A picture showing most modern digital products and services
Current digital infrastructure is to a large degree built on layers and layers of Open Source.
Open Source is to a large degree built and maintained by enthusiasts or other financially and resource restrained teams.
It should be in our mutual interest to make sure that well-used Open Source projects not only survive, but also perform well.
Critical Open Source infrastructure needs to be maintained. Maintenance is not easy nor can we expect that to be done by volunteers on their spare time.
Lots of Open Source projects are maintained by tiny teams or single individuals with small or no financial support at all.
Perhaps a better take on what digital infrastructure looks like
In Germany, the Sovereign Tech Agency was created a few years back to help with this situation. By sponsoring infrastructure projects they help enforce the ecosystem and strengthen the fabric we all rely on. They had the courage and good sense to sponsor projects anywhere, not just within Germany’s borders.
As this infrastructure challenge goes way above and beyond Germany and concerns us all, it only makes sense that this style of helping out is attempted elsewhere as well. To me, it makes perfect sense to provide this service at EU-level instead of having individual member states doing it. Or perhaps in addition to.
There is now a proposal to create such a fund. The proposal calls it the EU-STF. The European Union Sovereign Tech Fund. Following the STA’s lead, taken up a notch. More money for more projects, which ideally will help us fortify our infrastructure even better.
I think this is a good idea. I give this proposal my thumbs up.
Can’t write about this topic without using this image: XKCD 2347
The Proposal
The proposal itself is a huge and detailed 102 page PDF document. You can find it here:
The curl project (which I participate in) has received funding from the Sovereign Tech Agency (back when they were still called the Sovereign Tech Fund). We might perhaps also benefit from a future EU-STF.
The iceberg in the top illustration is not realistic. A real world iceberg shaped like that would float differently, probably tipped on its side. Experiment yourself with icebergs, their shapes and how they float on Iceberger.
The bird-on-elephant metaphor is imperfect in the sense that it is a rather working symbiotic relationship in nature. Not the same extracting value but not providing back as in software.
The xkcd metaphor is imperfect in that it does not spell out that all blocks in the lower half of the drawing are Open Source.
I am happy to announce that curl receives funding from The Sovereign Tech Fund. This funding is directed towards three specific projects that we have identified as interesting and worthwhile to push forward as ways to improve curl and the life of curl users.
This “investment” will fund two developers to work on curl over a period of six months: Stefan Eissing and myself. The three projects are explained at some detail below. Of course everyone and anyone is welcome to join in and help out with these projects. Everything will be done in the open, as usual.
At the end of the period, we will produce some kind of report or summary of how things turned out.
The three projects we are getting funded have been especially created and crafted (by me) to be good solid projects that we really want to see done. This funding is different than many others we have gotten over the years in that we got to decide and plan what we wanted done. These are things that are meant to improve curl as a project and to generally make Internet transfers better and more powerful for a vast amount of users.
Project 1 – known bugs cleanup
The curl project currently lists 120+ items as known bugs (up from 77 just two years ago).
The items in that list are reported problems that were recognized as problems at the time of their submission but as nobody worked on the issues at the time they were added to this list. The list includes everything from smaller irks up to big things that will either take a long time to fix or be (almost) impossible to address.
There is a good chance that the list will be extended during the project period just because some new bugs fall into the description mentioned above.
This project is an effort to go through as many as possible to make sure they are correctly categorized/described and work on fixing the issues or whatever is necessary to get them off the list.
The process would entail an initial proper research round to extend the description and increase the understanding of each entry, followed by a rough assessment of the amount of work it would take to fix them. Possibly with a 1 (easy) to 5 (extreme) scale.
The action would then be to address the issues, possibly in an easy to hard order. Addressing the issues could be to fix the code to remove the issue, dismiss it as not actually intended to work or document it as not working or even moving it over to the TODO document if it is more of a good idea for the future.
The goal being to reduce the list to zero entries and thus polish off numerous rough corners and annoyances in the project.
This will be done by Daniel Stenberg over a period of 6 months.
