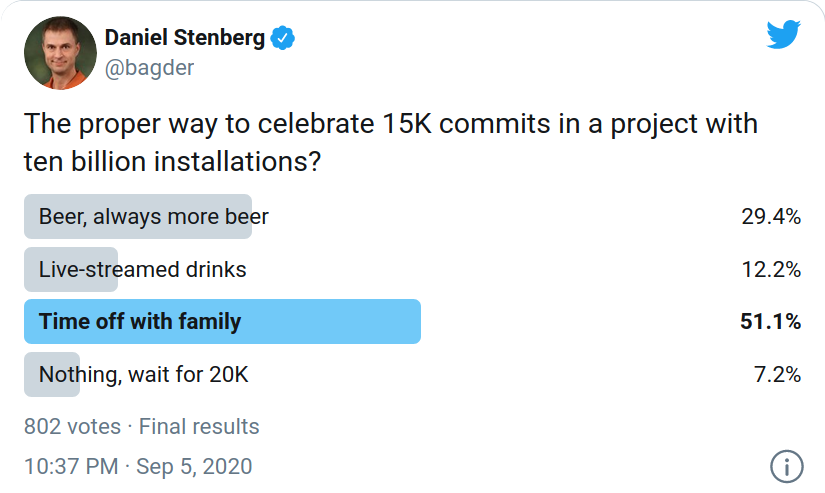Today, exactly three years ago, I received flowers, money and a gold medal at a grand prize ceremony that will forever live on in my mind and memory. I was awarded the Polhem Prize for my decades of work on curl. The prize itself was handed over to me by no one else than the Swedish king himself. One of the absolute top honors I can imagine in my little home country.
In some aspects, my life is divided into the life before this event and the life after. The prize has even made little me being presented on a poster in the Technical Museum in Stockholm. The medal itself still sits on my work desk and if I just stop starring at my monitors for a moment and glance a little over to the left – I can see it. I think the prize made my surroundings, my family and friends get a slightly different view and realization of what I actually do all these hours in front of my screens.
In the tree years since I received the prize, we’ve increased the total number of contributors and authors in curl by 50%. We’ve done over 3,700 commits and 25 releases since then. Upwards and onward.
Life moved on. It was not “peak curl”. There was no “prize curse” that left us unable to keep up the pace and development. It was possibly a “peak life moment” there for me personally. As an open source maintainer, I can’t imagine many bigger honors or awards to come my way ever again, but I’m not complaining. I got the prize and I still smile when I think about it.
In international curling competitions, each team is given 73 minutes to complete all of its throws. Welcome to curl 7.73.0.
Release presentation
Numbers
the 195th release 9 changes 56 days (total: 8,2XX) 135 bug fixes (total: 6,462) 238 commits (total: 26,316) 3 new public libcurl function (total: 85) 1 new curl_easy_setopt() option (total: 278) 2 new curl command line option (total: 234) 63 contributors, 31 new (total: 2,270) 35 authors, 17 new (total: 836) 0 security fix (total: 95) 0 USD paid in Bug Bounties(total: 2,800 USD)
Changes
We have to look back almost two years to find a previous release packed with more new features than this! The nine changes we’re bringing to the world this time are…
--output-dir
Tell curl where to store the file when you use -o or -O! Requested by users for a long time. Now available!
find .curlrc in $XDG_CONFIG_HOME
If this environment variable is set and there’s a .curlrc in there, it will now be used in preference to the other places curl will look for it.
--help has categories
The huge wall of text that --help previously gave us is now history. “curl --help” will now only show a few important options and the rest is provided if you tell curl which category you want to list help for. Requested by users for a long time.
API for meta-data about easy options
With three new functions, libcurl now provides an API for getting meta-data and information about all existing easy options that an application (possibly via a binding) can set for a transfer in libcurl.
CURLE_PROXY
We’ve introduced a new error code, and what makes this a little extra note-worthy besides just being a new way to signal a particular error, is that applications that receive this error code can also query libcurl for extended error information about what exactly in the proxy use or handshake that failed. The extended explanation is extracted with the new CURLINFO_PROXY_ERROR.
MQTT by default
This is the first curl release where MQTT support is enabled by default. We’ve had it marked experimental for a while, which had the effect that virtually nobody actually used it, tried it or even knew it existed. I’m very eager to get some actual feedback on this…
SFTP commands: atime and mtime
The “quote” functionality in curl which can sends custom commands to the SFTP server to perform various instructions now also supports atime and mtime for setting the access and modification times of a remote file.
knownhosts “fine replace” instruction
The “known hosts” feature is a SSH “thing” that lets an application get told if libcurl connects to a host that isn’t already listed in the known hosts file and what to do about it. This new feature lets the application return CURLKHSTAT_FINE_REPLACE which makes libcurl treat the host as “fine” and it will then replace the host key for that host in the known hosts file.
Elliptic curves
Assuming you use the supported backend, you can now select which curves libcurl should use in the TLS handshake, with CURLOPT_SSL_EC_CURVES for libcurl applications and with --curves for the command line tool.
Bug-fixes
As always, here follows a small selection of the many bug-fixes done this cycle.
buildconf: invoke ‘autoreconf -fi’ instead
Born in May 2001, this script was introduced to build configure etc so that you can run configure etc, when you’re building code straight from git (even if it was CVS back in 2001).
