
Another year reaches its calendar end and a new year awaits around the corner. In the curl project we’ve had another busy and event-full year. Here’s a look back at some of the fun we’ve done during 2018.
Releases
We started out the year with the 7.58.0 release in January, and we managed to squeeze in another six releases during the year. In total we count 658 documented bug-fixes and 31 changes. The total number of bug-fixes was actually slightly lower this year compared to last year’s 683. An average of 1.8 bug-fixes per day is still not too shabby.
Authors
I’m very happy to say that we again managed to break our previous record as 155 unique authors contributed code. 111 of them for the first time in the project, and 126 did fewer than three commits during the year. Basically this means we merged code from a brand new author every three days through-out the year!
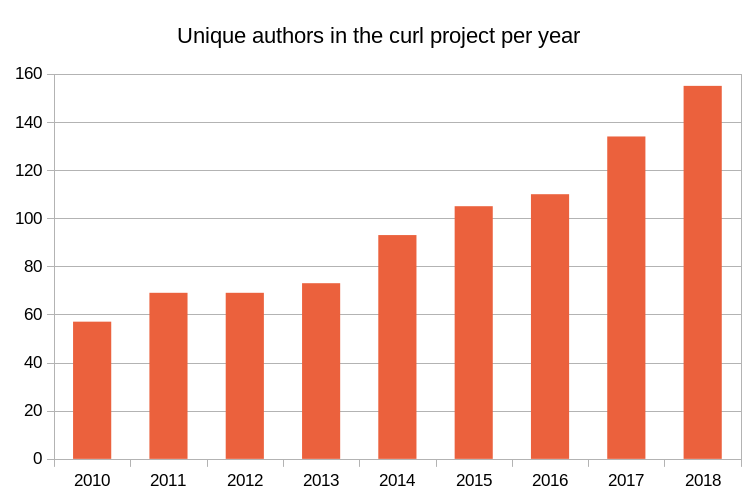
The list of “contributors”, where we also include helpers, bug reporters, security researchers etc, increased with another 169 new names this year to a total of 1829 in the last release of the year. That’s 169 new names. Of course we also got a lot of help from people who were already mentioned in there!
Will we be able to reach 2000 names before the end of 2019?
Commits
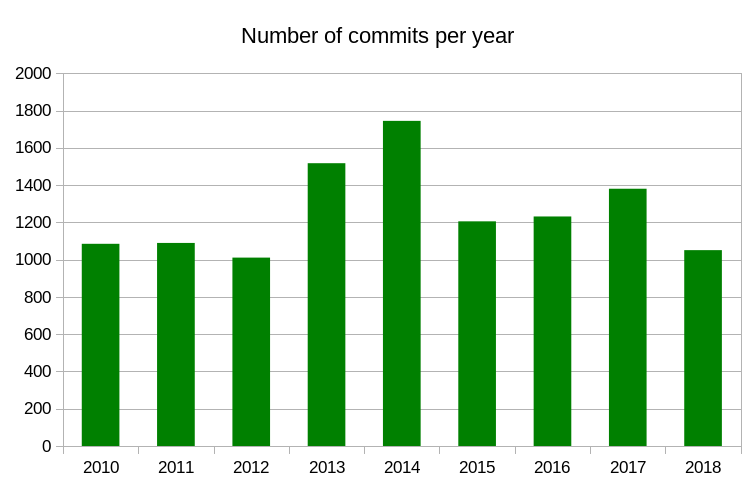
At the time of this writing, almost two weeks before the end of the year, we’re still behind the last few years with 1051 commits done this year. 1381 commits were done in 2017.