Project 2 – HTTP/3
Make HTTP/3 release-ready.
curl features experimental HTTP/3 and QUIC support already since a few years back, but there are several details still lacking:
known bugs
proper multiplexing: doing multiple transfers to the same host should be able to reuse an existing connection and multiplex over that, just as curl already does when using HTTP/2
HTTP/3 support for the test suite (and CI jobs) need to be done for us to be able to consider the support release ready. Cooperation can be had with QUIC libraries such as ngtcp2 to consider where/how some of the testing is best performed.
considerations for 0-RTT connection establishments (if anything needs to be done)
support for early data: to send off the HTTP request to the server faster.
connection migration:, a QUIC feature that allows a server to move over a live connection from one server to another without disruption
fallback to h1/h2 if the QUIC connection fails. The failure rate for QUIC connections are still in the 3-7% rate generally, so having a good fallback mechanism or documented for how applications can go back to an older HTTP version instead, is important.
HTTPS RR. This fairly new DNS resource record might contain information about the target server’s support for HTTP/3. If such a record is provided, curl can avoid superfluous round-trips to get the Alt-Svc header and rather connect directly to the HTTP/3 server.
All features and changes need to be documented. Functionality needs to be verified by test cases. Interop with real world servers is of course implied and assumed.
Stefan Eissing will spend 4 months on this project.
Project 3 – HTTP/2 over proxy
curl has provided support for doing network transfers via HTTP proxies since decades, and this is a very commonly used feature and network setup.
curl however only supports using HTTP version 1 over proxies. This makes applications less effective as it sometimes leads to many more TCP connections being used than otherwise would be necessary if HTTP/2 could be used. In particular when applications behind a proxy operate against many different hosts on the other side of the proxy.
It can also be noted that in many enterprise setups, this kind of HTTP proxy is used for all kinds of network operations through the use of the CONNECT method, so this functionality is not limited to plain HTTP(S), it should work for all TCP based protocols libcurl supports and which already work over HTTP/1 proxies.
The project will require adding new options to enable this functionality, to both the library and the command line tool. With associated documentation.
It will require creating or extending the HTTP/2 support in the curl test suite so that this new functionality can be verified and proven to work at a satisfactory level.
Considerations must be taken so that this work does not close the door for future extending this to support HTTP/3 over proxy. Time permitting, work should be taken to pave the road for that or even perhaps gently start the work to support that as well.
Stefan Eissing will spend 2 months on this project.
The outcome(s)
I hope and presume that the results of these projects will appear as a stream of pull-requests for curl that will be done and managed through-out the project period and not saved up to the end or anything. The review, test and merge process of these pull requests will follow our normal and standard project guidelines and procedures.
The projects are fully packed and (over) ambitious. There is a high risk that we will not be able to complete all the details for these projects within the time frame. But we will try.
The well-known log4j security vulnerability of December 2021 triggered a lot of renewed discussions around software supply chain security, and sometimes it has also been said to be an Open Source related issue.
This was not the first software component to have a serious security flaw, and it will not be the last.
What can we do about it?
This is the 10,000 dollar question that is really hard to answer. In this post I hope to help putting some light on to why it is such a hard problem. This comes from my view as an Open Source author and contributor since almost three decades now.
In this post I’m going to talk about security as in how we make our products have less bugs in the code we write and land on purpose. There is also a lot to be said about infrastructure problems such as consumers not verifying dependencies so that when malicious actors purposely destroy a component, users of that don’t notice the problem or supply chain security issues that risk letting bad actors insert malicious code into components. But those are not covered in this blog post!