Starting now, the script just runs ‘autoreconf -fi‘ and no extra custom magic is needed.
checksrc: now even stricter
Our homegrown code style checker got better and now also verifies:
Mandatory space after do and before while in “do { } while“
No space allowed after an exclamation mark in if(!true) expressions
// comments are not allowed even on column 0
cmake: remove scary warning
The text that was previously output, saying that the cmake build has glitches has been removed. Not really because it has gotten much better, but to not scare people away, let them proceed and use cmake and then report problems and submit pull requests that fix them!
curl: lots of dynbuf in the tool
The libcurl internal system for doing “dynamic buffers” (strings) is now also used by the curl tool and a lot of custom realloc logic has been converted over.
curl: retry and delays in parallel mode
The --retry option didn’t work when doing parallel transfers, and when fixed, the retry delay option didn’t work either so that was also fixed!
etag: save and use the full received contents
We changed the handling of saving and loading etags a little bit, so that it now stores and loads the full etag contents and not just the bytes between double quotes. This has the added benefit that the etag functionality now also works with weak etags and when working with servers that don’t really follow the syntax rules for etags.
ftp: a 550 SIZE response returns CURLE_REMOTE_FILE_NOT_FOUND
Getting a 550 response back from a SIZE command will now make curl return at once saying the file is missing. Previously it would put that into the generic “SIZE doesn’t work” pool of errors, but that could lead to some inconsistent return codes.
ftp: make a 552 response return CURLE_REMOTE_DISK_FULL
Turns out that when uploading data to an FTP server, there’s a dedicated response code for the server to tell the client when the disk system is full (there was not room enough to store the file) and since there was also an existing libcurl return code for it, this new mapping thus made perfect sense…
ftp: separate FTPS from FTP over “HTTPS proxy”
The FTP code would previously wrongly consider a HTTPS proxy to euqal *using TLS” as if it was using TLS for its control channel, which made it wrongly use commands that are reserved for TLS connections.
libssh2: SSH protocols over HTTPS proxy
Some adjustments were necessary to make sure the SCP and SFTP work when spoken over an HTTPS proxy. Also note that this fix is only done for the libssh2 backend (primarily because I didn’t find out to do it in the others when I did a quick check).
pingpong: use dynbuf sending commands
I blogged about this malloc reducing adventure separately. The command sending function in curl for FTP, IMAP, POP3 and SMTP now reuses the same memory buffer much better over a transfer’s lifetime.
runtests: add %repeat[]% and %hex[]hex% for test files
One of the really nice benefits of “preprocessing” the text files and generate another file that is actually used for running tests, is that we now can provide meta-instructions to generate content when the test starts up. For example, we had tests that had a megabyte or several hundred kilobytes of text for test purposes, and how we can replace those with just a single %repeat% instruction. Makes test cases much smaller and much easier to read. %hex% can generate binary output given a hex string.
runtests: curl’s version as %VERSION
The test suite now knows which version of curl it tests, which means it can properly verify the User-Agent: headers in curl’s outgoing HTTP requests. We’ve previously had a filter system that would filter out such headers before comparing. Yours truly then got the pleasure of updating no less than 619 test cases to longer filter off that header for the comparison and instead use %VERSION!
win32: drop support for WinSock version 1
Apparently version 2 has been supported in Windows since Windows 95…
Future
Unless we’ve screwed up somewhere, the next release will be 7.74.0 and ship on December 9, 2020. We have several pending pull-requests already in the queue with new features and changes!
tldr: work has started to make Hyper work as a backend in curl for HTTP.
curl and its data transfer core, libcurl, is all written in C. The language C is known and infamous for not being memory safe and for being easy to mess up and as a result accidentally cause security problems.
At the same time, C compilers are very widely used and available and you can compile C programs for virtually every operating system and CPU out there. A C program can be made far more portable than code written in just about any other programming language.
curl is a piece of “insecure” C code installed in some ten billion installations world-wide. I’m saying insecure within quotes because I don’t think curl is insecure. We have our share of security vulnerabilities of course, even if I think the rate of them getting found has been drastically reduced over the last few years, but we have never had a critical one and with the help of busloads of tools and humans we find and fix most issues in the code before they ever land in the hands of users. (And “memory safety” is not the single explanation for getting security issues.)
I believe that curl and libcurl will remain in wide use for a long time ahead: curl is an established component and companion in scripts and setups everywhere. libcurl is almost a de facto standard in places for doing internet transfers.
A rewrite of curl to another language is not considered. Porting an old, established and well-used code base such as libcurl, which to a far degree has gained its popularity and spread due to a stable API, not breaking the ABI and not changing behavior of existing functionality, is a massive and daunting task. To the degree that so far it hasn’t been attempted seriously and even giant corporations who have considered it, have backpedaled such ideas.
Change, but not change
This preface above might make it seem like we’re stuck with exactly what we have for as long as curl and libcurl are used. But fear not: things are more complicated, or perhaps brighter, than it first seems.
What’s important to users of libcurl needs to be kept intact. We keep the API, the ABI, the behavior and all the documented options and features remain. We also need to continuously add stuff and keep up with the world going forward.
But we can change the internals! Refactor as the kids say.
Backends, backends, backends
Already today, you can build libcurl to use different “backends” for TLS, SSH, name resolving, LDAP, IDN, GSSAPI and HTTP/3.
A “backend” in this context is a piece of code in curl that lets you use a particular solution, often involving a specific third party library, for a certain libcurl functionality. Using this setup you can, for example, opt to build libcurl with one or more out of thirteen different TLS libraries. You simply pick the one(s) you prefer when you build it. The libcurl API remains the same to users, it’s just that some features and functionality might differ a bit. The number of TLS backends is of course also fluid over time as we add support for more libraries in the future, or even drop support for old ones as they fade away.
When building curl, you can right now make it use up to 33 different third party libraries for different functions. Many of them of course mutually exclusive, so no single build can use all 33.
Said differently: you can improve your curl and libcurl binaries without changing any code, by simply rebuilding it to use another backend combination.
Green boxes are possible third-party dependencies curl can be told to use. No Hyper in this map yet…
libcurl as a glorified switch
With an extensive set of backends that use third party libraries, the job of libcurl to a large extent becomes to act as a switch between the provided stable external API and the particular third party library that does the heavy lifting.
API <=> glue code in C <=> backend library
libcurl as the rock, with a door and the entry rules written in stone. The backends can come and go, change and improve, but the applications outside the entrance won’t notice that. They get a stable API and ABI that they know and trust.
