

I spent a lot of time and effort digging up the numbers and facts for this post!
Lots of people keep referring to the awesome summary put together by a friendly pseudonymous “Tim” which says that “53 out of 95” (55.7%) security flaws in curl could’ve been prevented if curl had been written in Rust. This is usually in regards to discussions around how insecure C is and what to do about it. I’ve blogged about this topic before, but things change, the world changes and my own view on these matters keep getting refined.
I did my own count: how many of the current 98 published security problems in curl are related to it being written in C?
Possibly due to the slightly different question, possibly because I’ve categorized one or two vulnerabilities differently, possibly because I’m biased as heck, but my count end up at:
51 out of 98 security vulnerabilities are due to C mistakes
That’s still 52%. (you can inspect my analysis and submit issues/pull-requests against the vuln.pm file) and yes, 51 flaws that could’ve been avoided if curl had been written in a memory safe language. This contradicts what I’ve said in the past, but I will also show you below that the numbers have changed and I still was right back then!
Let me also already now say that if you check out the curl security section, you will find very detailed descriptions of all vulnerabilities. Using those, you can draw your own conclusions and also easily write your own blog posts on this topic!
This post is not meant as a discussion around how we can rewrite C code into other languages to avoid these problems. This is an introspection of the C related vulnerabilities in curl. curl will not be rewritten but will continue to support backends written in other languages.
It seems hard to draw hard or definite conclusions based on the CVEs and C mistakes in curl’s history due to the relatively small amounts to analyze. I’m not convinced this is data enough to actually spot real trends, but might be mostly random coincidences.
98 flaws out of 6,682
The curl changelog counts a total of 6,682 bug-fixes at the time of this writing. It makes the share of all vulnerabilities to be 1.46% of all known curl bugs fixed through curl’s entire life-time, starting in March 1998.
Looking at recent curl development: the last three years. Since January 1st 2018, we’ve fixed 2,311 bugs and reported 26 vulnerabilities. Out of those 26 vulnerabilities, 18 (69%) were due to C mistakes. 18 out of 2,311 is 0.78% of the bug-fixes.
We’ve not reported a single C-based vulnerability in curl since September 2019, but six others. And fixed over a thousand other bugs. (There’s another vulnerability pending announcement, a 99th one, to become public on March 31, but that is also not a C mistake.)
This is not due to lack of trying. We’re one of the few small open source projects that pays several hundred dollars for any reported and confirmed security flaw since a few years back.
The share of C based security issues in curl is an extremely small fraction of the grand total of bugs. The security flaws are however of course the most fatal and serious ones – as all bugs are certainly not equal.
But also: not all vulnerabilities are equal. Very few curl vulnerabilities have had a severity level over medium and none has been marked critical.
Unfortunately we don’t have “severity” noted for very many many of the past vulnerabilities, as we only started that practice in 2019 and I’ve spent time and effort to backtrack and fill them in for the 2018 ones, but it’s a tedious job and I probably will not update the remainder soon, if at all.
51 flaws due to C
Let’s dive in to see how they look.
Here’s a little pie chart with the five different C mistake categories that have caused the 51 vulnerabilities. The categories here are entirely my own. No surprises here really. The two by far most common C mistakes that caused vulnerabilities are reading or writing outside a buffer.
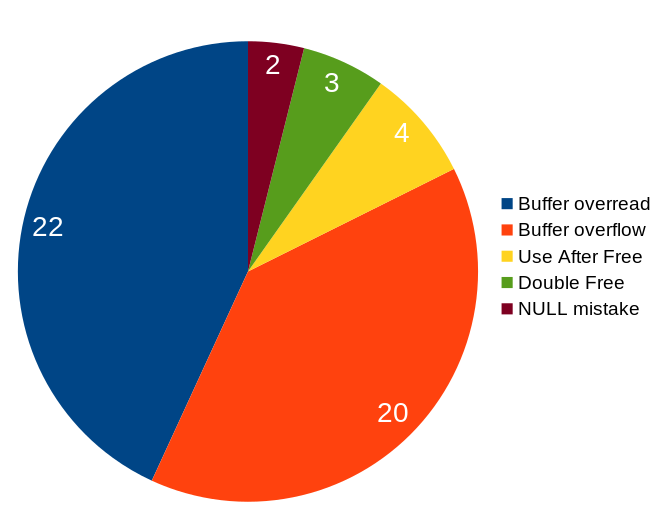
Buffer overread – reading outside the buffer size/boundary. Very often due to a previous integer overflow.