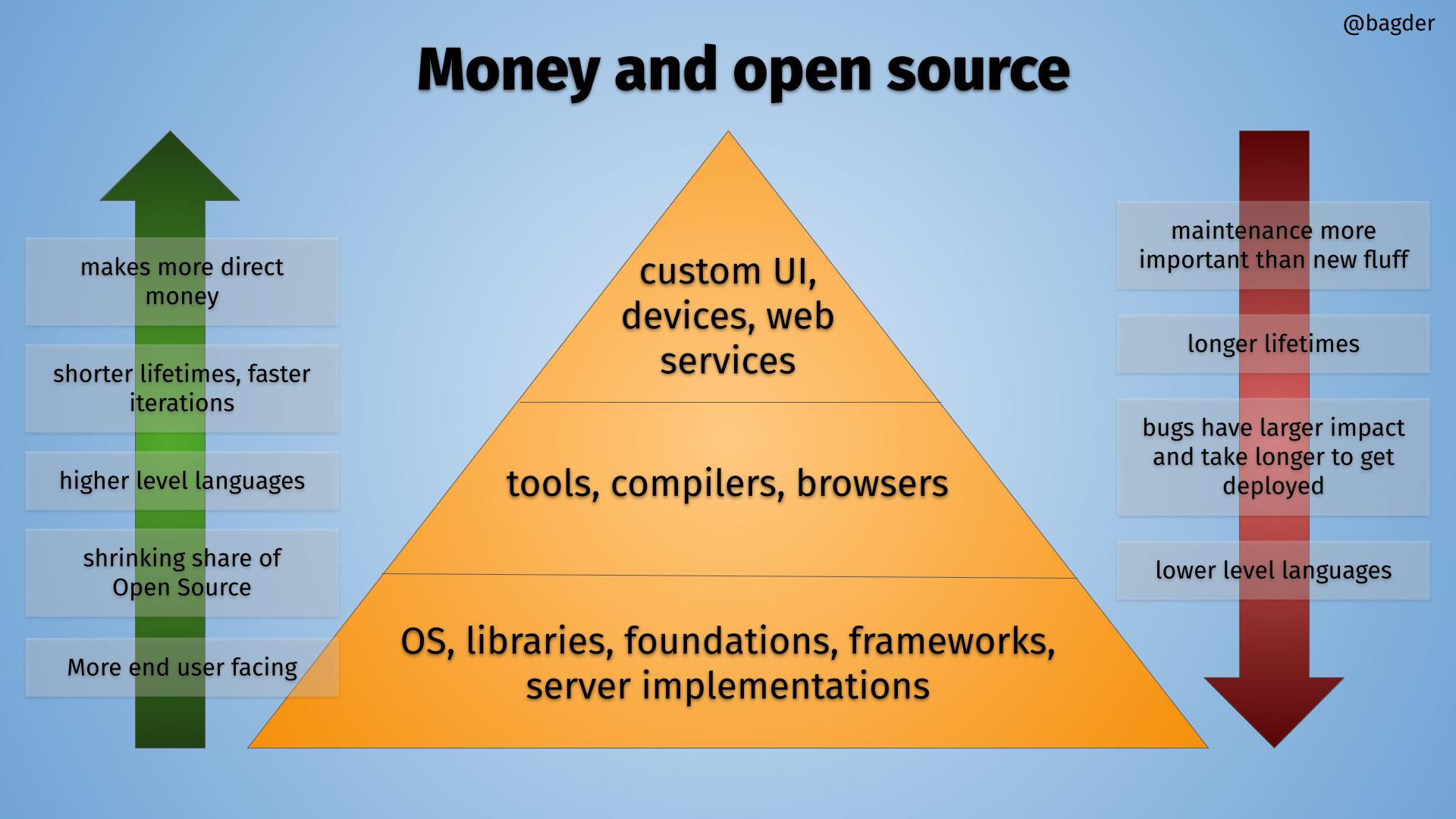
The OSS Pyramid
I think we can view the world of software and open source as a pyramid, and I made this drawing to illustrate.
The OSS pyramid, click for bigger version.
Inside the pyramid there is a hierarchy where things using software are build on top of others, in layers. The higher up you go, the more you stand on the shoulders of open source components below you.
At the very bottom of the pyramid are the foundational components. Operating systems and libraries. The stuff virtually everything runs or depends upon. The components you really don’t want to have serious security vulnerabilities.
Going upwards
In the left green arrow, I describe the trend if you look at software when climbing upwards the pyramid.