Safe backends
This setup provides a foundation and infrastructure to offer backends written in other languages as part of the package. As long as those libraries have APIs that are accessible to libcurl, libraries used by the backends can be written in any language – but since we’re talking about memory safety in this blog post the most obvious choices would probably be one of the modern and safe languages. For example Rust.
With a backend library written in Rust , libcurl would lean on such a component to do low level protocol work and presumably, by doing this it increases the chances of the implementations to be safe and secure.
Two of the already supported third party libraries in the world map image above are written in Rust: quiche and Mesalink.
Hyper as a backend for HTTP
Hyper is a HTTP library written in Rust. It is meant to be fast, accurate and safe, and it supports both HTTP/1 and HTTP/2.
As another step into this world of an ever-growing number of backends to libcurl, work has begun to make sure curl (optionally) can get built to use Hyper.
This work is gracefully funded by ISRG, perhaps mostly known as the organization behind Let’s Encrypt. Thanks!
Many challenges remain
I want to emphasize that this is early days. We know what we want to do, we know basically how to do it but from there to actually getting it done and providing it in source code to the world is a little bit of work that hasn’t been done. I’m set out to do it.
Hyper didn’t have a C API, they’re working on making one so that C based applications such as curl can actually use it. I do my best at providing feedback from my point of view, but as I’m not really into Rust much I can’t assist much with the implementation parts there.
Once there’s an early/alpha version of the API to try out, I will first make sure curl can get built to use Hyper, and then start poking on the code to start using it.
In that work I expect me to have to go back to the API with questions, feedback and perhaps documentation suggestions. I also anticipate challenges in switching libcurl internals to using this. Mostly small ones, but possibly also larger ones.
I have created a git branch and make my work on this public and accessible early on to let everyone who wants to, to keep up with the development. A first milestone will be the ability to run a single curl test case (any test case) successfully – unmodified. The branch is here: https://github.com/curl/curl/tree/bagder/hyper – beware that it will be rebased frequently.
There’s no deadline for this project and I don’t yet have any guesses as when there will be anything to test.
Rust itself is not there yet
This project is truly ground work for future developers to build upon as some of the issues dealt with in here should benefit others as well down the road. For example it immediately became obvious that Rust in general encourages to abort on out-of-memory issues, while this is a big nono when the code is used in a system library (such as curl).
I’m a bit vague on the details here because it’s not my expertise, but Rust itself can’t even properly clean up its memory and just returns error when it hits such a condition. Clearly something to fix before a libcurl with hyper could claim identical behavior and never to leak memory.
By default?
Will Hyper be used by default in a future curl build near you?
We’re going to work on the project to make that future a possibility with the mindset that it could benefit users.
If it truly happens involve many different factors (for example maturity, feature set, memory footprint, performance, portability and on-disk footprint…) and in particular it will depend a lot on the people that build and ship the curl packages you use – which isn’t the curl project itself as we only ship source code. I’m thinking of Linux and operating system distributions etc.
When it might happen we can’t tell yet as we’re still much too early in this process.
Still a lot of C
This is not converting curl to Rust.
Don’t be fooled into believing that we are getting rid of C in curl by taking this step. With the introduction of a Hyper powered backend, we will certainly reduce the share of C code that is executed in a typical HTTP transfer by a measurable amount (for those builds), but curl is much more than that.
It’s not even a given that the Hyper backend will “win” the competition for users against the C implementation on the platforms you care about. The future is not set.
More backends in safe languages?
Sure, why not? There are efforts to provide more backends written in Rust. Gradually, we might move into a future where less and less of the final curl and libcurl executable code was compiled from C.
How and if that will happen will of course depend on a lot of factors – in particular funding of the necessary work.
Can we drive the development in this direction even further? I think it is much too early to speculate on that. Let’s first see how these first few episodes into the coming decades turn out.
At the time of that blog post, the book was already at 13,000 words and 115 written subsections. I still had that naive hope that I would have it nearly “complete” by the summer of 2016. Always the optimist.
Today, the book is at over 72,000 words with content in 600 subsections – with just 21 subtitles noted “TBD” to signal that there’s still content to add there. The PDF version of it now clocks in at over 400 pages.
I’ve come to realize and accept that it will never be “complete” and that we will just keep on working on it indefinitely since curl itself keeps changing and we keep improving and expanding texts in the book.
Right now, we have 21 sections marked as not done, but then we’ve also added features through these five years that we haven’t described in the book yet. And there are probably other areas still missing too that would benefit the book to add. There’s no hurry, we’ll just add more content when we get around to it.
Everything curl is quite clearly the most complete book and resource about curl, libcurl, the project and how all of it works. We have merged contributions from 39 different authors and we’re always interested in getting more help!
Printed version
We’ve printed two editions of the book. The 2017 and the 2018 versions. As of 2020, the latest edition is out of print. If you really want one, email Dan Fandrich as mention on the web page this link takes you to. Maybe we can make another edition reality again.
The book was always meant to remain open and free, we only sell the printed version because it costs actual money to produce it.
For a long time we also offered e-book versions of everything curl, but sadly gitbooks removed those options in a site upgrade a while ago so now unfortunately we only offer a web version and a PDF version.
Other books?
There are many books that mention curl and that have sections or parts devoted to various aspects of curl but there are not many books about just curl. curl programming (by Dan Gookin) is one of those rare ones.
Everyone needs something fun to do in their spare time. And digging deep into curl internals is mighty fun!
One of the things I do in curl every now and then is to run a few typical command lines and count how much memory is allocated and how many memory allocation calls that are made. This is good project hygiene and is a basic check that we didn’t accidentally slip in a malloc/free sequence in the transfer path or something.
We have extensive memory checks for leaks etc in the test suite so I’m not worried about that. Those things we detect and fix immediately, even when the leaks occur in error paths – thanks to our fancy “torture tests” that do error injections.
The amount of memory needed or number of mallocs used is more of a boiling frog problem. We add one now, then another months later and a third the following year. Each added malloc call is motivated within the scope of that particular change. But taken all together, does the pattern of memory use make sense? Can we make it better?
How?
