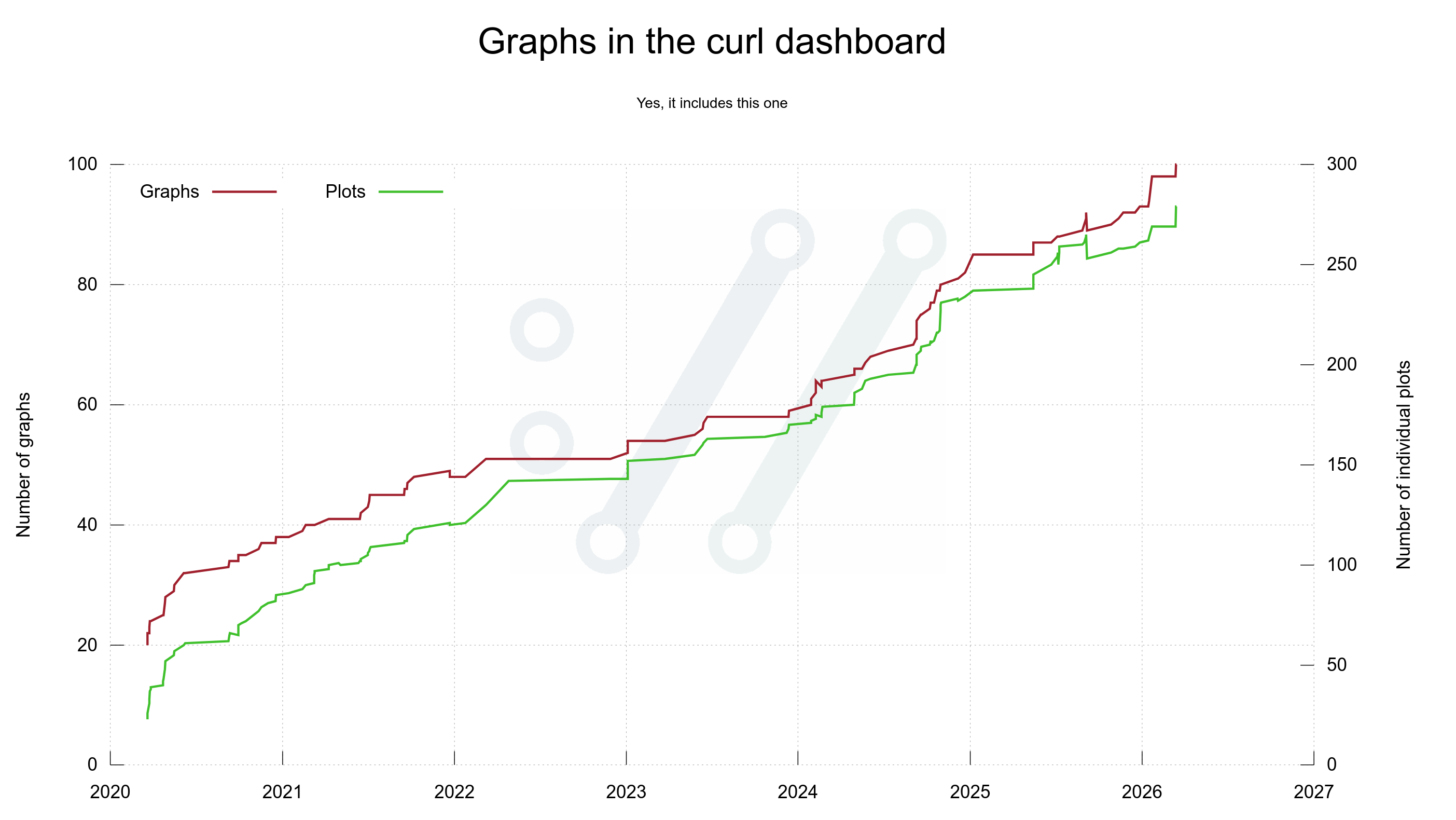
As I have been preparing slides for my coming talk at foss-north on April 28, 2026 I figured I could take the opportunity and share a glimpse of the current reality here on my blog. The high quality chaos era, as I call it.
No more AI slop
I complained and I complained about the high frequency junk submissions to the curl bug-bounty that grew really intense during 2025 and early 2026. To the degree that we shut it down completely on February 1st this year. At the time we speculated if that would be sufficient or if the flood would go on.
Now we know.
Higher volume, higher quality
In March 2026, the curl project went back to Hackerone again once we had figured out that GitHub was not good enough.
