PSL in this context stands for Public Suffix List. It is a list of known public suffixes in domain names. A public suffix is a name under which Internet users can (or historically could) directly register names – other than the top-level domains. One of the most commonly known and used such suffixes is “co.uk”, but the complete list is rather long and exhaustive.
Public suffixes are important when working with HTTP cookies, because the only way an HTTP client can accurately deny setting super cookies is to know about every existing PSL domain and deny servers to set cookies for those domains.
The use of PSL is recommend in RFC 6265: “If feasible, user agents SHOULD use an up-to-date public suffix list” (and yes, there mere fact that it speaks of a list and not the list of course highlights how problematic this is)
A super cookie is a cookie that is set for a “too wide” domain, making it apply across multiple sites in ways cookies are not supposed to function. If we allow a super cookie set for “co.uk”, that cookie could get sent to a huge amount of different domains.
If you ask me, this is one of the ugliest parts of cookie functionality. And there are a few such parts to select from.
The exact list of names present in the PSL varies over time. New names are added, old names are removed. This of course makes aging clients over time increasingly likely to unwittingly accept cookies for domain names that have since been added to the list. Or block cookies for domains that are no longer in the list!
curl, cookies and PSL
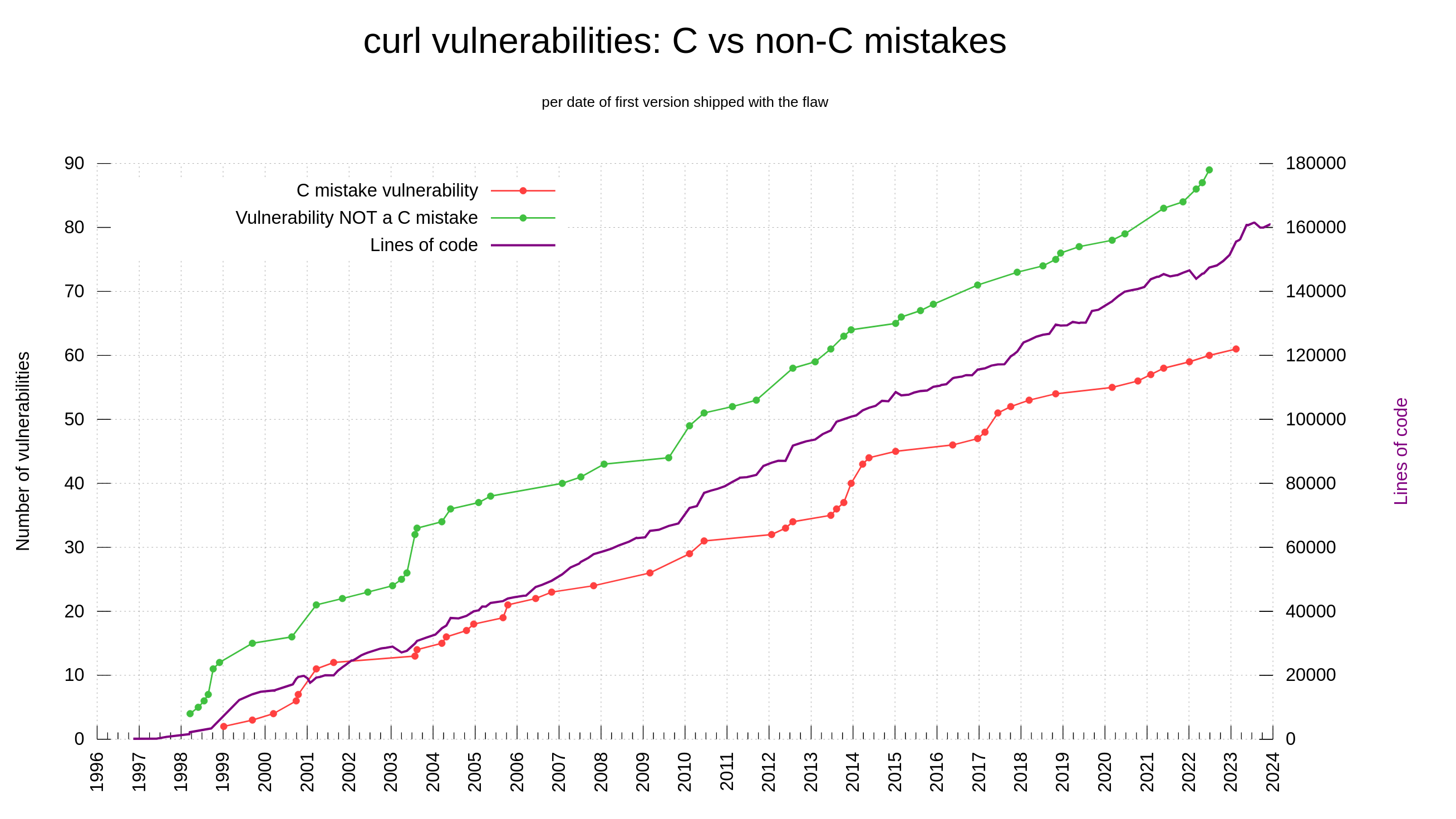
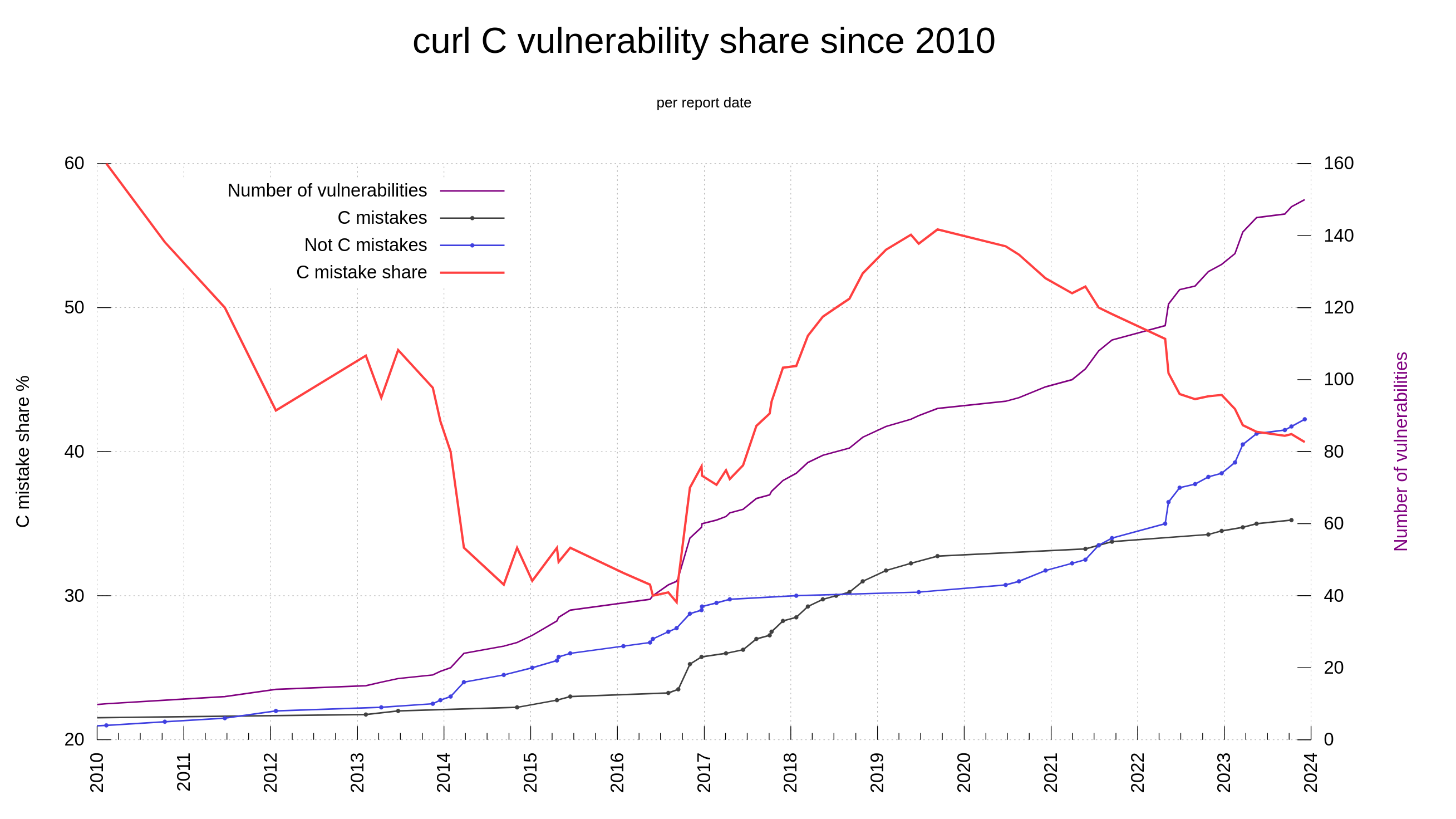
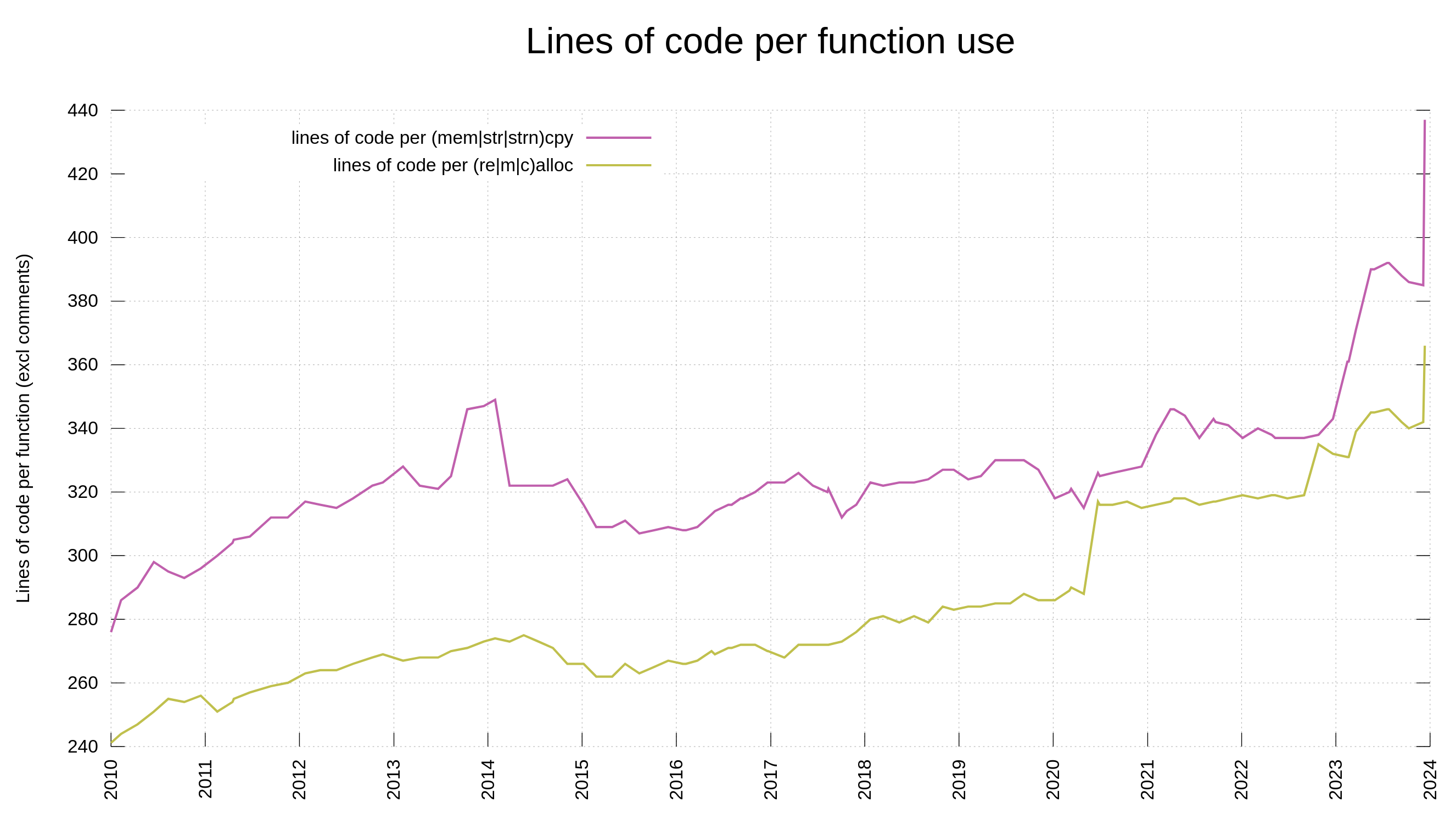
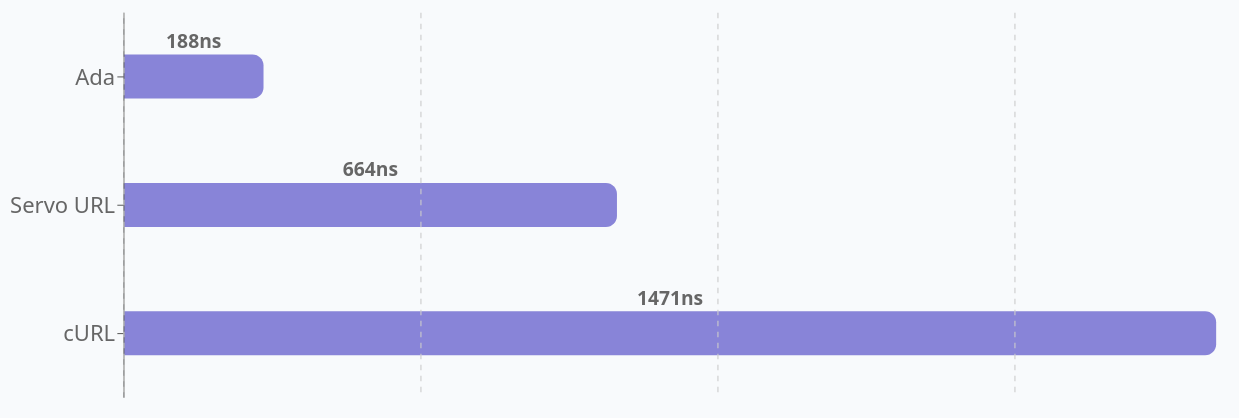
curl has supported cookies since 1998, but it has only supported PSL since 2015 (7.46.0). PSL support in curl is powered by the libpsl library.
Support for this external library is entirely optional in the build and lots of users deliberately decide to build curl without it. Leaving it out reduces footprint, avoids an extra dependency etc. Lots of users who build curl won’t use cookies or do not care about the risk for super cookies.
When you invoke curl -V, to get to see the versions and features of your currently installed curl tool, look for the PSL keyword among the features to learn whether your curl build supports Public Suffix List handling.
cookies are cross-client
