Last spring I wrote a blog post about our ongoing work in the background to gradually simplify the curl source code over time.
This is a follow-up: a status update of what we have done since then and what comes next.
In May 2025 I had just managed to get the worst function in curl down to complexity 100, and the average score of all curl production source code (179,000 lines of code) was at 20.8. We had 15 functions still scoring over 70.
Almost ten months later we have reduced the most complex function in curl from 100 to 59. Meaning that we have simplified a vast number of functions. Done by splitting them up into smaller pieces and by refactoring logic. Reviewed by humans, verified by lots of test cases, checked by analyzers and fuzzers,
The current 171,000 lines of code now has an average complexity of 15.9.
Complexity
The complexity score in this case is just the cold and raw metric reported by the pmccabe tool. I decided to use that as the absolute truth, even if of course a human could at times debate and argue about its claims. It makes it easier to just obey to the tool, and it is quite frankly doing a decent job at this so it’s not a problem.
How to simplify
In almost all cases the main problem with complex functions is that they do a lot of things in a single function – too many – where the functionality performed could or should rather be split into several smaller sub functions. In almost every case it is also immediately obvious that when splitting a function into two, three or more sub functions with smaller and more specific scopes, the code gets easier to understand and each smaller function is subsequently easier to debug and improve.
Development
I don’t know how far we can take the simplification and what the ideal average complexity score of a the curl code base might be. At some point it becomes counter-effective and making functions even smaller then just makes it harder to follow code flows and absorbing the proper context into your head.
Graphs
To illustrate our simplification journey, I decided to render graphs with a date axle starting at 2022-01-01 and ending today. Slightly over four years, representing a little under 10,000 git commits.
First, a look a the complexity of the worst scored function in curl production code over the last four years. Comparing with P90 and P99.
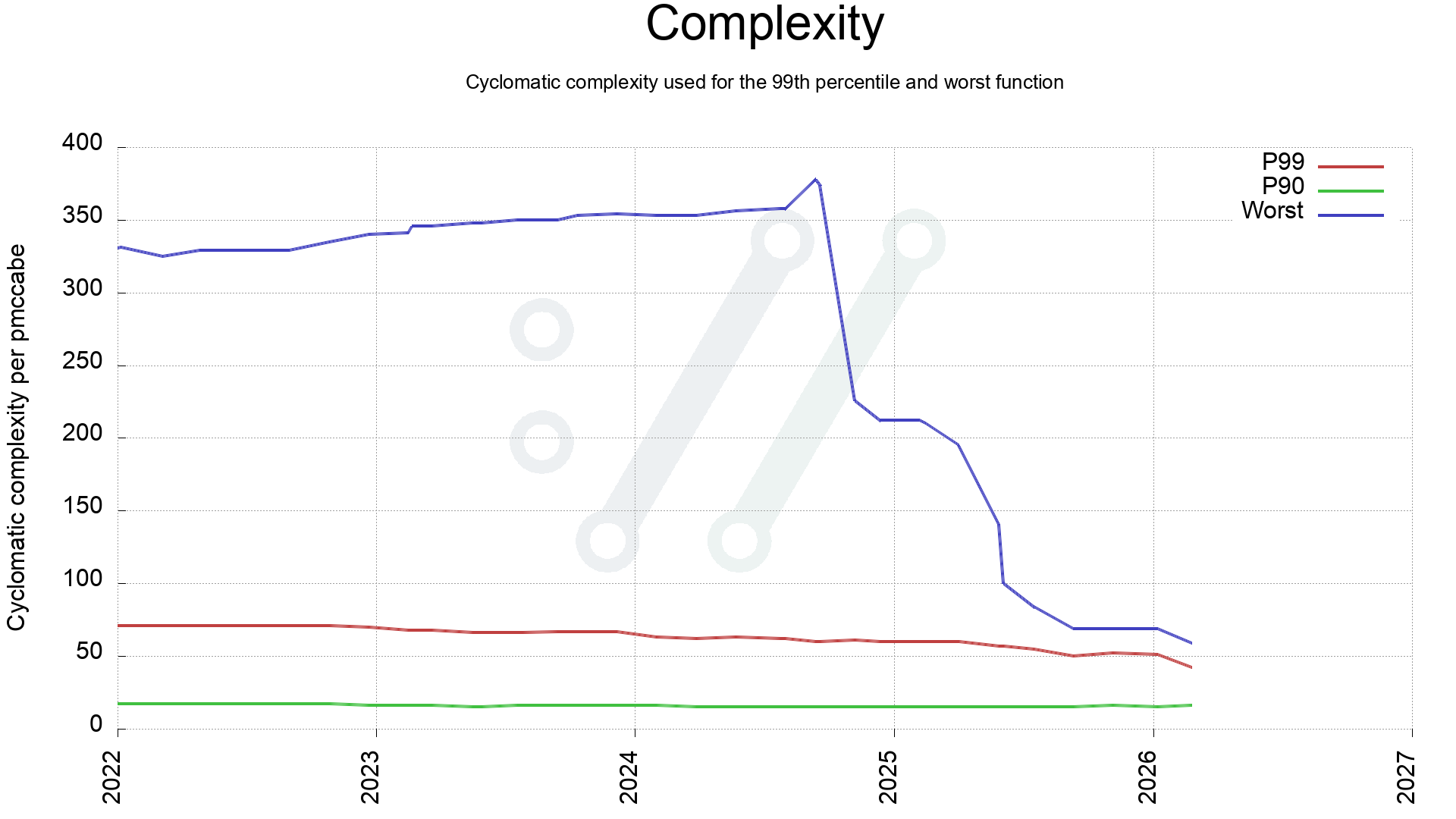
Identifying the worst function might not say too much about the code in general, so another check is to see how the average complexity has changed. This is calculated like this:
- All functions get a complexity score by pmccabe
- Each function has a number of lines
For all functions, add its function-score x function-length to a total complexity score, and in the end, divide that total complexity score on total number of lines used for all functions. Also do the same for a median score.
