When curl 8.19.0 ships in the beginning of March 2026, we have also added MQTTS; meaning MQTT done securely over TLS.
This bumps the number of supported transfer protocols to 29 not too long after the project turned 29 years old.
The 29 transfer protocols (or schemes) that curl supports in January 2026
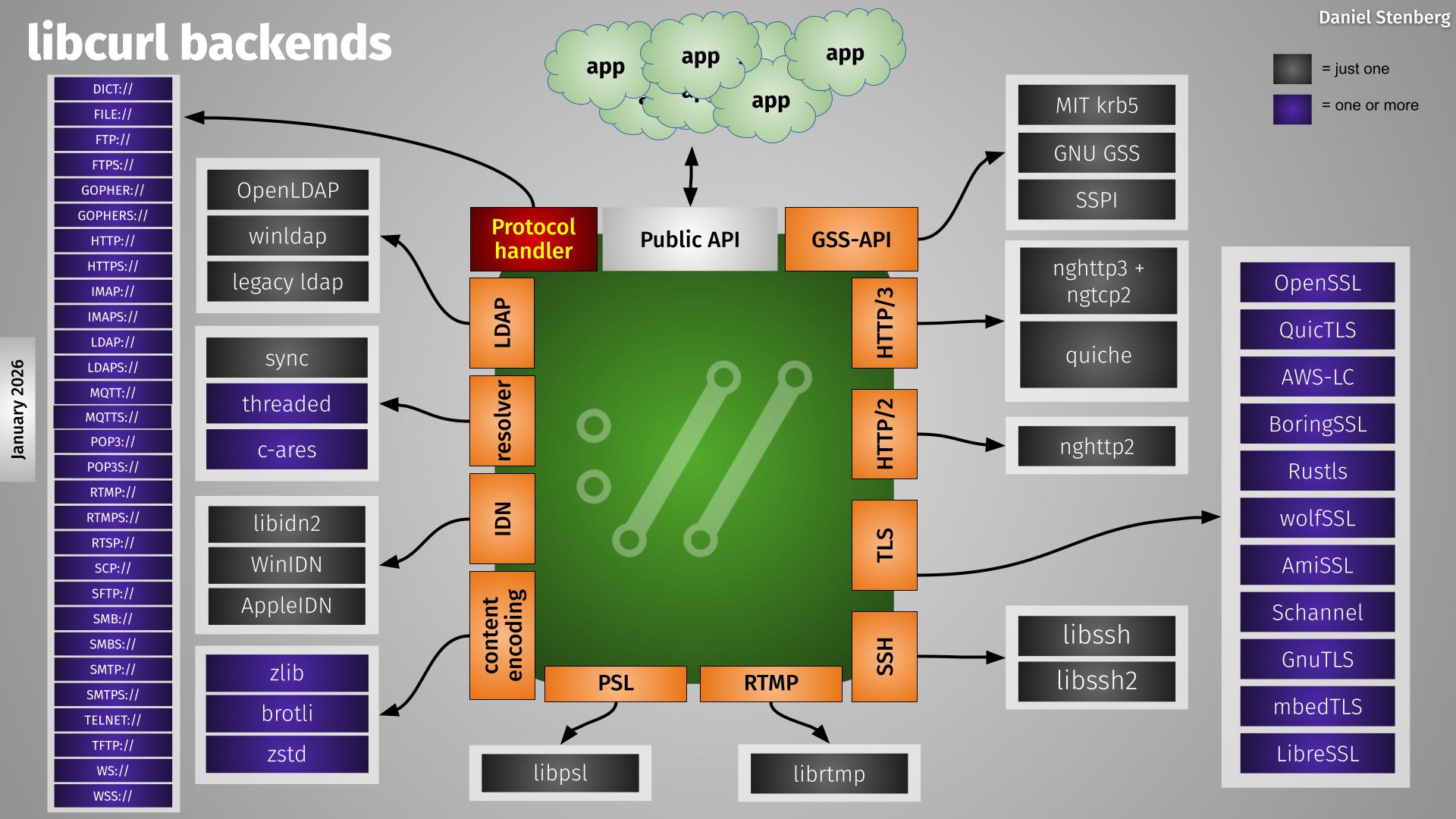
libcurl backends as of now
What’s MQTT?
Wikipedia describes it as a lightweight, publish–subscribe, machine-to-machine network protocol for message queue/message queuing service. It is designed for connections with remote locations that have devices with resource constraints or limited network bandwidth, such as in the Internet of things (IoT). It must run over a transport protocol that provides ordered, lossless, bi-directional connections—typically, TCP/IP.
Coming protocol support reduction
If things go as planned, the number of supported protocols will decrease soon as we have RTMP scheduled for removal later in the spring of 2026.
The first kept curl git commit is dated December 29, 1999. That is the date of our source code import into SourceForge as I quite annoyingly decided to not keep the prior history. The three years of development and the commits that happened before that import date are therefore not included in this count.
These 20,000 commits have been done on 5,589 separate days, meaning 59% of all days since December 1999. It also means I have done an average of 2.1 commits per day since then.
