The time has come for you to once again do your curl community duty. Run over and fill in the curl user survey and tell us about how you use curl etc. This is the only proper way we get user feedback on a wide scale so please use this opportunity to tell us what you really think.
This is the 12th time the survey runs. It is generally similar to last year’s but with some details updated and refreshed.
The survey stays up for fourteen days. Tell your friends.
On the completely impossible situation of blocking the Tor .onion TLD to avoid leaks, but at the same time not block it to make users able to do what they want.
dot-onion leaks
The onion TLD is a Tor specific domain that does not mean much to the world outside of Tor. If you try to resolve one of the domains in there with a normal resolver, you will get told that the domain does not exist.
If you ask your ISP’s resolver for such a hostname, you also advertise your intentions to speak with that domain to a sizeable portion of the Internet. DNS is inherently commonly insecure and has a habit of getting almost broadcast to lots of different actors. A user on this IP address intends to interact with this .onion site.
It is thus of utter importance for Tor users to never use the normal DNS system for resolving .onion names.
Remedy: refuse them
To help preventing DNS leaks as mentioned above, Tor people engaged with the IETF and the cooperation ultimately ended up with the publication of RFC 7686: The “.onion” Special-Use Domain Name. Published in 2015.
This document details how libraries and software should approach handling of this special domain. It basically says that software should to a large degree refuse to resolve such hostnames.
Eight years later the issue was still lingering in that document and curl had still not done anything about it, when Matt Jolly emerged from the shadows and brought a PR that finally implemented the filtering the RFC says we should do. Merged into curl on March 30, 2023. Shipped in the curl 8.1.0 release that shipped in May 17, 2023. Two years ago.
Since that release, curl users would not accidentally leak their .onion use.
A curl user that uses Tor would obviously use a SOCKS proxy to access the Tor network like they always have and then curl would let the Tor server do the name resolving as that is the entity here that knows about Tor and the dot onion domain etc.
That’s the thing with using a proxy like this. A network client like curl can hand the full host name to the proxy server and let that do the resolving magic instead of it being done by the client. It avoids leaking names to local name resolvers.
Controversy
It did not take long after curl started support the RFC that Tor themselves had pushed for, when Tor users with creative network setups realized and had opinions.
A proposal appeared to provide an override of the filter based on an environment variable for users who have a setup where the normal name resolver is already protected somehow and is known to be okay. Environment variables make for horrible APIs and the discussion did not end up in any particular consensus for other solutions so this suggestion did not make it through into code.
This issue has subsequently popped up a few more times when users have had some issues, but no fix or solution has been merged. curl remains blocking this domain. Usually people realize that when using the SOCKS proxy correctly, the domain name works as expected and that has then been the end of the discussions.
oniux
This week the Tor project announced a new product of their: oniux: a command-line utility providing Tor network isolation for third-party applications using Linux namespaces.
On their introductory web page explaining this new tool they even show it off using a curl command line:
(I decided to shorten the hostname here for illustration purposes.)
Wait a second, isn’t that a .onion hostname in that URL? Now what does curl do with .onion host names since that release two years ago?
Correct: that illustrated command line only works with old curl versions from before we implemented support for RFC 7686. From before we tried to do in curl what Tor indirectly suggested we should do. So now, when we try to do the right thing, curl does not work with this new tool Tor themselves launched!
At least we can’t say we get do live a dull life.
Hey this doesn’t work!
No really? Tell us all about it. Of course there was immediately an issue submitted against curl for this, quite rightfully. That tool was quite clearly made for a use case like this.
In a recent educational trick, curl contributor James Fuller submitted a pull-request to the project in which he suggested a larger cleanup of a set of scripts.
In a later presentation, he could show us how not a single human reviewer in the team nor any CI job had spotted or remarked on one of the changes he included: he replaced an ASCII letter with a Unicode alternative in a URL.
This was an eye-opener to several of us and we decided we needed to up our game. We are the curl project. We can do better.
