Back in 2012, the Happy Eyeballs RFC 6555 was published. It details how a sensible Internet client should proceed when connecting to a server. It basically goes like this:
Give the IPv6 attempt priority, then with a delay start a separate IPv4 connection in parallel with the IPv6 one; then use the connection that succeeds first.
We also tend to call this connection racing, since it is like a competition where multiple attempts compete trying to “win”.
In a normal name resolve, a client may get a list of several IPv4 and IPv6 addresses to try. curl would then pick the first, try that and if that fails, move on the next etc. If a whole family fails, it would start the other immediately.
v2
The updated Happy Eyeballs v2 RFC 8305 was published in 2017. It focused a lot on that the client should start its connections earlier in the process, preferably while getting responses from DNS instead of waiting for the hostname resolve phase to end before starting that.
This is complicated for lots of clients because there is no established (POSIX) API for doing such name resolves, so for a portable network library like libcurl we could not follow most of the new advice in this spec.
QUIC added a dimension
In 2012 we did not have QUIC on the map and not practically in 2017 either so those eyeballing specs did not include such details.
Even later, HTTP/3 was documented to require an alt-svc response header before a client would know if the server speaks HTTP/3 and only then could it attempt QUIC with it and expect it to work.
While curl works with alt-svc response approach, that’s information arriving far too late for many users – and it is especially damning for a command line tool as opposed to a browser, since lots of users just do single shot transfers and then never get to use HTTP/3 at all.
To combat that drawback, we decided that adding QUIC to the mix should add a separate connection competition. To allow faster and earlier use of QUIC.
Start the QUIC-IPv6 connect attempt first, then in order the QUIC-IPv4, TCP-ipv6 and finally the TCP-ipv4.
To users, this typically makes a very smooth operation where the client just automatically connects to the “best” alternative without it having to make any particular choices or decisions. It graciously and transparently adapts to situations where IPv6 or UDP have problems etc.
v3 and HTTPS-RR
With the introduction of HTTPS-RR, there are also more ways introduced to get IP addresses for hosts and there is now ongoing work within the IETF on making a v3 of the Happy Eyeballs specification detailing how exactly everything should be put together.
We are of course following that development to monitor and learn how we should adapt and polish curl connects further.
Parallel more
