

In a recent educational trick, curl contributor James Fuller submitted a pull-request to the project in which he suggested a larger cleanup of a set of scripts.
In a later presentation, he could show us how not a single human reviewer in the team nor any CI job had spotted or remarked on one of the changes he included: he replaced an ASCII letter with a Unicode alternative in a URL.
This was an eye-opener to several of us and we decided we needed to up our game. We are the curl project. We can do better.
GitHub
The replacement symbol looked identical to the ASCII version so it was not possible to visually spot this, but the diff viewer knows there is a difference.
In this GitHub website screenshot below I reproduced a similar case. The right-side version has the Latin letter ‘g’ replaced with the Armenian letter co. They appear to be the same.
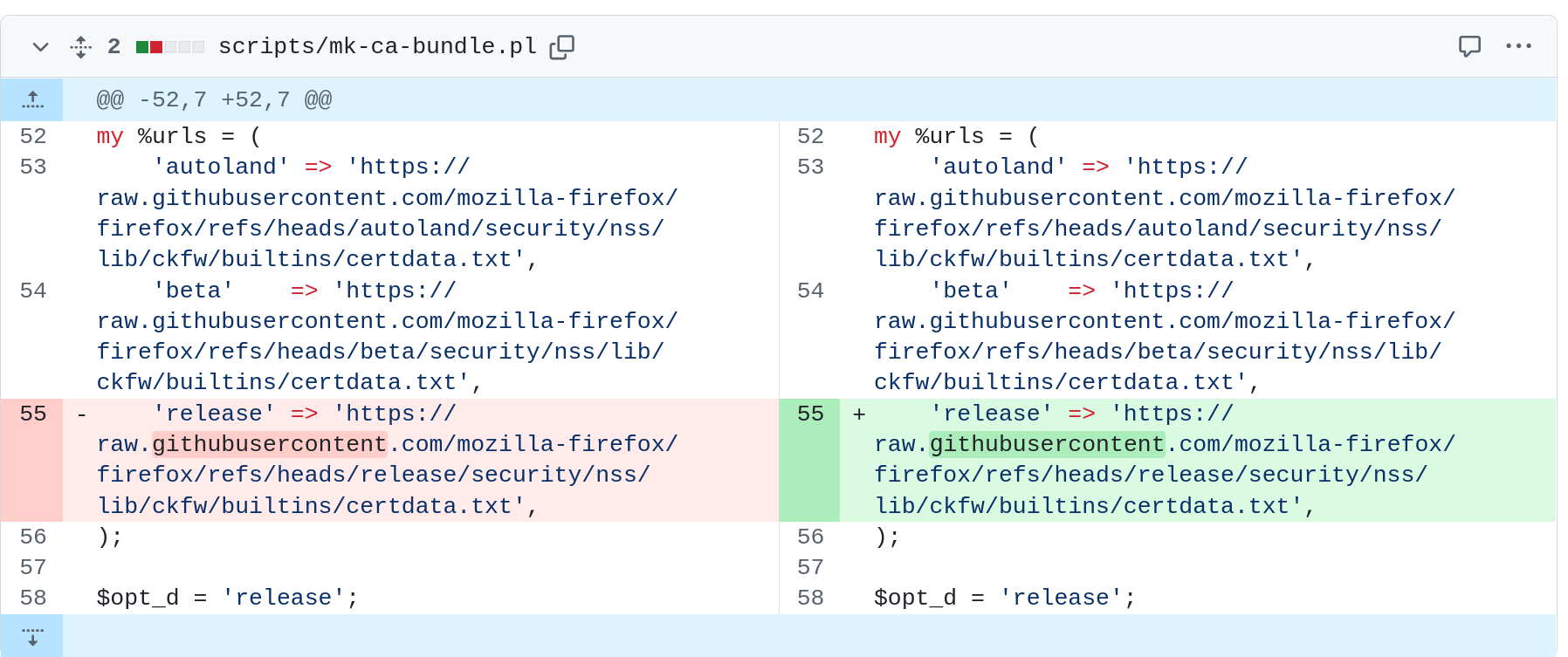
The diff viewer says there is a difference but as a human it isn’t possible to detect what it is. Is it a flaw? Does it matter? If done “correctly”, it would be done together with a real and expected fix.
The impact of changing one or more letters in a URL can of course be devastating depending on conditions.
When I flagged about this rather big omission to GitHub people, I got barely no responses at all and I get the feeling the impact of this flaw is not understood and acknowledged. Or perhaps they are all just too busy implementing the next AI feature we don’t want.