GitHub
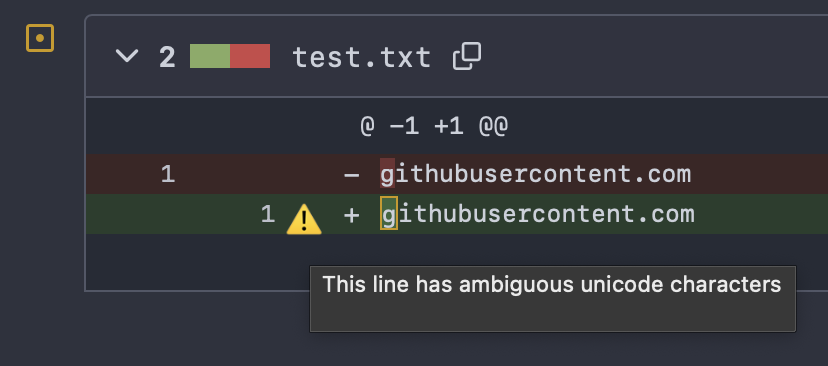
The replacement symbol looked identical to the ASCII version so it was not possible to visually spot this, but the diff viewer knows there is a difference.
In this GitHub website screenshot below I reproduced a similar case. The right-side version has the Latin letter ‘g’ replaced with the Armenian letter co. They appear to be the same.
GitHub shows a diff. But what is actually the difference?
The diff viewer says there is a difference but as a human it isn’t possible to detect what it is. Is it a flaw? Does it matter? If done “correctly”, it would be done together with a real and expected fix.
The impact of changing one or more letters in a URL can of course be devastating depending on conditions.
When I flagged about this rather big omission to GitHub people, I got barely no responses at all and I get the feeling the impact of this flaw is not understood and acknowledged. Or perhaps they are all just too busy implementing the next AI feature we don’t want.
Warnings
When we discussed this problem on Mastodon earlier this week, Viktor Szakats provided me with an example screenshot of doing a similar stunt with Gitea which quite helpfully highlights that there is something special about the replacement:
Gitea warns that the replacement is using “ambiguous Unicode characters”
I have been told that some of the other source code hosting services also show similar warnings.
As a user, I would actually like to know even more than this, but at least this warns about the proposed change clearly enough so that if this happens I would get the code manually and investigate before accepting such a change.
Detect
While we wait for GitHub to wake up and react (which I have no expectation will actually happen anytime soon), we have implemented checks to help us poor humans spot things like this. To detect malicious Unicode.
We have added a CI job that scans all files and validates every UTF-8 sequence in the git repository.
In the curl git repository most files and most content are plain old ASCII so we can “easily” whitelist a small set of UTF-8 sequences and some specific files, the rest of the files are simply not allowed to use UTF-8 at all as they will then fail the CI job and turn up red.
In order to drive this change home, we went through all the test files in the curl repository and made sure that all the UTF-8 occurrences were instead replaced by other kind of escape sequences and similar. Some of them were also used more or less by mistake and could easily be replaced by their ASCII counterparts.
The next time someone tries this stunt on us it could be someone with less good intentions, but now ideally our CI will tell us.
Confusables
There are plenty of tools to find similar-looking characters in different Unicode sets. One of them is provided by the Unicode consortium themselves:
This was yet another security-related fix reacting on a demonstrated problem. I am sure there are plenty more problems which we have not yet thought about nor been shown and therefore we do not have adequate means to detect and act on automatically.
We want and strive to be proactive and tighten everything before malicious people exploit some weakness somewhere but security remains this never-ending race where we can only do the best we can and while the other side is working in silence and might at some future point attack us in new creative ways we had not anticipated.
That future unknown attack is a tricky thing.
Update
(At 17:30 on the same day of the original post) GitHub has told me they have raised this as a security issue internally and they are working on a fix.
The other week we shipped the 266th curl release. This counter is perhaps a little inflated since it also includes the versions we did before we renamed it to curl, but still, there are hundreds of them. We keep cranking them out at least once every eight weeks; more often than so when we need to do patch releases. There is no planned end or expected change to this system for the foreseeable future. We can assume around ten new curl releases per year for a long time to come.
curl releases over time since late 1996 to April 2025
Release versions
We have the simplest possible release branching model: there is only one long term development branch. We create releases from master when the time comes. This means that we only have one version that is the latest and that we never fix or patch old releases. No other long-living release branches.
You can still find older curl versions in the wild getting patched, but those are not done by the curl project. Just about every Linux distribution, for example, maintains several old curl versions to which they back-port security fixes etc.
As we work crazy hard at not breaking users and to maintain behaviors, users should always be able to upgrade to the latest version without risking to break their use cases. Even when that upgrade jump is enormous. (We offer commercial alternatives for those who want even stronger guarantees, but they are provided slightly separate from the Open Source project.)
