One positive thing among many others at this version of the HTTP Workshop (day one, day two) is the fact that there have been several new faces showing up here. People who have not previously attended any HTTP Workshops. Getting fresh blood into the mix is great. A chance to maybe lower the average age of the attendees also feels welcome.
This half day was the final session for this time. Three topics were dealt with.
Do you speak HTTP? Getting your HTTP implementation to do right according to the specification can be a challenge. There is a whole range of existing tests for various areas of HTTP but there might still be a place to add HTTP semantic tests in particular for servers. Discussions brought about reflections around testing, doing tests, test formats, other tests, test infrastructure and more. I think the general sense was that yes it would be great. At least if someone else makes it happen…
Workshop feedback and thoughts. What is a good cadence for future events, how long should the events be etc. This is probably the maximum amount of attendees we can handle using the same setup. This event was clearly better than several of the past ones in terms of diversity, but I will second our “workshop maestro” in that it could improve further still. We also discussed whether do-arranging together with IETF is good or bad, should it then be before or after IETF?
I think the consensus said that making it biannual event is good. The reasoning for keeping the event in Europe has been because a larger share of the European attendees come from smaller companies compared to the non-Europeans which to a larger degree come from larger companies that might have it easier to pay for longer trips.
My personal take
The HTTP Workshop is a one-of-a-kind event. At these events everything is about and around HTTP with an information density level that is super high. We get to learn how things actually work for people or that do not work. And that we are not alone in whatever struggles or HTTP challenges we have.
Networking with other doers here and absorbing every protocol detail being expressed, gives food for thoughts and lessons to take advantage from in years to come when we for sure are going to take HTTP transfers further. This is in many ways a kind of brain fertilizer event.
Did I mention I enjoyed it? I will certainly try to attend the next one.
In an office building close to the Waterloo station in London, around 40 persons again sat down at this giant table forming a big square that made it possible for us all to see each other. One by one there were brief presentations done with follow-up discussions. The discussions often reiterated old truths, brought up related topics and sometimes went deep down into the weeds about teeny weeny details of the involved protocol specs. The way we love it.
The people around the table represent Ericsson, Google, Microsoft, Apple, Meta, Akamai, Cloudflare, Fastly, Mozilla, Varnish. Caddy, Nginx, Haproxy, Tomcat, Adobe and curl and probably a few more I forget now. One could say with some level of certainty that a large portion of every day HTTP traffic in the world is managed by things managed by people present here.
This morning we all actually understood that the south entrance is actually the east one (yeah, that’s a so called internal joke) and most of us were sitting down, eager and prepared when the day started at 9:30 am.
Capsule. The capsule protocol (RFC 9297) is a way to, put simply, send UDP packets/datagrams over old style HTTP/1 or HTTP/2 proxies.
Cookies. With the 6265bis effort well on its way to ship as an updated RFC, there is an effort and intent to take yet another stab at improving and refreshing the cookie spec situation. In particular to better split off browser management and API related stuff from the more network-oriented over-the-wire details. You know yours truly never ceases an opportunity to voice his opinion on cookies… I approve of this attempt as well, as I think increasing clarity and improving the specification situation can’t but to help improve things.
Declarative web push. There’s an ongoing effort to improve web push – not to be confused with server push, so that it can be done easier and without needing JavaScript to manage it in the client side.
Reverse HTTP. There are origins who want to contact their CDNs without having to listening on any ports/sockets and still be able to provide content. That’s one of the use cases for Reverse HTTP and we got to learn details from internet drafts done on the topics for the last fifteen years and why it might still be a worthwhile effort and why the use cases still exist. But is there an enough demand to put it into HTTP?
Server Stack Detection. A discussion around how someone can detect the origin of the server stack of any given HTTP server implementation. Should there be a better way? What is the downside of introducing what would basically be the server version of the user-agent header field? Lots of productive discussions on how to avoid recreating problems of the past but in a reversed way.
MoQ: What is it and why is it not just HTTP/3? Was an educational session about the ongoing work done in this working group that is wrongly named and would appreciate more input from the general protocol community.