From that day, the nature of the security report submissions have changed.
The slop situation is not a problem anymore.
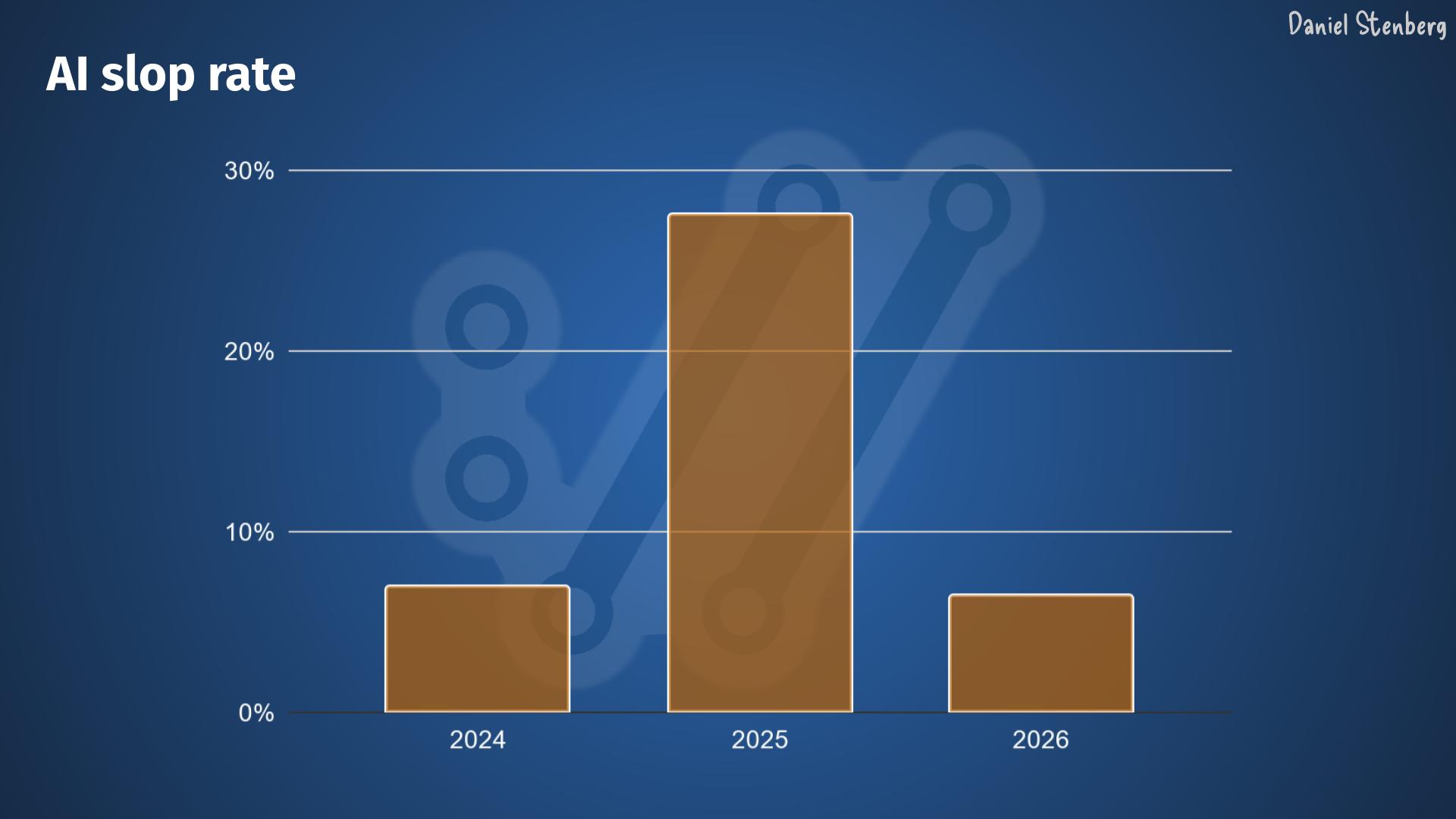
The report frequency is higher than ever. Recently it’s been about double the rate we had through 2025, which already was more than double from previous years.
