
In my view, wget is not a curl competitor. It is a companion tool that has a feature overlap with curl.
Use the tool that does the job.
Getting the job done is the key. If that means using wget instead of curl, then that is good and I don’t mind. Why would I?
To illustrate the technical differences (and some similarities) between curl and wget, I made the following Venn diagram. Click the image to get the full resolution version.
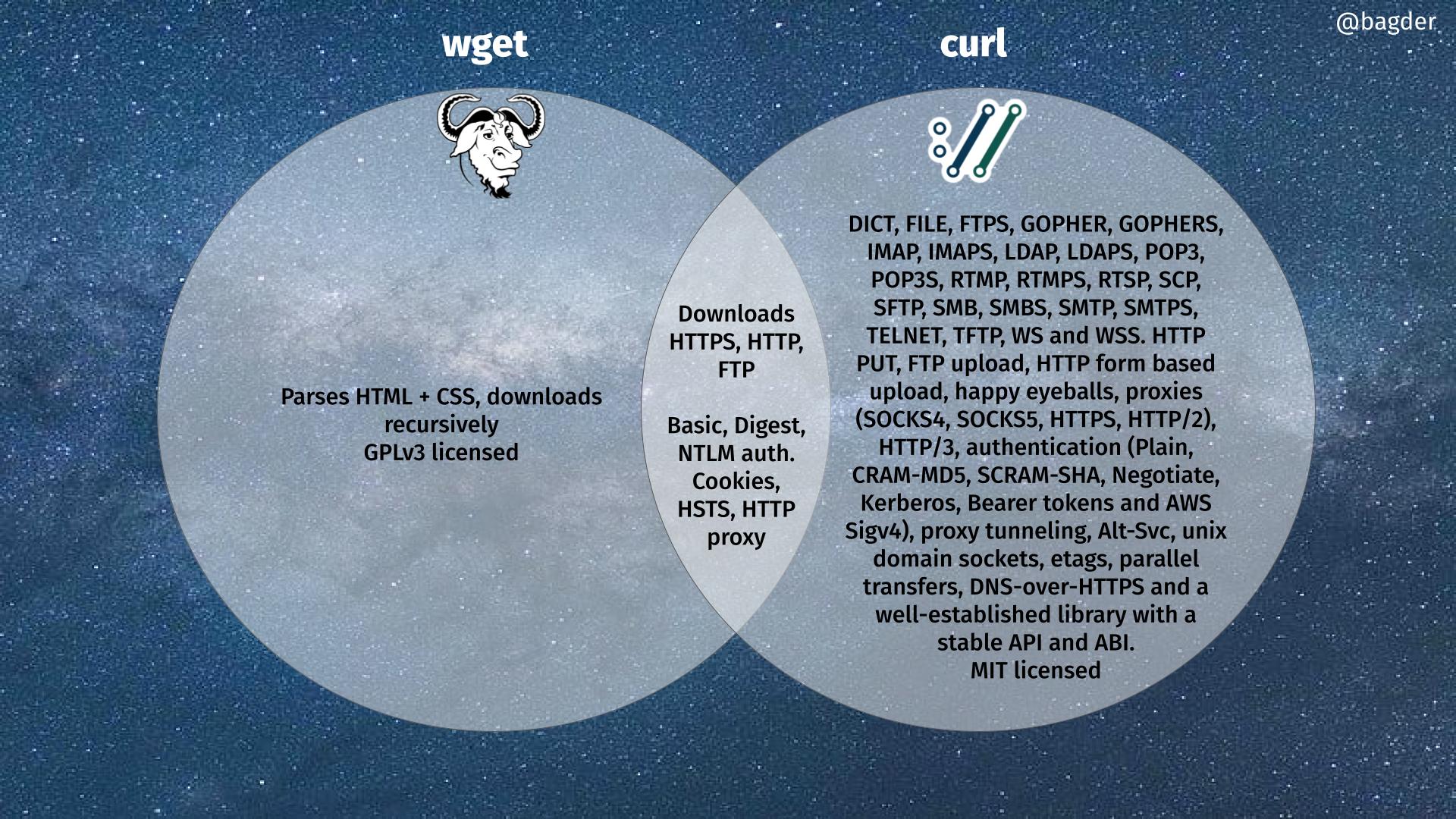
I have contributed code to wget. Several wget maintainers have contributed to curl. We are all friends.