New HTTP stack. A description of the journey of a full HTTP stack rewrite: how components can be chained together and in which order and a follow-up discussion about if this should be included in documentation and if so in which way etc. Lessons included that the spec is one thing, the Internet is another. Maybe not an entirely new revelation.
Multiplexing in the year 2024. There are details in HTTP/2 multiplexing that does not really work, there are assumptions that are now hard to change. To introduce new protocols and features in the modern HTTP stack, things need to be done for both HTTP/2 and HTTP/3 that are similar but still different and it forces additional work and pain.
What if we create a way to do multiplexing over TCP, so called “over streams”, so that the HTTP/3 fallback over TCP could still be done using HTTP/3 framing. This would allow future new protocols to remain HTTP/3-only and just make the transport be either QUIC+UDP or Streams-over TCP+TLS. This triggered a lot of discussions, mostly positive and forward-looking but also a lot of concerns raised about additional work and yet another protocols component to write and implement that then needs to be supported until the end of times because things never truly go away completely.
I think this sounds like a fun challenge! Count me in.
End of day two. I need a beer or two to digest this.
For the sixth time, this informal group of HTTP implementers and related “interested parties” unite in a room over a couple of days doing a HTTP Workshop. Nine years since that first event in Münster, Germany.
If you are someone like me, obsessed with networking and HTTP in particular this is certainly the place to be. Talking and discussing past lessons, coming changes and protocol dreams in several days with like-minded people is a blast. The people on these events are friends that I don’t always get to hang out with too often. Many of the attendees here have been involved in this community for a long time and have attended all or most of the past workshops as well. I have fortunately been able to attend all of them so far.
This time we are in London.
Let me tell you a little about the topics of day one – without spilling the beans about exactly who said what or what the company they came from. (I will add links to the presentations later once I know where to link to.)
Make Cleartext HTTP harder. The first discussion point of the day. While we have made HTTPS easier over recent years it can only take us so far. What if we considered means to make HTTP harder to use as the next level efforts to further reduce its use over the internet. The HSTS preload list is only growing. Should we instead convert it into a HSTS exclude list that can shrink over time? This triggered a looong a discussion in the group which brought back a lot of old arguments and reasoning from days I thought we had left behind long ago.
HTTP 2/3 abuses. A prominent implementer of a HTTP proxy/load balancer walked us through a whole series of different HTTP/2 and HTTP/3 protocols details that attackers can have been exploiting in recent years, with details about what can be done to mitigate such attacks. It made several other implementers mention how they take similar precautions and some other general discussions around the topics of what can be considered normal use of the protocol and what is not.
Idle connections & mobile: beneficial or harmful. 0-RTT instead of idle connections. There is a non-negligible cost associate with keeping connections alive for clients running on mobile phones. Would it be possible to instead move forward into a world when they are not kept alive but instead closed and 0-RTT opened again next time they are needed? Again the room woke up to a long discussion about the benefits and problems with doing this – which if it would be possible probably would save a lot of battery time on the average mobile phones.
QUIC pacing. We learned that it is very important for servers to implement decent QUIC pacing as it can increase performance up to 20 times compared to no pacing at all. What about using the flow control properly? What about changing the default buffer sizes for UDP sockets in the Linux kernel to something similar to TCP sockets in order to help the default case to perform better?
HTTP prioritization for product performance. The HTTP/2 way of doing prioritization was deemed a failure and too complicated a long time ago but in this presentation we were taught that there are definitely use cases and scenarios where the regular HTTP/3 priority setup is helpful and improves performs. Examples and descriptions for a popular and well used client were shown.
Allowing HTTP clients to use stale DNS data. What if HTTP clients would use stale data instead of having to wait for the DNS resolver response as a means to avoid having to wait a whole RTT to get the date that in a fair amount of the cases is the same as the stale data. Again a long discussion around TTLs for DNS queries and the fact that some clients are already doing this, in more or less explicit ways.
QUIC cache DSR. As the last talk of the the afternoon we got in the details of Direct Server Response for QUIC and how this can improve performance and problems and challenges involved with this. It then indirectly took us into a long sub-thread talking about HTTP caching, Vary headers and what could and should be done to improve things going forward. There seems to be an understanding that it would be good to improve the current situation but it is not entirely clear to this author exactly what that would entail.