The curl commits done before 2010 were not actually made with git, but with CVS. The curl source repository was converted to git when we switched hosting over to GitHub.
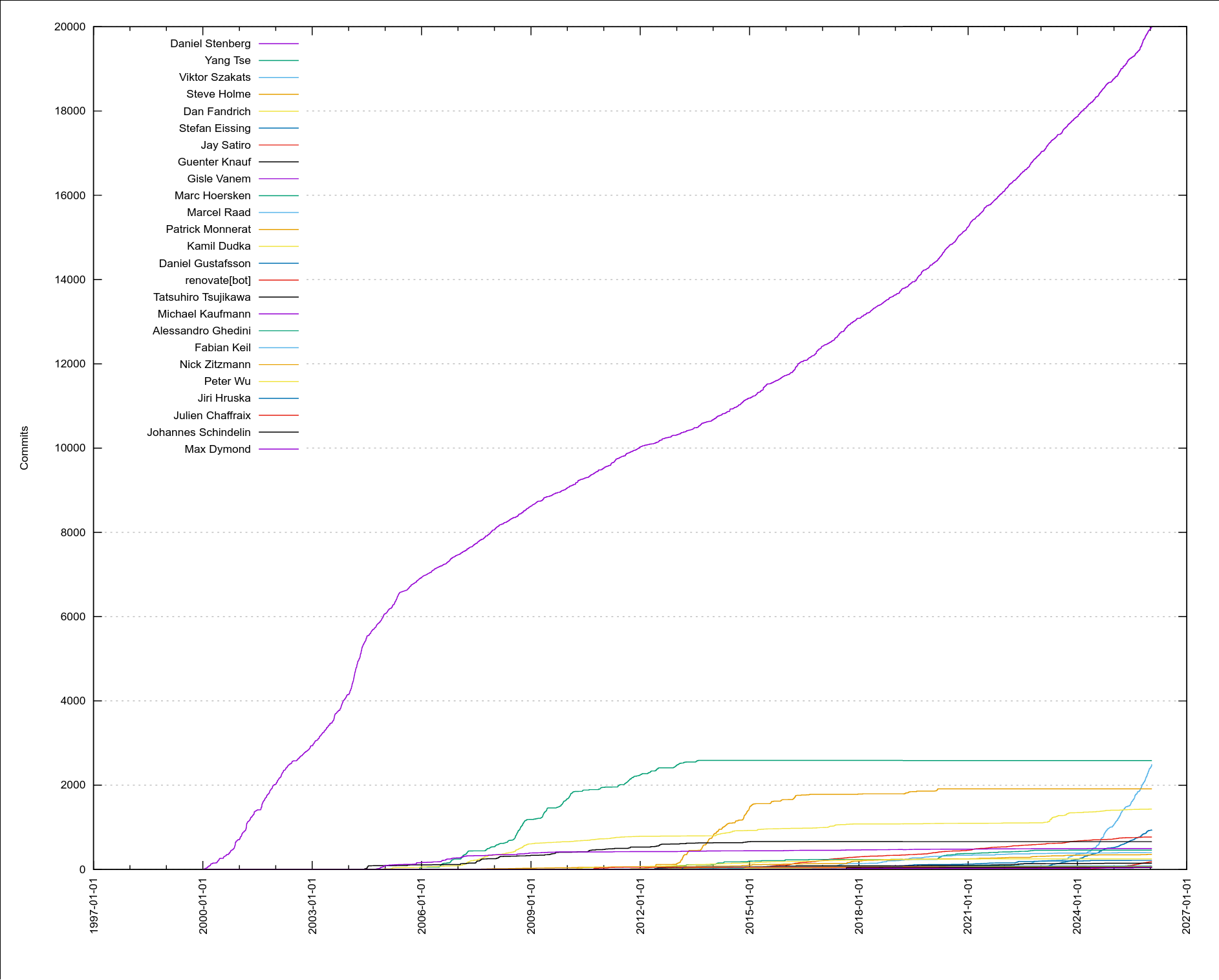
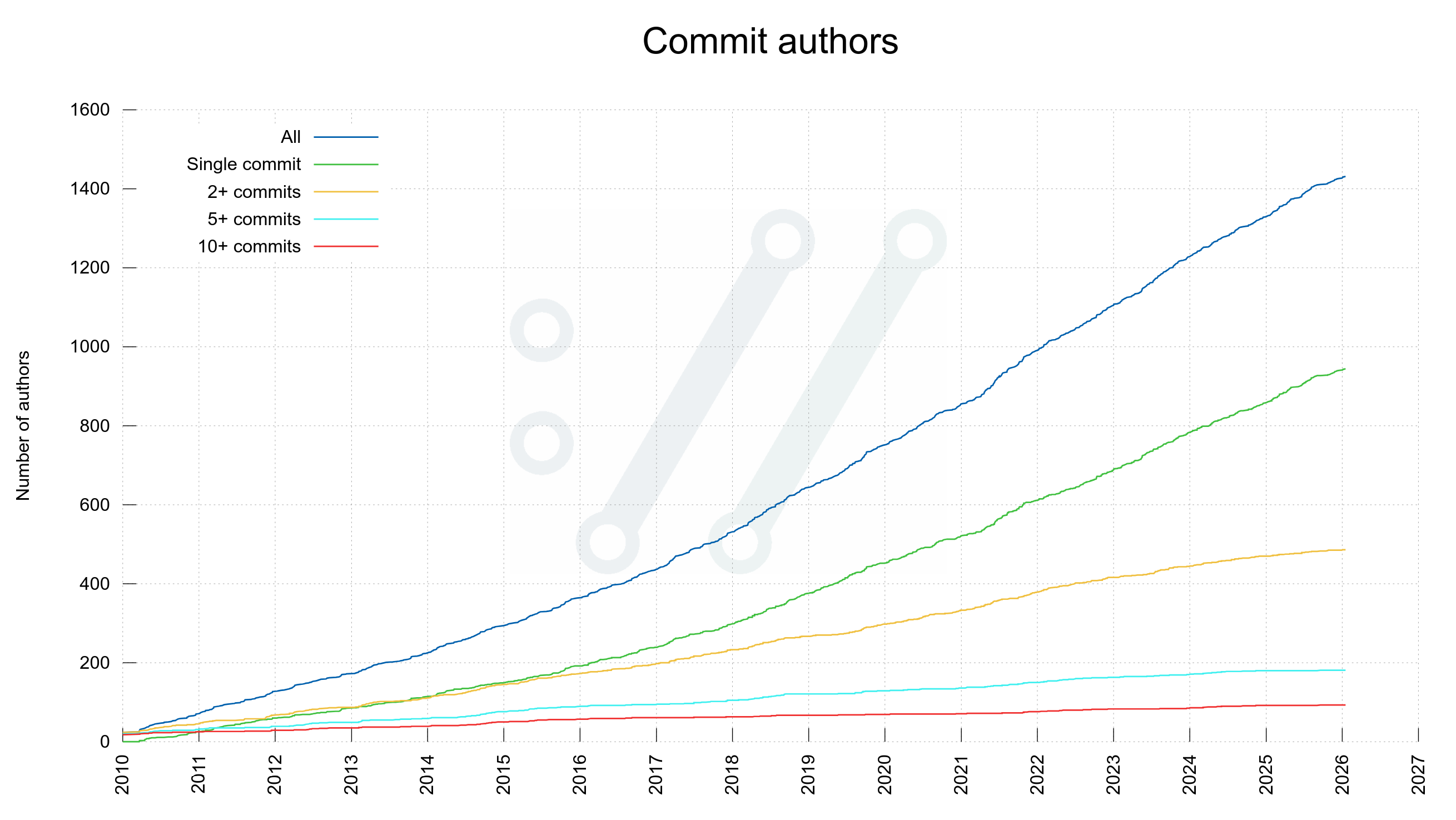
As of today, 1,431 separate individuals have authored commits merged into the curl source repository. 16 of us have made more than 100 commits. Five authors have written more than 1,000 commits. 941 of the authors only wrote a single commit (so far)!
The second-most curl committer by number of commits (Yang Tse) has almost 2,600 commits but he stopped being active already back in 2013.
My fellow top committers
The top-20 all time curl commit authors as of now:
Daniel Stenberg (20000 commits)
Yang Tse (2587 commits)
Viktor Szakats (2496 commits)
Steve Holme (1916 commits)
Dan Fandrich (1435 commits)
Stefan Eissing (941 commits)
Jay Satiro (773 commits)
Guenter Knauf (662 commits)
Gisle Vanem (498 commits)
Marc Hoersken (461 commits)
Marcel Raad (405 commits)
Patrick Monnerat (362 commits)
Kamil Dudka (255 commits)
Daniel Gustafsson (217 commits)
renovate[bot] (183 commits)
Tatsuhiro Tsujikawa (150 commits)
Michael Kaufmann (84 commits)
Alessandro Ghedini (83 commits)
Fabian Keil (77 commits)
Nick Zitzmann (70 commits)
Graphs
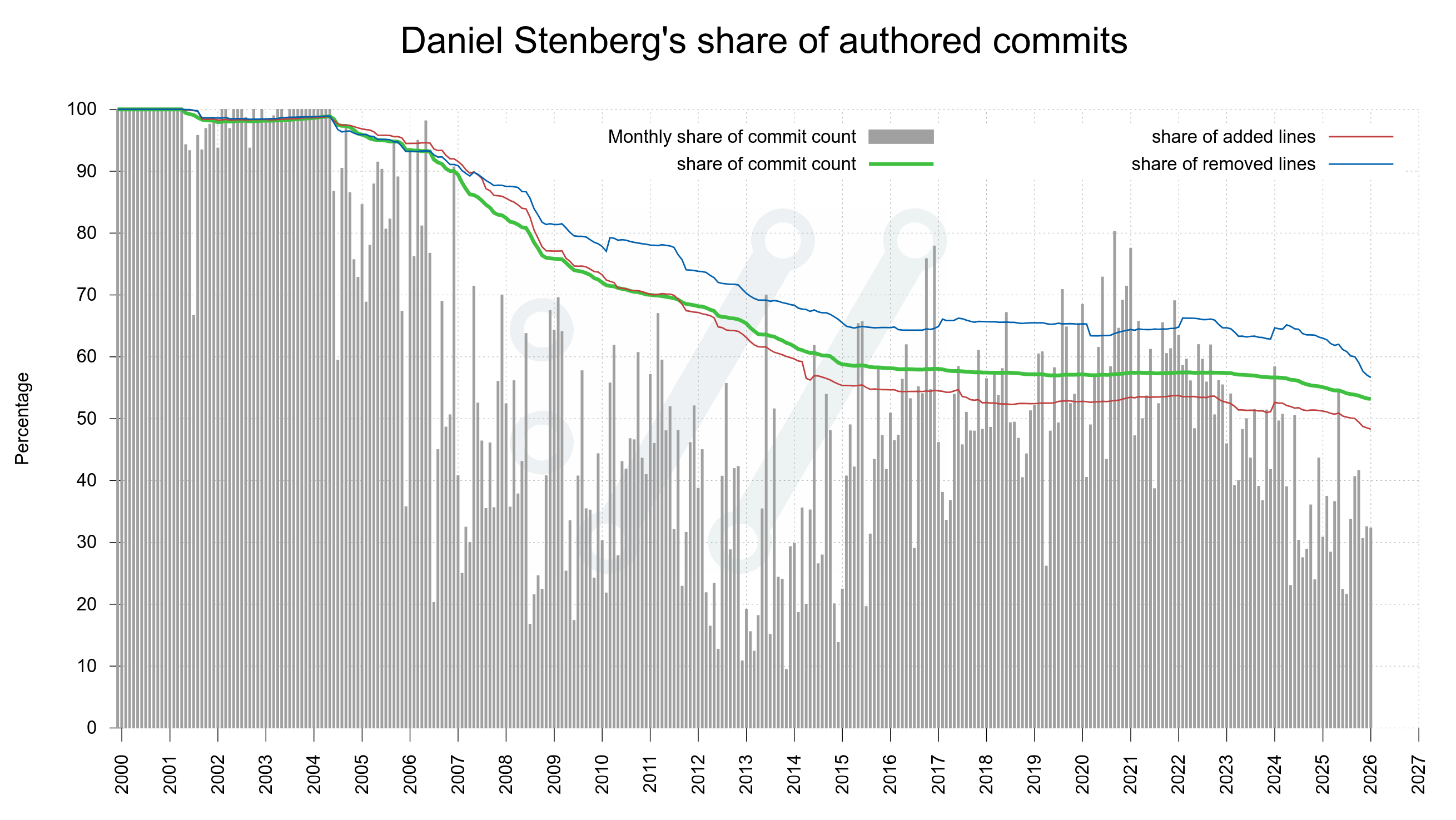
My share of the total amount of commits has been shrinking gradually since a long time and that is a good thing. It means we have awesome contributors and maintainers helping out. Not too far into the future I expect my share to go below 50%.