Buffer overflow – code wrote more data into a buffer than it was allocated to hold.
Use after free – code used a memory area that had already been freed.
Double free – freeing a memory pointer that had already been freed.
NULL mistakes – NULL pointer dereference and NUL byte mistake.
Addressing the causes
I’ve previously described a bunch of the counter-measures we’ve done in the project to combat some of the most common mistakes we’ve done. We continue to enforce those rules in the project.
Two of the main methods we’ve introduced that are mentioned in that post, are that we have A) created a generic dynamic buffer system in curl that we try to use everywhere now, to avoid new code that handles buffers, and B) we enforce length restrictions on virtually all input strings – to avoid risking integer overflows.
Areas
When I did the tedious job of re-analyzing every single security vulnerability anyway, I also assigned an “area” to each existing curl CVE. Which area of curl in which the problem originated or belonged. If we look at where the C related issues were found, can we spot a pattern? I think not.
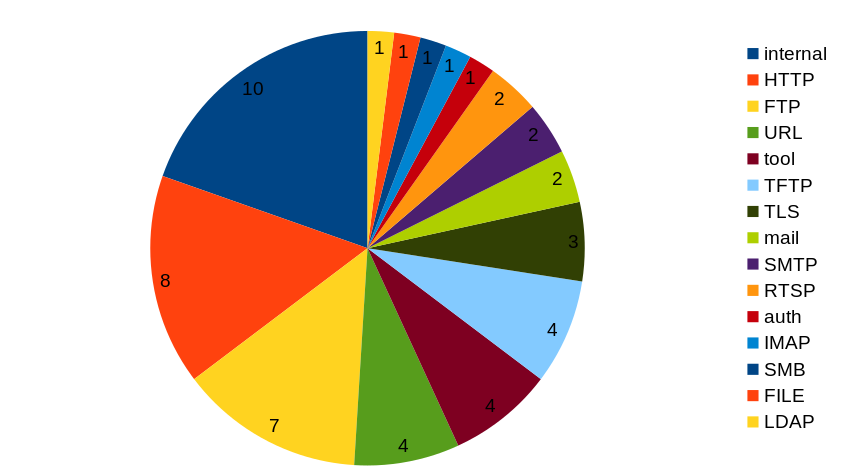
“internal” being the number one area, which means that was in generic code that affected multiple protocols or in several cases even entirely protocol independent.
HTTP was the second largest area, but that might just also reflect the fact that it is the by far most commonly used protocol in curl – and there is probably the most amount of protocol-specific code for this protocol. And there were a total of 21 vulnerabilities reported in that area, and 8 out of 21 is 38% C mistakes – way below the total average.
Otherwise I think we can conclude that the mistakes were distributed all over, rather nondiscriminatory…
C mistake history
As curl is an old project now and we have a long history to look back at, we can see how we have done in this regard throughout history. I think it shows quite clearly that age hasn’t prevented C related mistakes to slip in. Even if we are experienced C programmers and aged developers, we still let such flaws slip in. Or at least we don’t find old such mistakes that went in a long time ago – as the reported vulnerabilities in the project have usually been present in the source code for many years at the time of the finding.
The fact is that we only started to take proper and serious counter-measures against such mistakes in the last few years and while the graph below shows that we’ve improved recently, I don’t think we yet have enough data to show that this is a true trend and not just a happenstance or a temporary fluke.