When we then took a walk through the streets of London, only to have an awesome dinner during which we could all conclude that HTTP still is not ready. There is still work to be done. There are challenges left to overcome.
The last day of this edition of the HTTP workshop. Thursday November 3, 2022. A half day only. Many participants at the Workshop are going to continue their UK adventure and attend the IETF 115 in London next week.
We started off the day with a deep dive into connection details. How to make connections for HTTP – in particular on mobile devices. How to decide which IP to use, racing connections, timeouts, when to consider a connection attempt “done” (ie after the TCP SYNACK or after the TLS handshake is complete). QUIC vs TCP vs TLS and early data. IPv4 vs IPv6.
ECH. On testing, how it might work, concerns. Statistics are lies. What is the success expectancy for this and what might be the explanations for failures. What tests should be done and what answers about ECH in the wild would we like to get answered going forward?
Dan Stahr: Making a HTTP client good. Discussions around what to expose, not to expose and how HTTP client APIs have been written or should be written. Adobe has its own version of fetch for server use.
Mike Bishop brought up an old favorite subject: a way for a server to provide hints to a client on how to get its content from another host. Is it time to revive this idea? Blind caching the idea and concept was called in an old IETF 95 presentation by Martin Thomson. A host that might be closer the client or faster etc or simply that has the content in question could be used for providing content.
Mark Nottingham addressed the topic of HTTP (interop) testing. Ideas were raised around some kind of generic infrastructure for doing tests for HTTP implementations. I think people were generally positive but I figure time will tell what if anything will actually happen with this.
What’s next for HTTP? Questions were asked to the room, mostly of the hypothetical kind, but I don’t think anyone actually had the nerve to suggest they actually have any clear ideas for that at this moment. At least not in this way. HTTP/4 has been mentioned several times during these days, but then almost always in a joke context.
The End
This is how the workshop ends for this time. Super fun, super informative, packed with information with awesome people. One of these events that give me motivation and a warm fuzzy feeling inside for an extended period of time into the future.
Thanks everyone for your excellence. Thank you organizers for a fine setup!
During the discussions today it was again noticeable that apart from some specific individuals we also lack people in the room from prominent “players” in this area such as Chrome developers or humans with closer knowledge of how larger content deliverer work such as Netflix. Or what about a search engine person?
Years ago Chrome was represented well and the Apple side of the world was weak, but the situation seems to have been totally reversed by now.
The day
Mike Bishop talked about the complexities of current internet. Redirects before, during, after. HTTPS records. Alt-svc. Alt-SvcB. Use the HTTPS record for that alternative name.
This presentation triggered a long discussion on how to do things, how things could be done in a future and how the different TTLs in this scenario should or could interact. How to do multi-CDN, how to interact with DNS and what happens if a CDN wants to disable QUIC?
A very long discussion that mostly took us all back to square one in the end. The alt-svcb proposal as is.
Alan Frindell talked about HTTP priorities. What it is (only within connections, it has to be more than one thing and it something goes faster something else needs to go slower, re-prioritization takes a RTT/2 for a client to take effect), when to prioritize (as late as possible, for h2 just before committing to TCP).
Prioritizing images in Meta’s apps. On screen, close, not close. Guess first, then change priority once it knows better. An experiment going on is doing progressive images. Change priority of image transfers once they have received a certain amount. Results and conclusions are pending.
Priority within a single video. An important clue to successful priority handling seems to be more content awareness in the server side. By knowing what is being delivered, the server can make better decisions without the client necessarily having to say anything.
Who is doing SF libraries and APIs? Do we need an SF schema?
SF compression? Mark’s experiment makes it pretty much on par with HPACK.
Binary SF. Takes ~40% less time parsing in Mark’s experiment. ~10% larger in size (for now).
The was expressed interest in continuing this experimenting going forward. Reducing the CPU time for header parsing is considered valuable.