While waiting on the happy eyeballs v3 work to land in a document, Stefan Eissing took it upon himself to further tweak how curl behaves in an attempt to find the best connection even faster. Using more parallelism.
Starting in curl 8.16.0, curl will start the first IPv6 and the first IPv4 connection attempts exactly like before, but then, if none of them have connected after 200 milliseconds curl continues to the next address in the list and starts another attempt in parallel.
An illustration
Let’s take a look at an example of curl connecting to a server, let’s call the server curl.se. The orange numbers show the order of things after the DNS response has been received.
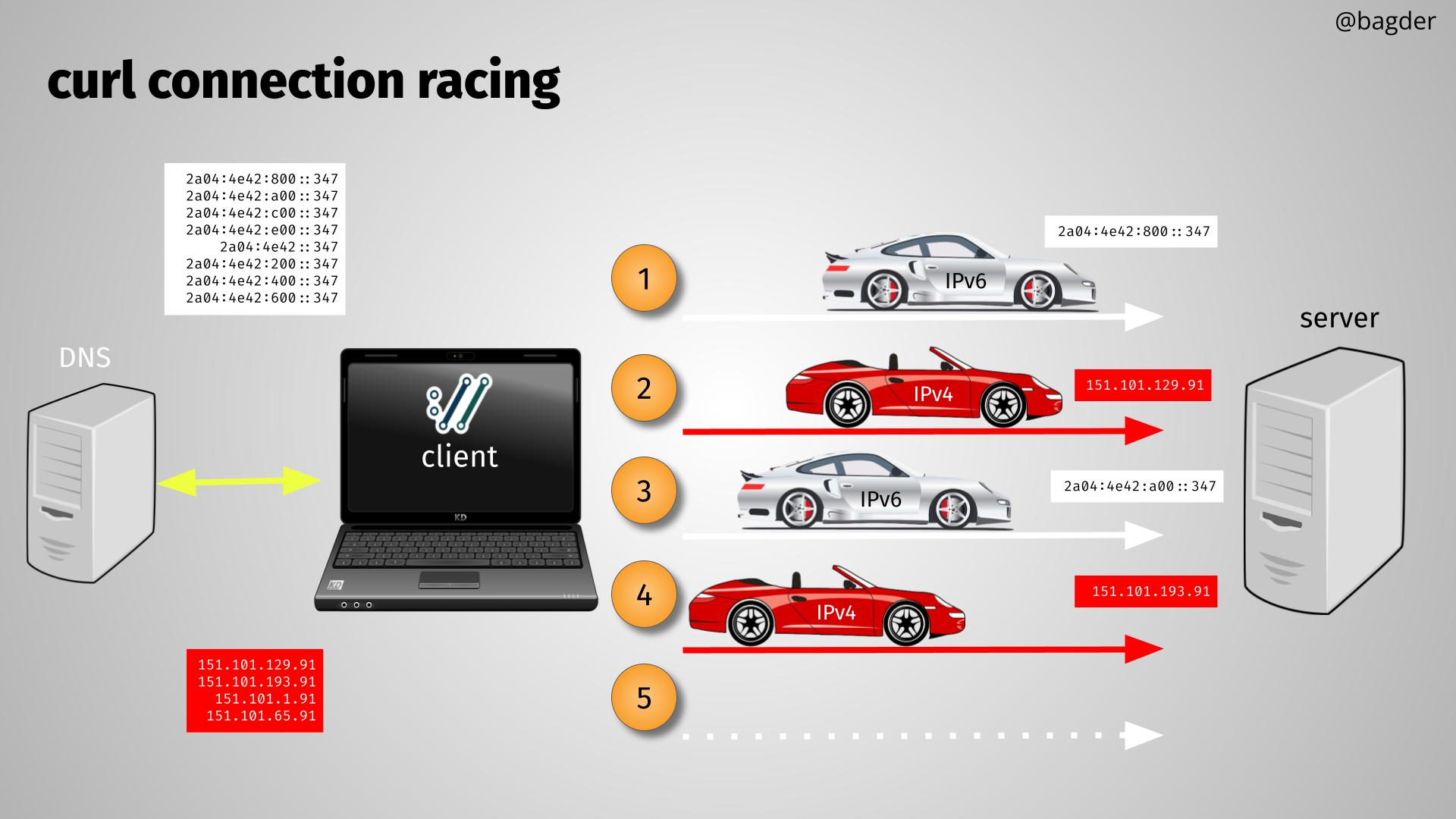
- The first connect attempt starts using the first IPv6 address from the DNS response. If it has not succeeded within 200 milliseconds…
- The second attempt starts in parallel, using the first IPv4 address. Now two connect attempts are running and if neither have succeeded in yet another 200 milliseconds…
- A second IPv6 connect attempt is started in parallel, using the second IPv6 address from the list. Now three connect attempts are racing. If none of them succeeds in another 200 milliseconds…
- A second IPv4 race starts, using the second IPv4 address from the list.
- … and this can continue, if this is a really slow or problematic server with many IP addresses.
Of course, each failed attempt makes curl immediately move to the next address in the list until all alternatives have been tested.
Add QUIC to that
The illustration above can be seen as “per transport”. If only TCP is wanted, there is a single such race going on. With potentially quite a few parallel attempts in the worst cases.
If instead HTTP/3 or a lower HTTP version is wanted, curl first starts a QUIC connection race as illustrated and then after 200 milliseconds it starts a similar TCP race in parallel to the QUIC one! Both run at the same time, the first one to connect wins.
A little table to illustrate when the different connect attempts starts when either QUIC or TCP is okay:
| Time (ms) | QUIC | TCP |
| 0 | Start IPv6 connect | – |
| 200 | Start IPv4 connect | Start IPv6 connect |
| 400 | Start 2nd IPv6 connect | Start IPv4 connect |
| 600 | Start 2nd IPv4 connect | Start 2nd IPv6 connect |
| 800 | Start 3rd IPv6 connect | Start 2nd IPv4 connect |
So in the case of trying to connect to a server that doesn’t respond that has more than two IPV6 and IPv4 addresses each, there could be nine connection attempts running after 801 milliseconds.
200 ms can be changed
The 200 milliseconds delay mentioned above is just the default time. It can easily be changed both using the library or the command line tool.
Credit
Image by Ilona Ilyés from Pixabay (heavily cropped)