Why would you use curl in a container? We actually don’t ask, we just provide the image, but I can think of a few reasons…
it is an easy way to use a modern curl version in a system that otherwise ships an ancient version. So many people are stuck on legacy distros with ancient curl versions.
it is an easy way to make use of a consistent fixed version from many places independently of what particular curl versions those systems otherwise can offer
CI jobs
other elaborate explanations
Six billion as of now
The official curl docker repository now (as of 06:43 UTC April 24, 2024) reports that the curl container has been pulled more than six billion times. Currently, people seem to be pulling the curl image from docker.com at a rate of 2-3 million pulls per day (about 25 per second).
It shall be noted that a pull does not necessary imply a download. The pull is a a check and the client may already have the latest version downloaded. It is therefore not equal to six billion downloads.
We started offering docker images to the world with curl 7.65.3, July 19 2019. Six billion pulls in 1832 days makes an average of 38 pulls/second through all this time. Less than five years.
How do I know the pull counter reached six billion? I asked their API:
We do not pay Docker anything for this service of theirs. They also do not pay anything to us for our service. The Docker Sponsored OSS program lists conditions that might make us disqualified for being part of it, but as long as you don’t tell them I won’t. And hey, at least the first six billion pulls have been served.
Other repositories
You can also opt to pull the container from other repositories like quay and GitHub. I have not included their pull counters in this.
Jan Gampe took things to the next level by actually making this cross-stitch out of the pattern I previously posted online. The flowers really gave it an extra level of charm I think.
This quote is from a comment by an upset user on my blog, replying to one of my previous articles about curl.
Fact check: while curl is my hobby, I also work on curl as a full-time job. It is a business and I serve and communicate with many customers on a daily basis. curl provides service to way more than a billion people. I claim that every human being on the planet that is Internet-connected uses devices or services every day that run curl.
The pattern
curl in San Francisco
Meanwhile, another “curl craft” seen in the wild recently is this ad in San Francisco (photo by diego).
hi, Stytch team member here who worked on the PUT request ad from Daniel’s post — feel free to AMA
TL;DR on ‘why pay to put a curl request on an ad’ is what you all have already said — (1) unique concentration of tech in SF; and (2) to specifically engage software engineers. More on each…
(1) We wouldn’t have run this ad in Sydney, or New York, or LA. SF definitely has an uniquely tech-oriented culture, and in particular has lots of startups in our ideal customer persona (ICP) at Stytch – in this case, engineers building B2B SaaS apps.
But in addition to the people who live in SF, even more software engineers visit the city for conferences, or events, or to fundraise. For example, while our ads are up over the next month, SF will host Stripe Sessions and POSTCon (two entire conferences focused around APIs), plus RSA (security focused).
(2) And although even with that, only a small segment of the pop will understand the ads, those people might be intrigued enough to actually look at them – and our ultimate goal is to get more engineers to look at our code & our docs. Another perk is that engineers can’t use ad blockers if the ad is on a bus shelter 🙂
So that was a bit of the thinking for us – on why SF & why a PUT request on a billboard. We’re also making the physical ads into an anchor for a ‘marketing moment’ for Stytch — so pair offline ads with digital marketing, as well. So if we’re successful, maybe you’ll see more on that, soon.
Here follows a brief description on how you can detect if the curl package would ever make an xz.
xz (and its library liblzma) was presumably selected as a target because it is an often used component and by extension via systemd it often used by openssh in several Linux distros. libcurl is probably an even more widely used software component and if infected, could potentially serve as an effective vessel to distribute evil into the world.
Conceivably, the xz attackers have infiltrated more than one other Open Source project to cover their bases. Which ones?
No inexplicable binary blobs
First, you can verify that there are no binary blobs stored in git that could host an encrypted attack payload, planted there for the future.
Every file in the curl git repository has a benign meaning and purpose. As part of the products, the documentation, tooling or the test suites etc.
Without any secret “hide-out” in the git repository, you know that any backdoor needs to be provided either in plain code or using some crazy weird steganography. Or get inserted into the tarballs with content not present in git – read on for how to verify that this is not happening.
No disabled fuzzers
The xz attack could have been detected by proper fuzzing (and valgrind use) which is why the attacker made sure to sneakily disable such automated checks of code.
While somewhat hard to verify, you can make sure that no such activities have been done in curl’s fuzzing or curl’s automated and CI testing,
No hidden payloads in tarballs
In the curl project we generate several files as part of the release process and those files end up in the release tarball. This means that not all files in the tarball are found in the git repository. (Because we don’t commit generated files.)