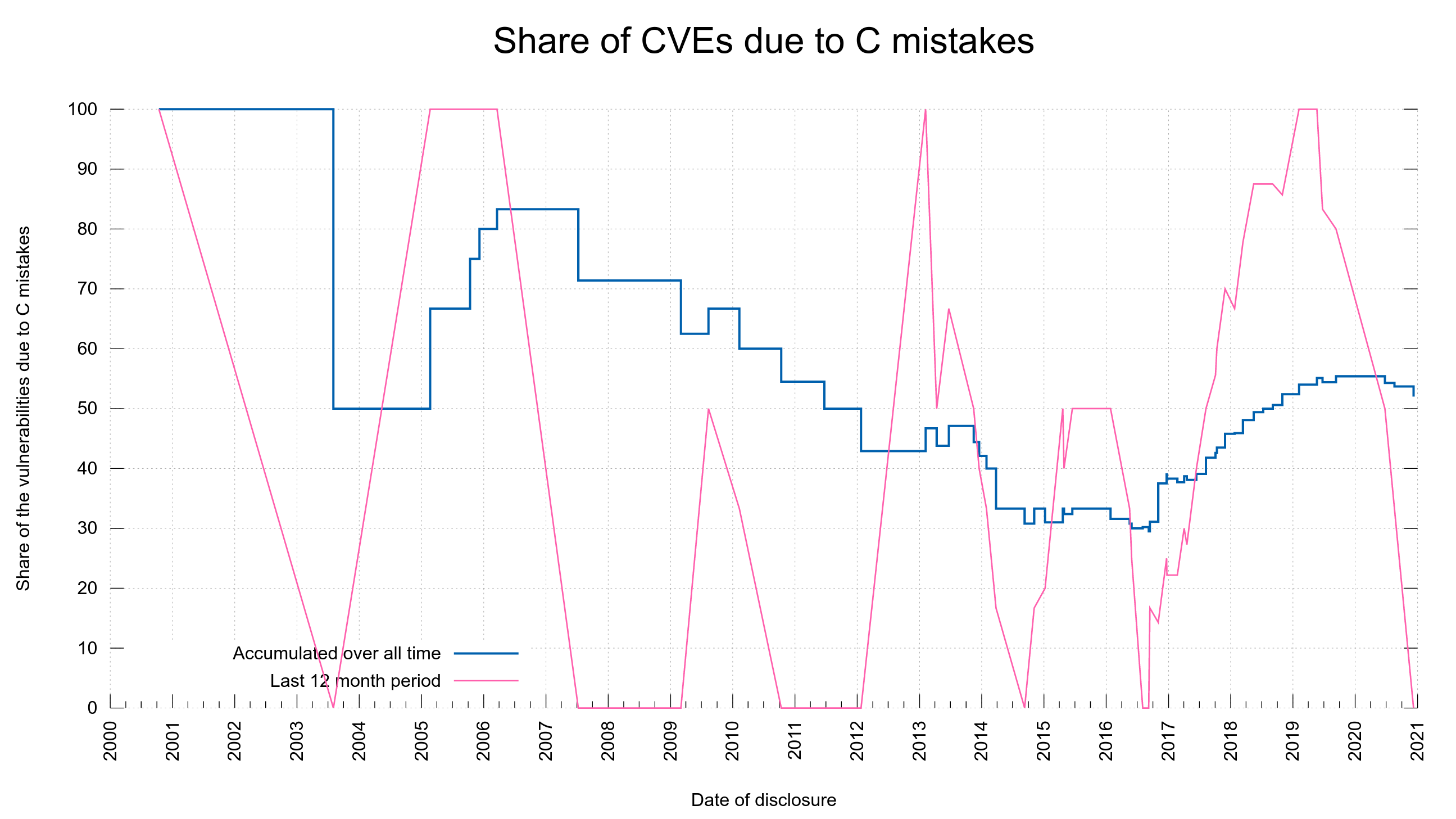
The blue line in the graph shows how big the accumulated share of all security vulnerabilities has been due to C mistakes over time. It shows we went below 50% totally in 2012, only to go above 50% again in 2018 and we haven’t come down below that again…
The red line shows the percentage share the last twelve months at that point. It illustrates that we have had several series of vulnerabilities reported over the years that were all C mistakes, and it has happened rather recently too. During the period one year back from the very last reported vulnerability, we did not have a single C mistake among them.
Finding the flaws takes a long time
C mistakes might be easier to find and detect in source code. valgrind, fuzzing, static code analyzers and sanitizers can find them. Logical problems cannot as easily be detected using tools.
I decided to check if this seems to be the case in curl and if it is true, then C mistakes should’ve lingered in the code for a shorter time until found than other mistakes.
I had a script go through the 98 existing vulnerabilities and calculating the average time the flaws were present in the code until reported, splitting out the C mistake ones from the ones not caused by C mistakes. It revealed a (small) difference:
C mistake vulnerabilities are found on average at 80% of the time other mistakes need to get found. Or put the other way around: mistakes that were not C mistakes took 25% longer to get reported – on average. I’m not convinced the difference is very significant. C mistakes are still shipped in code for 2,421 days – on average – until reported. Looking over the last 10 C mistake vulnerabilities, the average is slightly lower at 2,108 days (76% of the time the 10 most recent non C mistakes were found). Non C mistakes take 3,030 days to get reported on average.
Reproducibility
All facts I claim and provide in this blog post can be double-checked and verified using available public data and freely available scripts.
C mistake? I blame it lack of design!
