
 I decided to look closer at security problems and the age of the reported issues in the curl project.
I decided to look closer at security problems and the age of the reported issues in the curl project.
One theory I had when I started to collect this data, was that we actually get security problems reported earlier and earlier over time. That bugs would be around in public release for shorter periods of time nowadays than what they did in the past.
My thinking would go like this: Logically, bugs that have been around for a long time have had a long time to get caught. The more eyes we’ve had on the code, the fewer old bugs should be left and going forward we should more often catch more recently added bugs.
The time from a bug’s introduction into the code until the day we get a security report about it, should logically decrease over time.
What if it doesn’t?
First, let’s take a look at the data at hand. In the curl project we have so far reported in total 68 security problems over the project’s life time. The first 4 were not recorded correctly so I’ll discard them from my data here, leaving 64 issues to check out.
The graph below shows the time distribution. The all time leader so far is the issue reported to us on March 10 this year (2017), which was present in the code since the version 6.5 release done on March 13 2000. 6,206 days, just three days away from 17 whole years.
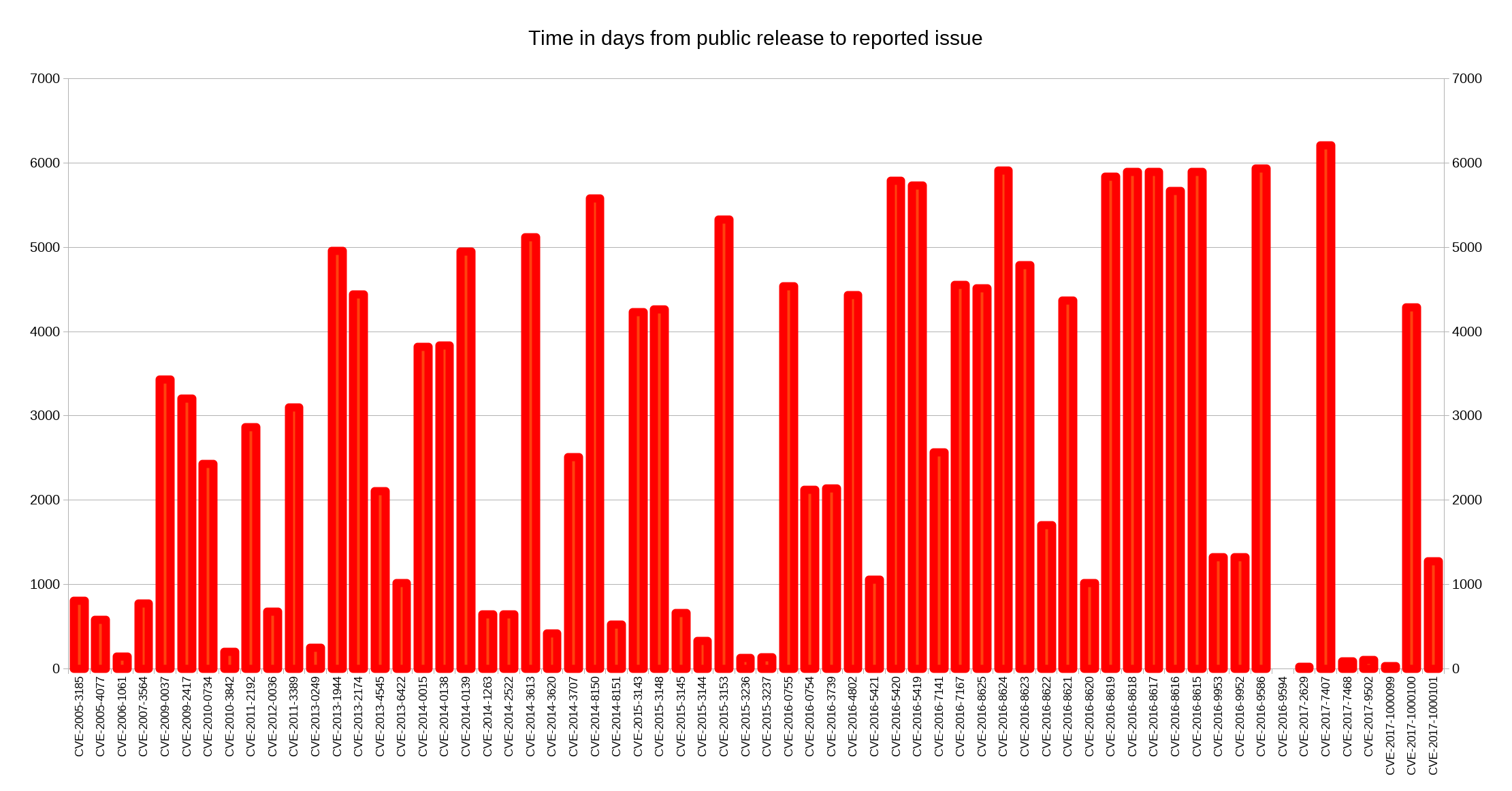
There are no less than twelve additional issues that lingered from more than 5,000 days until reported. Only 20 (31%) of the reported issues had been public for less than 1,000 days. The fastest report was reported on the release day: 0 days.
The median time from release to report is a whopping 2541 days.
When we receive a report about a security problem, we want the issue fixed, responsibly announced to the world and ship a new release where the problem is gone. The median time to go through this procedure is 26.5 days, and the distribution looks like this:
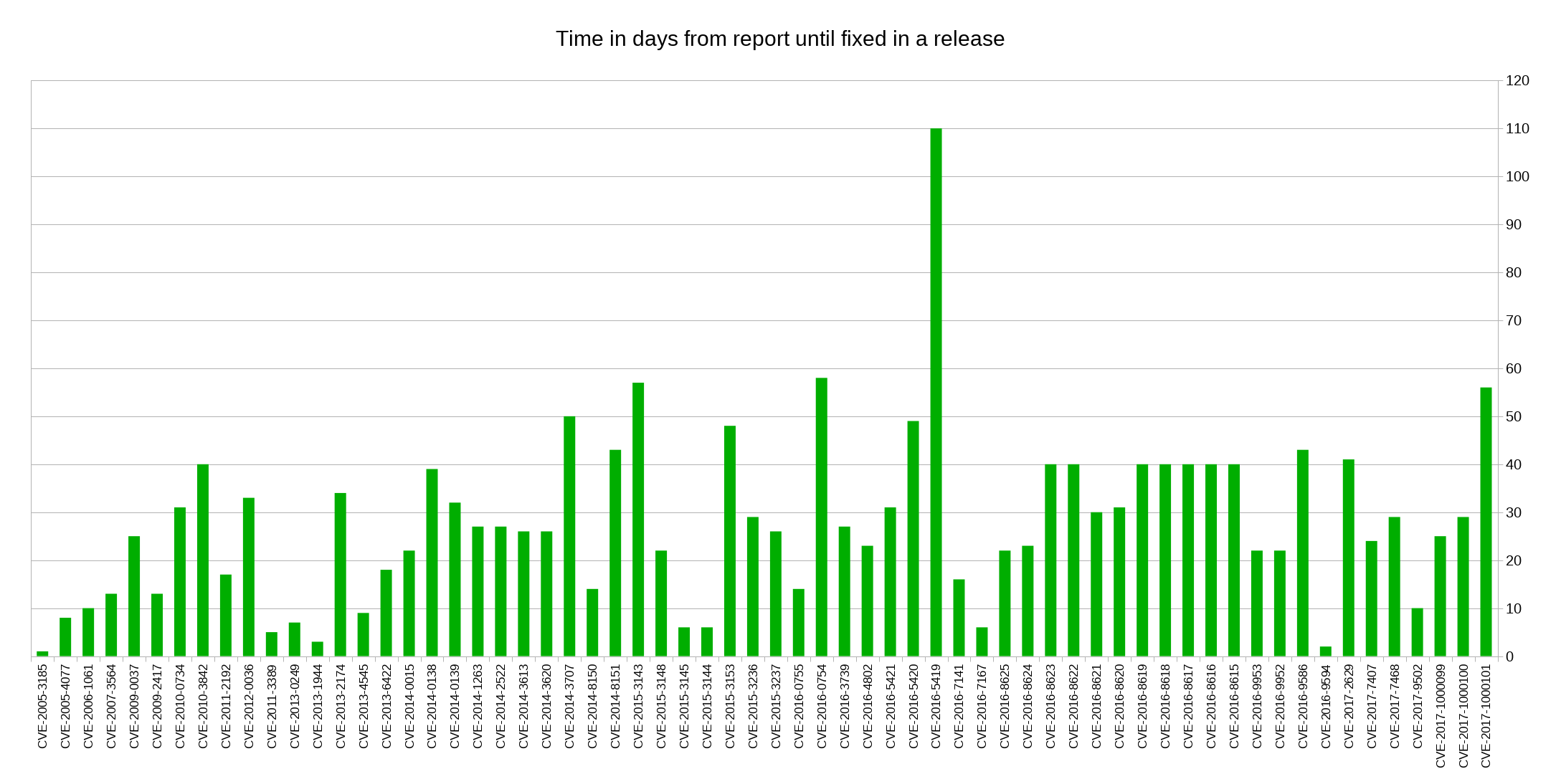
What stands out here is the TLS session resumption bypass, which happened because we struggled with understanding it and how to address it properly. Otherwise the numbers look all reasonable to me as we typically do releases at least once every 8 weeks. We rarely ship a release with a known security issue outstanding.
Why are very old issues still found?
I think partly because the tools are gradually improving that aid people these days to find things much better, things that simply wasn’t found very often before. With new tools we can find problems that have been around for a long time.