Sebastian Poreba talked “Networking in your pocket” about the challenges and architectures of mobile phone and smartwatch networking. Connection migration is an important property of QUIC that is attractive in the mobile world. H3 is good.
A challenge is to keep the modem activity off as much as possible and do network activities when the modem is already on.
Beers
My very important duties during these days also involved spending time in pubs and drinking beers with this awesome group of people. This not only delayed my blog post publish times a little, but it might also have introduced an ever so slight level of “haziness” into the process and maybe, just maybe, my recollection of the many details from the day is not exactly as detailed as it could otherwise have been.
That’s just the inevitable result of me sacrificing myself for the team. I did it for us all. You’re welcome.
Another full day
Another day fully packed with HTTP details from early to late. From 9am in the morning until 11pm in the evening. I’m having a great time. Tomorrow is the last day. I’ll let you know what happens then.
The HTTP Workshop is an occasional gathering of HTTP experts and other interested parties to discuss the Web’s foundational protocol.
The fifth HTTP Workshop is a three day event that takes place in Oxford, UK. I’m happy to say that I am attending this one as well, as I have all the previous occasions. This is now more than seven years since the first one.
Attendees
A lot of the people attending this year have attended previous workshops, but in a lot of cases we are now employed by other companies then when we attended our first workshops. Almost thirty HTTP stack implementers, experts and spec authors in a room.
There was a few newcomers and some regulars are absent (and missed). Unfortunately, we also maintain the lack of diversity from previous years. We are of course aware of this, but have still failed to improve things in this area very much.
Setup
All the people gather in the same room. A person talks briefly on a specific topic and then we have a free-form discussion about it. When I write this, the slides from today’s presentations have not yet been made available so I cannot link them here. I will add those later.
Lucas Pardue started the morning with a presentation and discussion around logging, tooling and the difficulty of debugging modern HTTP setups. With binary protocols doing streams and QUIC, qlog and qvis are in many ways the only available options but they are not supported by everything and there are gaps in what they offer. Room for improvements.
Anne van Kesteren showed a proposal from Domenic Denicola for a No-Vary-Search response header. An attempt to specify a way for HTTP servers to tell clients (and proxies) that parts of the query string produces the same response/resource and should be cached and treated as the same.
An issue that is more complicated than what if first might seem. The proposal has some fans in the room but I think the general consensus was that it is a bad name for the header…
HTTP versions. HTTP/3 is used in over a third of the requests both as seen by Cloudflare server-side and measured in Firefox telemetry client-side. Extensible and functional protocols. Nobody is talking about or seeing a point in discussing about a HTTP/4.
WebSocket over h2/h3. There does not seem to be any particular usage and nobody mentioned any strong reason or desired to change the status. Web Transport is probably what instead is going to be the future.
Frames. Discussions around the use and non-use of the origin frame. Note widely used. Could help to avoid extra “SNI leakage” and extra connections.
Anne then took a second round in front of the room and questioned us on the topic of cookies. Or perhaps more specifically about details in the spec and how to possible change the spec going forward. At least one person in the room insisted fairly strongly than any such restructures of said documents should be done after the ongoing 6265bis work is done.
Dinner
A company very generously sponsored a group dinner for us in the evening and I had a great time. I was asked to not reveal the name of said company, but I can tell you that a lot of the conversations at the table, at least in the area where I was parked, kept up the theme from the day and were HTTP oriented. Including oblivious HTTP, IPv4 formatting allowed in URLs and why IP addresses should not be put in the SNI field. Like any good conversion among friends.
The 2019 HTTP Workshop ended today. In total over the years, we have now done 12 workshop days up to now. This day was not a full day and we spent it on only two major topics that both triggered long discussions involving large parts of the room.
Cookies
Mike West kicked off the morning with his cookies are bad presentation.
One out of every thousand cookie header values is 10K or larger in size and even at the 50% percentile, the size is 480 bytes. They’re a disaster on so many levels. The additional features that have been added during the last decade are still mostly unused. Mike suggests that maybe the only way forward is to introduce a replacement that avoids the issues, and over longer remove cookies from the web: HTTP state tokens.