The generated files are produced with a small set of tools, and these tools use the source code available in git at the release tag. Anyone can check out the same code from that same release tag, make sure to have the corresponding tools (and versions) installed and then generate a version of the tarball themselves – to verify that this tarball indeed becomes an identical copy of the public release.
That process verifies that the tarballs we ship are generated only with legitimate tools and that the release contents originate only from the files present in git. No secret sauce added in the process. No malicious code can get inserted.
Reproducible tarballs
We have recently improved reproducibility as a direct result of the post xz-attack debate. To make sure that a repeated tarball creation actually produces the exact same results, but also to make it easier for others to verify our release tarballs. With more documentation (releases now contain documentation of exactly which tools and versions that generated the tarball) and by making it easier to run the exact same virtual machine and tool setup like the one that created the release. We aim to soon provide a Dockerfile to make this process even smoother.
We also verify tarball reproducibility in a CI job: generating a release tarball with a given timestamp produces the identical binary output when done again for the same timestamp.
Signed tarballs
As an extra detail, everyone can also verify that the released tarballs are in fact shipped by me Daniel personally, as they are always signed with my GPG key as part of the release process. This should at least prove that new releases are made with the same keys as previous ones were, which should with a reasonable probability be me.
The signatures also help verify that the tarballs have not been tampered with in transition, from the point I generated them to the moment they land in your download directory. curl downloads are normally distributed via a third-party CDN which we normally trust of course, but if it would ever be breached or similar, a modified tarball would be detected when the digital signature is verified.
We do not provide checksums for the tarballs simply because providing checksums next to the downloads adds almost no extra verification. If someone can tamper with the tarballs, they can probably update the webpage with a fake checksum as well.
Signed commits
All commits done to curl done by me are signed, You can verify that I did them. Not all committers in the project do them signed, unfortunately. We hope to increase the share going forward. Over the last 365 days, 73% of the curl commits were signed.
These signatures only verify that the commits where done by a maintainer of the curl project (or someone who controls that account). A maintainer you may not trust and who might not be known under their real name and you do not even know in which country they live. And of course, even a trusted maintainer can suddenly go rogue.
Is the content in git benign?
The process above only verifies that tarballs are indeed generated (only) from contents present in git and that they are unaltered from the moment I made them.
How do you know that the contents in git does not contain any backdoors or other vulnerabilities?
Without trusting anyone else’s opinions and without just relying on the fact that you can run the test suite, fuzzers and static code analyzers without finding anything, you can review it. Or pay someone else to review it.
We have had curl audited several times by external organizations, but can you trust claimed random audits?
Anonymous contributors
We regularly accept contributions from anonymous and pseudonymous contributors in curl – and we always have. Our policy says that if a contribution is good: if it passes review and all tests run green, we have no reason to deny it – in the name of progress and improvement. That is also why we accept even single-letter typo fixes: even a very small fix is a step in the right direction.
A (to me) surprisingly large amount of contributions are done by people who do not state a full real name. They may chose to be anonymous for various reasons – we do not ask. Maybe they fear retaliation if they would propose something that ends up buggy? Sometimes people want to hide their affiliation/origin so that their contribution is not associated with the organization they work at. Another reason sometimes mentioned is that women do it to avoid revealing themselves as female. etc. As I said: we do not ask so I cannot tell for sure.
Anonymous maintainers
We do not have anonymous maintainers, but we don’t actually have rules against it.
Right now, we have 18 members in the GitHub curl organization with the rights to push commits. I have not met all of them. I have not even seen the faces of all of them. They have all proven themselves worthy of their administrative rights based on their track record. I cannot know if anyone of them is using a false identity and I do not ask nor keep track in which country they reside. A former top maintainer in the curl projected even landed a large amount of changes under a presumed/false name during several years.
If a curl maintainer suddenly goes rogue and attempts to land malicious content, our only effective remedy is review. To rely on the curl community to have eyes on the changes and to test things.
Can curl be targeted?
I think it would be very hard but I can of course not rule it out. Possibly I am also blind for our weaknesses because I have lived with them for so long.
Everyone can help the greater ecosystem by verifying a package or two. If we all tighten all screws just a little bit more, things will get better.
Vulnerabilities
I maintain that planting a backdoor in curl code is so infuriatingly hard to achieve that efforts and energy are probably much rather spent on finding security vulnerabilities and ways to exploit them. After all, we have 155 published past vulnerabilities in curl so far, out of which 42 have been at severity high or critical.
I can be fairly sure that none of those 42 somewhat serious issues were deliberately planted, because just about every one of them were found in code that I personally authored…
People often ask. But I have never seen a backdoor attempt in curl. Maybe that is just me being naive.