What a lame comment
Lame or not, having the implementation follow a strict pattern of design that is consistent and does not lead to memory problems is indeed a solution. The issue is programmers not knowing how to properly manage memory in the first place, probably because it isn’t taught properly when everything seems to be garbage collected today practically which is a real shame as that creates many inconveniences and plenty of overhead. It’s almost like the creators of things like GC did it because they don’t trust the programmers to do their job or something. Weird, isn’t it?
It might be interesting to take your most-modern methods of finding/avoiding C mistakes that you’d use as QA tools now (e.g. static analyzers, sanitizer testsuite runs, etc), and go apply them to the code just before each of the historical C vulns were fixed, and see how many would’ve been caught early (as in, never released to production) with modern C practices like these.
Buffer overruns and overreads *should* still be much easier to prevent than other C mistakes. If the bounds are known everywhere then buffers are used, then it’s not too hard to do bounds checking.
@Alexander: I suppose that just then means that we’re not as good developers as you are.
I think the point is that buffer overflows are largely a library problem, not a language problem, per se. In Rust all interfaces doing buffer read-writes would use a Vec or variant, which actually often are implemented internally using unsafe{}. The biggest problem with C in this regard is the ecosystem. For all my own C projects I have a tried and true buffer implementation that I use, but that doesn’t help when interfacing across public APIs and projects, and so consistency suffers and bugs creep in.
( I see curl now also is beginning to use a dedicated buffer interface.)
“we have A) created a generic dynamic buffer system in curl that we try to use everywhere now, to avoid new code that handles buffers”
Can you elaborate and point to where in your source code this is implemented?
@Jay: sure!
The ‘dynbuf’ source code is here: https://github.com/curl/curl/blob/master/lib/dynbuf.c
The documentation for this internal API is here: https://github.com/curl/curl/blob/master/docs/DYNBUF.md
Thank you for this analysis!
Even though the amount of data is limited, it still represents years of development of a serious, active, widely used project.
It seems to agree with the now popular view that memory safety bugs make up a significant count of reported vulnerabilities.
I would like to be able to say that we’re getting better at catching C bugs and at dealing with the sharp edges of the language, but I’m not sure there’s a case to be made for that yet…
I would also have naively expected the share of security vs benign bugs to be higher than 1.46%, but given that curl deals with a diverse set of horribly complex protocols, maybe it’s not all that surprising that there’s a lot of non-exploitable edge cases for bugs to hide in.
So how much of C’s mistakes should attribute to Linux kernel?
never released to production) with modern C practices like these.
I don’t know why a whole language is being blamed as a culprit. A language can’t do any harm on its own, only the programmer. This could be a different story if instead it was “Rust mistakes” or something along those lines. C has dozens of flaws, and lacking in some compile-time abstractions that’d be nice, but it’s the best we have available today that does not inhibit my ability as a programmer without making my code verbose or “ugly”; even now, it’s only a means to an end because I know what the best programming language should look like, so I’m making that best programming language.
There is no mystery here. A “C mistake” is simply a bug that is enabled or encouraged by a design decision (or lack thereof) in C and would be hard to impossible to replicate in most other programming languages. This is a mistake in the *language* because it lets you write nonsense without it being rejected when it would be possible to reject it.
To some extent not all of these are necessarily problems in C the base language, but also C the ecosystem. In principle buffer overflows could be prevented by consistently using a bounds-checked buffer datatype… however, the C standard library does not provide such a type so in effect pretty much every C project eventually invents one, with incompatible APIs. So unless you are a serious subscriber to NIH as a virtue, you end up having to convert between different types of buffers all over the place which again is a frequent source of errors (not to mention inefficient as this will usually involve copying the data unnecessarily).
More than half of online fraud is due to English lies. Let’s ban English!
are not all these problems
* Buffer overread
* Buffer overflow
* Use after free
* Double free
* NULL mistakes
exactly the kind of problems various sanitisers should catch?
And if they are, but sanitisers do not catch them, it would be
@Harald: they’re all problems such tools could find but clearly none did (at the time).
Yes and no. That’s what they’re meant to do. However, developing a suit of compiler warnings or sanitizer or static analyzer that can reliably catch these bugs in C code bases in general is known to be theoretically impossible. All current such tools also have known gaping holes that are known to let 100% of large subsets of bugs through while they are known to catch <100% of all bugs in the subsets of bugs they can catch. By combining multiple tools, you can reduce the fraction of bugs you miss, but it is still an open question how effective such a combination actually is in practice. We do know that it is not 100% effective, since many such bugs are found in real world code bases that went through all of them without warnings.