A lot of people in the room had opinions and thoughts on this. I don’t think people in general have a strong love for cookies and the way they currently work, but the how-to-replace-them question still triggered lots of concerns about issues from routing performance on the server side to the changed nature of the mechanisms that won’t encourage web developers to move over. Just adding a new mechanism without seeing the old one actually getting removed might not be a win.
We should possibly “worsen” the cookie experience over time to encourage switch over. To cap allowed sizes, limit use to only over HTTPS, reduce lifetimes etc, but even just that will take effort and require that the primary cookie consumers (browsers) have a strong will to hurt some amount of existing users/sites.
(Related: Mike is also one of the authors of the RFC6265bis draft in progress – a future refreshed cookie spec.)
HTTP/3
Mike Bishop did an excellent presentation of HTTP/3 for HTTP people that possibly haven’t kept up fully with the developments in the QUIC working group. From a plain HTTP view, HTTP/3 is very similar feature-wise to HTTP/2 but of course sent over a completely different transport layer. (The HTTP/3 draft.)
Most of the questions and discussions that followed were rather related to the transport, to QUIC. Its encryption, it being UDP, DOS prevention, it being “CPU hungry” etc. Deploying HTTP/3 might be a challenge for successful client side implementation, but that’s just nothing compared the totally new thing that will be necessary server-side. Web developers should largely not even have to care…
One tidbit that was mentioned is that in current Firefox telemetry, it shows about 0.84% of all requests negotiates TLS 1.3 early data (with about 12.9% using TLS 1.3)
Thought-worthy quote of the day comes from Willy: “everything is a buffer”
Future Workshops
There’s no next workshop planned but there might still very well be another one arranged in the future. The most suitable interval for this series isn’t really determined and there might be reasons to try tweaking the format to maybe change who will attend etc.
The fact that almost half the attendees this time were newcomers was certainly good for the community but that not a single attendee traveled here from Asia was less good.
Thanks
Thanks to the organizers, the program committee who set this up so nicely and the awesome sponsors!
Yesterday we plowed through a large and varied selection of HTTP topics in the Workshop. Today we continued. At 9:30 we were all in that room again. Day two.
Martin Thomson talked about his “hx” proposal and how to refer to future responses in HTTP APIs. He ended up basically concluding that “This is too complicated, I think I’m going to abandon this” and instead threw in a follow-up proposal he called “Reverse Javascript” that would be a way for a client to pass on a script for the server to execute! The room exploded in questions, objections and “improvements” to this idea. There are also apparently a pile of prior art in similar vein to draw inspiration from.
With the audience warmed up like this, Anne van Kasteren took us back to reality with an old favorite topic in the HTTP Workshop: websockets. Not a lot of love for websockets in the room… but this was the first of several discussions during the day where a desire or quest for bidirectional HTTP streams was made obvious.
Woo Xie did a presentation with help from Alan Frindell about Extending h2 for Bidirectional Messaging and how they propose a HTTP/2 extension that adds a new frame to create a bidirectional stream that lets them do messaging over HTTP/2 fine. The following discussion was slightly positive but also contained alternative suggestions and references to some of the many similar drafts for bidirectional and p2p connections over http2 that have been done in the past.
Lucas Pardue and Nick Jones did a presentation about HTTP/2 Priorities, based a lot of research previously done and reported by Pat Meenan. Lucas took us through the history of how the priorities ended up like this, their current state and numbers and also the chaos and something about a possible future, the h3 way of doing prio and mr Meenan’s proposed HTTP/3 prio.
Nick’s second half of the presentation then took us through Cloudflare’s Edge Driven HTTP/2 Prioritisation work/experiments and he showed how they could really improve how prioritization works in nginx by making sure the data is written to the socket as late as possible. This was backed up by audience references to the TAPS guidelines on the topic and a general recollection that reducing the number connections is still a good idea and should be a goal! Server buffering is hard.
Asbjørn Ulsberg presented his case for a new request header: prefer-push. When used, the server can respond to the request with a series of pushed resources and thus save several round-rips. This triggered sympathy in the room but also suggestions of alternative approaches.