Supported versions
The curl support we provide for no money in the Open Source curl project is of course always a best-effort with no promises. We offer paid support for those that need promises, guaranteed response times or just want more and dedicated attention.
We support users with their curl issues, independent of their version – if we can. It is however likely that we ask the reporters using old versions to first try their cases using a modern curl version to see if the problem is not already fixed, so that we do not have to waste time researching something that might not need any work.
If the user’s reported problem cannot be reproduced with the latest curl version, then we are done. Otherwise, again, the paid support option exists.
So, while this is not quite a supported versions concept, we focus our free-support efforts on recent releases – bugs that are reported on old versions that cannot be reproduced with a modern version are considered outdated.
Not really End of life
Because of this concept, we don’t really have end of life dates for our products. They are all just in varying degrees of aging. We still happily answer questions about versions shipped twenty years ago if we can, but we do not particularly care about bugs in them if they don’t seem to exist anymore.
We urge and push users into using the most recent curl versions at any time so that they get the best features, the most solid functionality and the least amount of security problems.
Or that they pay for support to go beyond this.
In reality, of course, users are regularly stuck with old curl versions. Often because they use an (outdated) Linux distribution which does not upgrade its curl package.
They all “work”
We regularly have users ask questions about curl versions we shipped ten, twelve or even fifteen years ago so we know old releases are used widely. All those old versions still mostly work and as long as they do what the users want and ask curl to do, then things are fine. At least if they use versions from distributions that back-port security fixes.
In reality of course, the users who still use the most ancient curl versions also do this on abandoned or end-of-lived distros, which means that they run insecure versions of curl – and probably basically every other tool and library they use are also insecure by then. In the best of worlds the users have perfect control and awareness of those details.
Feature window
Since we do all releases from the single master branch we have the feature window/freeze concept. We only allow merging features/changes during a few weeks in the release cycle, and all the other time we only merge bugfixes and non-feature changes. This, to make sure that the branch is as stable as possible by the time the release is to be shipped.
For a to me unknown reason IPv6 connectivity has been failing to my home the last few days. When I try to curl curl.se I get to see a lot of IPv6 related failures and instead it connects to and uses one of the IPv4 addresses.
IPv6 has been working fine for me non-stop for the last few years before this. I suspect there is something on the ISP side and they are doing some planned maintenance in a few days that might change things. It’s not a big deal, everything I do on my machine just magically and transparently adapts.
Enter the TV
In my living room my family has an LG TV from a few years back. I find it pretty neat. It runs WebOS and has a bunch of streaming apps installed. Our household currently streams shows from Netflix, Disney, Max and SVT Play (The Swedish national broadcasting) on it.
What do you think happens to the TV and its apps when IPv6 does not work although hosts still resolve to a bunch of IPv6 + IPv4 addresses?
The TV OS itself, installing apps and everything works exactly as always.
Netflix: no difference. Streams as nicely and cleanly as always. SVT Play: runs perfectly.
Disney’s app gets stuck showing a rotating progress bar that never ends. Horribly user hostile.