the number of commits done by the top-20 commit authors in curl over time
Number of commit authors in curl over time
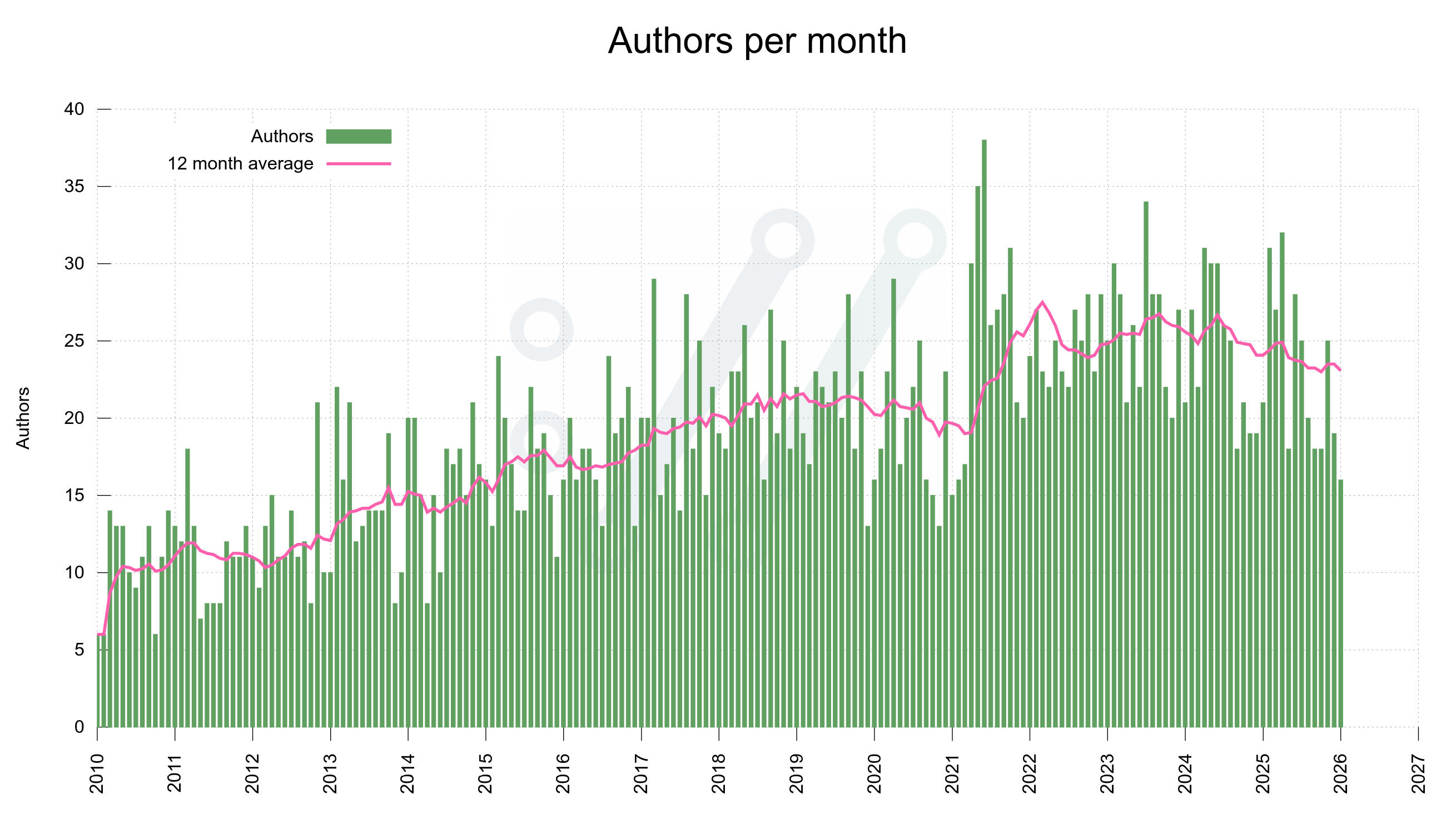
Number of unique authors per month over time
Daniel’s share of authored commits over time
Future
These are my first 20,000 commits.
I have no plans to go anywhere. I have averaged at about 800 commits per year in the curl source code repository for the last 25 years. That would imply reaching 30,000 would take another 12.5 years, so about by mid 2038 or so. If I manage to keep up that speed. Feels distant.
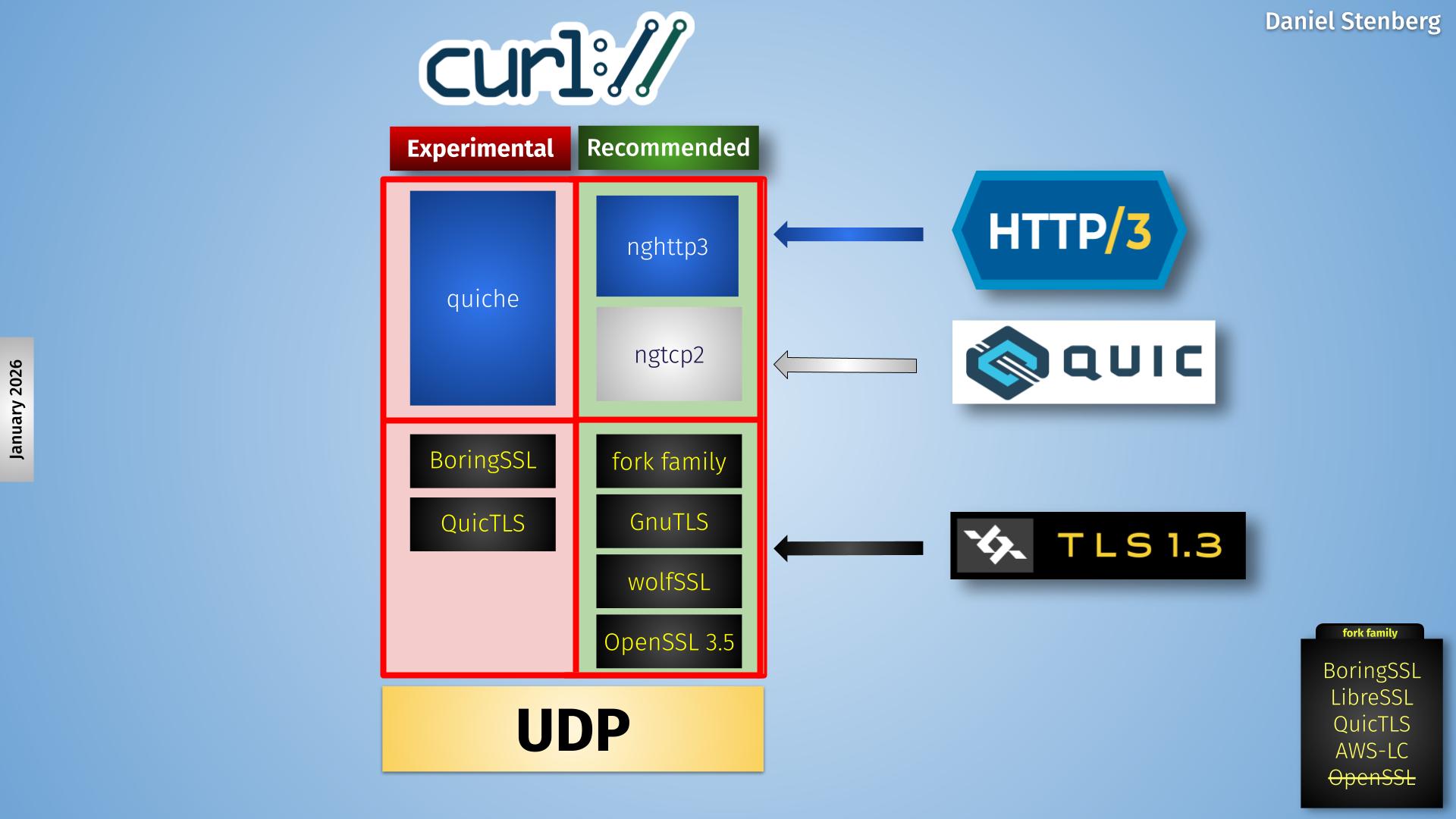
In the curl project we have a long tradition of offering multiple optional backends for specific protocols. In this spirit we have added experimental support for a number of different HTTP/3 + QUIC backends over time. A while ago we dropped one of those experiments, the msh3 backend.