Alan Frindell presented Partial POST Replay. It’s a rather elaborate scheme that makes their loadbalancers detect when a POST to one of their servers can’t be fulfilled and they instead replay that POST to another backend server. While Alan promised to deliver a draft for this, the general discussion was brought up again about POST and its “replayability”.
Willy Tarreau followed up with a very similar topic: Retrying failed POSTs. In this this context RFC 2310 – The Safe Response Header Field was mentioned and that perhaps something like this could be considered for requests? The discussion certainly had similarities and overlaps with the SEARCH/POST discussion of yesterday.
Mike West talked about Fetch Metadata Request Headers which is a set of request headers explaining for servers where and what for what purpose requests are made by browsers. He also took us through a brief explained of Origin Policy, meant to become a central “resource” for a manifest that describes properties of the origin.
Mark Nottingham presented Structured Headers (draft). This is a new way of specifying and parsing HTTP headers that will make the lives of most HTTP implementers easier in the future. (Parts of the presentation was also spent debugging/triaging the most weird symptoms seen when his Keynote installation was acting up!) It also triggered a smaller side discussion on what kind of approaches that could be taken for HPACK and QPACK to improve the compression ratio for headers.
Yoav Weiss described the current status of client hints (draft). This is shipped by Chrome already and he wanted more implementers to use it and tell how its working.
Roberto Peon presented an idea for doing “Partialy-Reliable HTTP” and after his talk and a discussion he concluded they will implement it, play around and come back and tell us what they’ve learned.
Willy Tarreau talked about a race problem he ran into with closing HTTP/2 streams and he explained how he worked around it with a trailing ping frame and suggested that maybe more users might suffer from this problem.
The oxygen level in the room was certainly not on an optimal level at this point but that didn’t stop us. We knew we had a few more topics to get through and we all wanted to get to the boat ride of the evening on time. So…
Hooman Beheshti polled the room to get a feel for what people think about Early hints. Are people still on board? Turns out it is mostly appreciated but not supported by any browser and a discussion and explainer session followed as to why this is and what general problems there are in supporting 1xx headers in browsers. It is striking that most of us HTTP people in the room don’t know how browsers work! Here I could mention that Cory said something about the craziness of this, but I forget his exact words and I blame the fact that they were expressed to me on a boat. Or perhaps that the time is already approaching 1am the night after this fully packed day.
As the final conversation of the day, Anne van Kesteren talked about Response Sources and the different ways a browser can do requests and get responses.
Boat!
HAproxy had the excellent taste of sponsoring this awesome boat ride on the Amsterdam canals for us at the end of the day
Boating on the Amsterdam canals, sponsored by HAproxy!
Thanks again to Cory Benfield for feeding me his notes of the day to help me keep things straight. All mistakes are mine. But if you tell me about them, I will try to correct the text!
The forth season of my favorite HTTP series is back! The HTTP Workshop skipped over last year but is back now with a three day event organized by the very best: Mark, Martin, Julian and Roy. This time we’re in Amsterdam, the Netherlands.
35 persons from all over the world walked in the room and sat down around the O-shaped table setup. Lots of known faces and representatives from a large variety of HTTP implementations, client-side or server-side – but happily enough also a few new friends that attend their first HTTP Workshop here. The companies with the most employees present in the room include Apple, Facebook, Mozilla, Fastly, Cloudflare and Google – having three or four each in the room.
Patrick Mcmanus started off the morning with his presentation on HTTP conventional wisdoms trying to identify what have turned out as successes or not in HTTP land in recent times. It triggered a few discussions on the specific points and how to judge them. I believe the general consensus ended up mostly agreeing with the slides. The topic of unshipping HTTP/0.9 support came up but is said to not be possible due to its existing use. As a bonus, Anne van Kesteren posted a new bug on Firefox to remove it.
Mark Nottingham continued and did a brief presentation about the recent discussions in HTTPbis sessions during the IETF meetings in Prague last week.
Martin Thomson did a presentation about HTTP authority. Basically how a client decides where and who to ask for a resource identified by a URI. This triggered an intense discussion that involved a lot of UI and UX but also trust, certificates and subjectAltNames, DNS and various secure DNS efforts, connection coalescing, DNSSEC, DANE, ORIGIN frame, alternative certificates and more.
