
Using curl to perform an operation a user just managed to do with his or her browser is one of the more common requests and areas people ask for help about.
How do you get a curl command line to get a resource, just like the browser would get it, nice and easy? Both Chrome and Firefox have provided this feature for quite some time already!
From Firefox
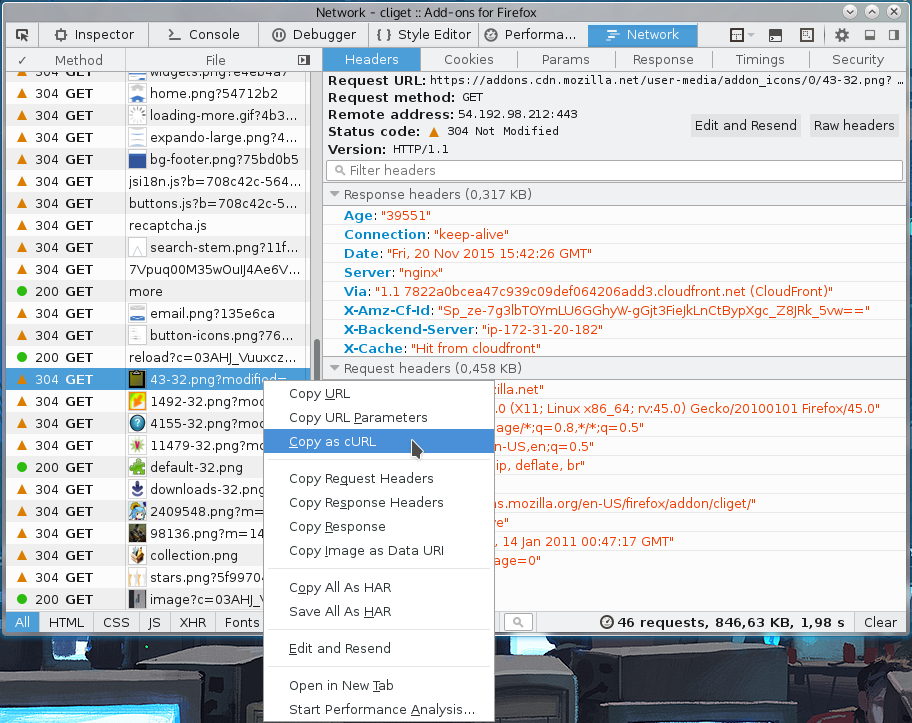
You get the site shown with Firefox’s network tools. You then right-click on the specific request you want to repeat in the “Web Developer->Network” tool when you see the HTTP traffic, and in the menu that appears you select “Copy as cURL”. Like this screenshot below shows. The operation then generates a curl command line to your clipboard and you can then paste that into your favorite shell window. This feature is available by default in all Firefox installations.