Today we cleanup even more and remove support for yet another backend: the OpenSSL-QUIC stack and we are now down to only supporting two different HTTP/3 alternatives: the ngtcp2 + nghttp3 combo or quiche. And out of those two, the quiche backend is still considered experimental.
The first release shipping with this change will be curl 8.19.0.
OpenSSL-QUIC
This is the QUIC stack implemented and provided by OpenSSL. To make matters a little complicated, this is a separate thing from the QUIC API that OpenSSL also offers. The first one is a full QUIC implementation, the second one is an API that is powerful enough to allow a separate QUIC implementation use OpenSSL for its cryptographic and TLS needs.
A quick recap how history unfolded
2019 – BoringSSL introduced an API for QUIC. QUIC implementations picked it up and it worked. A pull request was made for OpenSSL to allow them to provide the same API so that QUIC stacks all over could use OpenSSL.
2021 – OpenSSL eventually denied merging the pull-request and announced they would instead implement their own QUIC stack – that nobody had asked for.
2023 – OpenSSL 3.2 shipped with support for their own QUIC stack. It was broken in many ways.
2025: OpenSSL version 3.4.1 was released and now the QUIC stack worked decently. In OpenSSL 3.5.0 they announced a QUIC API that now finally allowed independent QUIC stacks to use OpenSSL.
Experimental
Skilled contributors added support for OpenSSL-QUIC to curl primarily to allow people using OpenSSL to still be able to use HTTP/3.
OpenSSL’s own QUIC implementation only reached experimental state in curl meaning that we explicitly and strongly discourage users from using it in production and reserve ourselves the right to change functionality and more between versions.
There are three reasons why it did not graduate from experimental and they are also the reasons why we think we are better off without offering support for it:
The API is lacking. We have communicated with the OpenSSL-QUIC team since even before the API first shipped and it still does not offer the knobs and controls we would like to make it a competitive QUIC alternative. We don’t feel they care much.
The performance is bad. And by bad I mean really bad. The leading QUIC implementation alternative ngtcp2 transfers data much faster in all benchmarks and comparisons. Sometimes up to a factor three difference.
The memory use is abysmal. The amount of more memory required to do transfers with OpenSSL-QUIC compared to ngtcp2 can reach a factortwenty.
A drawing
This makes the curl backend situation simpler in the HTTP/3 and QUIC department as the image below tries to show.
CVE-2025-15224: libssh key passphrase bypass without agent set
Changes
There are a few this time, mostly around dropping support for various dependencies:
drop support for VS2008 (Windows)
drop Windows CE / CeGCC support
drop support for GnuTLS < 3.6.5
gnutls: implement CURLOPT_CAINFO_BLOB
openssl: bump minimum OpenSSL version to 3.0.0
Bugfixes
See the release presentation video for a walk-through of some of the most important/interesting fixes done for this release, or go check out the full list in the changelog.
I am heading to FOSDEM again at the end of January. I go there every year and I have learned that there is a really sticker-happy audience there. The last few times I have been there, I have given away several thousands of curl stickers.
As I realized I did not actually have a few thousand stickers left, I had to restock. I consider stickers a fun and somewhat easy way to market the curl project. It helps us getting known and seen out there in the world.
The stickers are paid for by curl donations. Thanks to all of you who have donated!
This time I ordered the stickers from stickerapp.se. They have a rather fancy web UI editor and tools to make sure the stickers become exactly the way I want them. I believe the total order price was actually slightly cheaper than the previous provider I used.
I ordered five classic curl sticker designs and I introduced a new one. Here is the full set:
Six different curl stickers
Die cut curl logo 7.5cm x 2.8cm – the classic “small” curl logo sticker. (bottom left in the photo)
Die cut curl logo 10cm x 3.7cm – the slightly larger curl logo sticker. (top row in the photo)
Rounded rectangle 7.5cm x 4.1cm – yes we curl, the curl symbol and my face (mid left in the photo)
Oval 7.5cm x 4cm – with the curl logo (bottom right in the photo)
Round 2.5cm x 2.5 cm – small curl symbol. (in the middle of the photo). My favorite. Perfect for the backside of a phone. Fits perfectly in the logo on the lid of a Frame Work laptop.
Round 4cm x 4cm – curl symbol in a slightly larger round version. The new sticker variant in the set. (on the right side in the middle row in the photo)
The quality and feel of the products are next to identical to previous sticker orders. They look great!
I got 1,000 copies of each variant this time.
The logo
The official curl logo, the curl symbol, the colors and everything related is freely available and anyone is welcome to print their own stickers at will: https://curl.se/logo/
How to get one?
I bring curl stickers to all events I go to. Ask me!
There is no way to buy stickers from me or from the curl project. I encourage you to look me up and ask for one or a few. At FOSDEM I try to make sure the wolfSSL stand has plenty to hand out, since it is a fixed geographical point that might be easier to find than me.