Now this is easy because when we build curl debug enabled, we have a fancy logging system (we call it memdebug) that logs all calls to “fallible” system functions so after the test is completed we can just easily grep for them and count. It also logs the exact source code and line number.
cd tests
./runtests -n [number]
egrep -c 'alloc|strdup' log/memdump
Let’s start
Let me start out with a look at the history and how many allocations (calloc, malloc, realloc or strdup) we do to complete test 103. The reason I picked 103 is somewhat random, but I wanted to look at FTP and this test happens to do an “active” transfer of content and makes a total of 10 FTP commands in the process.
The reason I decided to take a closer look at FTP this time is because I fixed an issue in the main ftp source code file the other day and that made me remember the Curl_pp_send() function we have. It is the function that sends FTP commands (and IMAP, SMTP and POP3 commands too, the family of protocols we refer to as the “ping pong protocols” internally because of their command-response nature and that’s why it has “pp” in the name).
When I reviewed the function now with my malloc police hat on, I noticed how it made two calls to aprintf(). Our printf version that returns a freshly malloced area – which can even cause several reallocs in the worst case. But this meant at least two mallocs per issued command. That’s a bit unnecessary, isn’t it?
What about a few older versions
I picked a few random older versions, checked them out from git, built them and counted the number of allocs they did for test 103:
7.52.1: 141 7.68.0: 134 7.70.0: 137 7.72.0: 123
It’s been up but it has gone down too. Nothing alarming, Is that a good amount or a bad amount? We shall see…
Cleanup step one
The function gets printf style arguments and sends them to the server. The sent command also needs to append CRLF to the data. It was easy to make sure the CRLF appending wouldn’t need an extra malloc. That was just sloppy of us to have there in the first place. Instead of mallocing the new printf format string with CRLF appended, it could use one in a stack based buffer. I landed that as a first commit.
This trimmed off 10 mallocs for test 103.
Step two, bump it up a notch
The remaining malloc allocated the memory block for protocol content to send. It can be up to several kilobytes but is usually just a few bytes. It gets allocated in case it needs to be held on to if the entire thing cannot be sent off over the wire immediately. Remember, curl is non-blocking internally so it cannot just sit waiting for the data to get transferred.
I switched the malloc’ed buffer to instead use a ‘dynbuf’. That’s our internal “dynamic buffer” system that was introduced earlier this year and that we’re gradually switching all internals over to use instead of doing “custom” buffer management in various places. The internal API for dynbuf is documented here.
The internal API Curl_dyn_addf() adds a printf()-style string at the end of a “dynbuf”, and it seemed perfectly suitable to use here. I only needed to provide a vprintf() alternative since the printf() format was already received by Curl_pp_sendf()… I created Curl_dyn_vaddf() for this.
This single dynbuf is kept for the entire transfer so that it can be reused for subsequent commands and grow only if needed. Usually the initial 32 bytes malloc should be sufficient for all commands.
Not good enough
It didn’t help!
Counting the mallocs showed me with brutal clarity that my job wasn’t done there. Having dug this deep already I wasn’t ready to give this up just yet…
Why? Because Curl_dyn_addf() was still doing a separate alloc of the printf string that it then appended to the dynamic buffer. But okay, having our own printf() implementation in the code has its perks.
Add a printf() string without extra malloc
Back in May 2020 when I introduced this dynbuf thing, I converted the aprintf() code over to use dynbuf to truly unify our use of dynamically growing buffers. That was a main point with it after all.
As all the separate individual pieces I needed for this next step were already there, all I had to do was to add a new entry point to the printf() code that would accept a dynbuf as input and write directly into that (and grow it if needed), and then use that new function (Curl_dyn_vprintf) from the Curl_dyn_addf().
Phew. Now let’s see what we get…
There are 10 FTP commands that previously did 2 mallocs each: 20 mallocs were spent in this function when test 103 was executed. Now we are down to the ideal case of one alloc in there for the entire transfer.
Test 103 after polish
The code right now in master (to eventually get released as 7.73.0 in a few weeks), now shows a total of 104 allocations. Down from 123 in the previous release, which not entirely surprising is 19 fewer and thus perfectly matching the logic above.
All tests and CI ran fine. I merged it. This is a change that benefits all transfers done with any of the “ping pong protocols”. And it also makes the code easier to understand!
Compared to curl 7.52.1, this is a 26% reduction in number of allocation; pretty good, but even compared to 7.72.0 it is still a 15% reduction.
More?
There is always more to do, but there’s also a question of diminishing returns. I will continue to look at curl’s memory use going forward too and make sure everything is motivated and reasonable. At least every once in a while.
I have some additional ideas for further improvements in the memory use area to look into. We’ll see if they pan out…
Don’t count on me to blog about every such finding with this level of detail! If you want to make sure you don’t miss any of these fine-tunes in the future, follow the curl github repo.
Earlier this year I was the recipient of a monetary Google patch grant with the expressed purpose of improving security in libcurl.
This was an upfront payout under this Google program describing itself as “an experimental program that rewards proactive security improvements to select open-source projects”.
I accepted this grant for the curl project and I intend to keep working fiercely on securing curl. I recognize the importance of curl security as curl remains one of the most widely used software components in the world, and even one that is doing network data transfers which typically is a risky business. curl is responsible for a measurable share of all Internet transfers done over the Internet an average day. My job is to make sure those transfers are done as safe and secure as possible. It isn’t my only responsibility of course, as I have other tasks to attend to as well, but still.
Do more
Security is already and always a top priority in the curl project and for myself personally. This grant will of course further my efforts to strengthen curl and by association, all the many users of it.
What I will not do
When security comes up in relation to curl, some people like to mention and propagate for other programming languages, But curl will not be rewritten in another language. Instead we will increase our efforts in writing good C and detecting problems in our code earlier and better.
