To get good results from Google’s Summer of Code, we need a fair amount of volunteering mentors and we need a good set of interesting projects to make students get attracted.
If your interest is in the Rockbox project, add your project ideas or add yourself as mentor on this wiki page.
If your interest is in the cURL project, read this page about the existing ideas and provide new ones or submit yourself as mentor on the mailing list!
Organizations can apply for becoming part of this starting tomorrow, March 3 2008.
Information to this was mailed to me from a friend but is easily verified as I’ll describe below.
America Online in the UK (AOL UK) is using our cURL application (without including the license anywhere) as part of their automated broadband router configuration CD for their AOL UK customer base. The CD is provided to all AOL UK customers and the automated router configuration component using cURL has been included with it for a couple of years.
The software includes the cURL application renamed to “AOL_Broadband_Installer.EXE“. There is no license included or mention of the license anywhere on the CD or installer, contrary to what’s required at http://curl.haxx.se/docs/copyright.html.
The md5sum for AOL_Broadband_Installer.EXE matches the win32 binary in the curl-7.15.3-win32-nossl.zip release package I personally built and offer for download…!
If you want to check it out yourself, the direct link I figured out to the installer is here and I found it on this page (download the “easy installer” for Netgear DG834G).
In case you haven’t read it before, Randy Bush‘s 55 page PDF slide show named “IPv6 Transition & Operational Reality” is a harsh (but quite accurate) description of how the IPv6 protocol was made, where some of its major problems lie and why the transition is going so slow etc.
I tried to find some official and recent figures or statements from some of the more IPv6-positive people and companies, but I failed to find much updates from after the year 2000 or so…
Speaking of network things that aren’t so successfully deployed: DNSSEC. Apparently iis.se (runs the Swedish TLD) tested 10 broadband routers (article and PDF in Swedish only) how well they support this (I believe mainly because .se tries to be a pioneer in DNSSEC), and 7 of the tested ones failed… Personally I’ve never liked the fact that DNSSEC isn’t really crafted to do it securely all the way.
So the big fancy (and often ridiculously stupid) Swedish IT news site idg.se opened up a “blogging” portal, and in there we find an at least semi-interesting open source blog named Open Force. Contrary to linuxworld.idg.se, it doesn’t look exactly like they just suck out all the news from slashdot, linux.com and linux today and translate them to Swedish.
But of course the author (Niklas Andersson) is but a journalist and not an open source contributor, why I fear it may very well keep up with the rest of idg.se anyway.
I’ll try to keep an eye on it and give it the benefit of the doubt for a while.
Update: it should possibly be noted that “Open Force” – despite the name – is written entirely in Swedish.
If so, this is no point unless we can at least present a bunch of interesting projects to lure students to us to have them work to improve (lib)curl and do stuff we otherwise might have a hard time to get done.
What things would you like to see that you consider would be a good project for a student to work on during the summer 2008?
New protocols? Fixing the last remaining blocking calls within libcurl? Fixing up/replacing language bindings? It’s not strictly a requirement that we come up with the best ideas since students apply with their own suggestion anyway, but we can provide good suggestions and ideas that will make students attracted to us and make them select to work for our project – should we be selected as a mentor organization.
Yes, as I hinted earlier Google is indeed going to do their very much appreciated program once again this year. Google’s summer of code accepts mentoring organizations to apply starting March 3rd 2008.
Now let’s get our imaginations and get some even better project ideas added to our gsoc 2008 wiki page!
They really make me want one of these to play with. Unfortunately, all the software Johnny’s done for this that is available on his site seems to be C# for Windows! ;-(
There is reason to suspect that there’s an upcoming announcement from Google about their Summer of Code 2008, so for the Rockbox project it might be just about time to start thinking about what particular projects we’d like to see done this time!
Of course it is also time to look back on how we performed last year and to consider what we should improve to make sure we do it better this time (should we be accepted again). After all, we got 4 projects assigned, two are now in SVN, one was a complete failure and one was half-done.
Based on suggestions from friends I did ‘apt-get install audacious‘ and gave it a go. It certainly looks very similar to xmms and it also provides the same simple features I like and use when it comes to music playback on my computer.
While I’m really not bothering much about looks of software and my computer desktop in general, the default skin in Audacious really is quite awful. But really, mosts skins for winamp and xmms that (rather nicely) work for this player are just graphics-crammed overworked stuff so finding a “bare” and “simple” skin that looks nice isn’t that easy.
I just settled with one that looks a bit better than the default.
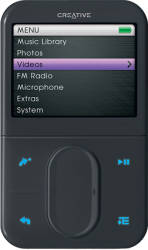
Maurus Cuelenaere has been doing some great progress recently and is now capable of running custom code on the Creative Zen Vision:M target.
The work is now in full progress to make the Rockbox bootloader actually run on it. The LCD seems to work and buttons are in the works…
If you haven’t joined before, now’s a perfect opportunity to dig up that old Creative’s of yours and join the Rockbox bandwagon as it starts to roll on yet another target!
It is a TMS320DM320 target, and all the hw info you need is here.

 If your interest is in the Rockbox project, add your project ideas or add yourself as mentor on this wiki page.
If your interest is in the Rockbox project, add your project ideas or add yourself as mentor on this wiki page. If your interest is in the cURL project, read this page about the existing ideas and provide new ones or submit yourself as mentor on the mailing list!
If your interest is in the cURL project, read this page about the existing ideas and provide new ones or submit yourself as mentor on the mailing list!