I occasionally do talks about curl. In these talks I often include a few slides that say something abut curl’s coverage and presence on different platforms. Mostly to boast of course, but also to help explain to the audience how curl has manged to reach its ten billion installations.
This is current incarnation of those seven slides in November 2022. I am of course also eager to get your feedback on the specific contents, especially if you miss details in them, that I should add so that my future curl presentations include more accurate data.
curl runs in all your devices
curl is used in (almost) every Internet-connected device out there, and I try to visualize that with this packed slide. Cars, servers, game consoles, medical devices, games, apps, operating systems, watches, robots, TVs, speakers, light-bulbs, freezers, printers, motorcycles, music instruments and more.
The intent being to show with images that it runs in quite a few devices.

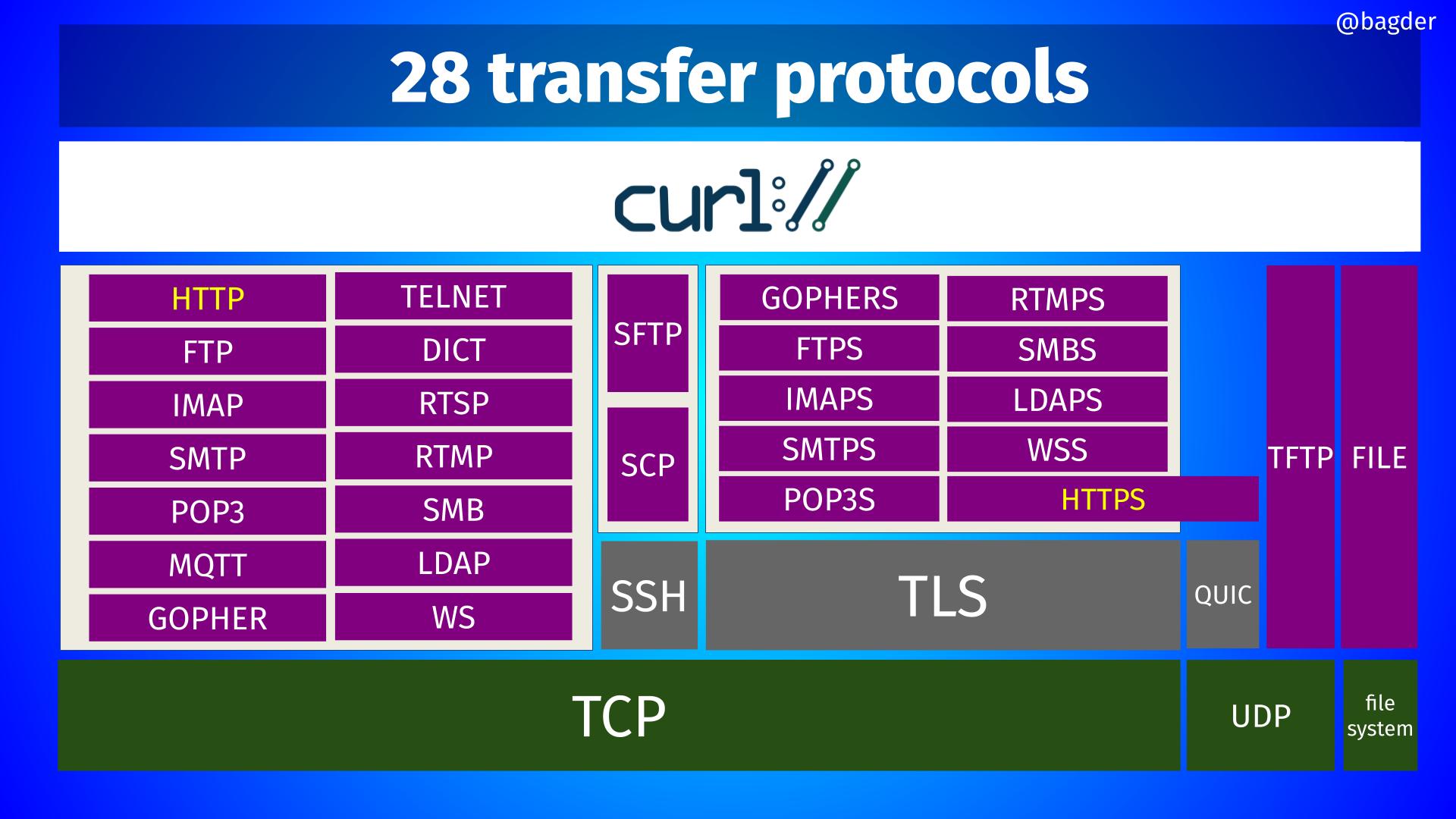
28 transfer protocols
More strictly speaking these are the 28 URL schemes curl supports right now, including in experimental builds. The image tries to put them in a sort of hierarchical way so that you can see what underlying protocol that is used for them: TCP, SSH, TLS, QUIC etc.
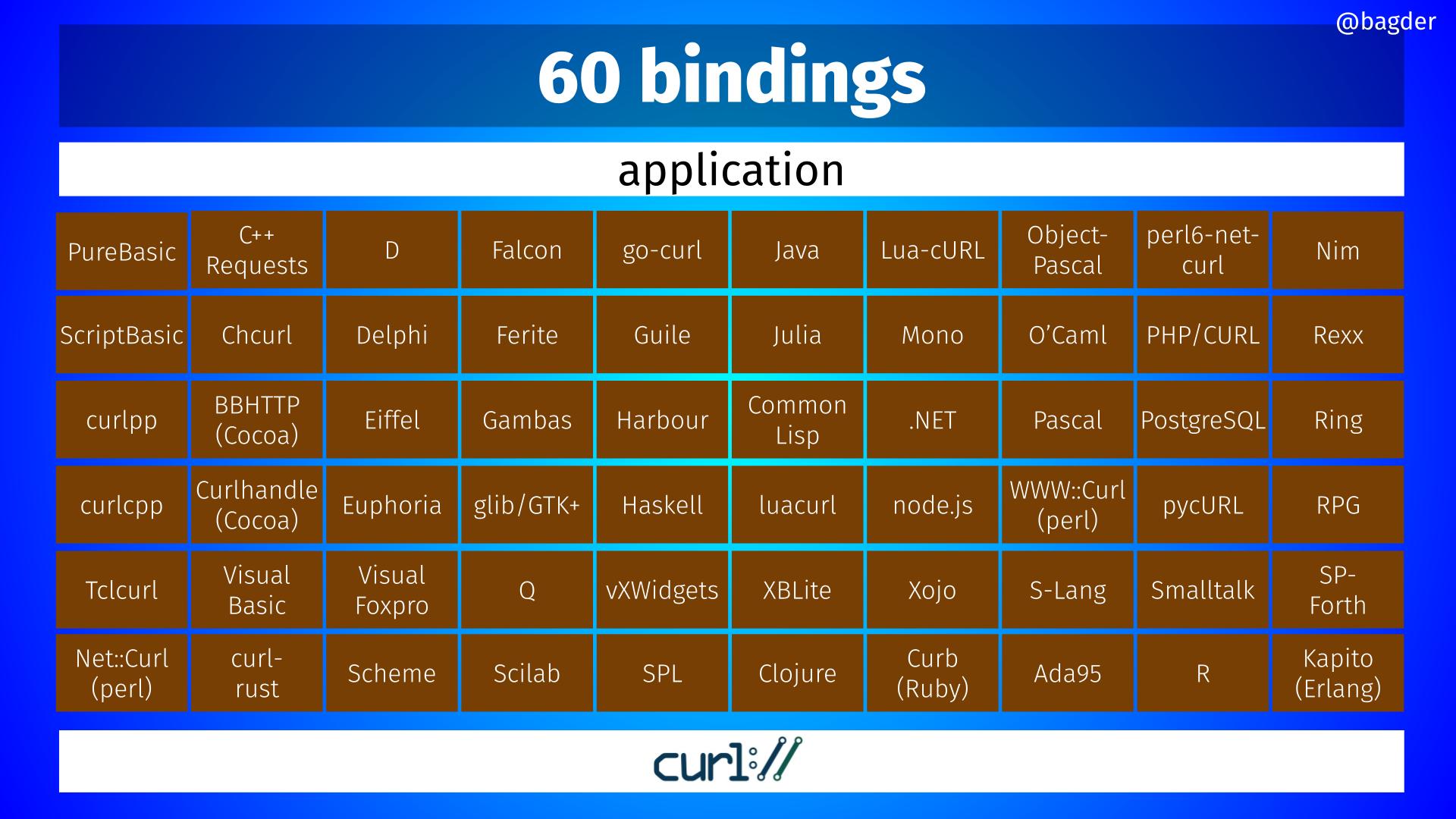
60 bindings
Volunteers have created and maintain libcurl bindings for at least these 60 different environments, making it possible for developers to access and use libcurl powers from virtually every programming language you can think of.
37 third party dependencies
curl’s modular design and ability letting the developer who builds curl to mix and match features and what particular third party dependencies to use, makes it possible to craft exactly the curl builds you want. Device manufacturers get the combination they like for exactly their purposes and needs.

89 operating systems
This list has been worked on and bounced around several times between friends and it always brings out a few questions and people like to argue with me about a few entries I include and about a few entries I do not include. The problem is both that there is not a clear defining line between the definition of an operating systems and a distribution or a different running environment and sometimes it is just branding differences separating X from Y. With a “flexible” attitude to the definition of operating systems, this is the current collection of no less than 89 individual ones on which curl runs or has run on:

24 CPU architectures
Older versions of this slide used to have x86-64 as a separate one, but I think we have concluded that a large amount of the architectures have separate 64 bit versions so if I were to keep x86-64 I should also include a lot of other 64 bit versions so I removed the x86-64 from the slide. Maybe I should rather go the other way and add all the 64 bit version as separate architectures?
Anyway, curl has been made to run on virtually all modern or semi-modern 32 bit or larger CPU architectures we can find:

2 planets
I admit it. I include this slide in my presentation and in this blog post because it feels like the ultimate show-off. curl was used in the mars 2020 helicopter mission.