Mike West explained for the room about the concept for Signed Exchanges that Chrome now supports. A way for server A to host contents for server B and yet have the client able to verify that it is fine.
Tommy Pauly then talked to his slides with the title of Website Fingerprinting. He covered different areas of a browser’s activities that are current possible to monitor and use for fingerprinting and what counter-measures that exist to work against furthering that development. By looking at the full activity, including TCP flows and IP addresses even lots of our encrypted connections still allow for pretty accurate and extensive “Page Load Fingerprinting”. We need to be aware and the discussion went on discussing what can or should be done to help out.
The meeting is going on somewhere behind that red door.
Roberto Peon presented his new idea for “Generic overlay networks”, a suggested way for clients to get resources from one out of several alternatives. A neighboring idea to Signed Exchanges, but still different. There was an interested to further and deepen this discussion and Roberto ended up saying he’d at write up a draft for it.
Max Hils talked about Intercepting QUIC and how the ability to do this kind of thing is very useful in many situations. During development, for debugging and for checking what potentially bad stuff applications are actually doing on your own devices. Intercepting QUIC and HTTP/3 can thus also be valuable but at least for now presents some challenges. (Max also happened to mention that the project he works on, mitmproxy, has more stars on github than curl, but I’ll just let it slide…)
Poul-Henning Kamp showed us vtest – a tool and framework for testing HTTP implementations that both Varnish and HAproxy are now using. Massaged the right way, this could develop into a generic HTTP test/conformance tool that could be valuable for and appreciated by even more users going forward.
Asbjørn Ulsberg showed us several current frameworks that are doing GET, POST or SEARCH with request bodies and discussed how this works with caching and proposed that SEARCH should be defined as cacheable. The room mostly acknowledged the problem – that has been discussed before and that probably the time is ripe to finally do something about it. Lots of users are already doing similar things and cached POST contents is in use, just not defined generically. SEARCH is a already registered method but could get polished to work for this. It was also suggested that possibly POST could be modified to also allow for caching in an opt-in way and Mark volunteered to author a first draft elaborating how it could work.
Indonesian and Tibetan food for dinner rounded off a fully packed day.
Thanks Cory Benfield for sharing your notes from the day, helping me get the details straight!
Diversity
We’re a very homogeneous group of humans. Most of us are old white men, basically all clones and practically indistinguishable from each other. This is not diverse enough!
A big thank you to the HTTP Workshop 2019 sponsors!
Previously, on the HTTP Workshop. Yesterday ended with a much appreciated group dinner and now we’re back energized and eager to continue blabbing about HTTP frames, headers and similar things.
Martin from Mozilla talked on “connection management is hard“. Parts of the discussion was around the HTTP/2 connection coalescing that I’ve blogged about before. The ORIGIN frame is a draft for a suggested way for servers to more clearly announce which origins it can answer for on that connection which should reduce the frequency of 421 needs. The ORIGIN frame overrides DNS and will allow coalescing even for origins that don’t otherwise resolve to the same IP addresses. The Alt-Svc header, a suggested CERTIFICATE frame and how does a HTTP/2 server know for which origins it can do PUSH for?
A lot of positive words were expressed about the ORIGIN frame. Wildcard support?