Proactive counter-measures
Things we have done lately and working on to enforce everywhere:
String and buffer size limits – all string inputs and all buffers in libcurl that are allowed to grow now have a maximum allowed size, that makes sense. This stops malicious uses that could make things grow out of control and it helps detecting programming mistakes that would lead to the same problems. Also, by making sure strings and buffers are never ridiculously large, we avoid a whole class of integer overflow risks better.
Unified dynamic buffer functions – by reducing the number of different implementations that handle “growing buffers” we reduce the risk of a bug in one of them, even if it is used rarely or the spot is hard to reach with and “exercise” by the fuzzers. The “dynbuf” internal API first shipped in curl 7.71.0 (June 2020).
Realloc buffer growth unification – pretty much the same point as the previous, but we have earlier in our history had several issues when we had silly realloc() treatment that could lead to bad things. By limiting string sizes and unifying the buffer functions, we have reduced the number of places we use realloc and thus we reduce the number of places risking new realloc mistakes. The realloc mistakes were usually in combination with integer overflows.
Code style – we’ve gradually improved our code style checker (checksrc.pl) over time and we’ve also gradually made our code style more strict, leading to less variations in code, in white spacing and in naming. I’m a firm believer this makes the code look more coherent and therefore become more readable which leads to fewer bugs and easier to debug code. It also makes it easier to grep and search for code as you have fewer variations to scan for.
More code analyzers – we run every commit and PR through a large number of code analyzers to help us catch mistakes early, and we always remove detected problems. Analyzers used at the time of this writing: lgtm.com, Codacy, Deepcode AI, Monocle AI, clang tidy, scan-build, CodeQL, Muse and Coverity. That’s of course in addition to the regular run-time tools such as valgrind and sanitizer builds that run the entire test suite.
Memory-safe components – curl already supports getting built with a plethora of different libraries and “backends” to cater for users’ needs and desires. By properly supporting and offering users to build with components that are written in for example rust – or other languages that help developers avoid pitfalls – future curl and libcurl builds could potentially avoid a whole section of risks. (Stay tuned for more on this topic in a near future.)
Reactive measures
Recognizing that whatever we do and however tight ship we run, we will continue to slip every once in a while, is important and we should make sure we find and fix such slip-ups as good and early as possible.
Raising bounty rewards. While not directly fixing things, offering more money in our bug-bounty program helps us get more attention from security researchers. Our ambition is to gently drive up the reward amounts progressively to perhaps multi-thousand dollars per flaw, as long as we have funds to pay for them and we mange keep the security vulnerabilities at a reasonably low frequency.
More fuzzing. I’ve said it before but let me say it again: fuzzing is really the top method to find problems in curl once we’ve fixed all flaws that the static analyzers we use have pointed out. The primary fuzzing for curl is done by OSS-Fuzz, that tirelessly keeps hammering on the most recent curl code.
Good fuzzing needs a certain degree of “hand-holding” to allow it to really test all the APIs and dig into the dustiest corners, and we should work on adding more “probes” and entry-points into libcurl for the fuzzer to make it exercise more code paths to potentially detect more mistakes.
I’ve long maintained that persistence is one of the main qualities you need in order to succeed with your (software) project. In order to manage to ship a product that truly conquers the world. By continuously and never-ending keeping at it: polishing away flaws and adding good features. On and on and on.
Today marks the day when I landed my 15,000th commit in the master branch in curl’s git repository – and we don’t do merge commits so this number doesn’t include such. Funnily enough, GitHub can’t count and shows a marginally lower number.
This is of course a totally meaningless number and I’m only mentioning it here because it’s even and an opportunity for me to celebrate something. To cross off an imaginary milestone. This is not even a year since we passed 25,000 total number of commits. Another meaningless number.
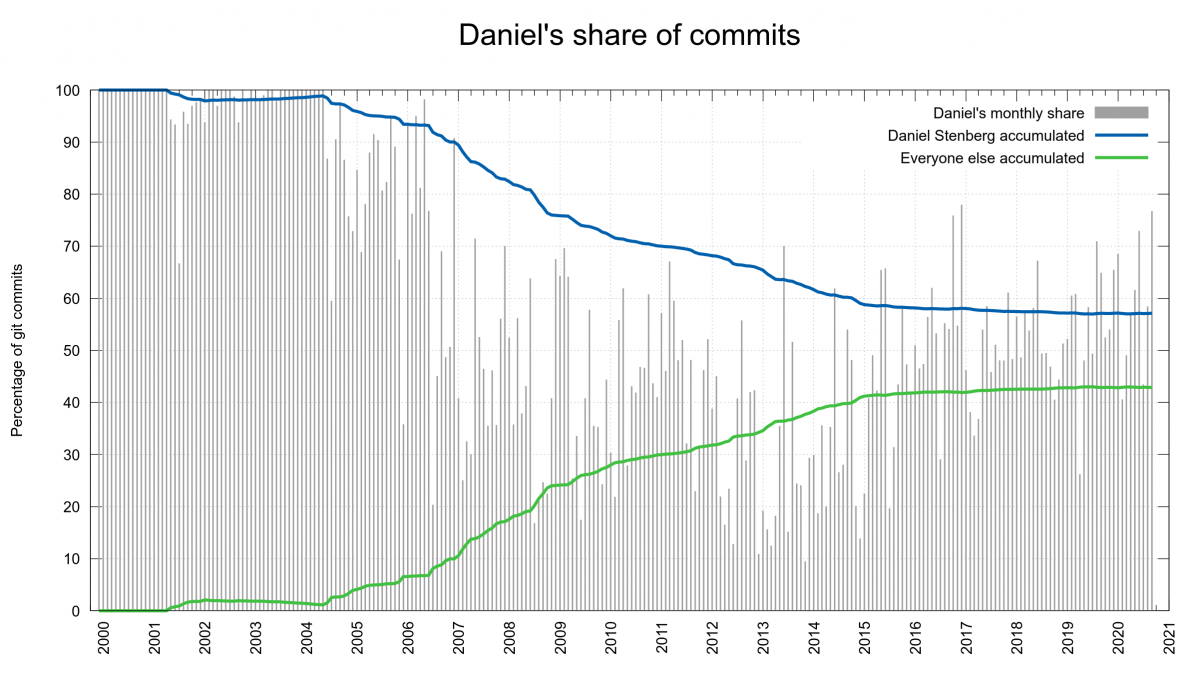
15,000 commits equals 57% of all commits done in curl so far and it makes me the only committer in the curl project with over 10% of the commits.
