
 A few years ago I explained the timer and timeout concepts of the libcurl internals. A decent prerequisite for this post really.
A few years ago I explained the timer and timeout concepts of the libcurl internals. A decent prerequisite for this post really.
Today, I introduced “timer IDs” internally in libcurl so that all expiring timers we use has to specify which timer it is with an ID, and we only have a set number of IDs to select from. Turns out there are only about 10 of them. 10 different ones. Per easy handle.
With this change, we now only allow one running timer for each ID, which then makes it possible for us to change timers during execution so that they never “fire” in vain like they used to do (since we couldn’t stop or remove them them before they expired previously). This change makes event loops slightly more efficient since now they will end up getting much fewer “spurious” timeouts that happen only because we had no infrastructure to prevent them.
Another benefit from only keeping one single timer for each ID in the list of timers, is that the dynamic list of running timers immediately become much shorter. This, because many times the same timer ID was used again and we would then add a new node to the list so the timer that had one purpose would expire twice (or more). But now it no longer works like that. In some typical uses I’ve tested, I’ve seen the list shrink from a maximum of 7-8 nodes down to a maximum of 1 or 2.
Finally, since we now have a finite number of timers that can be set at any given time and we know the maximum amount is fairly small, I could make the timer code completely skip using dynamic memory. Allocating 10 tiny structs as part of the main handle allocation is more efficient than doing tiny mallocs() for them one by one. In a basic comparison test I’ve run, this reduced the total number of allocations from 82 to 72 for “curl localhost”.
This change will be included in the pending curl release targeted to ship on June 14th 2017. Possibly called version 7.54.1.
Those are all in a tree
As explained previously: the above explanation of timers goes for the set of timers kept for each individual easy handle, and with libcurl you can add an unlimited amount of easy handles to a multi handle (to perform lots of transfers in parallel) and then the multi handle has a self-balanced splay tree with the nearest-in-time timer for each individual easy handle as nodes in the tree, so that it can quickly and easily figure out which handle that needs attention next and when in time that is.
The illustration below shows a captured imaginary moment in time when there are five easy handles in different colors, all doing their own separate transfers, Each easy handle has three private timers set. The tree contains five nodes and the root of the tree is the node representing the the easy handle that needs to be taken care of next (in time). It also means we immediately know exactly how long time there is left until libcurl needs to act next.
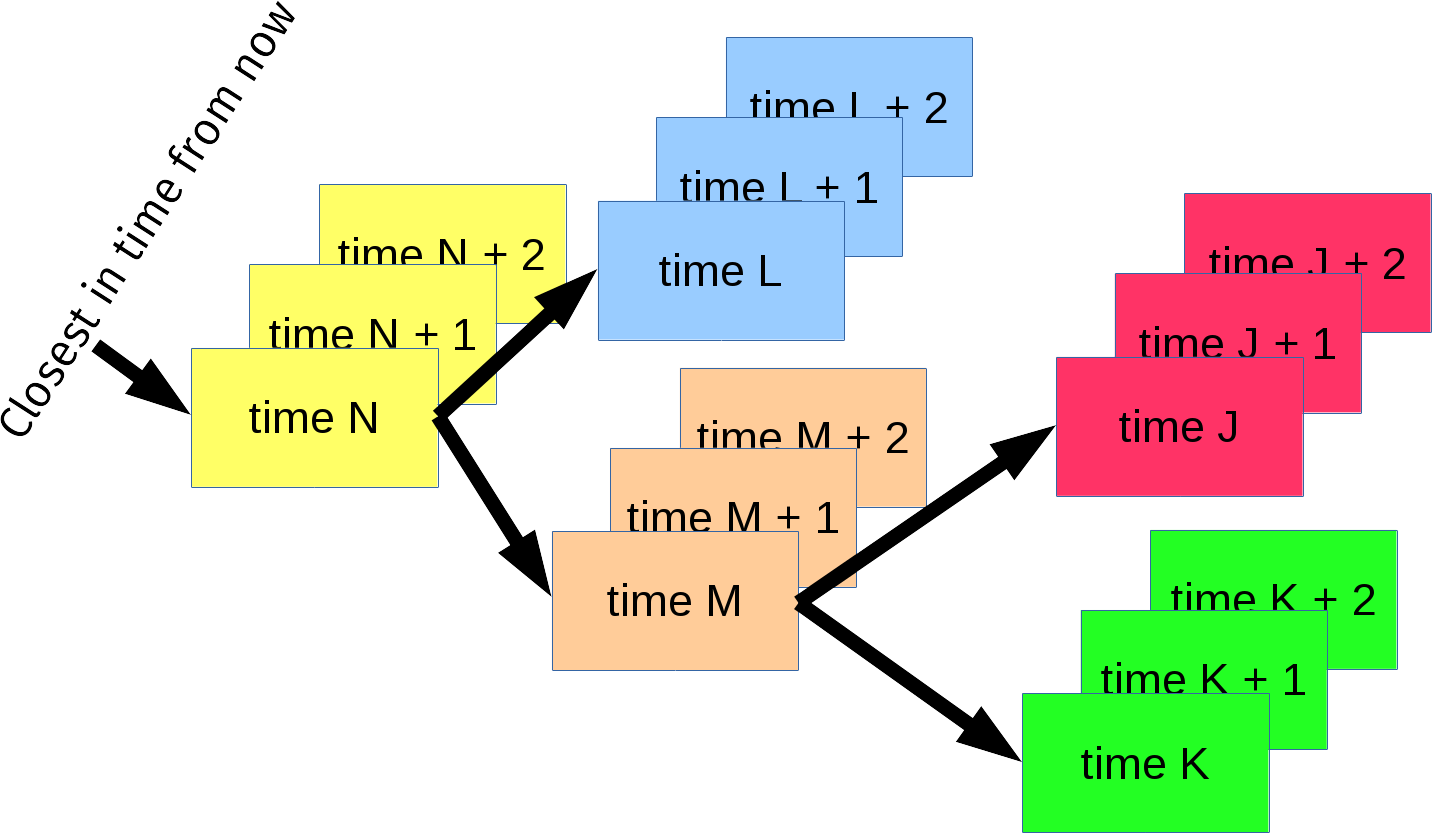
Expiry
As soon “time N” occurs or expires, libcurl takes care of what the yellow handle needs to do and then removes that timer node from the tree. The yellow handle then advances the next timer first in line and the tree gets re-adjusted accordingly so that the new yellow first-node gets re-inserted positioned at the right place in the tree.