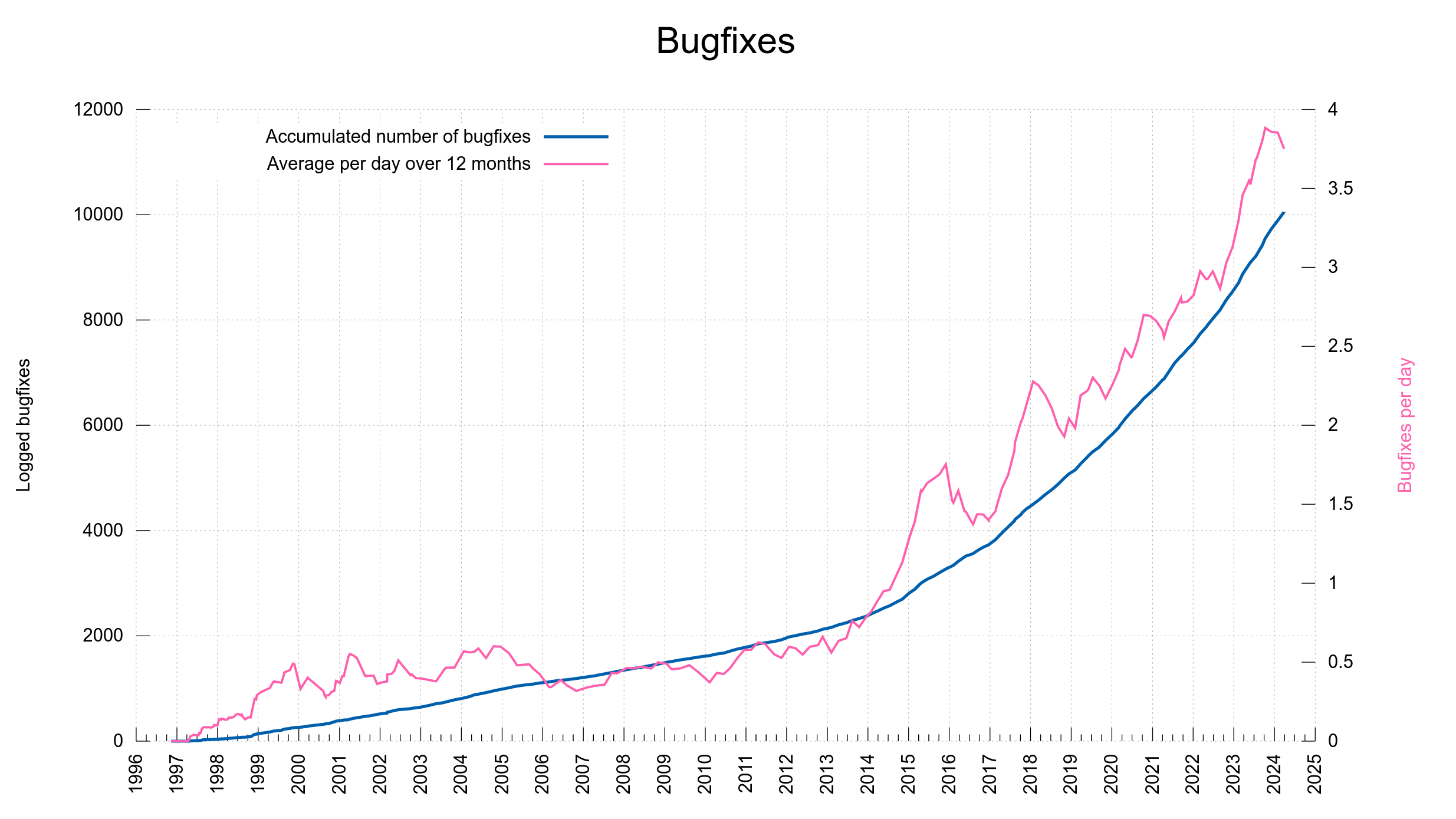
We keep track of bugfixes done to curl. All bugfixes ever done. A while back I also went back and populated the lists with details from all the releases to the pre-cursors of curl: httpget and urlget. All and every change made since November 1996.
The rate of bugfixes has been increasing over the years. I think in terms of actual bugs being squashed and fixes being merged, but also partly because we have gotten much better at keeping meticulous logs and do better release notes.
A bugfix can be a single letter typo fix in a document, a spell-fix in a source code comment or it can fix a serious security vulnerability. From high to low, from important to a small subtle detail. The counter does not value, it is just a counter.
When we shipped the recent curl version, 8.6.0, the counter said 9,888 shipped bugfixes. The other day, when 8.7.0 and 8.7.1 shipped, the counter was upped to surpass 10,000 and now says: 10,051.
