue but that has no defined established field in the JSON schema. Since I think the data still adds value to users, I decided to put them into this section that is designed and meant exactly for this kind of extensions.
You can see that we set an “id” that is the CVE ID with a CURL- prefix. This is just us catering to the conditions of OSV and the JSON schema. We apparently need our own ID and provide the actual CVE ID as an alias, so we “fake” this by simply prepending curl to the CVE ID. We don’t use any private ID when we work with vulnerabilities: we only deal with public issues and we only deal with issues that are CVE worthy so it seems unnecessary to involve anything else.
Credits
Image by Reto Scheiwiller from Pixabay