Makes more direct money
Shorter lifetimes, faster iterations
Higher level languages
Shrinking share of Open Source
More end user facing
At the top, there are a lot of things that are not Open Source. Proprietary shiny fronts with Open Source machines in the basement.
Going downwards
In the red arrow on the right, I describe the trend if you look at software when going downwards in the pyramid.
Maintenance is more important than new fluff
Longer lifetimes
Bugs have larger impact, fixes take longer to get deployed
Lower level languages
At the bottom, almost everything is Open Source. Each component in the bottom has countless users depending on them.
It is in the bottom of the pyramid each serious bug has a risk of impacting the world in really vast and earth-shattering ways. That is where tightening things up may have the most positive outcomes. (Even if avoiding problems is mostly invisible unsexy work.)
Zoom out to see the greater picture
We can argue about specific details and placements within the pyramid, but I think largely people can agree with the greater picture.
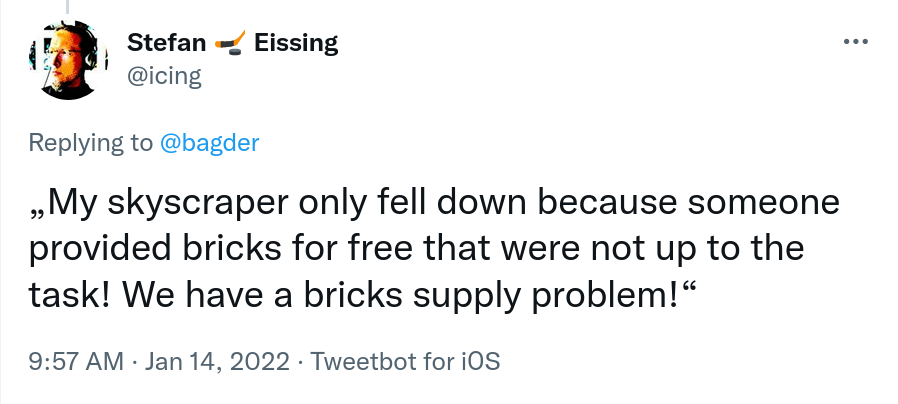
Skyscrapers using free bricks
A little quote from my friend Stefan Eissing:
As a manufacturer of skyscrapers, we decided to use the free bricks made available and then maybe something bad happened with them. Where is the problem in this scenario?
Market economy drives “good enough”
As long as it is possible to earn a lot of money without paying much for the “communal foundation” you stand on, there is very little incentive to invest in or pay for maintenance of something – that also incidentally benefits your competitors. As long as you make (a lot of) money, it is fine if it is “good enough”.
Good enough software components will continue to have the occasional slip-ups (= horrible security flaws) and as long as those mistakes don’t truly hurt the moneymakers in this scenario, this world picture remains hard to change.
However, if those flaws would have a notable negative impact on the mountains of cash in the vaults, then something could change. It would of course require something extraordinary for that to happen.
What can bottom-dwellers do
Our job, as makers of bricks in the very bottom of the pyramid, is to remind the top brass of the importance of a solid foundation.
Our work is to convince a large enough share of software users higher up the stack that are relying on our functionality, that they are better off and can sleep better at night if they buy support and let us help them not fall into any hidden pitfalls going forward. Even if this also in fact indirectly helps their competitors who might rely on the very same components. Having support will at least put them in a better position than the ones who don’t have it, if something bad happens. Perhaps even make them avoid badness completely. Paying for maintenance of your dependencies help reduce the risk for future alarm calls far too early on a weekend morning.
This convincing part is often much easier said than done. It is only human to not anticipate the problem ahead of time and rather react after the fact when the problem already occurred. “We have used this free product for years without problems, why would we pay for it now?”
Software projects with sufficient funding to have engineer time spent on the code should be able to at least make serious software glitches rare. Remember that even the world’s most valuable company managed to ship the most ridiculous security flaw. Security is hard.
