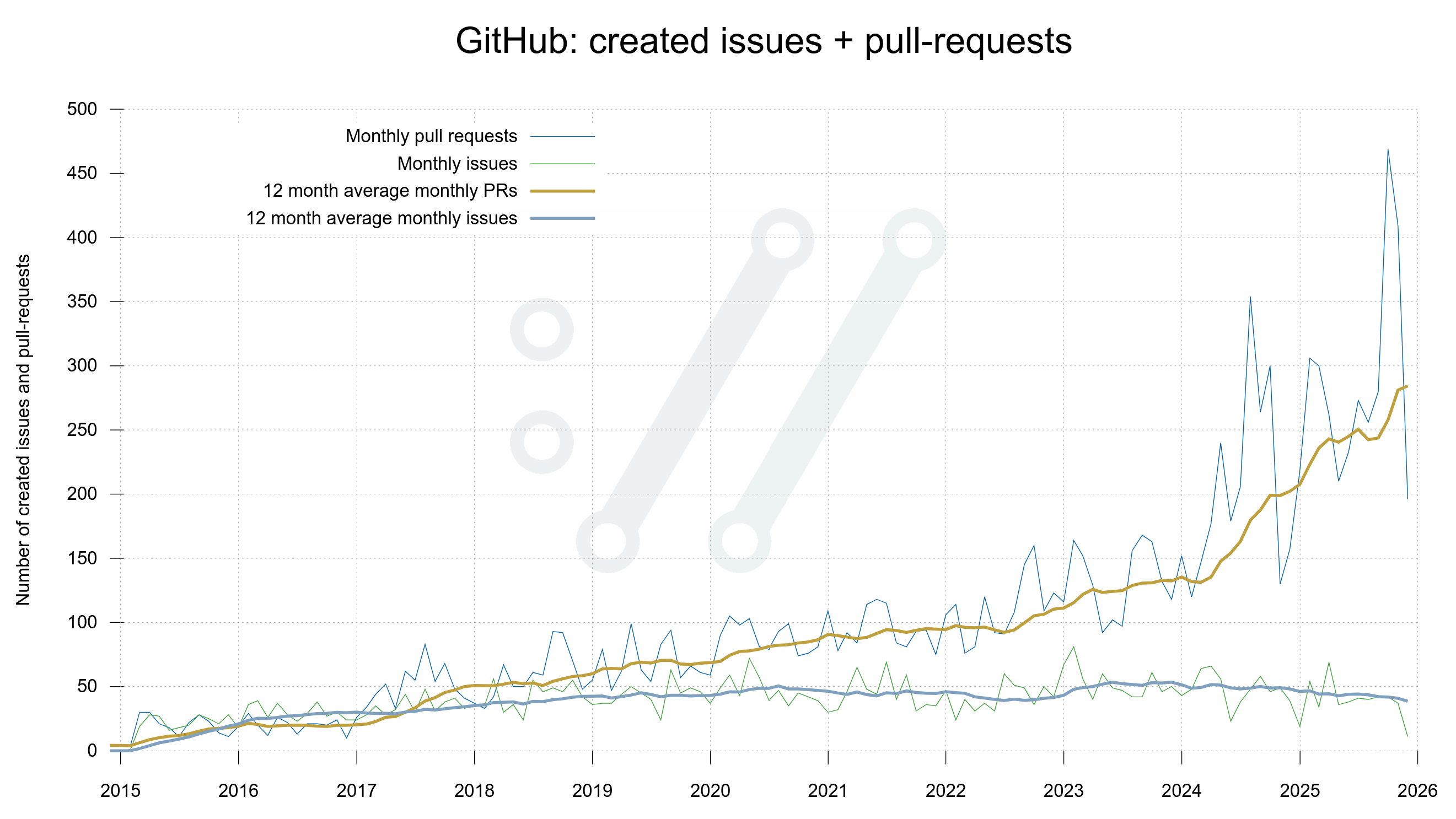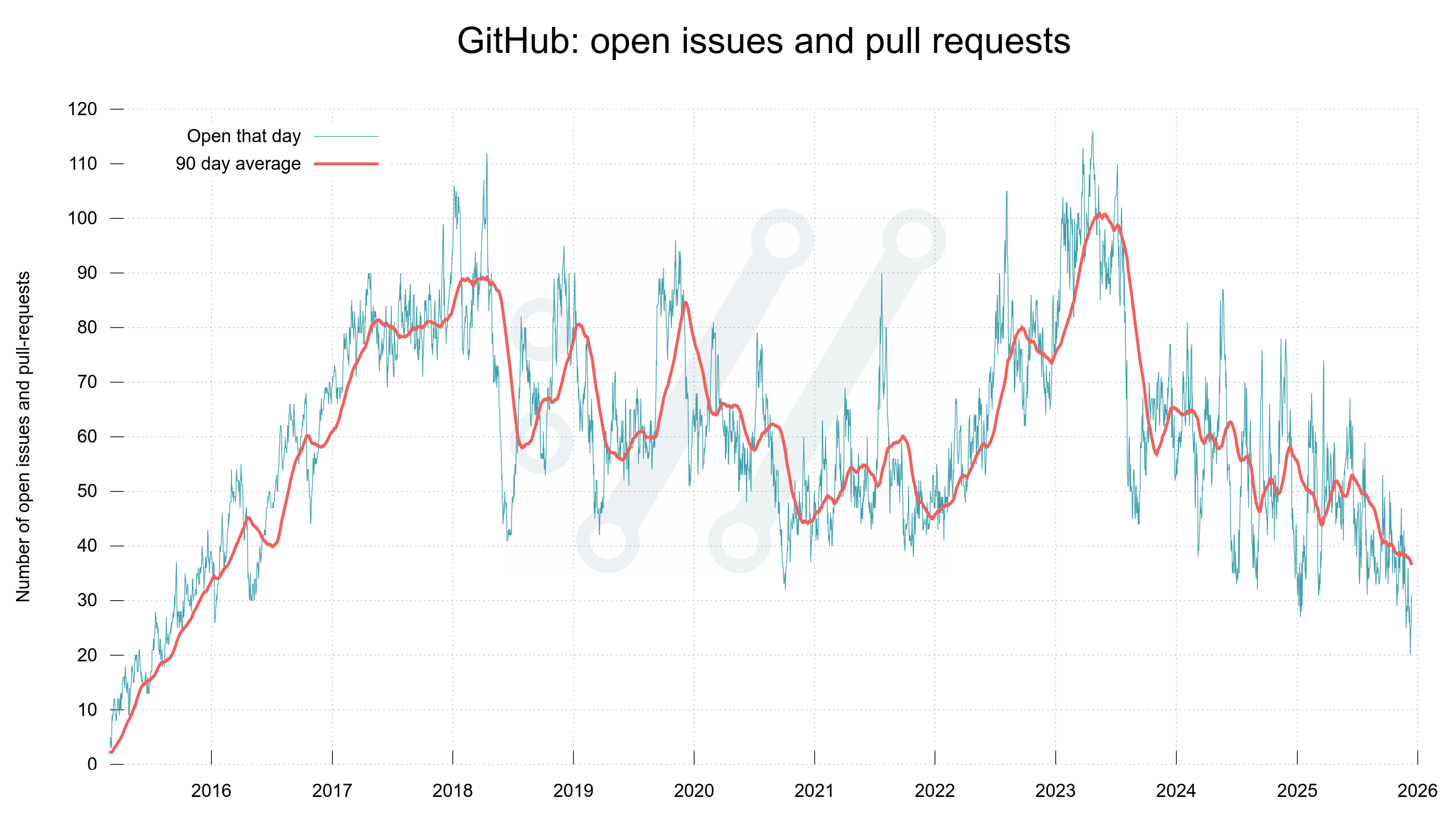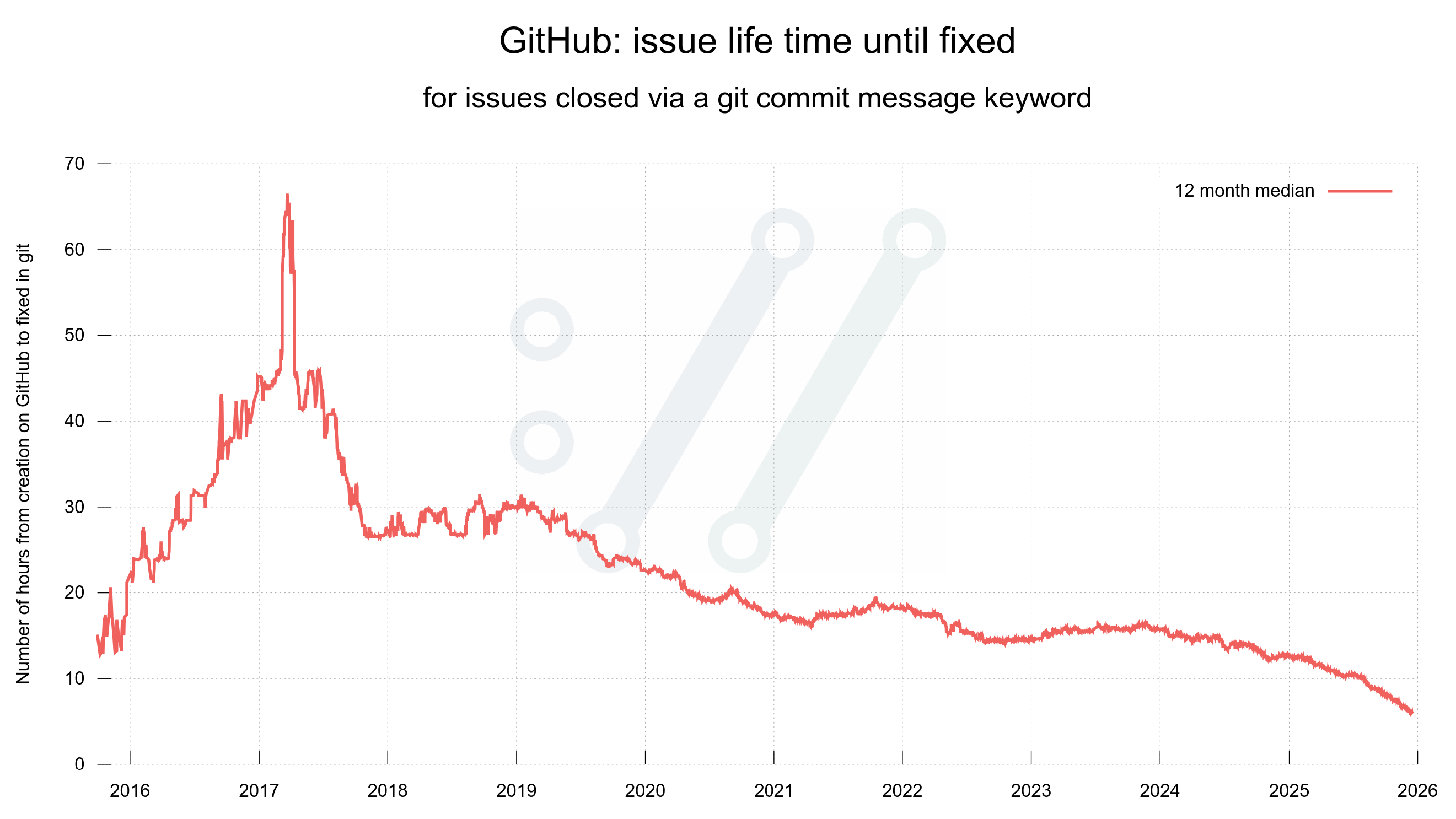
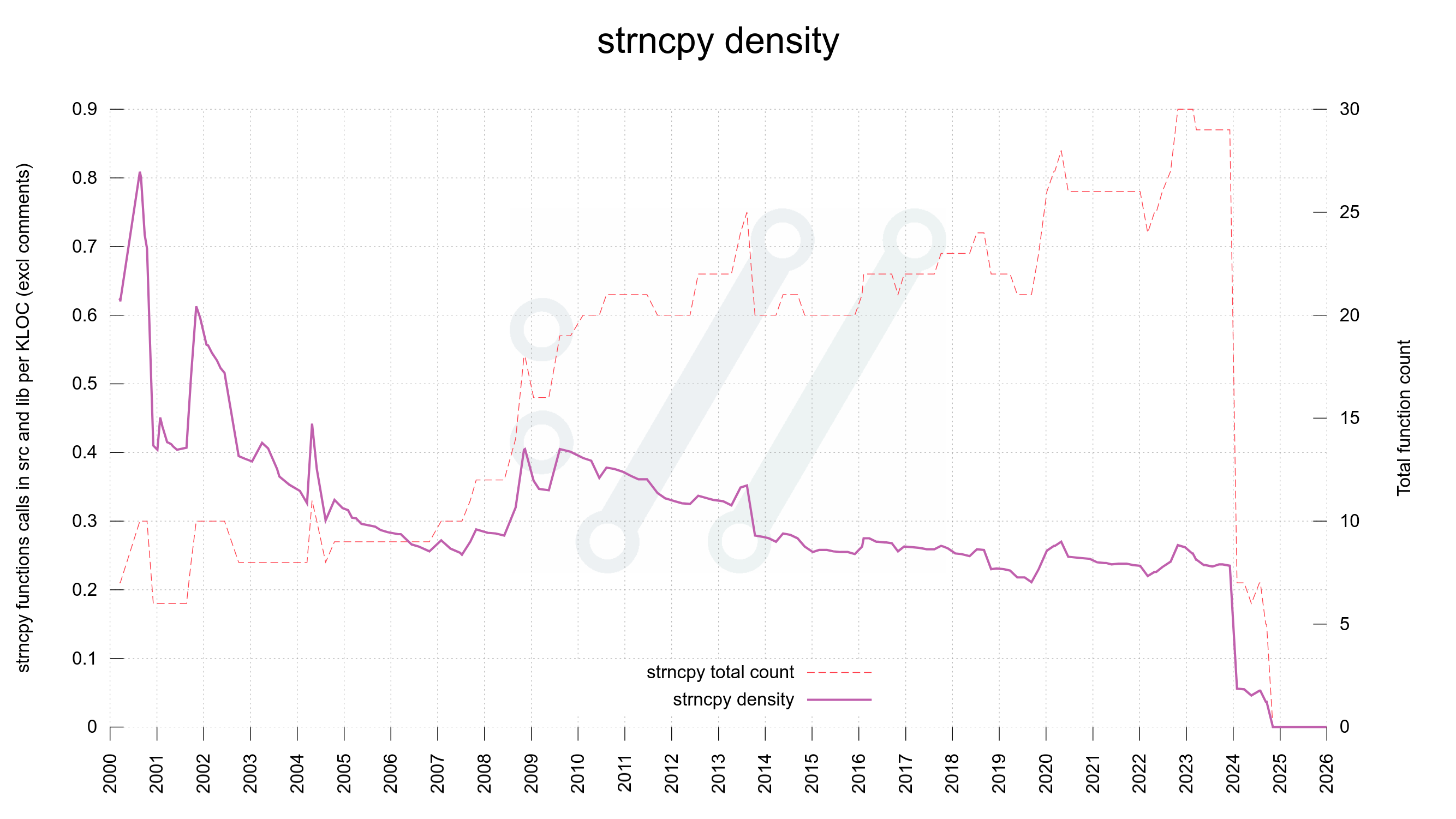
Some time ago I mentioned that we went through the curl source code and eventually got rid of all strncpy() calls.
strncpy() is a weird function with a crappy API. It might not null terminate the destination and it pads the target buffer with zeroes. Quite frankly, most code bases are probably better off completely avoiding it because each use of it is a potential mistake.
In that particular rewrite when we made strncpy calls extinct, we made sure we would either copy the full string properly or return error. It is rare that copying a