The curl git history starts on December 29 1999, so the first 19 months of commits from the early curl history are lost. 15,000 commits over this period equals a little less than 2 commits per day on average. I reached 10,000 commits in December 2011, so the latest 5,000 commits were done at a slower pace than the first 10,000.
I estimate that I’ve spent more than 15,000 hours working on curl over this period, so it would mean that I spend more than one hour of “curl time” per commit on average. According to gitstats, these 15,000 commits were done on 4,271 different days.
We also have other curl repositories that aren’t included in this commit number. For example, I have done over 4,400 commits in curl’s website repository.
With these my first 15,000 commits I’ve added 627,000 lines and removed 425,000, making an average commit adding 42 and removing 28 lines. (Feels pretty big but I figure the really large ones skew the average.)
The largest time gap ever between two of my commits in the curl tree is almost 35 days back in June 2000. If we limit the check to “modern times”, as in 2010 or later, there was a 19 day gap in July 2015. I do take vacations, but I usually keep up with the most important curl development even during those.
On average it is one commit done by me every 12.1 hours. Every 15.9 hours since 2010.
I’ve been working full time on curl since early 2019, up until then it was a spare time project only for me. Development with pull-requests and CI and things that verify a lot of the work before merge is a recent thing so one explanation for a slightly higher commit frequency in the past is that we then needed more “oops” commits to rectify mistakes. These days, most of them are done in the PR branches that are squashed when subsequently merged into master. Fewer commits with higher quality.
curl committers
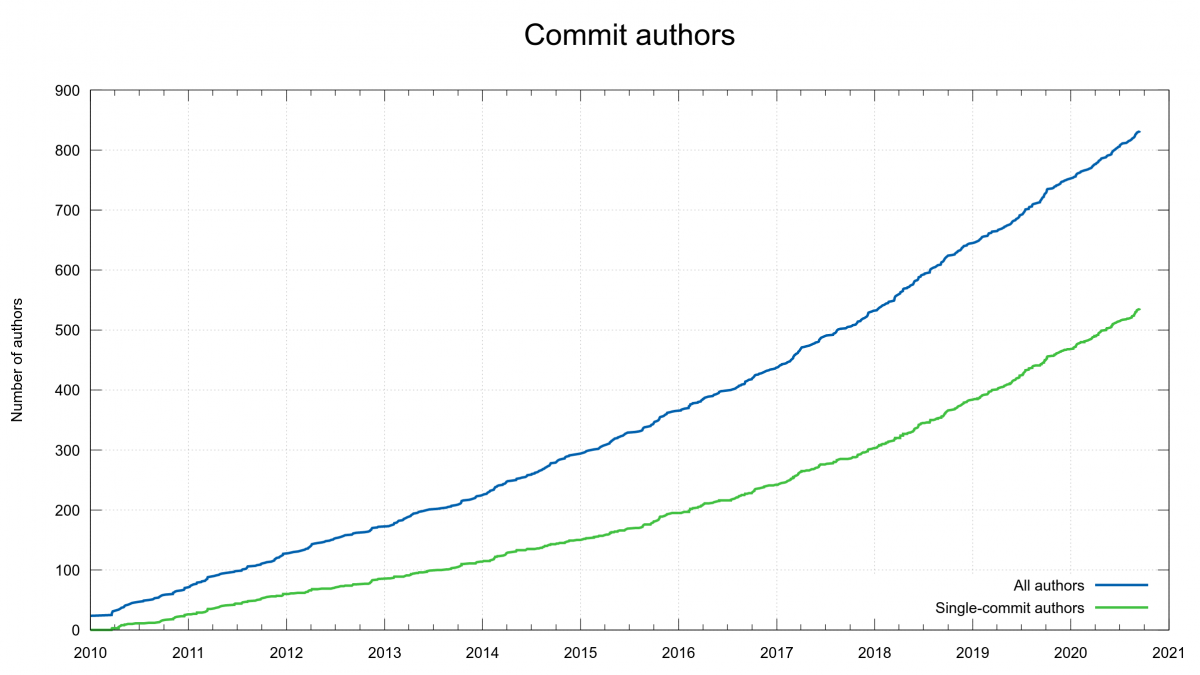
We have merged commits authored by over 833 authors into the curl master repository. Out of these, 537 landed only a single commit (so far).