In our imaginary case here, the new yellow time N (formerly known as N + 1) is now later in time than L, but before M. L is now nearest in time and the tree has now adjusted to look something like this:
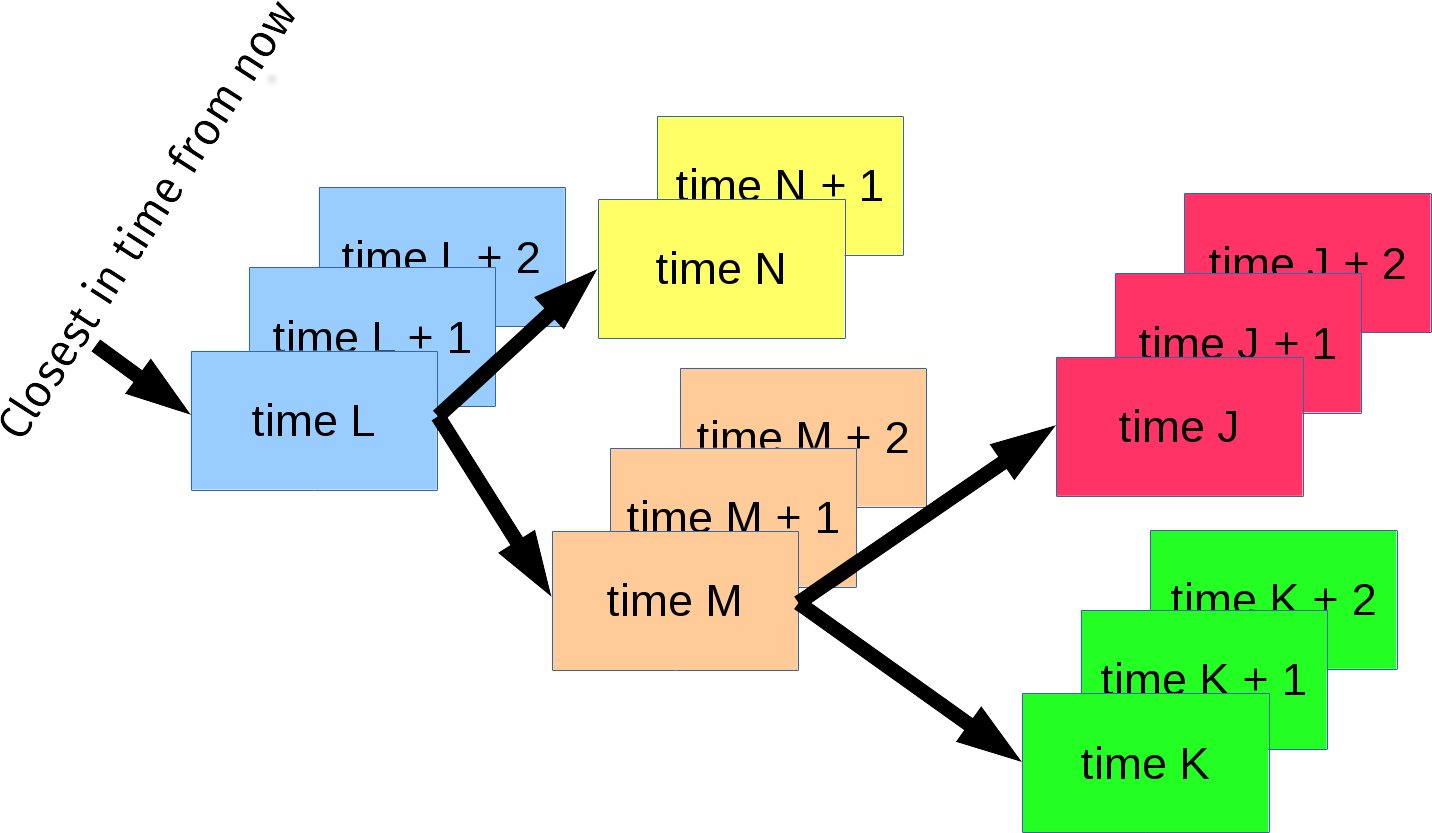
Since the tree only really cares about the root timer for each handle, you also see how adding a new timeout to single easy handle that isn’t the next in time is a really quick operation. It just adds a node in a linked list – per that specific handle. The linked list which now has a maximum length that is capped to the total amount of different timers: 10.
Straight-forward!