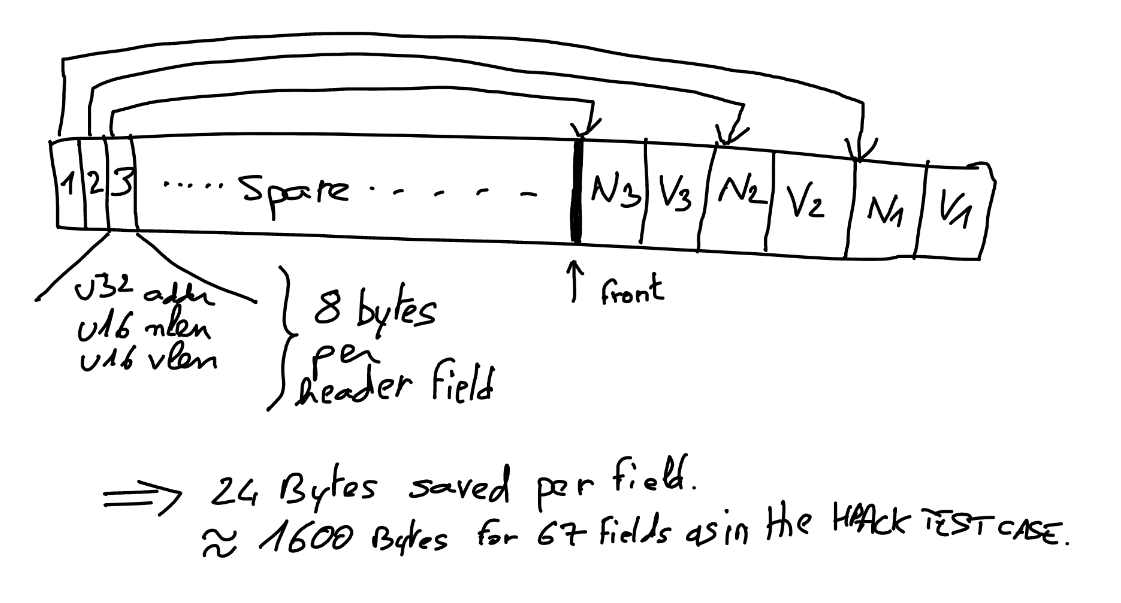
Willy from HA-proxy talked about his Memory and CPU efficient HPACK decoding algorithm. Personally, I think the award for the best slides of the day goes to Willy’s hand-drawn notes.
Lucas from BBC talked about usage data for iplayer and how much data and number of requests they serve and how their largest share of users are “non-browsers”. Lucas mentioned their work on writing a libcurl adaption to make gstreamer use it instead of libsoup. Lucas talk triggered a lengthy discussion on what needs there are and how (if at all) you can divide clients into browsers and non-browser.
Wenbo from Google spoke about Websockets and showed usage data from Chrome. The median websockets connection time is 20 seconds and 10% something are shorter than 0.5 seconds. At the 97% percentile they live over an hour. The connection success rates for Websockets are depressingly low when done in the clear while the situation is better when done over HTTPS. For some reason the success rate on Mac seems to be extra low, and Firefox telemetry seems to agree. Websockets over HTTP/2 (or not) is an old hot topic that brought us back to reiterate issues we’ve debated a lot before. This time we also got a lovely and long side track into web push and how that works.
Roy talked about Waka, a HTTP replacement protocol idea and concept that Roy’s been carrying around for a long time (he started this in 2001) and to which he is now coming back to do actual work on. A big part of the discussion was focused around the wakli compression ideas, what the idea is and how it could be done and evaluated. Also, Roy is not a fan of content negotiation and wants it done differently so he’s addressing that in Waka.
Vlad talked about his suggestion for how to do cross-stream compression in HTTP/2 to significantly enhance compression ratio when, for example, switching to many small resources over h2 compared to a single huge resource over h1. The security aspect of this feature is what catches most of people’s attention and the following discussion. How can we make sure this doesn’t leak sensitive information? What protocol mechanisms exist or can we invent to help out making this work in a way that is safer (by default)?
Trailers. This is again a favorite topic that we’ve discussed before that is resurfaced. There are people around the table who’d like to see support trailers and we discussed the same topic in the HTTP Workshop in 2016 as well. The corresponding issue on trailers filed in the fetch github repo shows a lot of the concerns.
Julian brought up the subject of “7230bis” – when and how do we start the work. What do we want from such a revision? Fixing the bugs seems like the primary focus. “10 years is too long until update”.
Kazuho talked about “HTTP/2 attack mitigation” and how to handle clients doing many parallel slow POST requests to a CDN and them having an origin server behind that runs a new separate process for each upload.
And with this, the day and the workshop 2017 was over. Thanks to Facebook for hosting us. Thanks to the members of the program committee for driving this event nicely! I had a great time. The topics, the discussions and the people – awesome!