
In the standard libc API set there are multiple functions provided that do ASCII numbers to integer conversions.
They are handy and easy to use, but also error-prone and quite lenient in what they accept and silently just swallow.
atoi
atoi() is perhaps the most common and basic one. It converts from a string to signed integer. There is also the companion atol() which instead converts to a long.
Some problems these have include that they return 0 instead of an error, that they have no checks for under or overflow and in the atol() case there’s this challenge that long has different sizes on different platforms. So neither of them can reliably be used for 64-bit numbers. They also don’t say where the number ended.
Using these functions opens up your parser to not detect and handle errors or weird input. We write better and stricter parser when we avoid these functions.
strtol
This function, along with its siblings strtoul() and strtoll() etc, is more capable. They have overflow detection and they can detect errors – like if there is no digit at all to parse.
However, these functions as well too happily swallow leading whitespace and they allow a + or – in front of the number. The long versions of these functions have the problem that long is not universally 64-bit and the long long version has the problem that it is not universally available.
The overflow and underflow detection with these function is quite quirky, involves errno and forces us to spend multiple extra lines of conditions on every invoke just to be sure we catch those.
curl code
I think we in the curl project as well as more or less the entire world has learned through the years that it is usually better to be strict when parsing protocols and data, rather than be lenient and try to accept many things and guess what it otherwise maybe meant.
As a direct result of this we make sure that curl parses and interprets data exactly as that data is meant to look and we error out as soon as we detect the data to be wrong. For security and for solid functionality, providing syntactically incorrect data is not accepted.
This also implies that all number parsing has to be exact, handle overflows and maximum allowed values correctly and conveniently and errors must be detected. It always supports up to 64-bit numbers.
strparse
I have previously blogged about how we have implemented our own set of parsing function in curl, and these also include number parsing.
curlx_str_number() is the most commonly used of the ones we have created. It parses a string and stores the value in a 64-bit variable (which in curl code is always present and always 64-bit). It also has a max value argument so that it returns error if too large. And it of course also errors out on overflows etc.
This function of ours does not allow any leading whitespace and certainly no prefixing pluses or minuses. If they should be allowed, the surrounding parsing code needs to explicitly allow them.
The curlx_str_number function is most probably a little slower that the functions it replaces, but I don’t think the difference is huge and the convenience and the added strictness is much welcomed. We write better code and parsers this way. More secure. (curlx_str number source code)
History
As of yesterday, November 12 2025 all of those weak functions calls have been wiped out from the curl source code. The drop seen in early 2025 was when we got rid of all strtrol() variations. Yesterday we finally got rid of the last atoi() calls.
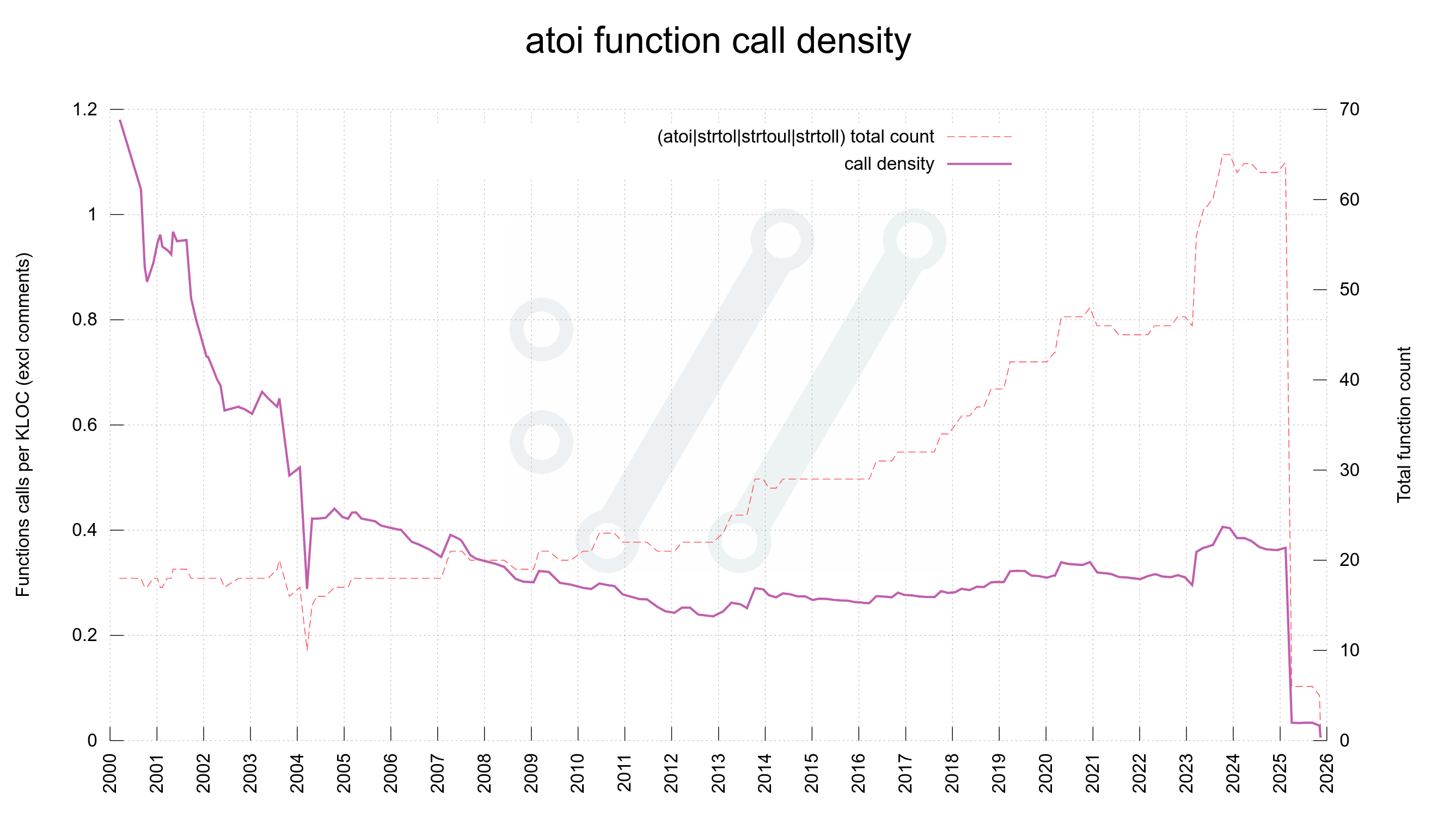
(Daily updated version of the graph.)
curlx
The function mentioned above uses a ‘curlx’ prefix. We use this prefix in curl code for functions that exist in libcurl source code but that be used by the curl tool as well – sharing the same code without them being offered by the libcurl API.
A thing we do to reduce code duplication and share code between the library and the command line tool.