If you think there is a problem or omission in the diagram, let me know and I can do updates.
Wget can also automatically decode URI-encoded filenames. Kinda surprised that you still can’t do that with Curl, but I also understand that Curl isn’t always meant to write files to disc anyway.
@Gareth: Are you talking about names in Content-Disposition: headers or where are these filenames it decodes?
I mean, filenames in the URLs that the tool defaults to if given the -O option.
As an example URL:
https://example.com/Alice%20and%20Bob%27s%20Holiday%Photos%20%282019%29.zip
Curl with -O would write it to the filesystem as “Alice%20and%20Bob%27s%20Holiday%20Photos%20%282019%29.zip”, but Wget would write it as “Alice and Bob’s Holiday Photos (2019).zip”.
@Gareth: ah right: curl would not do that for -O since that would violate what the option is made for and how it is documented. It would break (many) existing scripts.
We could of course introduce a new option for doing this with curl. If someone would provide the code.
@Daniel I get the part about breaking existing scripts – it would wreak havoc with our own CI for some things. But what do you mean by it would violate what the option was made for? So far as I can see in the man page, it’s just an implementation note that this doesn’t decode uri components (i.e. it looks to me like it *could have* done that and still worked for what it was made for, it just didn’t).
@Mahmoud: if we had implemented it like that from the beginning, it certainly could have done that sure. I was thinking of it in terms of if we would add that feature today.
Hi Daniel, I saw this comment thread and added the feature to decode the filename before writing similar to wget’s behavior. Thus option -W seemed fitting and was available.
so it can be used exactly like -O and -J:
curl -W https://www.example.com/new%20pricing.htm
writes file -> ‘new pricing.htm’
curl -WJ http://test.greenbytes.de/tech/tc2231/attwithfnrawpctenca.asis
writes file -> foo-A.html
curl –remote-name-decode-all https://www.example.com/new%20pricing.htm http://test.greenbytes.de/tech/tc2231/attwithfnrawpctenca.asis
writes files -> ‘new pricing.htm’ and attwithfnrawpctenca.asis
curl –remote-name-decode-all -J https://www.example.com/new%20pricing.htm http://test.greenbytes.de/tech/tc2231/attwithfnrawpctenca.asis
writes files -> ‘new pricing.htm’ and foo-A.html
I have the changes in feature/remote-name-decoded branch here:
https://github.com/magks/curl/tree/feature/remote-name-decoded
I tried to keep changes as minimal and simple as possible and used the lib/escape.h Curl_urldecode function, however because of this, the linker can only find the symbol when I pass the –disable-symbol-hiding.
I wanted to discuss with you what approach you’d recommend taking to include the function from escape.h in tool_operhlp and tool_cb_wrt.
I manually tested thoroughly but still need to add unit tests.
Hey, not sure why my comment appeared all as one line. moved it to gist:
https://gist.github.com/magks/f0a566caba74fd08036a94f90b6f67a1
I use curl and wget often and am a great fan of both tools.
For me the one place where “wget ” is my preferred command is downloading a single file large enough (or binary) so I do not want to view the file on the command line immediately.
The reasons may be default settings differences or my perceptions only. Are the below correct? Thank you!
1. By default wget writes output to a file rather than stdout. With curl I can use -O to achieve the same thing.
2. With wget the download is by default retried and resumed up to 20 times according to the man page for –tries option. I have seen and been happy this retry works by default in wget. With curl I think the default for –retry is 0?
It would be good to implement curl –wget file and then do what wget does.
@Daniel I think it’s a wonderful resource but might be much more readable as a table. Also, I love the sentiment you express with “I have contributed code to wget. Several wget maintainers have contributed to curl. We are all friends.”
They are the same picture.
One thing wget can do that curl does not, is create WARC archives. I find this extremely useful in combination with things like warcprox, but even without that, it allows to record and archive an entire (set of) requests and responses including timings and headers.