partial string is the right choice, and if it is, we can just as well memcpy it and handle the null terminator explicitly. This meant no case for using strlcpy or anything such either.
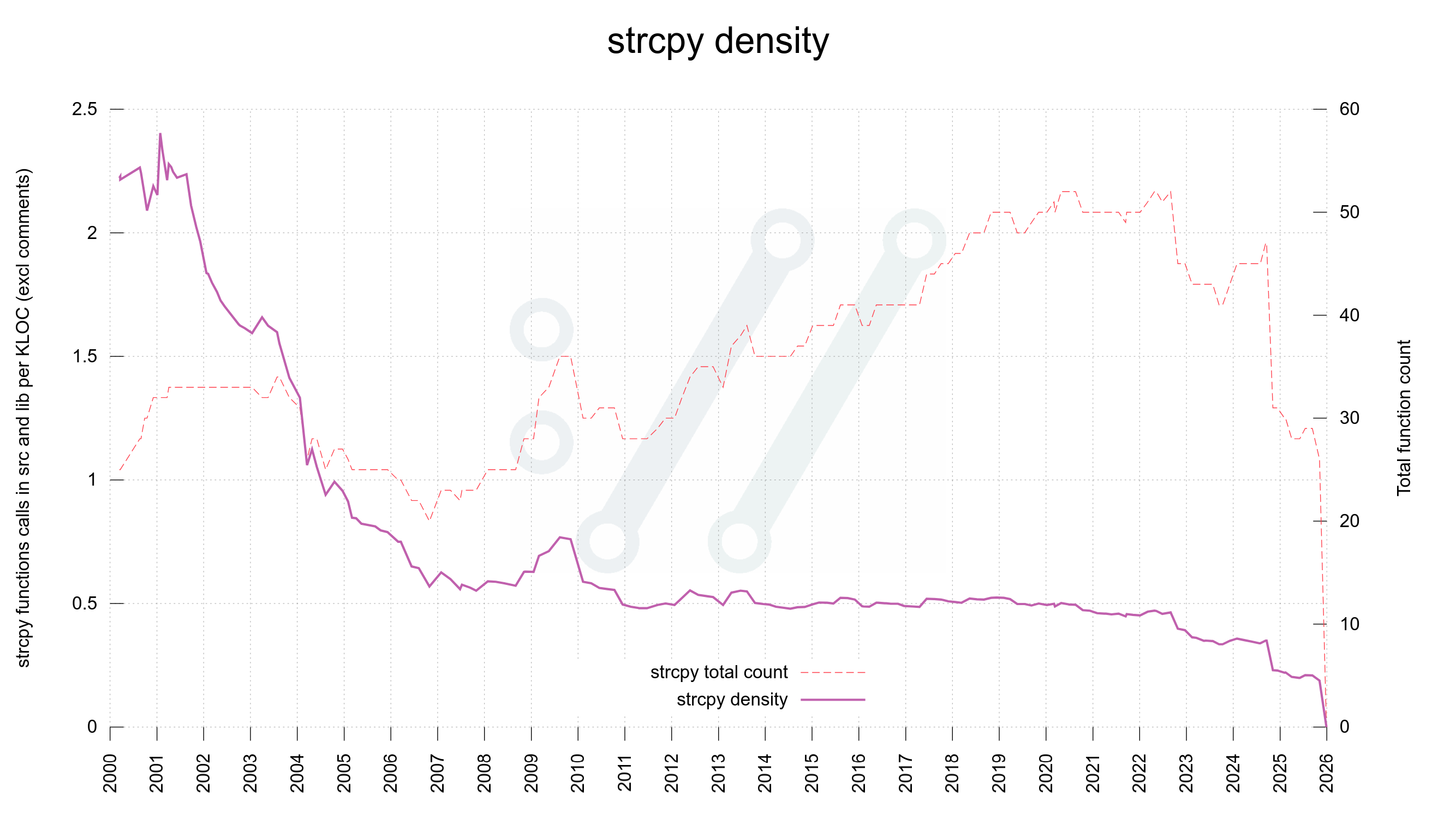
But strcpy?
strcpy however, has its valid uses and it has a less bad and confusing API. The main challenge with strcpy is that when using it we do not specify the length of the target buffer nor of the source string.
This is normally not a problem because in a C program strcpy should only be used when we have full control of both.
But normally and always are not necessarily the same thing. We are but all human and we all do mistakes. Using strcpy implies that there is at least one or maybe two, buffer size checks done prior to the function invocation. In a good situation.