Since cookies are sent to clients / browsers typically in a completely client-agnostic way, setting cookies with “illegal” domains make them get discarded and not used. This makes sites tend to not try super cookies for normal scenarios as those cookies will just be rejected by most clients. This fact sometimes save the non-PSL compliant clients.
Of course, servers can also just send a flood of cookies to the client trying different domain attributes – as clients will just silent discard the illegal ones and keep the legal ones and then use them later according to their own best abilities.
Force a decision
Based on the realization that people have been building and shipping curl without PSL support perhaps without fully understanding what they have ducked for, I have just merged a change to curl’s configure script. This change will ship in curl 8.6.0.
The configure script checks for libpsl by default (and has done so for a long time) and will use the library if detected, but starting now it will exit with an error if the detection fails to highlight this fact in a much more noticeable way. The users who want to keep building without it can just add --without-libpsl to hush up the message. Previously, a failed detection only worked as a hint to configure that it should build curl without PSL support – completely fine, but maybe not always done so with the user being totally knowledgeable of what that means.
This change still does not necessarily mean that the person getting the configure error understands PSL in depth, but it forces them to make a decision: Willingly build without it, or fix the build to use it. Your choice!
Not a security issue (in curl)
This (now past) lenient take, to allow users to build curl easily without PSL support, was reported as a curl security problem.
I disagree with that take, as I believe it is the responsibility of everyone building curl to make sure that the sum of the components is what they think it should be – the curl build procedure is not designed for nor attempting to make sure that the final product is hardened security wise (whatever that could be). PSL support is optionally built-in – by design.
This said: users who mistakenly use curl without PSL support might of course end up in what could be seen as a potential security problem. I do however not think that it is a security problem in the curl project itself.