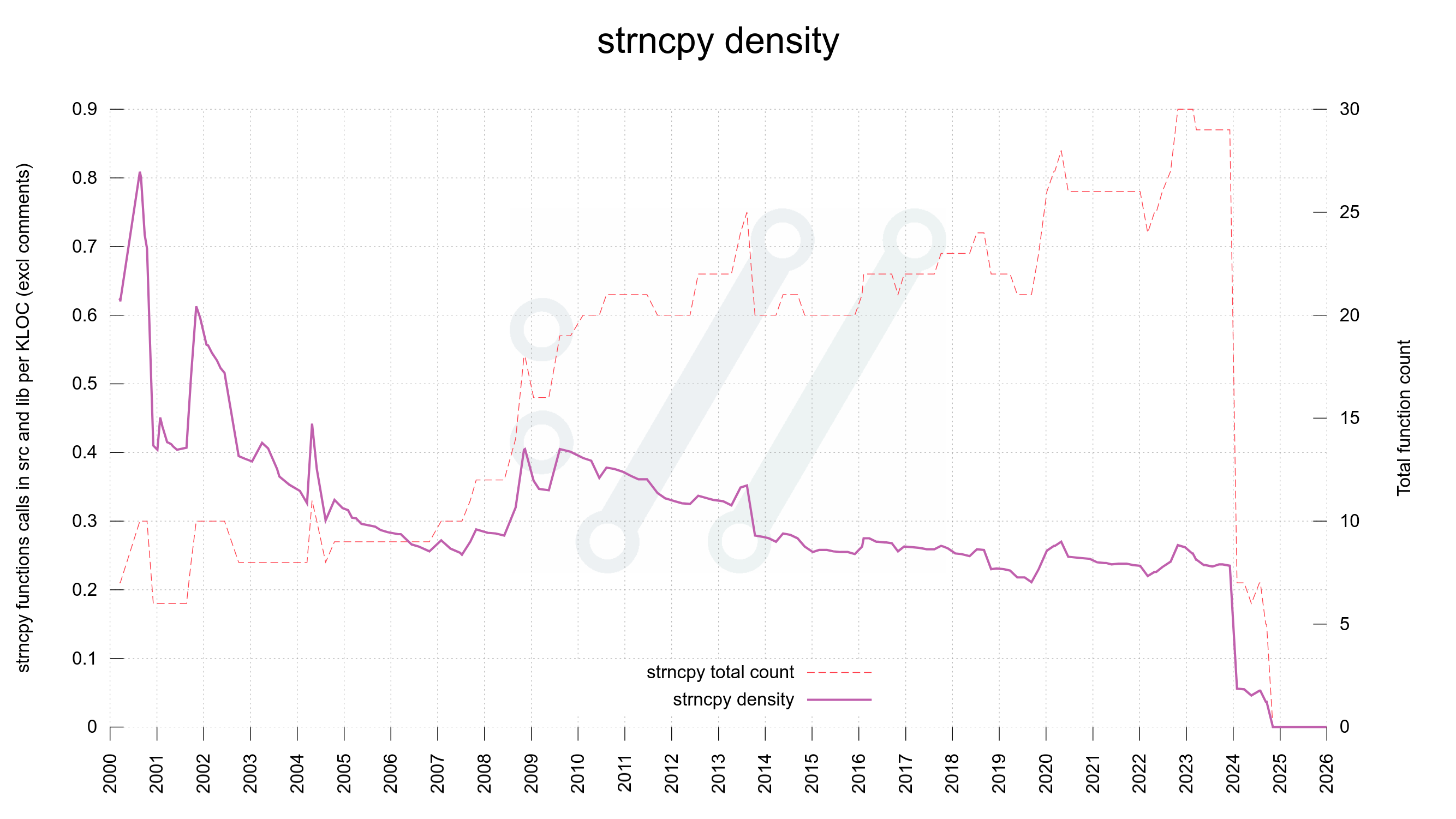
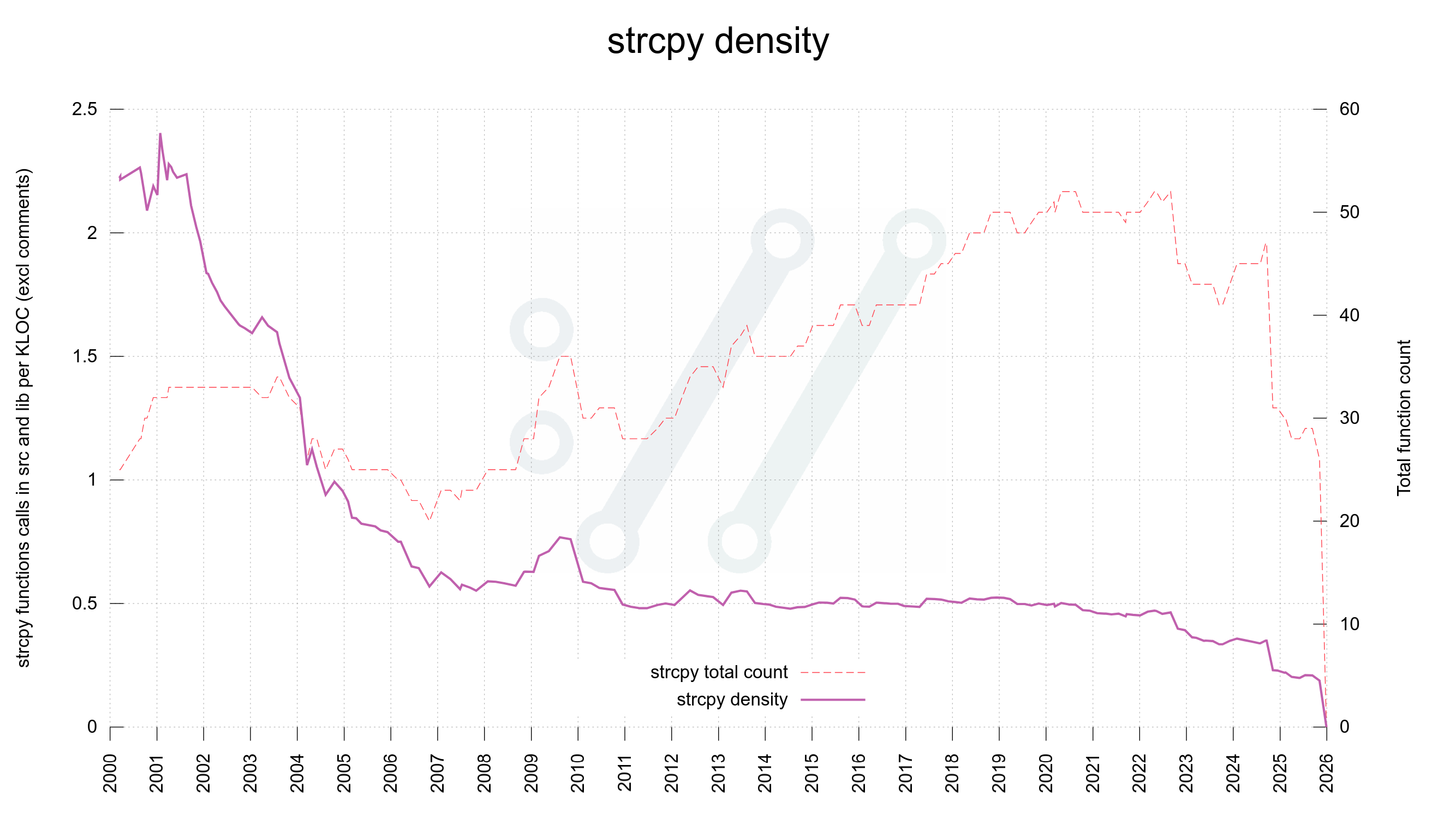
Some time ago I mentioned that we went through the curl source code and eventually got rid of all strncpy() calls.
strncpy() is a weird function with a crappy API. It might not null terminate the destination and it pads the target buffer with zeroes. Quite frankly, most code bases are probably better off completely avoiding it because each use of it is a potential mistake.
In that particular rewrite when we made strncpy calls extinct, we made sure we would either copy the full string properly or return error. It is rare that copying a partial string is the right choice, and if it is, we can just as well memcpy it and handle the null terminator explicitly. This meant no case for using strlcpy or anything such either.
strncpy density in curl over time
But strcpy?
strcpy however, has its valid uses and it has a less bad and confusing API. The main challenge with strcpy is that when using it we do not specify the length of the target buffer nor of the source string.
This is normally not a problem because in a C program strcpy should only be used when we have full control of both.
But normally and always are not necessarily the same thing. We are but all human and we all do mistakes. Using strcpy implies that there is at least one or maybe two, buffer size checks done prior to the function invocation. In a good situation.
Over time however – let’s imagine we have code that lives on for decades – when code is maintained, patched, improved and polished by many different authors with different mindsets and approaches, those size checks and the function invoke may glide apart. The further away from each other they go, the bigger is the risk that something happens in between that nullifies one of the checks or changes the conditions for the strcpy.
Enforce checks close to code
To make sure that the size checks cannot be separated from the copy itself we introduced a string copy replacement function the other day that takes the target buffer, target size, source buffer and source string length as arguments and only if the copy can be made and the null terminator also fits there, the operation is done.
This made it possible to implement the replacement using memcpy(). Now we can completely ban the use of strcpy in curl source code, like we already did strncpy.
Using this function version is a little more work and more cumbersome than strcpy since it needs more information, but we believe the upsides of this approach will help us have an oversight for the extra pain involved. I suppose we will see how that will fare down the road. Let’s come back in a decade and see how things developed!
An additional minor positive side-effect of this change is of course that this should effectively prevent the AI chatbots to report strcpy uses in curl source code and insist it is insecure if anyone would ask (as people still apparently do). It has been proven numerous times already that strcpy in source code is like a honey pot for generating hallucinated vulnerability claims.
Still, this will just make them find something else to make up a report about, so there is probably no net gain. AI slop is not a game we can win.
Let’s take a look back and remember some of what this year brought.
commits
At more than 3,400 commits we did 40% more commits in curl this year than any single previous year!
Since at some point during 2025, all the other authors in the project have now added more lines in total to the curl repository than I have. Meaning that out of all the lines ever added in the curl repository, I have now added less than half.
More than 150 individuals authored commits we merged during the year. Almost one hundred of them were first-timers. Thirteen authors wrote ten or more commits.