Over time however – let’s imagine we have code that lives on for decades – when code is maintained, patched, improved and polished by many different authors with different mindsets and approaches, those size checks and the function invoke may glide apart. The further away from each other they go, the bigger is the risk that something happens in between that nullifies one of the checks or changes the conditions for the strcpy.
Enforce checks close to code
To make sure that the size checks cannot be separated from the copy itself we introduced a string copy replacement function the other day that takes the target buffer, target size, source buffer and source string length as arguments and only if the copy can be made and the null terminator also fits there, the operation is done.
This made it possible to implement the replacement using memcpy(). Now we can completely ban the use of strcpy in curl source code, like we already did strncpy.
Using this function version is a little more work and more cumbersome than strcpy since it needs more information, but we believe the upsides of this approach will help us have an oversight for the extra pain involved. I suppose we will see how that will fare down the road. Let’s come back in a decade and see how things developed!
void curlx_strcopy(char *dest,
size_t dsize,
const char *src,
size_t slen)
{
DEBUGASSERT(slen < dsize);
if(slen < dsize) {
memcpy(dest, src, slen);
dest[slen] = 0;
}
else if(dsize)
dest[0] = 0;
}
AI slop
An additional minor positive side-effect of this change is of course that this should effectively prevent the AI chatbots to report strcpy uses in curl source code and insist it is insecure if anyone would ask (as people still apparently do). It has been proven numerous times already that strcpy in source code is like a honey pot for generating hallucinated vulnerability claims.
Still, this will just make them find something else to make up a report about, so there is probably no net gain. AI slop is not a game we can win.