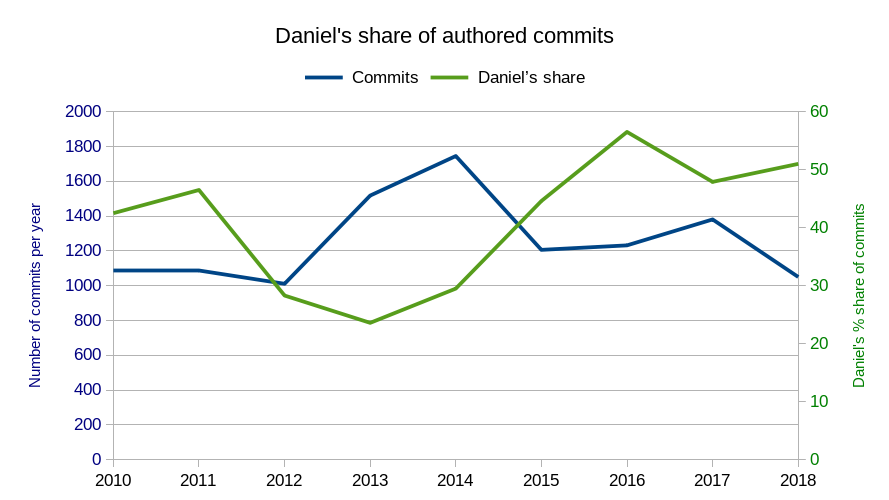
Daniel’s commit share
I personally authored 535 (50.9%) of all commits during 2018. Marcel Raad did 65 and Daniel Gustafsson 61. In general I maintain my general share of the changes done in the project over time. Possibly I’ve even increased it slightly the last few years. This graph shows my share of the commits layered on top of the number of commits done.
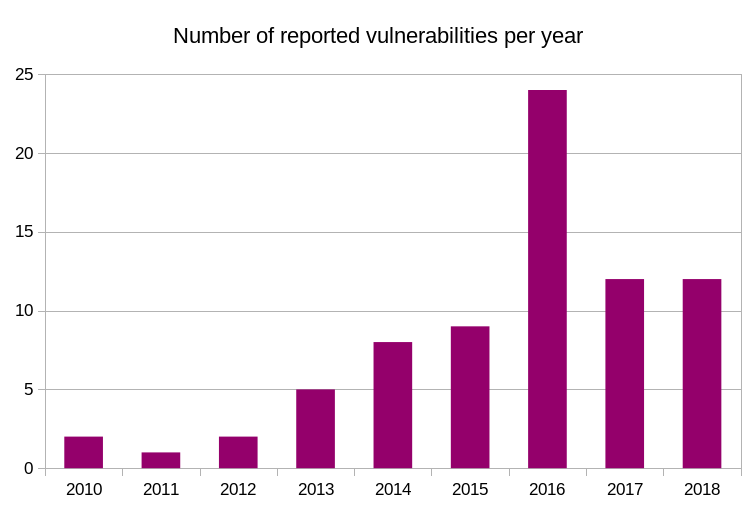
Vulnerabilities
This year we got exactly the same amount of security problems reported as we did last year: 12. Some of the problems were one-off due curl being added to the OSS-Fuzz project in 2018 and it has taken a while to really hit some of our soft spots and as we’ve seen a slow-down in reports from there it’ll be interesting to see if 2019 will be a brighter year in this department. (In total, OSS-Fuzz is credited for having found six security vulnerabilities in curl to date.)
During the year we manage to both introduce new bug bounty program as well as retract that very same again when it shut down almost at once! 🙁
Lines of code
Counting all lines in the git repo in the src, lib and include directories, they grew nearly 6,000 lines (3.7%) during the year to 155,912. The primary code growing activities this year were:
- DNS-over-HTTPS support
- The new URL API and using that internally as well
Deprecating legacy
In July we created the DEPRECATE.md document to keep order of some things we’re stowing away in the cyberspace attic. During the year we cut off axTLS support as a first example of this deprecation procedure. HTTP pipelining, global DNS cache and HTTP/0.9 accepted by default are features next in line marked for removal, and the two first are already disabled in code.
curl up

We had our second curl conference this year; in Stockholm. It was blast again and I’m already looking forward to curl up 2019 in Prague.
Sponsor updates
Yours truly quit Mozilla and with that we lost them as a sponsor of the curl project. We have however gotten several new backers and sponsors over the year since we joined opencollective, and can receive donations from there.
Governance
Together with a bunch of core team members I put together a two-step proposal that I posted back in October:
- we join an umbrella organization
- we create a “board” to decide over money
As the first step turned out to be a very slow operation (ie we’ve applied, but the process has not gone very far yet) we haven’t yet made step 2 happen either.
2019
Things that didn’t happen in 2018 but very well might happen in 2019 include:
- Some first HTTP/3 and QUIC code attempts in curl
- HSTS support? A pull request for this has been lingering for a while already.
Note: the numbers for 2018 in this post were extracted and graphs were prepared a few weeks before the actual end of year, so some of the data quite possibly changed a little bit since.