All producers of code should make sure dependencies of theirs are of high quality. High quality here, does not only mean that the code as of right now is working, but they should also make sure that the dependencies are run in ways that are likely to continue to produce good output.
This may require that you help out. Add resources. Provide funding. Run infrastructure. Whatever those projects may need to improve – if anything.
The smallest are better off with helping hands
I participate in a few small open source projects outside of curl. Small projects that produce libraries that are used widely. Not as widely as curl perhaps, but still millions and millions of users. Pyramid-bottom projects providing infrastructure for free for the moneymakers in the top. (I’m not naming them here because it doesn’t matter exactly which ones it is. As a reader I’m sure you know of several of this kind of projects.)
This kind of projects don’t have anyone working on the project full-time and everyone participates out of personal interest. All-volunteer projects.
Imagine that a company decides they want to help avoiding “the next log4j flaw” in such a project. How would that be done?
In the slightly larger projects there might be a company involved to pay for support or an individual working on the project that you can hire or contract to do work. (In this aspect, curl would for example count as a “slightly larger” kind.)
In these volunteers-only projects, all the main contributors work somewhere (else) and there is no established project related entity to throw money at to fix issues. In these projects, it is not necessarily easy for a contributor to take on a side project for a month or two – because they are employed to do something else during the days. Day-jobs have a habit of making it difficult to take a few weeks or months off for a side project.
Helping hands would, eh… help
Even the smallest projects tend to appreciate a good bug-fix and getting things from the TODO list worked on and landed. It also doesn’t add too much work load or requirements on the volunteers involved and it doesn’t introduce any money-problems (who would receive it, taxation, reporting, etc).
For projects without any existing way setup or available method to pay for support or contract work, providing man power is for sure a good alternative to help out. In many cases the very best way.
This of course then also moves the this is difficult part to the company that wants the improvement done (the user of it), as then they need to find that engineer with the correct skills and pay them for the allotted time for the job etc.
The entity providing such helping hands to smaller projects could of course also be an organization or something dedicated for this, that is sponsored/funded by several companies.
A general caution though: this creates the weird situation where the people running and maintaining the projects are still unpaid volunteers but people who show up contributing are getting paid to do it. It causes unbalances and might be cause for friction. Be aware. This needs to be done in close cooperating with the maintainers and existing contributors in these projects.
Not the mythical man month
Someone might object and ask what about this notion that adding manpower to a late software project makes it later? Sure, that’s often entirely correct for a project that already is staffed properly and has manpower to do its job. It is not valid for understaffed projects that most of all lack manpower.
Grants are hard for small projects
Doing grants is a popular (and easy from the giver’s perspective) way for some companies and organizations who want to help out. But for these all-volunteer projects, applying for grants and doing occasional short-term jobs is onerous and complicated. Again, the contributors work full-time somewhere, and landing and working short term on a project for a grant is then a very complicated thing to mix into your life. (And many employers actively would forbid employees to do it.)
Should you be able to take time off your job, applying for grants is hard and time consuming work and you might not even get the grant. Estimating time and amount of work to complete the job is super hard. How much do you apply for and how long will it take?
Some grant-givers even assume that you also will contribute so to speak, so the amount of money paid by the grant will not even cover your full-time wage. You are then, in effect, expected to improve the project by paying parts of the job yourself. I’m not saying this is always bad. If you are young, a student or early in your career that might still be perfect. If you are a family provider with a big mortgage, maybe less so.
In Nebraska since 2003
A more chaotic, more illustrative and probably more realistic way to show “the pyramid”, was done by Randall Munroe in his famous xkcd 2347 image, which, when applied onto my image looks like this:
Me shamelessly stealing image parts from xkcd 2347 to further make my point
Generalizing
Of course lots of projects in the bottom make money and are sufficiently staffed and conversely not all projects in the top are proprietary money printing business. This is a simplified image showing trends and the big picture. There will always be exceptions.
Thanks to funding by ISRG (via Google), we merged the hyper powered HTTP back-end into curl earlier this year as an alternative HTTP/1 and HTTP/2 implementation. Previously, there was only one way to do HTTP/1 and 2 in curl.