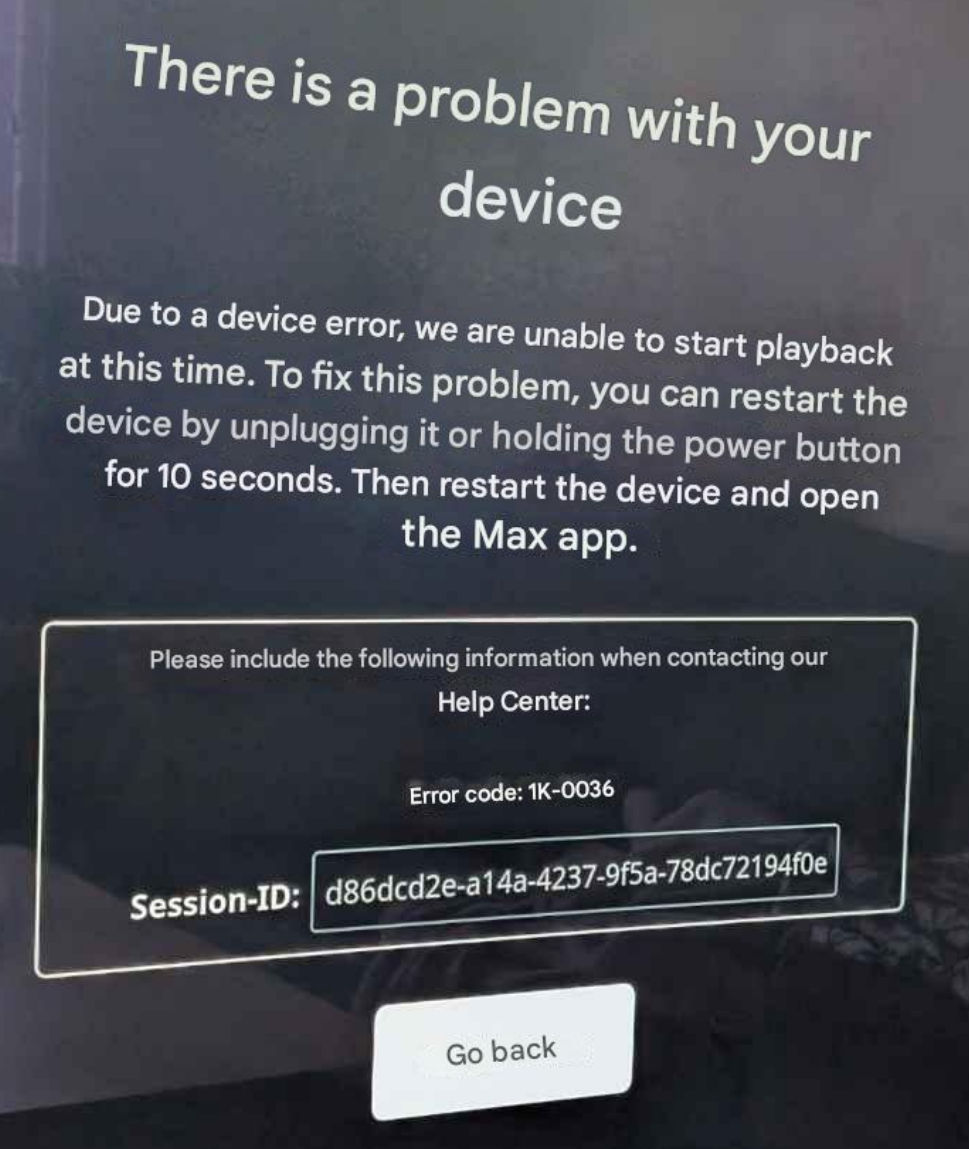
The Max app fires up and allows me to select a media to watch, and then after I press play it sits showing the progress bar for a while until it fails with this 1k-0036 error.
The original Swedish error. My TV is set to Swedish.
The translated to English version just to keep everyone in the loop.
On a computer
Trying their services using the same account on the same network but from a computer in a browser showed no problems at all.
Tracking down the problem
The Max customer service advice on how to fix this of course started out with the standard most predictable actions:
Unplug your device, keep it off for ten seconds and then start it again.
The exact same procedure with your router.
Not a word or attempt to explain what the error code actually means. But then when I told the support person that these tricks did not help, they instead asked me to disable IPv6 in the TV’s network settings.
Even though I already knew I had this glitch for the moment with IPv6, it was first when I read his advise that I actually connected the two issues. To me, the problems were so unlikely to be related that I had not even considered it!
So now we know what 1k-0036 means.
Bye bye IPv6 TV
And yeps it was quickly confirmed: disabling IPv6 in the network settings for the TV now made streaming with the Max app work again. And yes, with the Disney app as well.
I was mildly negatively surprised that these two highly popular streaming apps actually do not handle happy eyeballs and selecting between IP address families better. Rather lame.
While we know curl is part of WebOS this clearly hints that it is not used for streaming using these services at least. (Because curl has supported happy eyeballs for decades already and clearly has no problem to connect to a host just because IPv6 glitches.) Not that surprising really. We already know that Netflix for example also use curl in their app but only for most things around and not the actual media stream.
Disabling IPv6 on the TV config comes with basically no downside so I will probably just leave it off now.
James Fuller was our man on the ground in Prague. He found the venue, organized most of the event and made it another curl up success. Thank you! The curl up series started in 2017 and is our annual curl developers meetup, but since it was converted to online only for a few years through Covid, this was only our fifth physical event.