Warnings
When we discussed this problem on Mastodon earlier this week, Viktor Szakats provided me with an example screenshot of doing a similar stunt with Gitea which quite helpfully highlights that there is something special about the replacement:
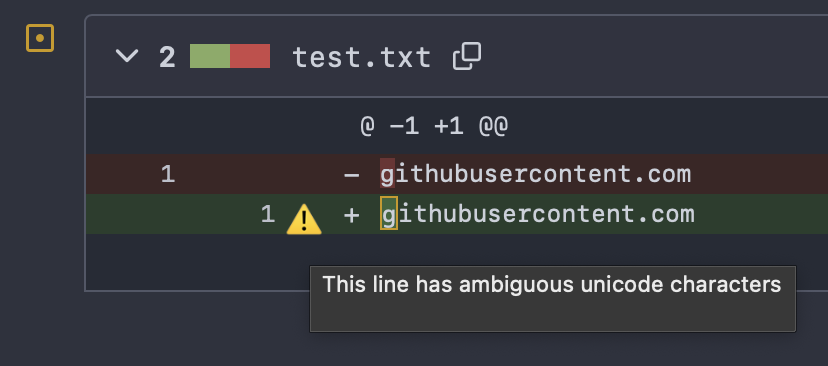
I have been told that some of the other source code hosting services also show similar warnings.
As a user, I would actually like to know even more than this, but at least this warns about the proposed change clearly enough so that if this happens I would get the code manually and investigate before accepting such a change.
Detect
While we wait for GitHub to wake up and react (which I have no expectation will actually happen anytime soon), we have implemented checks to help us poor humans spot things like this. To detect malicious Unicode.
We have added a CI job that scans all files and validates every UTF-8 sequence in the git repository.
In the curl git repository most files and most content are plain old ASCII so we can “easily” whitelist a small set of UTF-8 sequences and some specific files, the rest of the files are simply not allowed to use UTF-8 at all as they will then fail the CI job and turn up red.
In order to drive this change home, we went through all the test files in the curl repository and made sure that all the UTF-8 occurrences were instead replaced by other kind of escape sequences and similar. Some of them were also used more or less by mistake and could easily be replaced by their ASCII counterparts.
The next time someone tries this stunt on us it could be someone with less good intentions, but now ideally our CI will tell us.
Confusables
There are plenty of tools to find similar-looking characters in different Unicode sets. One of them is provided by the Unicode consortium themselves:
https://util.unicode.org/UnicodeJsps/confusables.jsp
Reactive
This was yet another security-related fix reacting on a demonstrated problem. I am sure there are plenty more problems which we have not yet thought about nor been shown and therefore we do not have adequate means to detect and act on automatically.
We want and strive to be proactive and tighten everything before malicious people exploit some weakness somewhere but security remains this never-ending race where we can only do the best we can and while the other side is working in silence and might at some future point attack us in new creative ways we had not anticipated.
That future unknown attack is a tricky thing.
Update
(At 17:30 on the same day of the original post) GitHub has told me they have raised this as a security issue internally and they are working on a fix.
GitHub just started to warn about hidden Unicode characters.
https://github.blog/changelog/2025-05-01-github-now-provides-a-warning-about-hidden-unicode-text/
@Christian: yes they did, but that doesn’t help us here…
I’d really like each code editor / viewer to highlight non 7bit ascii.
About 15 years ago, I was affraid of similar thing. Not because security, but because possible mojibake. I was affraid that the same text file will cause havock when interpreted as cp1250 by one program and when interpret as cp437 or as UTF-8 by another program. One of the programs would be the compiler, other night be version control system or my text editor. I set my text editor (jEdit) to accept 7bit ASCII only in order to detect this. Happily the only thing it ever detected was … (three dots) vs … (unicode ellipsis) in code comments caused by Mac coworkers (I used Windows).
“allowlist” ?
I wonder how many open source projects got hacked this way.
It is good to detect such things but in the case of domain names I think they are already restricted by charset so while curl would attempt to get it, no one could register it.
There are no such charset restrictions with IDN domain names, see https://en.wikipedia.org/wiki/IDN_homograph_attack for further reading.
It is indeed by some registries only. Should definitely have been at the IDN level IMHO.
JetBrains has a team tool called Qodana that brings all its inspections to the CI pipeline with some other features. It has a NonAsciiCharacters inspection.
For details on how to handle these issues, see [UTS #55 Unicode Source Code Handling](https://www.unicode.org/reports/tr55/#Confusability).
Probably not useful other as a possibly a reference or to test with. But Linus at Mullvad has developed a tool for this inspired by the result of a pentest we performed.
https://crates.io/crates/unicop
I have a little tidbit to tell. I remember writing a trojan in the years of Windows XP. At that time windows was firing a lot of processes “svhost.exe” which could not be killed – a process required for Windows to function (it was located in System32). So I came up with the idea that my Trojan should also copy itself there and also have such a name. Then I replaced the “o” with the Greek “omicron” (U+03BF) in its name. That way this Trojan was quite thoughtfully installed (I also gave it a system file flag :D). Ahh, those were beautiful times 🙂