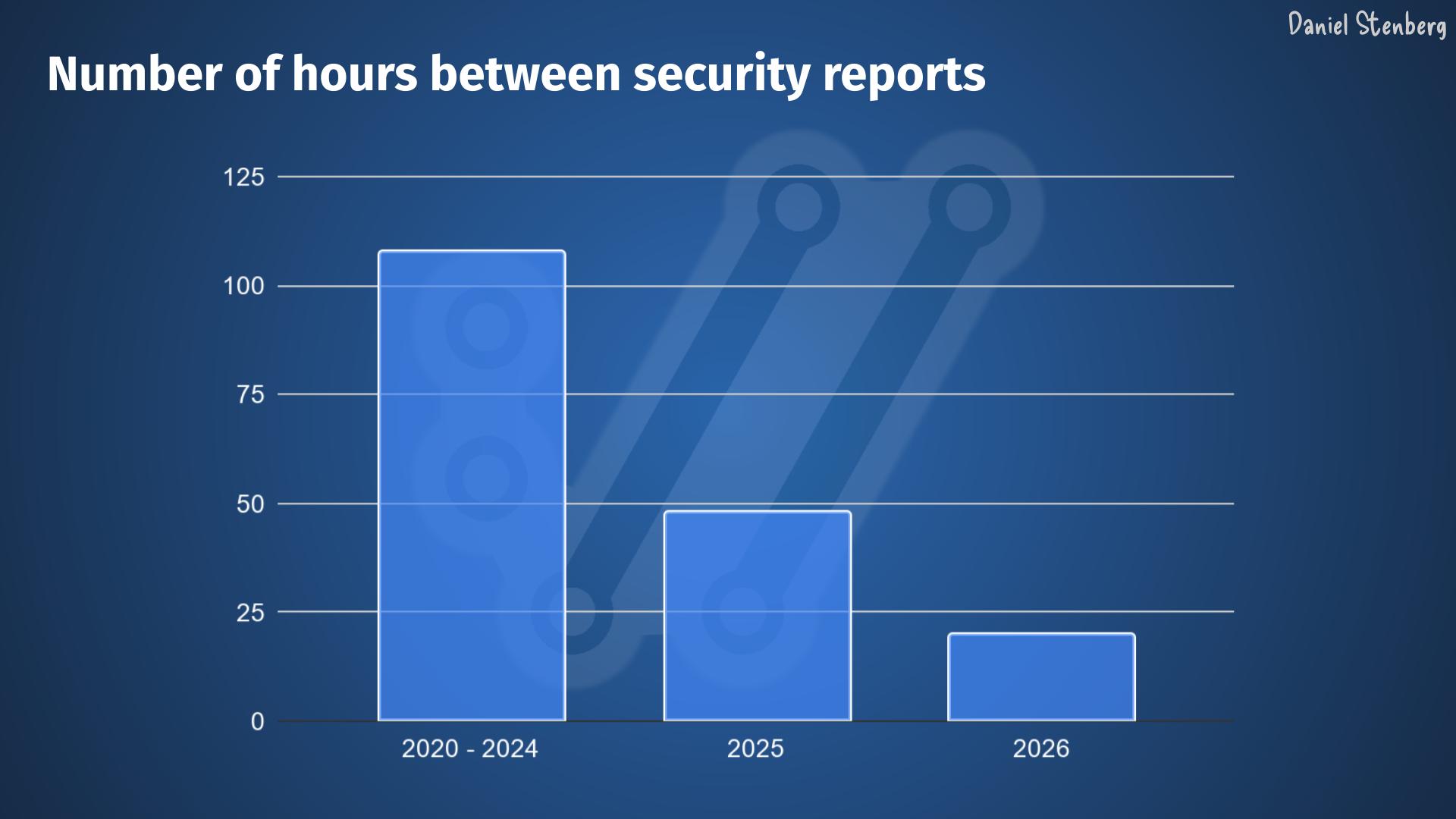
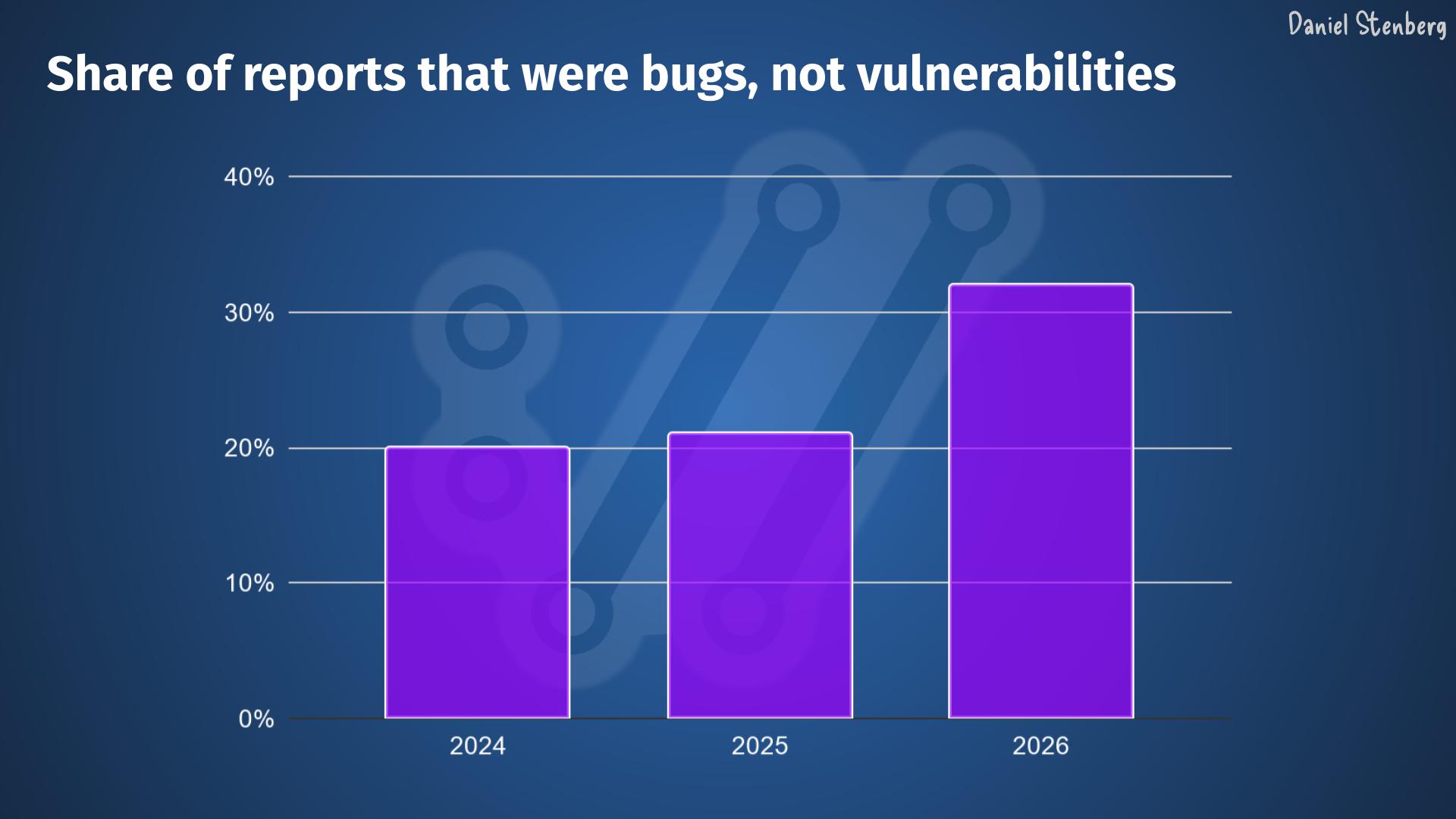
The quality is higher. The rate of confirmed vulnerabilities is back to and even surpassing the 2024 pre-AI level, meaning somewhere in the 15-16% range.