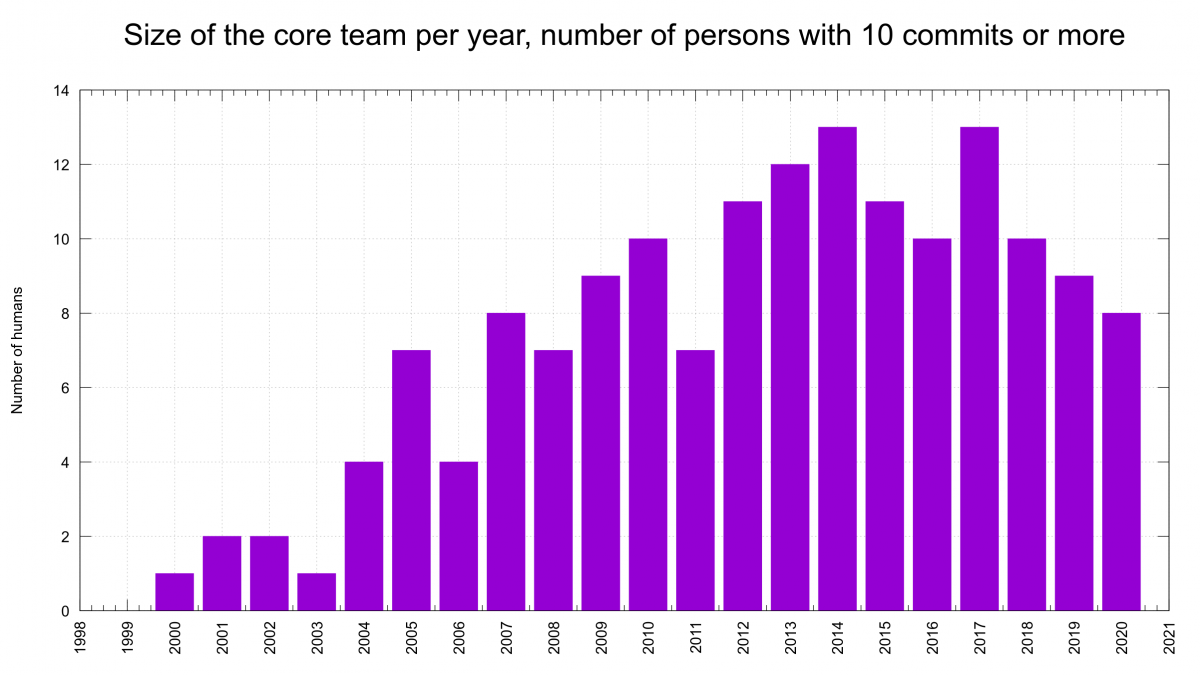
We are 48 authors who ever wrote 10 or more commits within the same year. 20 of us committed that amount of commits during more than one year.
We are 9 authors who wrote more than 1% of the commits each.
We are 5 authors who ever wrote 10 or more commits within the same year in 10 or more years.
Our second-most committer (by commit count) has not merged a commit for over seven years.
To reach curl’s top-100 committers list right now, you only need to land 6 commits.
can I keep it up?
I intend to stick around in the curl project going forward as well. If things just are this great and life remains fine, I hope that I will be maintaining roughly this commit speed for years to come. My prediction is therefore that it will take longer than another twenty years to reach 30,000 commits.
I’ve worked on curl and its precursors for almost twenty-four years. In another twenty-four years I will be well into my retirement years. At some point I will probably not be fit to shoulder this job anymore!
I have never planned long ahead before and I won’t start now. I will instead keep focused on keeping curl top quality, an exemplary open source project and a welcoming environment for newcomers and oldies alike. I will continue to make sure the project is able to function totally independently if I’m present or not.
The 15,000th commit?
So what exactly did I change in the project when I merged my 15,000th ever change into the branch?
It was a pretty boring and non-spectacular one. I removed a document (RESOURCES) from the docs/ folder as that has been a bit forgotten and now is just completely outdated. There’s a much better page for this provided on the web site: https://curl.haxx.se/rfc/
Celebrations!
I of coursed asked my twitter friends a few days ago on how this occasion is best celebrated:
tldr: --output-dir [directory] comes in curl 7.73.0
The curl options to store the contents of a URL into a local file, -o (--output) and -O (--remote-name) were part of curl 4.0, the first ever release, already in March 1998.
Even though we often get to hear from users that they can’t remember which of the letter O’s to use, they’ve worked exactly the same for over twenty years. I believe the biggest reason why they’re hard to keep apart is because of other tools that use similar options for maybe not identical functionality so a command line cowboy really needs to remember the exact combination of tool and -o type.
Later on, we also brought -J to further complicate things. See below.
Let’s take a look at what these options do before we get into the new stuff:
--output [file]
This tells curl to store the downloaded contents in that given file. You can specify the file as a local file name for the current directory or you can specify the full path. Example, store the the HTML from example.org in "/tmp/foo":
curl -o /tmp/foo https://example.org
--remote-name
This option is probably much better known as its short form: -O (upper case letter o).
This tells curl to store the downloaded contents in a file name name that is extracted from the given URL’s path part. For example, if you download the URL "https://example.com/pancakes.jpg" users often think that saving that using the local file name “pancakes.jpg” is a good idea. -O does that for you. Example:
curl -O https://example.com/pancakes.jpg
The name is extracted from the given URL. Even if you tell curl to follow redirects, which then may go to URLs using different file names, the selected local file name is the one in the original URL. This way you know before you invoke the command which file name it will get.
--remote-header-name
This option is commonly used as -J (upper case letter j) and needs to be set in combination with --remote-name.
This makes curl parse incoming HTTP response headers to check for a Content-Disposition: header, and if one is present attempt to parse a file name out of it and then use that file name when saving the content.
This then naturally makes it impossible for a user to be really sure what file name it will end up with. You leave the decision entirely to the server. curl will make an effort to not overwrite any existing local file when doing this, and to reduce risks curl will always cut off any provided directory path from that file name.
Example download of the pancake image again, but allow the server to set the local file name:
curl -OJ https://example.com/pancakes.jpg
(it has been said that “-OJ is a killer feature” but I can’t take any credit for having come up with that.)
Which directory
So in particular with -O, with or without -J, the file is download in the current working directory. If you want the download to be put somewhere special, you had to first ‘cd’ there.
When saving multiple URLs within a single curl invocation using -O, storing those in different directories would thus be impossible as you can only cd between curl invokes.
Introducing --output-dir
In curl 7.73.0, we introduce this new command line option --output-dir that goes well together with all these output options. It tells curl in which directory to create the file. If you want to download the pancake image, and put it in $HOME/tmp no matter which your current directory is:
This new option also goes well in combination with --create-dirs, so you can specify a non-existing directory with --output-dir and have curl create it for the download and then store the file in there:
curl 4.8 was released in 1998 and contained 46 command line options. curl --help would list them all. A decent set of options.
When we released curl 7.72.0 a few weeks ago, it contained 232 options… and curl --help still listed all available options.
What was once a long list of options grew over the decades into a crazy long wall of text shock to users who would enter this command and option, thinking they would figure out what command line options to try next.