Viktor Szakats did the most number of commits per month for almost all months in 2025.
Stefan Eissing has now done the latest commit for 29% of the product source code lines – where my share is 36%.
About 598 authors have their added contributions still “surviving” in the product code. This is down from 635 at end of last year.
tests
We have 232 more tests at the end of this year compared to last December (now at 2179 separate test cases), and for the first time ever we have more than twelve test cases per thousand lines of product source code.
(Sure, counting test cases is rather pointless and weird since a single test can be small or big, simple or complex etc, but that’s the only count we have for this.)
releases
The eight releases we did through the year is a fairly average amount:
8.12.0
8.12.1
8.13.0
8.14.0
8.14.1
8.15.0
8.16.0
8.17.0
No major revolution happened this year in terms of big features or changes.
We reduced source code complexity a lot. We have stopped using some more functions we deem were often the reasons for errors or confusion. We have increased performance. We have reduced numbed of used allocations.
We added experimental support for HTTPS-RR, the DNS record.
The bugfix frequency rate beat new records towards the end of the year as nearly 450 bugfixes shipped in curl 8.17.0.
This year we started doing release candidates. For every release we upload a series of candidates before the actual release so that people can help us and test what is almost the finished version. This helps us detect and fix regressions before the final release rather than immediately after.
Command line options
We end the year with 6 more curl command line options than we had last new year’s eve; now at 273 in total.
The curl man page continued to grow; now more than 500 lines longer since last year (7090 lines), which means that even when counted number of man page lines per command line option it grew from 24.7 to 26.
Lines of code
libcurl grew with a mere 100 lines of code over the year while the command line tool got 1,150 new lines.
libcurl is now a little over 149,000 lines. The command line tool has 25,800 lines.
Most of the commits clearly went into improving the products rather than expanding them. See also the dropped support section below.
QUIC
This year OpenSSL finally introduced and shipped an API that allows QUIC stacks to use vanilla OpenSSL, starting with version 3.5.
As a direct result of this, the use of the OpenSSL QUIC stack has been marked as deprecated in curl and is queued for removal early next year.
As we also removed msh3 support during 2025, we are looking towards a 2026 with supporting only two QUIC and HTTP/3 backends in curl.
Security
This year the number of AI slop security reports for curl really exploded. The curl security team has gotten a lot of extra load because of this. We have been mentioned in media a lot during the year because of this.
The reports not evidently made with AI help have also gotten significantly worse quality wise while the total volume has increased – a lot. Also adding to our collective load.
We published nine curl CVEs during 2025, all at severity low or medium.
AI improvements
A new breed of AI-powered high quality code analyzers, primarily ZeroPath and Aisle Research, started pouring in bug reports to us with potential defects. We have fixed several hundred bugs as a direct result of those reports – so far.
This is in addition to the regular set of code analyzers we run against the code and for which we of course also fix the defects they report.
Web traffic
At the end of the year 2025 we see 79 TB of data getting transferred monthly from curl.se. This is up from 58 TB (+36%) for the exact same period last year.
We don’t have logs or analysis so we don’t know for sure what all this traffic is, but we know that only a tiny fraction is actual curl downloads. A huge portion of this traffic is clearly not human-driven.
GitHub activity
More than two hundred pull requests were opened each month in curl’s GitHub repository.
For a brief moment during the fall we reached zero open issues.
We have over 220 separate CI jobs that in the end of the year spend more than 25 CPU days per day verifying our ongoing changes.
Dashboard
The curl dashboard expanded a lot. I removed a few graphs that were not accurate anymore, but the net total change is still that we went up from 82 graphs in December 2024 to 92 separate illustrations in December 2025. Now with a total of 259 individual plots (+25).
Dropped support
We removed old/legacy things from the project this year, in an effort to remove laggards, to keep focus on what’s important and to make sure all of curl is secure.
Support for Visual Studio 2005 and older (removed in 8.13.0)
The curl project moved over its source code hosting to GitHub in March 2010, but we kept the main bug tracker running like before – on Sourceforge.
It took us a few years, but in 2015 we finally ditched the Sourceforge version fully. We adopted and switched over to the pull request model and we labeled the GitHub issue tracker the official one to use for curl bugs. Announced on the curl website proper on March 9 2015.
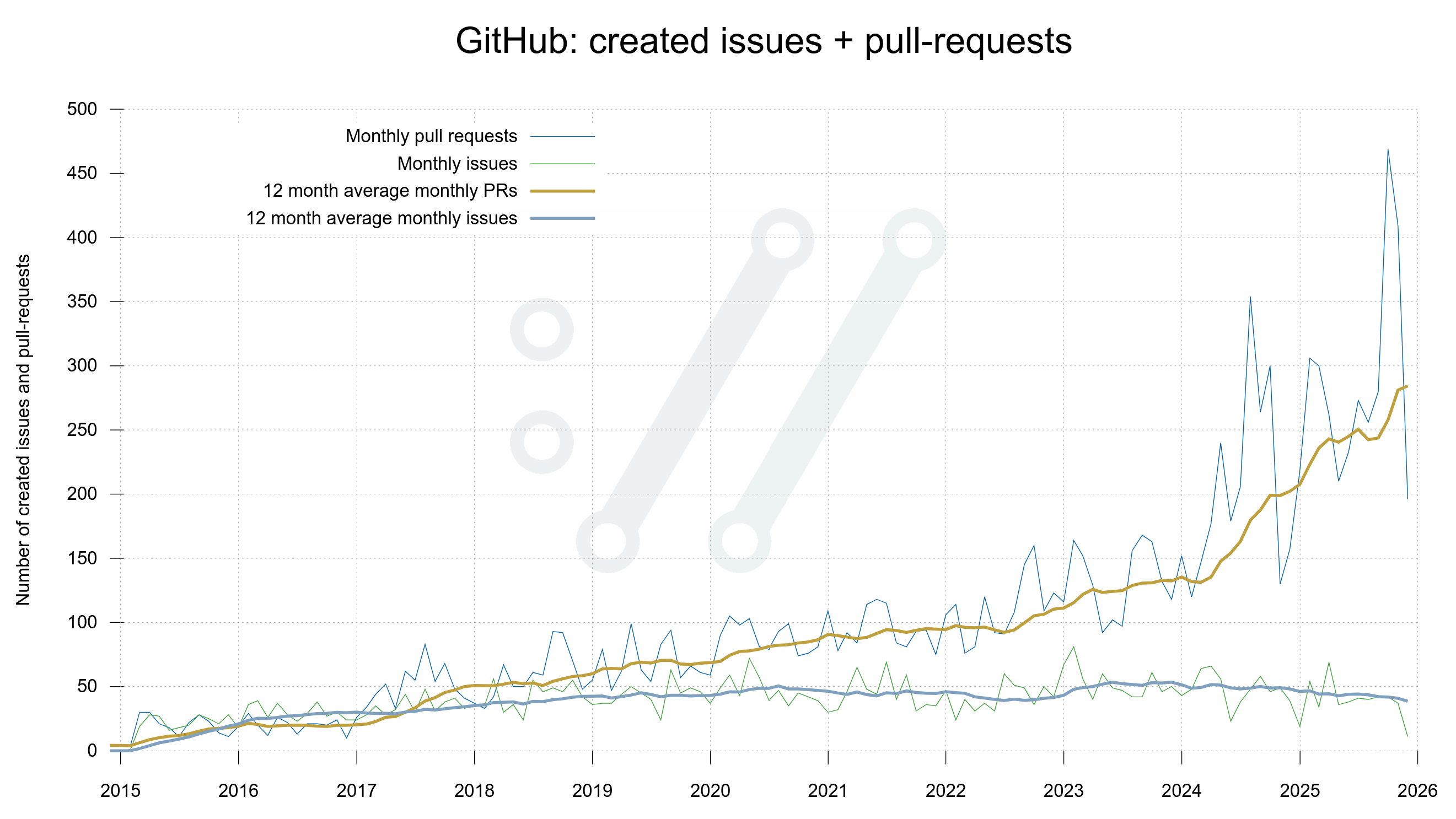
GitHub holds issues and pull requests in the same number series, and since a few years back they also added discussions to the mix. This number is another pointless one, but it is large and even so let’s celebrate it!
Issue one in curl’s GitHub repository is from October 2010.