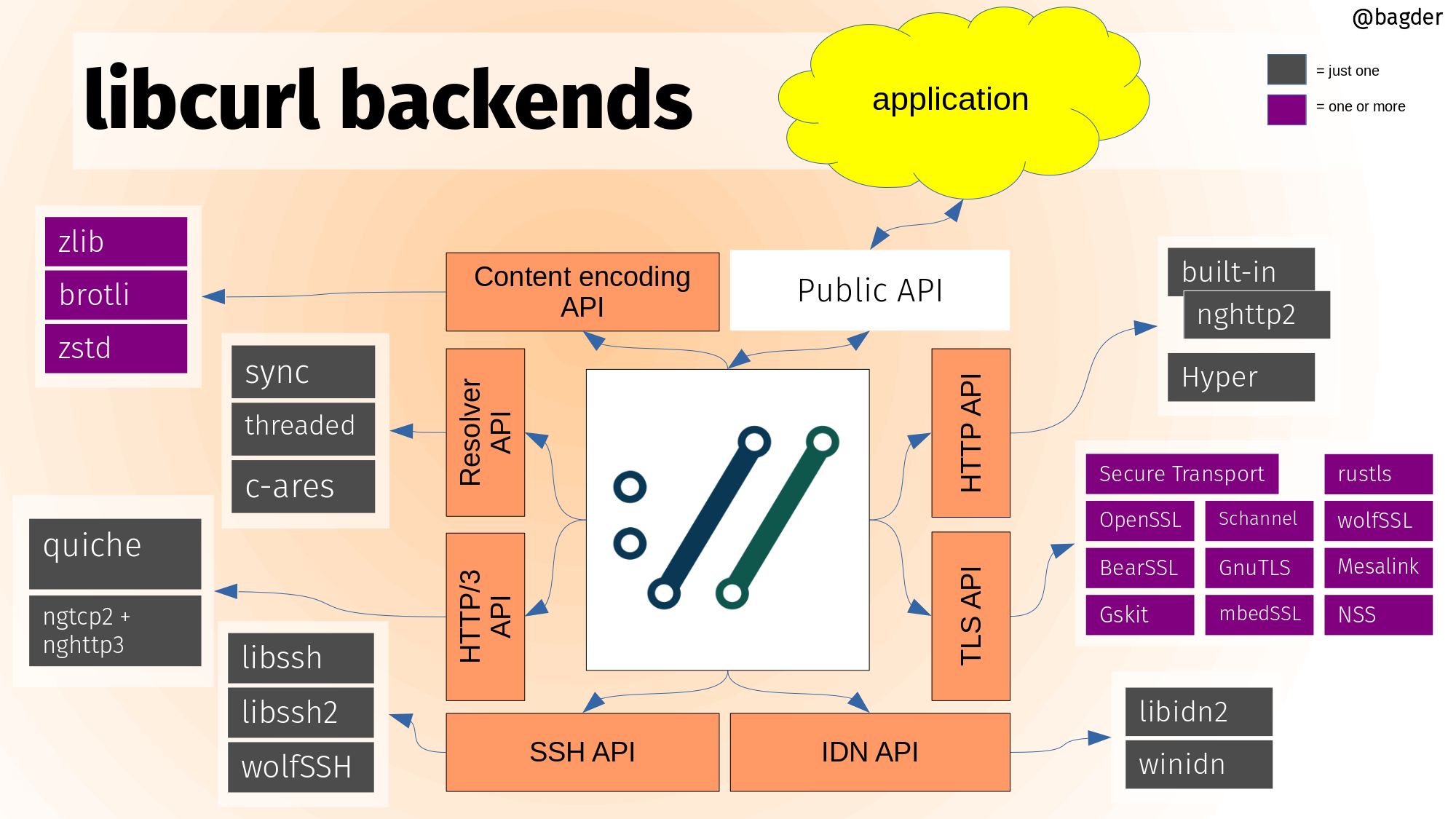
Backends
Core libcurl functionality can be powered by optional and alternative backends in a way that doesn’t change the API or directly affect the application. This is done by featuring internal APIs that can be implemented by independent components. See the illustration below (click for higher resolution).
curl 7.75.0 became the first curl release that could be built with hyper. The support for it was labeled “experimental” as while most of all common and basic use cases were supported, we still couldn’t run the full test suite when built with it and some edge cases even crashed.