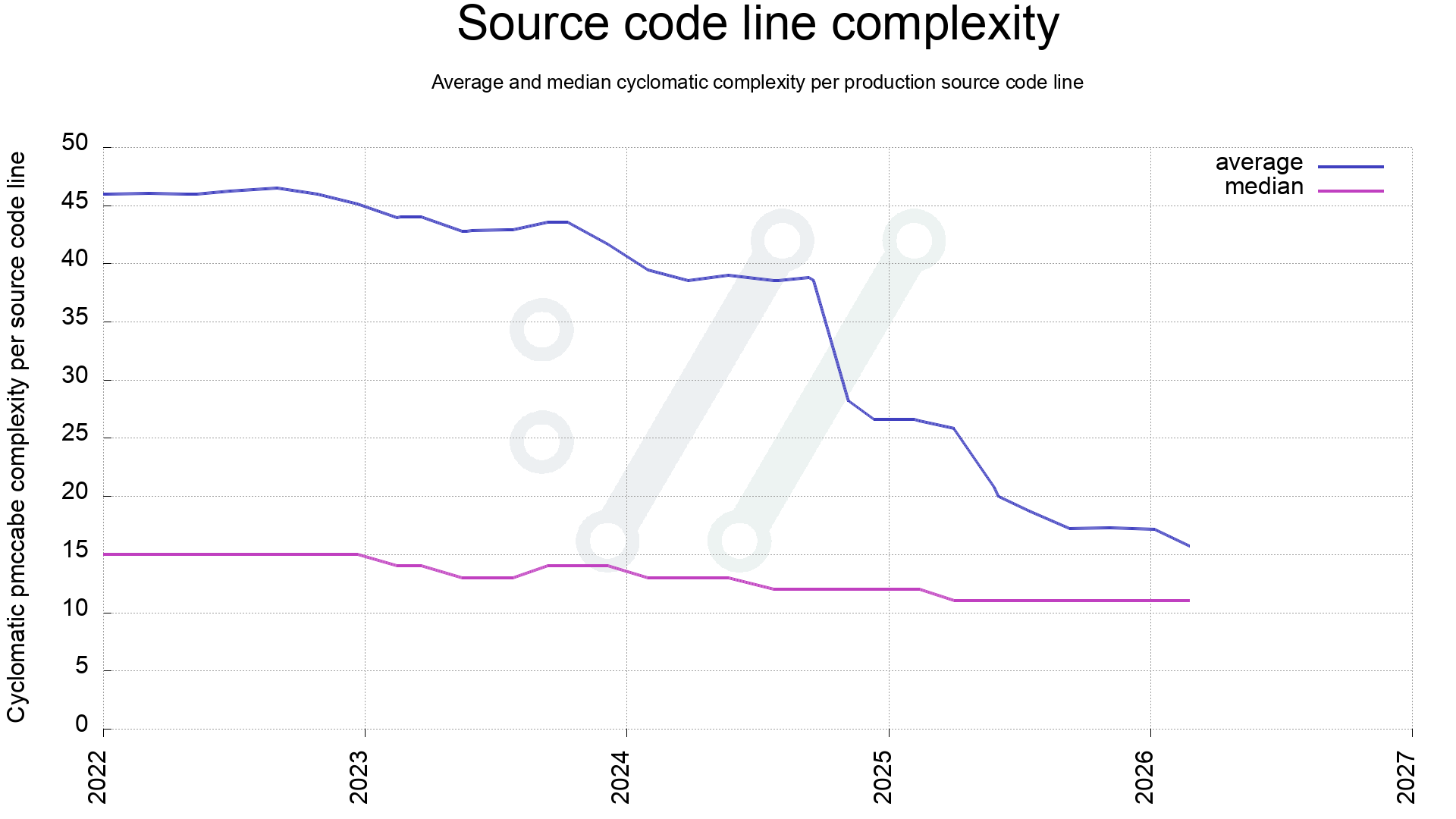
When 2022 started, the average was about 46 and as can be seen, it has been dwindling ever since, with a few steep drops when we have merged dedicated improvement work.