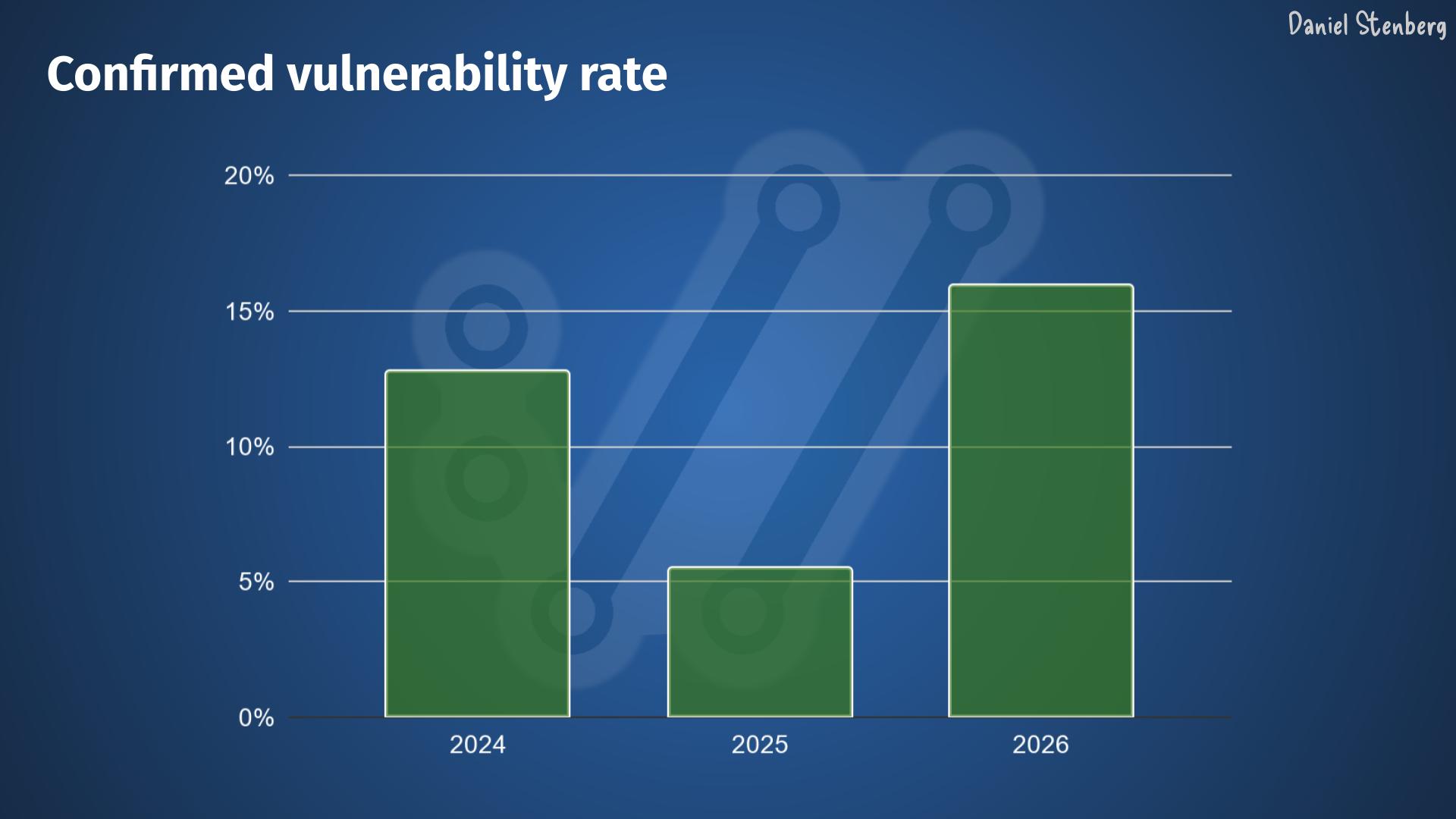
In addition to that, the share of reports that identify a bug, meaning that they aren’t vulnerabilities but still some kind of problem, is significantly higher than before.
Everything is AI now
Almost every security report now uses AI to various degrees. You can tell by the way they are worded, how the report is phrased and also by the fact that they now easily get very detailed duplicates in ways that can’t be done had they been written by humans.
The difference now compared to before however, is that they are mostly very high quality.
The reporters rarely mention exactly which AI tool or model they used (and really, we don’t care), but the evidence is strong that they used such help.
We are not unique
I did a quick unscientific poll on Mastodon to see if other Open Source projects see the same trends and man, do they! Friends from the following projects confirmed that they too see this trend. Of course the exact numbers and volumes vary, but it shows its not unique to any specific project.
Apache httpd, BIND, curl, Django, Elasticsearch Python client, Firefox, git, glibc, GnuTLS, GStreamer, Haproxy, Immich, libssh, libtiff, Linux kernel, OpenLDAP, PowerDNS, python, Prometheus, Ruby, Sequoia PGP, strongSwan, Temporal, Unbound, urllib3, Vikunja, Wireshark, wolfSSL, …
I bet this list of projects is just a random selection that just happened to see my question. You will find many more experiencing and confirming this reality view.
An explosion
When we ship curl 8.20.0 in the middle of next week – end of April 2026, we expect to announce at least six new vulnerabilities. Assuming that the trend keeps up for at least the rest of the year, and I think that is a fair assumption, we are looking at an estimated explosion and a record amount of CVEs to be published by the curl project this year.
We might publish closer to 50 curl vulnerabilities in 2026.