Every year, the age of the oldest parts of the code get one year older. So the older the project gets, the older bugs can be found, while in the early days there was a smaller share of the code that was really old (if any at all).
What if we instead count age as a percentage of the project’s life time? Using this formula, a bug found at day 100 that was added at day 50 would be 50% but if it was added at day 80 it would be 20%. Maybe this would show a graph where the bars are shrinking over time?
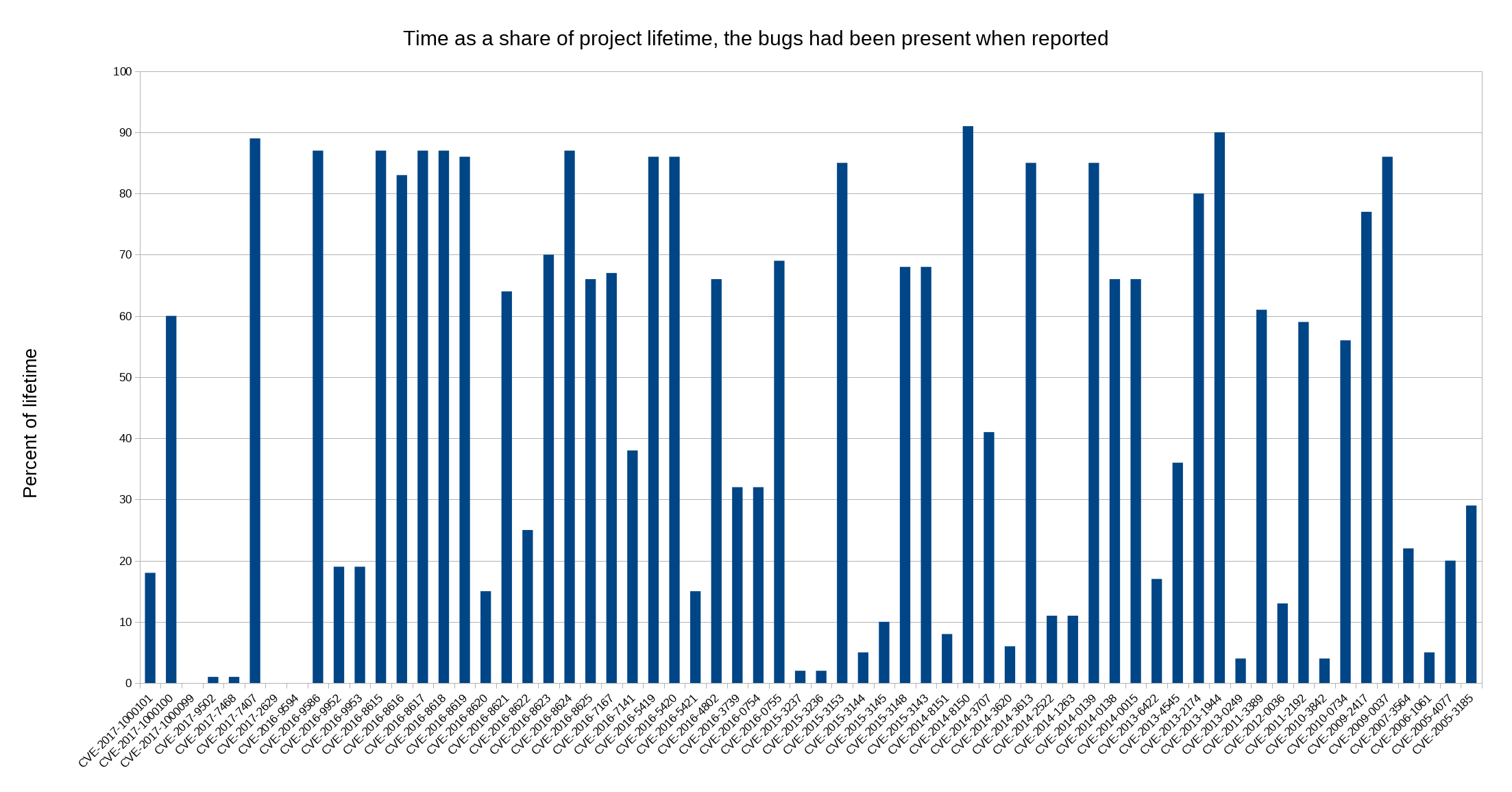
But no. In fact it shows 17 (27%) of them having been present during 80% or more of the project’s life time! The median issue had been in there during 49% of the project’s life time!
It does however make another issue the worst offender, as one of the issues had been around during 91% of the project’s life time.
This counts on March 20 1998 being the birth day. Of course we got no reports the first few years since we basically had no users then!
Specific or generic?
Is this pattern something that is specific for the curl project or can we find it in other projects too? I don’t know. I have not seen this kind of data being presented by others and I don’t have the same insight on such details of projects with an enough amount of issues to be interesting.
What can we do to make the bars shrink?
Well, if there are old bugs left to find they won’t shrink, because for every such old security issue that’s still left there will be a tall bar. Hopefully though, by doing more tests, using more tools regularly (fuzzers, analyzers etc) and with more eyeballs on the code, we should iron out our security issues over time. Logically that should lead to a project where newly added security problems are detected sooner rather than later. We just don’t seem to be at that point yet…
Caveat
One fact that skews the numbers is that we are much more likely to record issues as security related these days. A decade ago when we got a report about a segfault or something we would often just consider it bad code and fix it, and neither us maintainers nor the reporter would think much about the potential security impact.
These days we’re at the other end of the spectrum where we people are much faster to jumping to a security issue suspicion or conclusion. Today people report bugs as security issues to a much higher degree than they did in the past. This is basically a good thing though, even if it makes it harder to draw conclusions over time.
Data sources
When you want to repeat the above graphs and verify my numbers:
- vuln.pm – from the curl web site repository holds security issue meta data
- releaselog – on the curl web site offers release meta data, even as a CSV download on the bottom of the page
- report2release.pl – the perl script I used to calculate the report until release periods.