One way to complete the average and median lines to offer us a better picture of the state, is to investigate the complexity distribution through-out the source code.
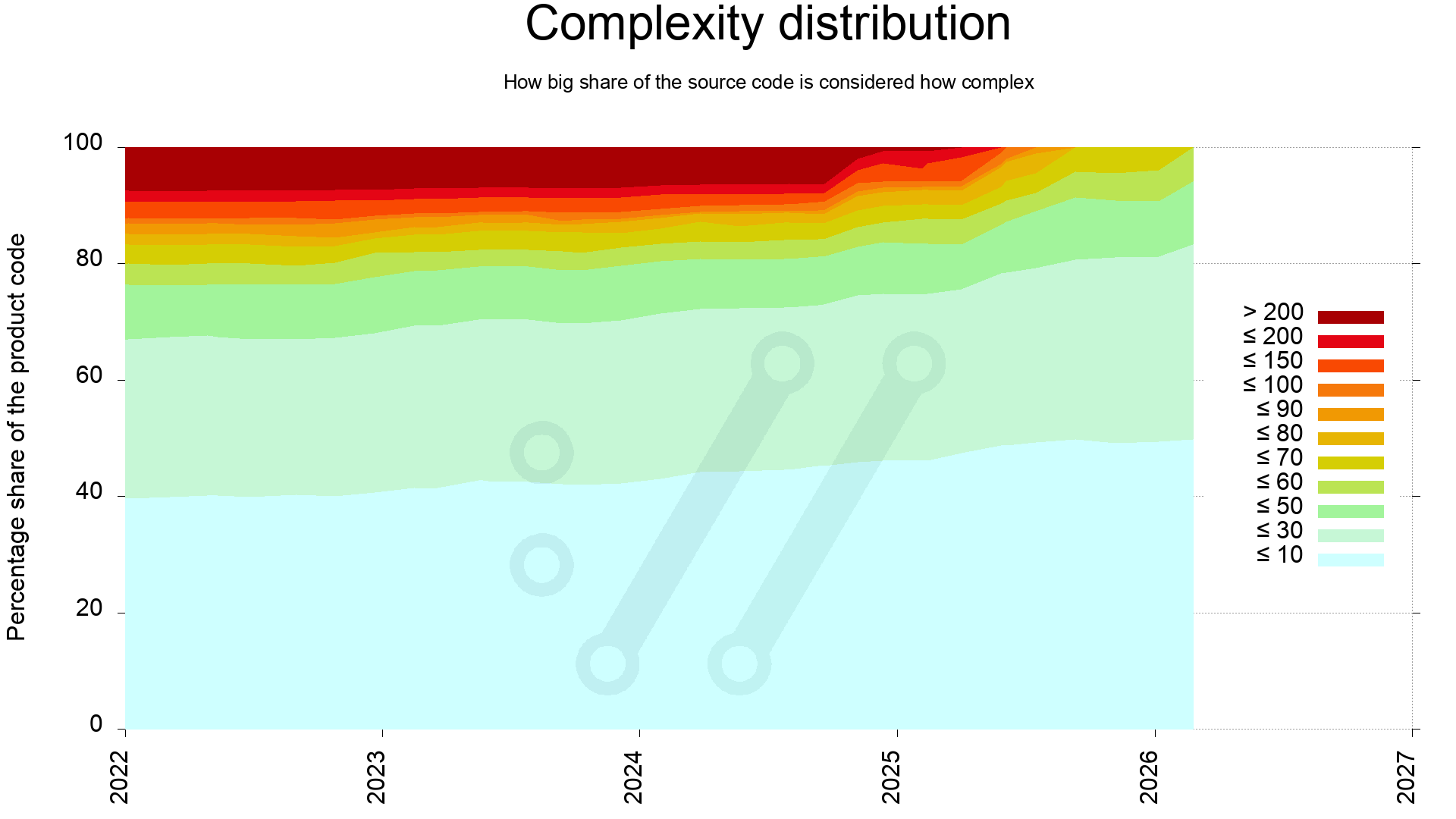
This reveals that the most complex quarter of the code in 2022 has since been simplified. Back then 25% of the code scored above 60, and now all of the code is below 60.
It also shows that during 2025 we managed to clean up all the dark functions, meaning the end of 100+ complexity functions. Never to return, as the plan is at least.
Does it matter?
We don’t really know. We believe less complex code is generally good for security and code readability, but it is probably still too early for us to be able to actually measure any particular positive outcome of this work (apart from fancy graphs). Also, there are many more ways to judge code than by this complexity score alone. Like having sensible APIs both internal and external and making sure that they are properly and correctly documented etc. The fact that they all interact together and they all keep changing, makes it really hard to isolate a single factor like complexity and say that changing this alone is what makes an impact.
Additionally: maybe just the refactor itself and the attention to the functions when doing so either fix problems or introduce new problems, that is then not actually because of the change of complexity but just the mere result of eyes giving attention on that code and changing it right then.
Maybe we just need to allow several more years to pass before any change from this can be measured?