Issue 10,000 was created November 29, 2022. That meant 9,500 issues created in 2,597 days. 3.7 issues/day on average over seven years.
Issue 20,000 (a pull request really) was created today, on December 16, 2025. 10,000 more issues created in 1,113 days. 9 issues/day over the last three years.
The pace of which primarily new pull requests are submitted has certainly gone up over the recent years, as this graph clearly shows. (Since the current month is only half so far, the drop at the right end of the plot is quite expected.)
Number of issues and pull-requests submitted each month
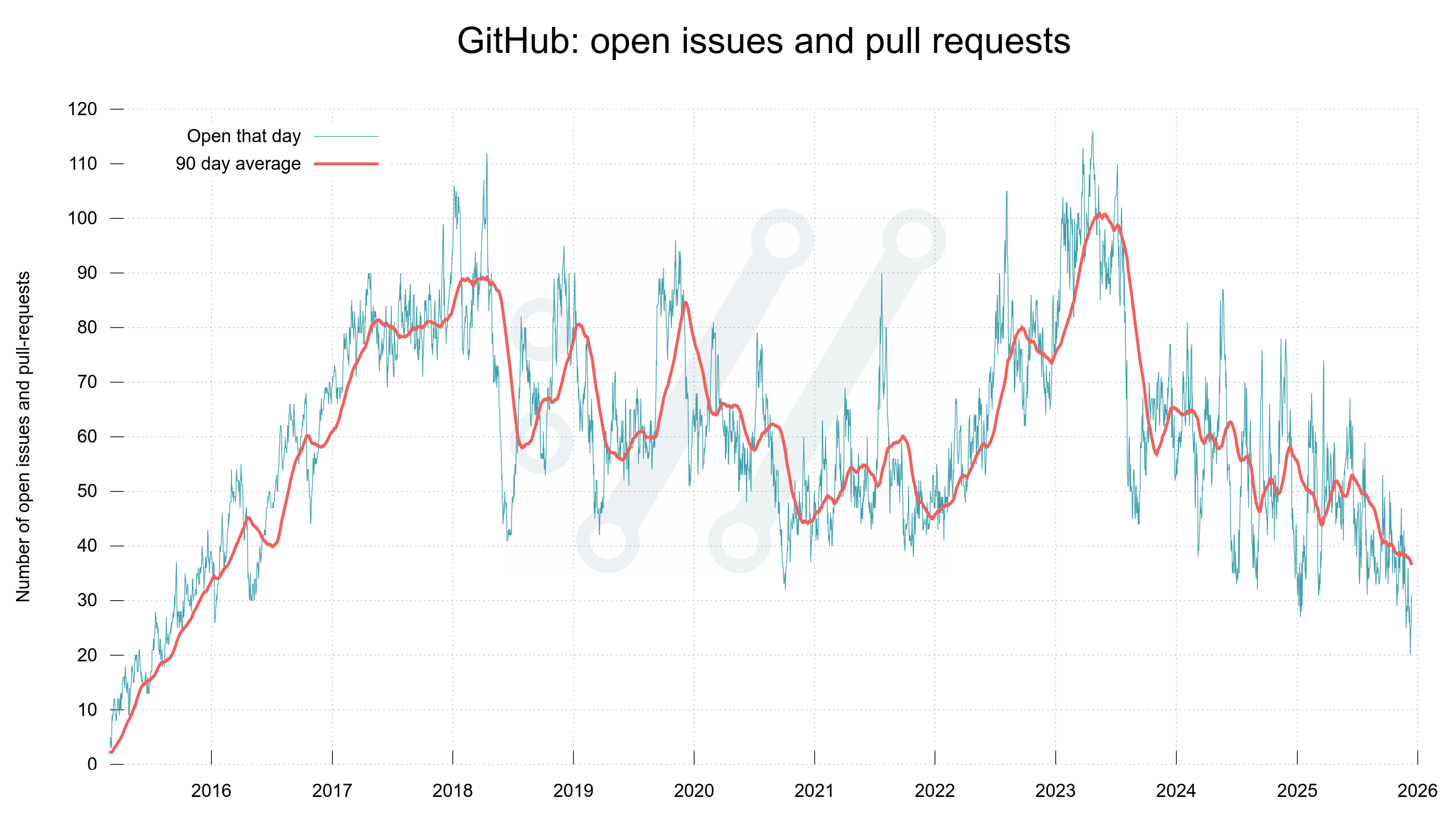
We work hard in the project to keep the number of open issues and pull requests low even when the frequency rises.
Number of open issues and pull requests any given day
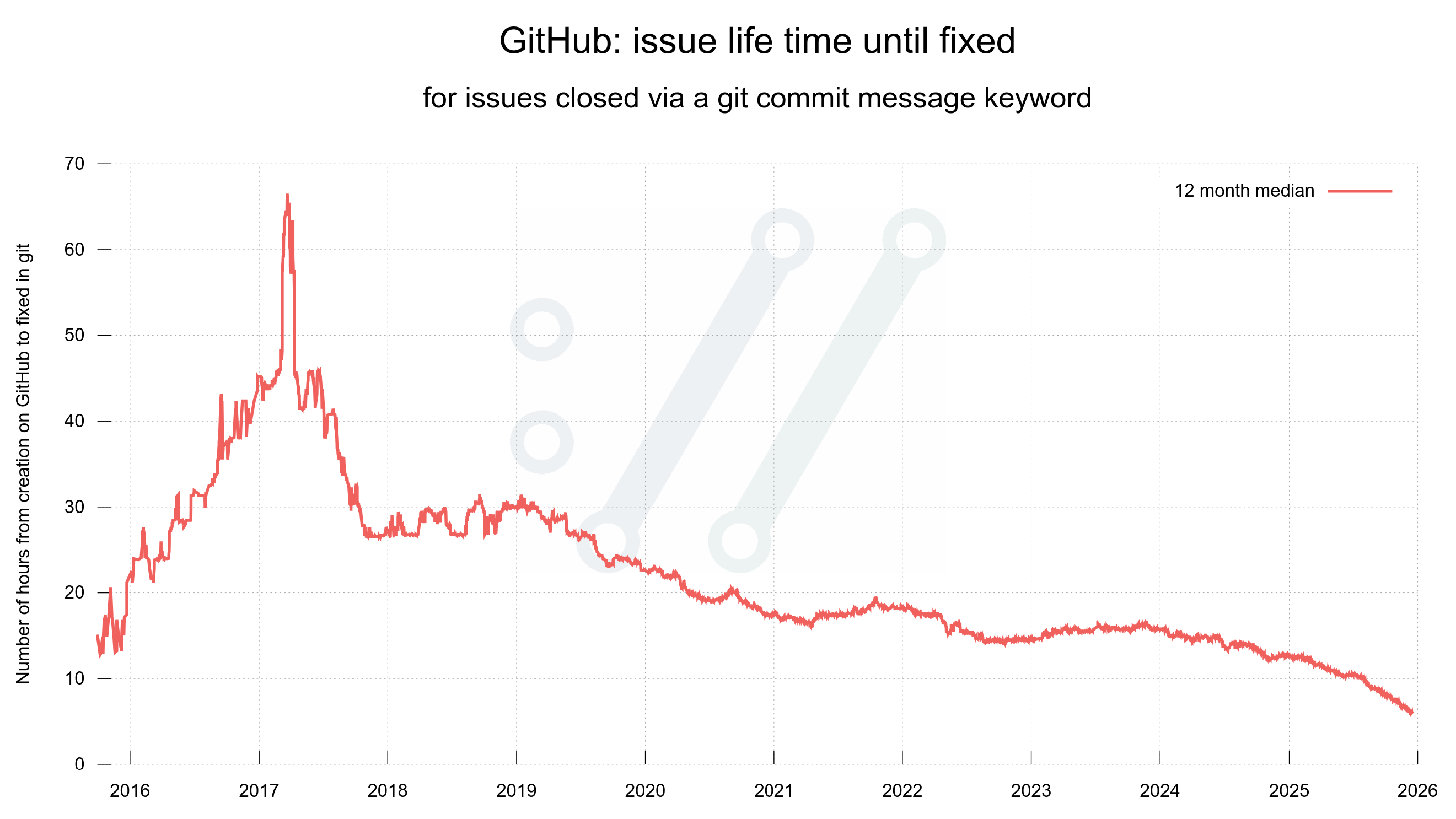
It can also be noted that issues and pull requests are typically closed fast. Out of the ones that are closed with instructions in the git commit message, the trend looks like below. Half of them are closed within 6 hours.