We managed to cram in no less than sixteen curl related presentations over the weekend. Some fifteen eager hackers had gathered for this years event, as per usual a whole bunch of registered attendees decided to not show up. We did not let that stop us or bring us down.
The curl up 2025 venue, as we were closing up.
In person
I think we all feel that there is value in meeting up in person every once in a while, as it helps us cooperate and work better together the rest of the time.
This time, a handful of the regular old-timers attended, and a number of less regular contributors and even a set of local interested hackers decided to take the opportunity – which is so lovely to see. We love to share our knowledge with others, and getting fresh eyes and feedback from people with different views and experiences helps us!
We talked. At the conference itself of course but also over lunches, dinners, coffee breaks and beers.
Recordings
We streamed the entire event live on Twitch and recorded all the sessions. Because we are a tiny team without any dedicated video enthusiasts etc, we of course ran into some technical snags that made us mostly botch the two initial talks (by me and Stefan Eissing) and then we gradually improved the recordings through the event. We still have fourteen talks on video now available on YouTube.
You can also head over to the curl up 2025 agenda page, and find links to the recorded talks and their corresponding slide-sets.
I have a fair idea now how we should go about this next year! And yeah, it probably involves me getting a new laptop that can actually handle the task a little gentler. At these times, my ten year old work horse certainly shows its age. It was not even considered powerful when it was new.
Sponsors
We reimburse travel and hotel expenses for top contributors to attend curl up and we make the event a free-to-attend one to remove friction and really not make it about the cost. We can only do this of course thanks to our awesome project sponsors.
Next time
We intend to run curl up again in 2026, but we do not yet know where. Ideally in another European capital that is easy reachable by plane. If you want to help us make it happen in your city, please reach out!
I was reminded that I had not really gotten back to this topic and explained to you, my dear readers, how it is and how it has worked out. This curl-being-a-CNA thing I mean.
CNA stands for CVE Numbering Authority. Every CNA has the right and ability to allocate and publish their own CVE records. We manage a “vulnerability scope” that is ours and every CNA cares for all CVEs within our own respective scopes. Right now there are 450 CNAs, up from 350 when we joined.
CVE instability
Recently the entire CVE system has been shaky. The funding was gone, came back and now while back still seems unreliable and the entire thing is like walking on thin ice. While a related issue, it is not really changing how we work with vulnerabilities and our role as CNA. If the CVE system breaks down and we change to something else tomorrow, we would still try to work exactly the same under that system.
It was never a good idea for CVE to be so tightly associated with or under the control of the US government (any government really). Maybe this can still push the development in the right direction?
Becoming CNA
A primary reason for us to become CNA was to be able to block bogus CVEs from being registered against curl. This has worked fine, but we also have not yet had to reject a single CVE request…!
A secondary reason was to be able to set our own severity levels for the issues we publish. This has not worked out great – or at all really. Or rather, we can indeed set our own CVSS scores on issues and then that would had been fine, but since we object to the one-dimensional impossible mission of setting a single score for a problem with a product that can be used in virtually any product and in any context, it does not. When we don’t fill in the CVSS field, someone else does it for us and they do it more or less by rolling dice.
More on CVSS below.
The actual process of becoming a CNA is straight-forward. It does not cost any money (just some time and effort), there is not a lot of red tape or weirdo procedures to follow or forms to fill in. There are just a few basic and quite reasonable steps and confirmations made, and then you’re in.
Being CNA
The actual being a CNA part is a low friction and low maintenance role. Allocating and publishing CVEs can of course be burdensome, but it’s not a lot more work to do it yourself than to fill in forms and have someone else press submit.
The bulk of the security work in curl is still the same as before we became a CNA, as that is the researching, understanding, debating and assessing part of it. In our case, we had meticulous control and check of every possible detail of our security related issues already before and we still do. We take pride in providing top notch security information.
Working on the inside
Being a CNA of course allows us to discuss and work on things for and related to the CVE project on “the inside”. There are two things I primarily want like to see addressed:
Flaw 1 – everyone must be a CNA
The fact that the CVE system works so bad for involved parties (like Open Source projects) that are not CNAs I believe is a primary weakness in the system. I believe this is the main reason for the current avalanche of new CNAs signing up. We all want control of CVEs assigned to us – or claiming to be about our products.