–help me if you can
We’ve known about this usability flaw for a while but it took us some time to figure out how to approach it and decide what the best next step would be. Until this year when long time curl veteran Dan Fandrich did his presentation at curl up 2020 titled –help me if you can.
Emil Engler subsequently picked up the challenge and converted ideas surfaced by Dan into reality and proper code. Today we merged the refreshed and improved --help behavior in curl.
Perhaps the most notable change in curl for many users in a long time. Targeted for inclusion in the pending 7.73.0 release.
help categories
First out, curl --help will now by default only list a small subset of the most “important” and frequently used options. No massive wall, no shock. Not even necessary to pipe to more or less to see proper.
Then: each curl command line option now has one or more categories, and the help system can be asked to just show command line options belonging to the particular category that you’re interested in.
For example, let’s imagine you’re interested in seeing what curl options provide for your HTTP operations:
$ curl --help http
Usage: curl [options…]
http: HTTP and HTTPS protocol options
--alt-svc Enable alt-svc with this cache file
--anyauth Pick any authentication method
--compressed Request compressed response
-b, --cookie Send cookies from string/file
-c, --cookie-jar Write cookies to after operation
-d, --data HTTP POST data
--data-ascii HTTP POST ASCII data
--data-binary HTTP POST binary data
--data-raw HTTP POST data, '@' allowed
--data-urlencode HTTP POST data url encoded
--digest Use HTTP Digest Authentication
[...]
list categories
To figure out what help categories that exists, just ask with curl --help category, which will show you a list of the current twenty-two categories: auth, connection, curl, dns, file, ftp, http, imap, misc, output, pop3, post, proxy, scp, sftp, smtp, ssh, telnet ,tftp, tls, upload and verbose. It will also display a brief description of each category.
Each command line option can be put into multiple categories, so the same one may be displayed in both in the “http” category as well as in “upload” or “auth” etc.
--help all
You can of course still get the old list of every single command line option by issuing curl --help all. Handy for grepping the list and more.
“important”
The meta category “important” is what we use for the options that we show when just curl --help is issued. Presumably those options should be the most important, in some ways.
Credits
Code by Emil Engler. Ideas and research by Dan Fandrich.
I think it is fair to say that libcurl is a library that is very widely spread, widely used and powers a sizable share of Internet transfers. It’s age, it’s availability, it’s stability and its API contribute to it having gotten to this position.
libcurl is in a position where it could remain for a long time to come, unless we do something wrong and given that we stay focused on what we are and what we’re here for. I believe curl and libcurl might still be very meaningful in ten years.
Bindings are key
Another explanation is the fact that there are a large number of bindings to libcurl. A binding is a piece of code that allows libcurl to be used directly and conveniently from another programming language. Bindings are typically authored and created by enthusiasts of a particular language. To bring libcurl powers to applications written in that language.
The list of known bindings we feature on the curl web sites lists around 70 bindings for 62 something different languages. You can access and use libcurl with (almost) any language you can dream of. I figure most mortals can’t even name half that many programming languages! The list starts out with Ada95, Basic, C++, Ch, Cocoa, Clojure, D, Delphi, Dylan, Eiffel, Euphoria and it goes on for quite a while more.
Keeping bindings in sync is work
The bindings are typically written to handle transfers with libcurl as it was working at a certain point in time, knowing what libcurl supported at that moment. But as readers of this blog and followers of the curl project know, libcurl keeps advancing and we change and improve things regularly. We add functionality and new features in almost every new release.
This rather fast pace of development offers a challenge to binding authors, as they need to write the binding in a very clever way and keep up with libcurl developments in order to offer their users the latest libcurl features via their binding.
With libcurl being the foundational underlying engine for so many applications and the number of applications and services accessing libcurl via bindings is truly uncountable – this work of keeping bindings in sync is not insignificant.
If we can provide mechanisms in libcurl to ease that work and to reduce friction, it can literally affect the world.
“easy options” are knobs and levers
Users of the libcurl knows that one of the key functions in the API is the curl_easy_setopt function. Using this function call, the application sets specific options for a transfer, asking for certain behaviors etc. The URL to use, user name, authentication methods, where to send the output, how to provide the input etc etc.
At the time I write this, this key function features no less than 277 different and well-documented options. Of course we should work hard at not adding new options unless really necessary and we should keep the option growth as slow as possible, but at the same time the Internet isn’t stopping and as the whole world is developing we need to follow along.
Options generally come using one of a set of predefined kinds. Like a string, a numerical value or list of strings etc. But the names of the options and knowing about their existence has always been knowledge that exists in the curl source tree, requiring each bindings to be synced with the latest curl in order to get knowledge about the most recent knobs libcurl offers.
Until now…
Introducing an easy options info API
Starting in the coming version 7.73.0 (due to be released on October 14, 2020), libcurl offers API functions that allow applications and bindings to query it for information about all the options this libcurl instance knows about.
curl_easy_option_next lets the application iterate over options, to either go through all of them or a set of them. For each option, there’s details to extract about it that tells what kind of input data that option expects.
curl_easy_option_by_name allows the application to look up details about a specific option using its name. If the application instead has the internal “id” for the option, it can look it up using curl_easy_option_by_id.
With these new functions, bindings should be able to better adapt to the current run-time version of the library and become less dependent on syncing with the latest libcurl source code. We hope this will make it easier to make bindings stay in sync with libcurl developments.
Legacy is still legacy
Lots of bindings have been around for a long time and many of them of course still want to support libcurl versions much older than 7.73.0 so jumping onto this bandwagon of new fancy API for this will not be an instant success or take away code needed for that long tail of old version everyone wants to keep supporting.
We can’t let the burden of legacy stand in the way for improvement and going forward. At least if you find that you are lucky enough to have 7.73.0 or later installed, you can dynamically figure out these things about options. Maybe down the line the number of legacy versions will shrink. Maybe if libcurl still is relevant in ten years none of the pre curl 7.73.0 versions need to be supported anymore!
Credits
Lots of the discussions and ideas for this API come from Jeroen Ooms, author of the R binding for libcurl.