Number of hours until an issue is closed, when closed with git commit instructions
Of course, these graphs are updated daily and shown on the curl dashboard.
Note: we have not seen the AI slop tsunami in the issues and pull requests as we do on Hackerone. This growth is entirely human made and benign.
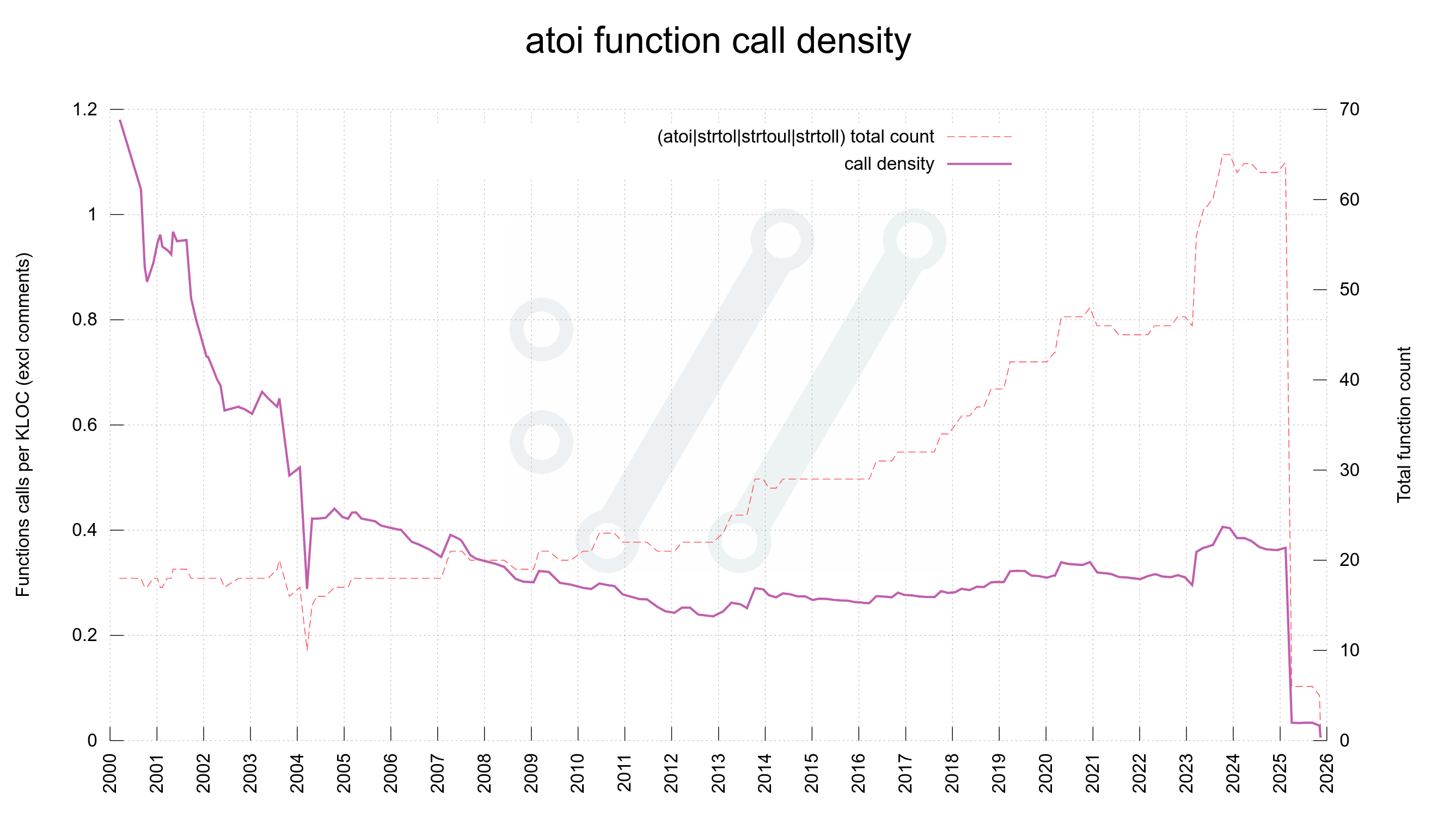
In the standard libc API set there are multiple functions provided that do ASCII numbers to integer conversions.
They are handy and easy to use, but also error-prone and quite lenient in what they accept and silently just swallow.
atoi
atoi() is perhaps the most common and basic one. It converts from a string to signed integer. There is also the companion atol() which instead converts to a long.
Some problems these have include that they return 0 instead of an error, that they have no checks for under or overflow and in the atol() case there’s this challenge that long has different sizes on different platforms. So neither of them can reliably be used for 64-bit numbers. They also don’t say where the number ended.
Using these functions opens up your parser to not detect and handle errors or weird input. We write better and stricter parser when we avoid these functions.
strtol
This function, along with its siblings strtoul() and strtoll() etc, is more capable. They have overflow detection and they can detect errors – like if there is no digit at all to parse.
However, these functions as well too happily swallow leading whitespace and they allow a + or – in front of the number. The long versions of these functions have the problem that long is not universally 64-bit and the long long version has the problem that it is not universally available.
The overflow and underflow detection with these function is quite quirky, involves errno and forces us to spend multiple extra lines of conditions on every invoke just to be sure we catch those.
curl code
I think we in the curl project as well as more or less the entire world has learned through the years that it is usually better to be strict when parsing protocols and data, rather than be lenient and try to accept many things and guess what it otherwise maybe meant.
As a direct result of this we make sure that curl parses and interprets data exactly as that data is meant to look and we error out as soon as we detect the data to be wrong. For security and for solid functionality, providing syntactically incorrect data is not accepted.
This also implies that all number parsing has to be exact, handle overflows and maximum allowed values correctly and conveniently and errors must be detected. It always supports up to 64-bit numbers.
strparse
I have previously blogged about how we have implemented our own set of parsing function in curl, and these also include number parsing.
curlx_str_number() is the most commonly used of the ones we have created. It parses a string and stores the value in a 64-bit variable (which in curl code is always present and always 64-bit). It also has a max value argument so that it returns error if too large. And it of course also errors out on overflows etc.
This function of ours does not allow any leading whitespace and certainly no prefixing pluses or minuses. If they should be allowed, the surrounding parsing code needs to explicitly allow them.
The curlx_str_number function is most probably a little slower that the functions it replaces, but I don’t think the difference is huge and the convenience and the added strictness is much welcomed. We write better code and parsers this way. More secure. (curlx_str number source code)
History
As of yesterday, November 12 2025 all of those weak functions calls have been wiped out from the curl source code. The drop seen in early 2025 was when we got rid of all strtrol() variations. Yesterday we finally got rid of the last atoi() calls.
libc number function call density in curl production code
The function mentioned above uses a ‘curlx’ prefix. We use this prefix in curl code for functions that exist in libcurl source code but that be used by the curl tool as well – sharing the same code without them being offered by the libcurl API.
A thing we do to reduce code duplication and share code between the library and the command line tool.
the 271st release 11 changes 56 days (total: 10,092) 448 bugfixes (total: 12,537) 699 commits (total: 36,725) 2 new public libcurl function (total: 100) 0 new curl_easy_setopt() option (total: 308) 1 new curl command line option (total: 273) 69 contributors, 35 new (total: 3,534) 22 authors, 5 new (total: 1,415) 1 security fixes (total: 170)
Security
CVE-2025-10966: missing SFTP host verification with wolfSSH. curl’s code for managing SSH connections when SFTP was done using the wolfSSH powered backend was flawed and missed host verification mechanisms.
Changes
We drop support for several things this time around:
write-out: make %header{} able to output all occurrences of a header
Bugfixes
We set a new project record this time with no less than 448 documented bugfixes since the previous release.
The release presentation mentioned above discusses some of the perhaps most significant ones.
Coming next
There a small set of pull-requests waiting to get merged, but other than that our future is not set and we greatly appreciate your feedback, submitted issues and provided pull-requests to guide us.
If this release happens to include an annoying regression, there might be a patch release already next week. If we are lucky and it doesn’t, then we aim for a 8.18.0 release in the early January 2026.









{kind=link}