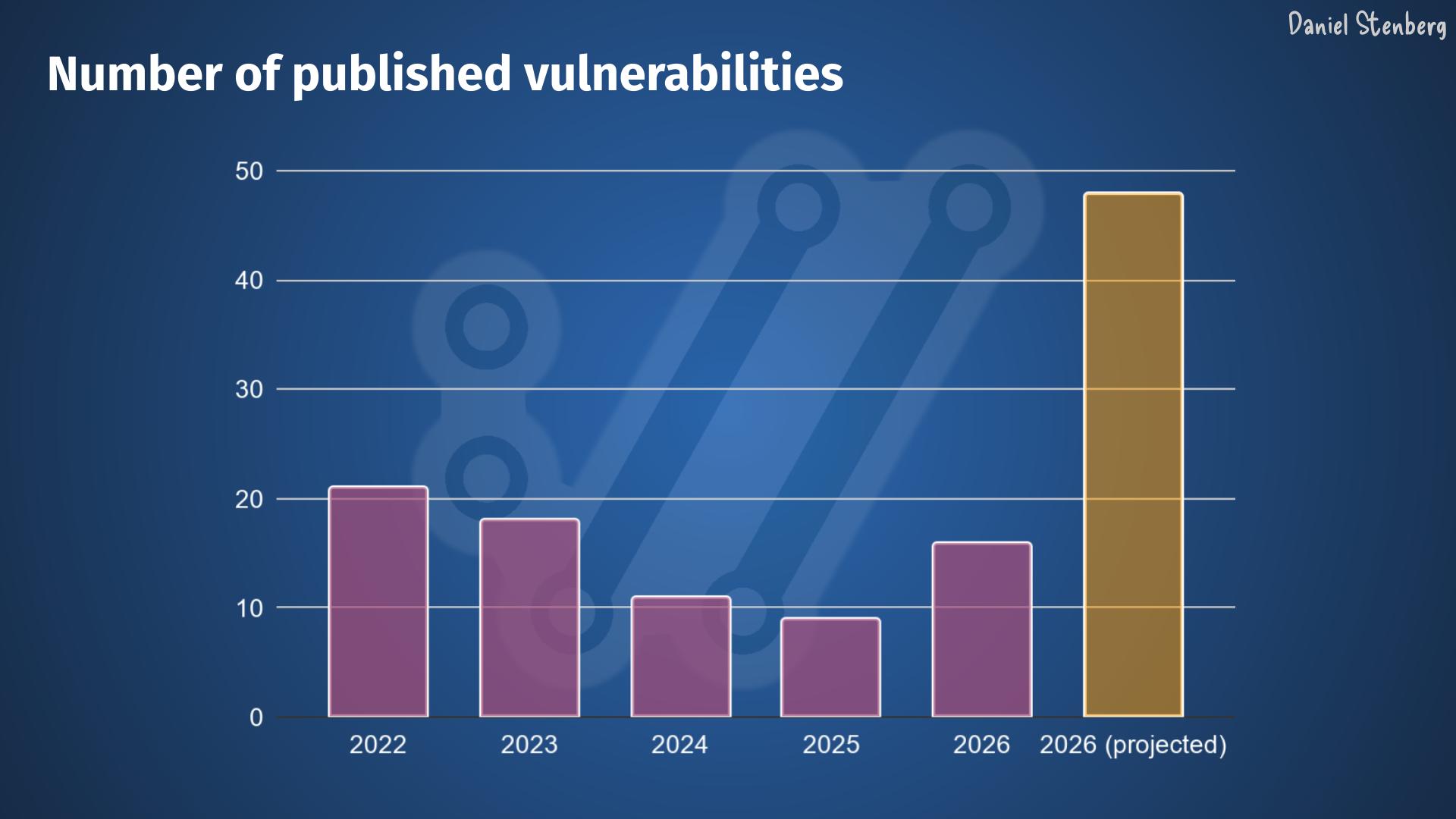
Given this universal trend, I cannot see how this pattern can not also be spotted and expected to happen in many other projects as well.
Where does it end?
The tools are still improving. We keep adding flaws when we do bugfixes and add new features.
Someone has suggested it might work as with fuzzing, that we will see a plateau within a few years. I suppose we just have to see how it goes.
This avalanche is going to make maintainer overload even worse. Some projects will have a hard time to handle this kind of backlog expansion without any added maintainers to help.
It is probably a good time for the bad guys who can easily find this many problems themselves by just using the same tools, before all the projects get time, manpower and energy to fix them.
Then everyone needs to update to the newly released fixed versions of all packages, which we know is likely to take an even longer time.
We are up for a bumpy ride.