

I had the honor and pleasure to hand over this prize to its first real laureate during the award gala on Thursday evening in Brussels, Belgium.
This annual award ceremony is one of the primary missions for the European Open Source Academy, of which I am the president since last year.
As an academy, we hand out awards and recognition to multiple excellent individuals who help make Europe the home of excellent Open Source. Fellow esteemed academy members joined me at this joyful event to perform these delightful duties.
As I stood on the stage, after a brief video about Greg was shown I introduced Greg as this year’s worthy laureate. I have included the said words below. Congratulations again Greg. We are lucky to have you.
Me introducing Greg Kroah-Hartman
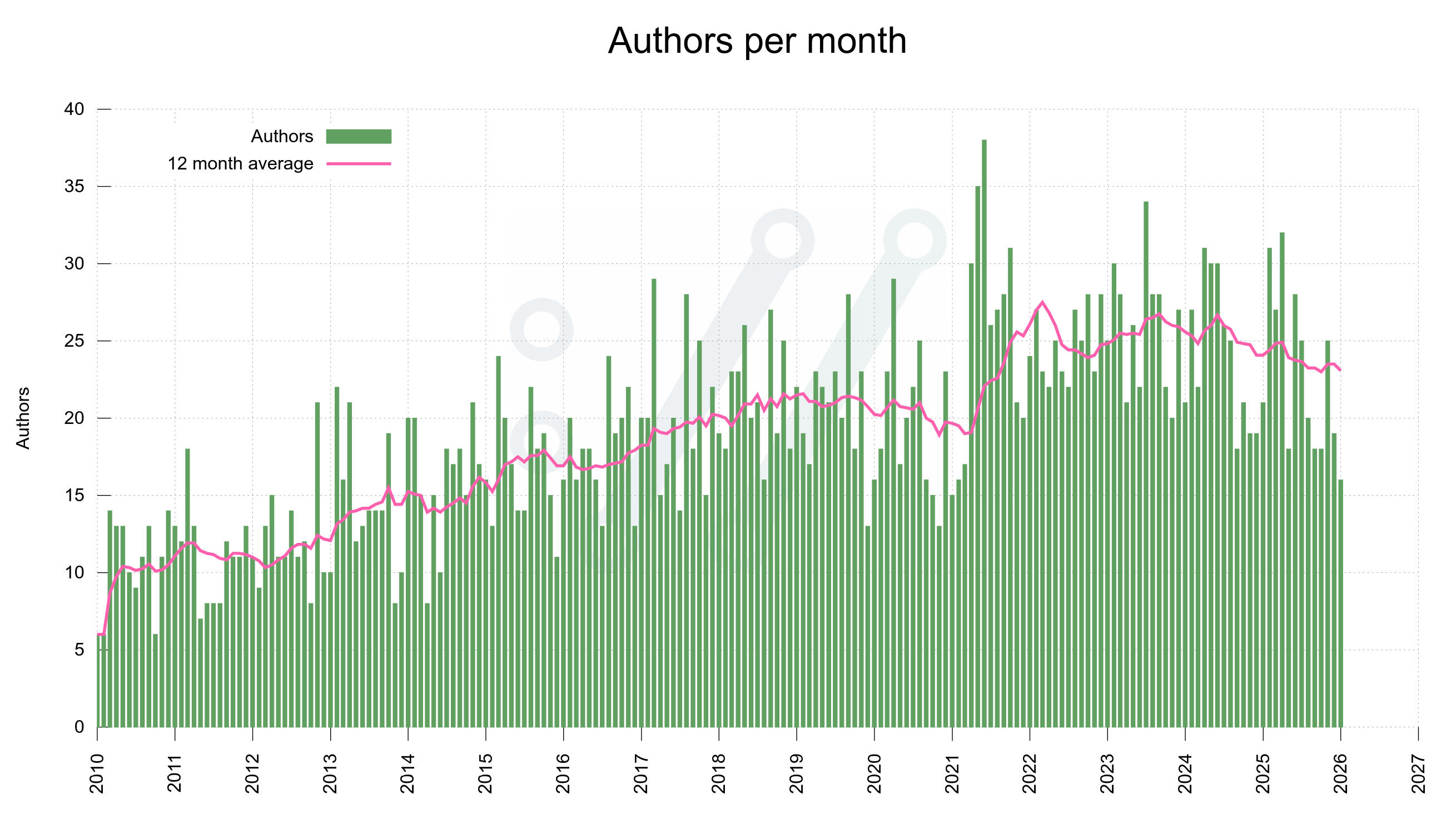
There are tens of millions of open source projects in the world, and there are millions of open source maintainers. Many more would count themselves as at least occasional open source developers. These are the quiet builders of Europe’s digital world.
When we work on open source projects, we may spend most of our waking hours deep down in the weeds of code, build systems, discussing solutions, or tearing our hair out because we can’t figure out why something happens the way it does, as we would prefer it didn’t.
Open source projects can work a little like worlds on their own. You live there, you work there, you debate with the other humans who similarly spend their time on that project. You may not notice, think, or even care much about other projects that similarly have a set of dedicated people involved. And that is fine.
Working deep in the trenches this way makes you focus on your world and maybe remain unaware and oblivious to champions in other projects. The heroes who make things work in areas that need to work for our lives to operate as smoothly as they, quite frankly, usually do.
Greg Kroah-Hartman, however, our laureate of the Prize for Excellence in Open Source 2026, is a person whose work does get noticed across projects.
Our recognition of Greg honors his leading work on the Linux kernel and in the Linux community, particularly through his work on the stable branch of Linux. Greg serves as the stable kernel maintainer for Linux, a role of extraordinary importance to the entire computing world. While others push the boundaries of what Linux can do, Greg ensures that what already exists continues to work reliably. He issues weekly updates containing critical bug fixes and security patches, maintaining multiple long-term support versions simultaneously. This is work that directly protects billions of devices worldwide.
It’s impossible to overstate the importance of the work Greg has done on Linux. In software, innovation grabs headlines, but stability saves lives and livelihoods. Every Android phone, every web server, every critical system running Linux depends on Greg’s meticulous work. He ensures that when hospitals, banks, governments, and individuals rely on Linux, it doesn’t fail them. His work represents the highest form of service: unglamorous, relentless, and essential.
Without maintainers like Greg, the digital infrastructure of our world would crumble. He is, quite literally, one of the people keeping the digital infrastructure we all depend on running.
As a fellow open source maintainer, Greg and I have worked together in the open source security context. Through my interactions with him and people who know him, I learned a few things:
- Greg is competent. a custodian and maintainer of many parts and subsystems of the Linux kernel tree and its development for decades.
- Greg has a voice. He doesn’t bow to pressure or take the easy way out. He has integrity.
- Greg is persistent. He has been around and done hard work for the community for decades.
- Greg is a leader. He shares knowledge, spreads the word, and talks to crowds. In a way that is heard and appreciated. He is a mentor.
An American by origin, Greg now calls Europe his home, having lived in the Netherlands for many years. While on this side of the pond, he has taken on an important leadership role in safeguarding and advocating for the interests of the open source community. This is most evident through his work on the Cyber Resilience Act, through which he has educated and interacted with countless open source contributors and advocates whose work is affected by this legislation.
We — if I may be so bold — the Open Source community in Europe — and yes, the whole world, in fact — appreciate your work and your excellence. Thank you, Greg. Please come on stage and collect your award.


The whole event
Here is the entire ceremony, from start to finish.








{kind=link}