From Chrome
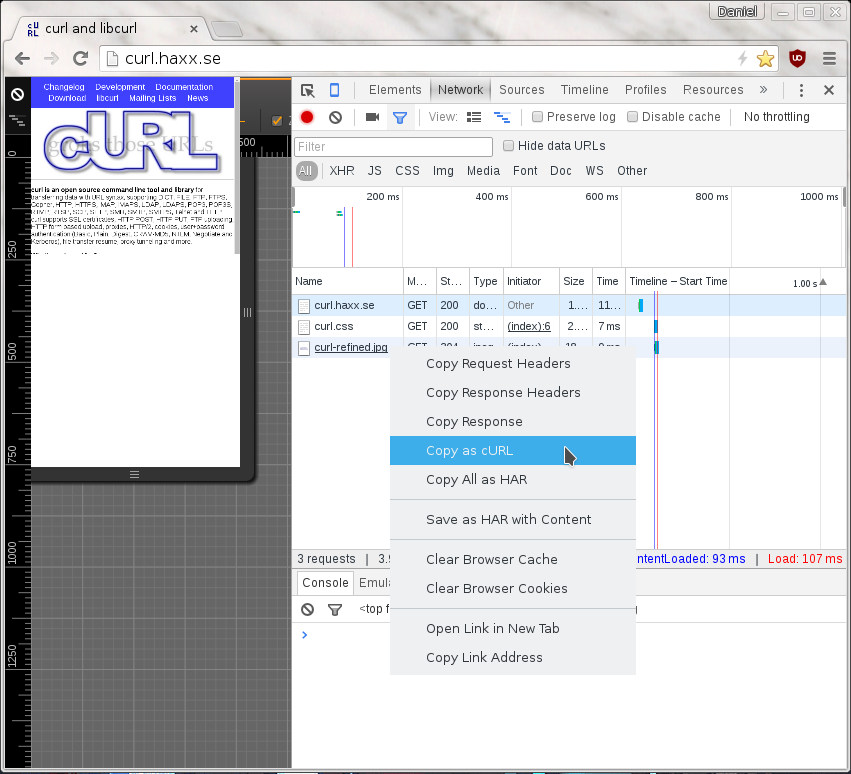
When you pop up the More tools->Developer mode in Chrome, and you select the Network tab you see the HTTP traffic used to get the resources of the site. On the line of the specific resource you’re interested in, you right-click with the mouse and you select “Copy as cURL” and it’ll generate a command line for you in your clipboard. Paste that in a shell to get a curl command line that makes the transfer. This feature is available by default in all Chome and Chromium installations.
On Firefox, without using the devtools
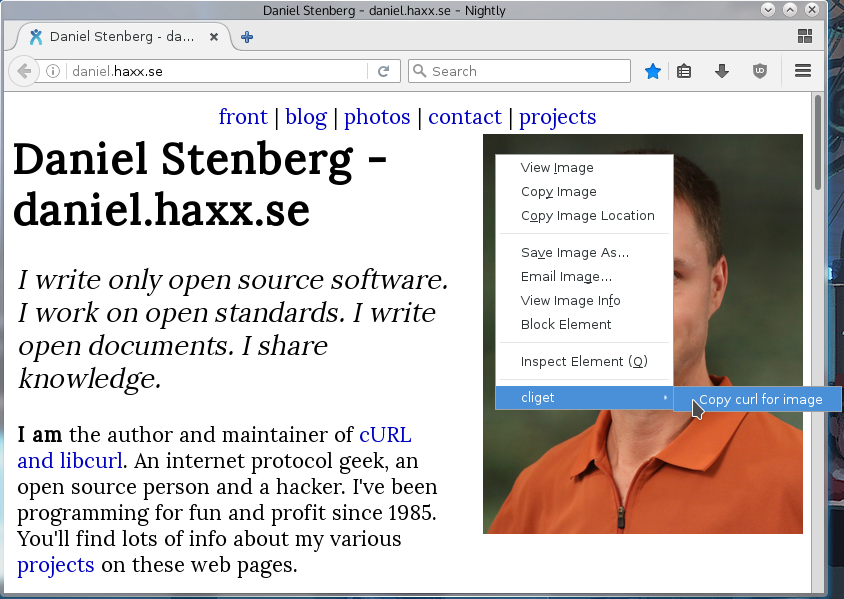
If this is something you’d like to get done more often, you probably find using the developer tools a bit inconvenient and cumbersome to pop up just to get the command line copied. Then cliget is the perfect add-on for you as it gives you a new option in the right-click menu, so you can get a quick command line generated really quickly, like this example when I right-click an image in Firefox:
 At times I post blog articles that get the view counter go up to and beyond 50,000 views. This puts me in a position where I get offers from companies to mention them or to “cooperate” on further blog posts that would somehow push their agenda or businesses.
At times I post blog articles that get the view counter go up to and beyond 50,000 views. This puts me in a position where I get offers from companies to mention them or to “cooperate” on further blog posts that would somehow push their agenda or businesses.