I would like to see a system where projects could add their products to the scope of an existing CNA so that small projects can avoid becoming a CNA but still “protect” and “own” their respective CVE spaces. This alone would drastically lessen the need and attraction of the whole world becoming CNAs. I don’t think there is anything inherent in the system that prevents this from working, but it would perhaps be good with a more formalized way of accepting this approach.
Flaw 2 – CVSS is often more of a joke than useful
There is this OSS CNA user group, an informal formation of Open Source based CNAs that discuss CVE and vulnerability management within this system, and as a team we are currently drafting a proposal to allow Open Source projects to prevent ADPs (Authorized Data Publishers) like CISA to amend CVE records with CVSS scores.
This is far from being just a curl problem. The Linux kernel has it, perl has it, lots of projects who do foundational and ubiquitous software do. When we report a security problem, it is next to impossible for us to assess the CVSS score in a way that would work for everyone as our stuff can be used in some many different places in so many different ways.
For this reason we avoid setting CVSS scores, but for now we cannot stop official ADPs to then step in and do it for us. We cannot say stop. We cannot prevent them from doing this. We want to establish a formal mechanism and process where can say STOP. To tell them hands off from our CVSS score field. To let it remain unset if we decide so.
Other flaws
Of course there are more issues in this system, but I consider the two ones mentioned above more important than others.
Future
Remind me and I’ll follow up in a year or so and see how things are different if at all. I expect lots of new CNAs in the meantime. I expect the CVE system to go through at least some metamorphosis following in the footsteps of the US breakdown. I expect 2025 to have substantially more CVE entries published than during 2024 and I expect 2026 to have even more.
On April 10 we ran the curl distro meeting 2025. A, by now, annual open meeting where maintainers from the curl project hang out with curl package maintainers for distros and other people who are interested. The mission is to improve curl for distros, and improve how the distros “do” curl.
Around ten people joined. There were representatives present from several different Linux distributions (Arch, Gentoo, Alpine and Debian) and a few curl maintainers.
We spent our two full hours talking and while we did not really follow the agenda, we managed to touch all the included subjects. Some of them of course more than others. (There is no recording and I do not mention names here – on purpose.)
A fair amount of time was spent on the topic of TLS libraries and the different statuses for them in curl, in particular in regards to QUIC/HTTP/3, ECH and Post Quantum.
This exact day ngtcp2 merged their PR that adds support for the OpenSSL QUIC API which opens up the ability to soon do HTTP/3 using OpenSSL in curl better than before and there was some excitement and interest expressed around this.
Viktor explained to the team how you can enable unity builds and test bundles that in some environments speed up build and test execution times significantly. They basically lump all the source code files into a single file and then compile that. Worth testing if that helps your build!
We talked about the success of the recently introduced release candidates. I have promised to come up with a tag/branch scheme for them to make it easier for everyone to see them, find them and access them directly in and with git.
Lots of regressions (well, four or five at least) were found in the 8.13.0 rc releases due to Debian’s excellent reverse-dependencies rerunning tests against the rc builds. It was also reported that Debian has started to run curl’s Debug tests, that are tests in the curl test suite that requires that it was built Debug enabled. Such builds have extra special code in certain places to alter internals in ways suitable for extra testing, but not suitable to remain in there in production. The curl test infra was recently improved so that we can now run only the Debug tests when wanted.
We discussed how the Debian maintainers found a regression in 8.13.0 that broke reproducible builds, but that this problem had not been detected by the curl project itself and not by anyone else either. Ideas were shared about what we can do to make it more likely that we catch a similar mistake the next time. This problem was an unstable sort in a script that changed the order based on the locale but most of us ran the verification using the same locale as the original was produced with…
We had quite some discussions around wcurl and the proposal to bundle the wcurl script in future curl release tarballs with the final verdict that yes we will do so. This was the second action item for me from the meeting: work out how to best include wcurl in future releases in a good reproducible manner and write a PR for it.
trurl was mentioned briefly, but no one had a lot to say. It’s there. It works. It is probably not terribly widely used.
Appreciation was expressed for the way we manage security advisories and the information we provide in association with them. I mentioned how I recently improved the JSON output format we offer. We briefly touched the fact that we (curl) are now a CNA and I was asked to maybe write a blog post about how it has been and how it works. My third action item.