We’ve subsequently fixed a few of the worst flaws so the Hyper powered curl has gradually and slowly improved since then.
Going further
Our best friends at ISRG has now once again put up funding and I’ll spend more work hours on making sure that more (preferably all) tests can run with hyper.
I’ve already started. Right now I’m sitting and staring at test case 154 which is doing a HTTP PUT using Digest authentication and an Expect: 100-continue header and this test case currently doesn’t work correctly when built to use Hyper. I’ll report back in a few weeks and let you know how it goes – and then I don’t mean with just test 154!
Consider yourself invited to join the #curl IRC channel and chat if you want live reports or want to help out!
Fund
You too can fund me to do curl work. Get in touch!
On October 25, 2005 I sent out the announcement about “libcurl funding from the Swedish IIS Foundation“. It was the beginning of what would eventually become the curl_multi_socket_action() function and its related API features. The API we provide for event-driven applications. This API is the most suitable one in libcurl if you intend to scale up your client up to and beyond hundreds or thousands of simultaneous transfers.
Thanks to this funding from IIS, I could spend a couple of months working full-time on implementing the ideas I had. They paid me the equivalent of 19,000 USD back then. IIS is the non-profit foundation that runs the .se TLD and they fund projects that help internet and internet usage, in particular in Sweden. IIS usually just call themselves “.se” (dot ess ee) these days.
Event-based programming isn’t generally the easiest approach so most people don’t easily take this route without careful consideration, and also if you want your event-based application to be portable among multiple platforms you also need to use an event-based library that abstracts the underlying function calls. These are all reasons why this remains a niche API in libcurl, used only by a small portion of users. Still, there are users and they seem to be able to use this API fine. A success in my eyes.
Part of that improvement project to make libcurl scale and perform better, was also to introduce HTTP pipelining support. I didn’t quite manage that part with in the scope of that project but the pipelining support in libcurl was born in that period (autumn 2006) but had to be improved several times over the years until it became decently good just a few years ago – and we’re just now (still) fixing more pipelining problems.
On December 10, 2014 there are exactly 3333 days since that initial announcement of mine. I’d like to highlight this occasion by thanking IIS again. Thanks IIS!
Current funding
These days I’m spending a part of my daytime job working on curl with my employer’s blessing and that’s the funding I have – most of my personal time spent is still spare time. I certainly wouldn’t mind seeing others help out, but the best funding is provided as pure man power that can help out and not by trying to buy my time to add your features. Also, I will decline all (friendly) offers to host the web site on your servers since we already have a fairly stable and reliable infrastructure sponsored.
I’m not aware of anyone else that are spending (much) paid work time on curl code, although I’m know there are quite a few who do it every now and then – especially to fix problems that occur in commercial products or services or to add features to such.
IIS still donates money to internet related projects in Sweden but I never applied for any funding from them again. Mostly because it has been hard to sync with my normal life and job situation. If you’re a Swede or just live in Sweden, do consider checking this out for your next internet adventure!







 Part of that improvement project to make libcurl scale and perform better, was also to introduce HTTP pipelining support. I didn’t quite manage that part with in the scope of that project but the pipelining support in libcurl was born in that period (autumn 2006) but had to be improved several times over the years until it became decently good just a few years ago – and we’re just now (still) fixing more pipelining problems.
Part of that improvement project to make libcurl scale and perform better, was also to introduce HTTP pipelining support. I didn’t quite manage that part with in the scope of that project but the pipelining support in libcurl was born in that period (autumn 2006) but had to be improved several times over the years until it became decently good just a few years ago – and we’re just now (still) fixing more pipelining problems.