The curl-distros mailing list was setup as a direct result of last year’s meeting and it has proven to be an asset during the last year. Let’s keep using it and maybe even use it more! curl related issues and problems in one distro very often affects or spill over to other distros. Sharing details and lessons bout found and fixed regressions allows us to share the load and improve universally.
There is a curl Google calendar that contains all curl release dates, as well as the feature freeze/window dates and now also all rc release dates. Using this, future dates for these events should never have to come as a surprise!
It is a somewhat common question to me: how do we write C in curlto make it safe and secure for billions of installations? Some precautions we take and decisions we make. There is no silver bullet, just guidelines. As I think you can see for yourself below they are also neither strange nor surprising.
The ‘c’ in curl does not and never did stand for the C programming language, it stands for client.
Disclaimer
This text does in no way mean that we don’t occasionally merge security related bugs. We do. We are human. We do mistakes. Then we fix them.
Testing
We write as many tests as we can. We run all the static code analyzer tools we can on the code – frequently. We run fuzzers on the code non-stop.
C is not memory-safe
We are certainly not immune to memory related bugs, mistakes or vulnerabilities. We count about 40% of our security vulnerabilities to date to have been the direct result of us using C instead of a memory-safe language alternative. This is however a much lower number than the 60-70% that are commonly repeated, originating from a few big companies and projects. If this is because of a difference in counting or us actually having a lower amount of C problems, I cannot tell.
Over the last five years, we have received no reports identifying a critical vulnerability and only two of them were rated at severity high. The rest ( 60 something) have been at severity low or medium.
We currently have close to 180,000 lines of C89 production code (excluding blank lines). We stick to C89 for widest possible portability and because we believe in continuous non-stop iterating and polishing and never rewriting.
Readability
Code should be easy to read. It should be clear. No hiding code under clever constructs, fancy macros or overloading. Easy-to-read code is easy to review, easy to debug and easy to extend.
Smaller functions are easier to read and understand than longer ones, thus preferable.
Code should read as if it was written by a single human. There should be a consistent and uniform code style all over, as that helps us read code better. Wrong or inconsistent code style is a bug. We fix all bugs we find.
We have tooling that verify basic code style compliance.
Narrow code and short names
Code should be written narrow. It is hard on the eyes to read long lines, so we enforce a strict 80 column maximum line length. We use two-spaces indents to still allow us to do some amount of indent levels before the column limit becomes a problem. If the indent level becomes a problem, maybe it should be split up in several sub-functions instead?
Also related: (in particular local) identifiers and names should be short. Having long names make them hard to read, especially if there are multiple ones that are similar. Not to mention that they can get hard to fit within 80 columns after some amount of indents.
So many people will now joke and say something about wide screens being available and what not but the key here is readability. Wider code is harder to read. Period. The question could possibly be exactly where to draw the limit, and that’s a debate for every project to have.
Warning-free
While it should be natural to everyone already, we of course build all curl code entirely without any compiler warning in any of the 220+ CI jobs we perform. We build curl with all the most picky compiler options that exist with the set of compilers we use, and we silence every warning that appear. We treat every compiler warning as an error.
Avoid “bad” functions
There are some C functions that are just plain bad because of their lack of boundary controls or local state and we avoid them (gets, sprintf, strcat, strtok, localtime, etc).
There are some C functions that are complicated in other ways. They have too open ended functionality or do things that often end up problematic or just plain wrong; they easily lead us into doing mistakes. We avoid sscanf and strncpy for those reasons.
We have tooling that bans the use of these functions in our code. Trying to introduce use of one of them in a pull request causes CI jobs to turn red and alert the author about their mistake.
Buffer functions
Years ago we found ourselves having done several mistakes in code that were dealing with different dynamic buffers. We had too many separate implementations working on dynamically growing memory areas. We unified this handling with a new set of internal help functions for growing buffers and now made sure we only use these. This drastically reduces the need for realloc(), which helps us avoid mistakes related to that function.
Each dynamic buffer also has its own maximum size set, which in its simplicity also helps catching mistakes. In the current libcurl code, we have 80 something different dynamic buffers.
Parsing functions
I mentioned how we don’t like sscanf. It is a powerful function for parsing, but it often ends up parsing more than what the user wants (for example more than one space even if only one should be accepted) and it has weak (non-existing) handling of integer overflows. Lastly, it steers users into copying parsed results around unnecessarily, leading to superfluous uses of local stack buffers or short-lived heap allocations.
Instead we introduced another set of helper functions for string parsing, and over time we switch all parser code in curl over to using this set. It makes it easier to write strict parsers that only match exactly what we want them to match, avoid extra copies/mallocs and it does strict integer overflow and boundary checks better.
Monitor memory function use
Memory problems often involve a dynamic memory allocation followed by a copy of data into the allocated memory area. Or perhaps, if the allocation and the copy are both done correctly there is no problem but if either of them are wrong things can go bad. Therefor we aim toward minimizing that pattern. We rather favor strdup and memory duplication that allocates and copies data in the same call – or uses of the helper functions that may do these things behind their APIs. We run a daily updated graph in the curl dashboard that shows memory function call density in curl. Ideally, this plot will keep falling over time.
Memory function call density in curl production code over time
It can perhaps also be added that we avoid superfluous memory allocations, in particular in hot paths. A large download does not need any more allocations than a small one.
Double-check multiplications
Integer overflows is another area for concern. Every arithmetic operation done needs to be done with a certainty that it does not overflow. This is unfortunately still mostly a manual labor, left for human reviews to detect.
64-bit support guaranteed
In early 2023 we dropped support for building curl on systems without a functional 64-bit integer type. This simplifies a lot of code and logic. Integer overflows are less likely to trigger and there is no risk that authors accidentally believe they do 64-bit arithmetic while it could end up being 32-bit in some rare builds like could happen in the past. Overflows and mistakes can still happen if using the wrong type of course.
Maximum string length
To help us avoid mistakes on strings, in particular with integer overflows, but also with other logic, we have a general check of all string inputs to the library: they do not accept strings longer than a set limit. We deem that any string set that is longer is either just a blatant mistake or some kind of attempt (attack?) to trigger something weird inside the library. We return error on such calls. This maximum limit is right now eight megabytes, but we might adjust this in the future as the world and curl develop.
keep master golden
At no point in time is it allowed to break master. We only merge code into master that we believe is clean, fine and runs perfect. This still fails at times, but then we do our best at addressing the situation as quickly as possible.
Always check for and act on errors
In curl we always check for errors and we bail out without leaking any memory if (when!) they happen. This includes all memory operations, I/O, file operations and more. All calls.
Some developers are used to modern operating systems basically not being able to return error for some of those, but curl runs in many environments with varying behaviors. Also, a system library cannot exit or abort on errors, it needs to let the application take that decision.
APIs and ABIs
Every function and interface that is publicly accessible must never be changed in a way that risks breaking the API or ABI. For this reason and to make it easy to spot the functions that need this extra precautions, we have a strict rule: public functions are prefixed with “curl_” and no other functions use that prefix.
Everyone can do it
Thanks to the process of human reviewers, plenty of automatic tools and an elaborate and extensive test suite, everyone can (attempt to) write curl code. Assuming you know C of course. The risk that something bad would go in undetected, is roughly equal no matter who the author of the code is. The responsibility is shared.
the 266th release 12 changes 48 days (total: 9,875) 305 bugfixes (total: 11,786) 499 commits (total: 34,782) 0 new public libcurl function (total: 96) 1 new curl_easy_setopt() option (total: 307) 1 new curl command line option (total: 268) 71 contributors, 37 new (total: 3,379) 41 authors, 16 new (total: 1,358) 0 security fixes (total: 164)
Changes
curl: new write-out variable ‘tls_earlydata’
curl: –url supports a file with URLs
curl: add ’64dec’ function for base64 decoding
IMAP: add CURLOPT_UPLOAD_FLAGS and –upload-flags
add CURLFOLLOW_OBEYCODE and CURLFOLLOW_FIRSTONLY
gnutls: set priority via –ciphers
OpenSSL/quictls: support TLSv1.3 early data
wolfSSL: support TLSv1.3 early data
rustls: add support for CERTINFO
rustls: add support for SSLKEYLOGFILE
rustls: support ECH w/ DoH lookup for config
rustls: support native platform verifier
Records
This release broke the old project record and is the first release ever to contain more than 300 bugfixes since the previous release. There were so many bugfixes landed that I decided to not even list my favorites in this blog post the way I have done in the past. Go read the full changelog, or watch the release video to see me talk about some of them.
Another project record broken in this release is the amount commits merged into the repository since the previous release: 501.