These bugfixes happened thanks to 3,134 contributors, out of which 1,252 persons have authored commits merged into the curl source repository.
This journey started with httpget. The first ever release of httpget 0.1 that was made public happened on November 11 1996. Today, that is exactly 10,000 days ago.
We only have git commits stored from late 1999, but that counter is almost at 32,000 now. Making a little less than every third commit ever done a logged bugfix.
Number of bugfixes and bugfix rate over time in the curl project.
How I do the release notes
This is highly scripted task.
It starts with: every commit of the RELEASE-NOTES file in git that makes it up-to-date needs to use the single word “synced” as commit message. The commit that syncs it.
Further, I have an alias in my ~/.gitconfig file that says:
[alias]
latest = log @^{/RELEASE-NOTES:.synced}..
This allows me to invoke git latest to get a list of the latest changes done in the repository since I most recently synced the RELEASE-NOTES.
Sync
When that list starts to grow, typically roughly every four to ten days something, I invoke the release-notes.pl script we have in the curl git repository. This scripts gets all the changes since the most previous sync and inserts them into the RELEASE-NOTES file, complete with a correct reference to the associated GitHub issue or pull-request.
The actual bullet point text it inserts comes from the first line of the corresponding commit message. The links comes from parsing commit messages and finding keywords and links according to how the project dictates how they should be used. This is one reason why it is important to do good commit messages following the correct style in the project. It makes the release notes job easier and the results better.
The script does not know what’s a change, what’s a bugfix or what’s not even worthy of mentioning. It just adds all changes to top the list of changes (and includes a convenient separator so that it is easy to spot the newly added ones) and the next step for me is then to manually go over the list and delete the ones that aren’t intended to be mentioned there and move the few changes into the correct section of the release notes.
I run release-notes.pl cleanup which then sorts the lists alphabetically and removes dangling references (which are leftovers from the lines I removed).
Contributors
We keep track, try to say thanks to and give credit to every contributor that helps out in the project. No matter the size of the contribution. When someone has reported a bug. the reporter is credited in the commit message of the bugfix. We also give credit to co-authors and people assisting in solving the issues etc. To make sure we mention and give credit to the contributors and keep track of them beyond what git itself does.
We can also add names manually to the release notes file, like if we had forgotten to mention them in a commit message. Then I run the contributors.sh script. It reads the list of names currently in the RELEASE-NOTES and then scans all the git changes since the previous sync and generates an updated list of all git authors, committers and everyone else who are credited, and it outputs an updated list (and contributor counter). That updated list is then pasted into RELEASE-NOTES.
In recent years, in a normal eight week release cycle, we typically feature 60 to 80 named contributors in this file. Of course, top contributors in the project tend to get mentioned in just about every release notes file, as they just have to help out and contribute once every 56 days to appear there.
On release days, we update the docs/THANKS file (using the contrithanks.sh script) where all contributors who ever helped out are mentioned and saved for the future. That list of people is also made visible on the thanks page on the curl website.
Counters
At the top of the release notes we have a few counters displayed. It looks similar to:
Public curl releases: 255
Command line options: 258
curl_easy_setopt() options: 304
Public functions in libcurl: 93
Contributors: 3119
After the list of contributors have been pasted into the current release notes, I invoke the delta script, which shows a lot of curl git repository statistics since the most previous release tag. That input includes the numbers shown in the release notes top, so if they are different now I update the release notes accordingly with the updated data. Most frequently, the contributor counter has been bumped.
Commit
included the lists of bugfixes and changes
updated contributors
updated the counters
The RELEASE-NOTES file is then committed to git using “synced” as commit message. Until it is time to sync it again.
Because of this work, we can offer the pending release notes on the website, as it is the work in progress file with the changes we have already logged that is targeted to be included in the next release.
Release
Of course, on release days I make sure to do a final update so that all the last changes get into the file before release as then the file ends up in the release tarball, that is locked, signed and stored the archives.
After a release, I just manually erase the lists from the file and clear the list of names and commit. Then we start rebuilding it again with new stuff in the new release cycle.
the 255th and 256th releases 5 changes 56 days (total: 9,504) 162 bug-fixes (total: 10,050) 246 commits (total: 31,931) 0 new public libcurl function (total: 93) 0 new curl_easy_setopt() option (total: 304) 0 new curl command line option (total: 258) 92 contributors, 56 new (total: 3,133) 37 authors, 15 new (total: 1,252) 4 security fixes (total: 155)
Versions
I first released 8.7.0, but immediately someone pointed out that one of the files in the tarballs was broken, so I fixed the issue, created a new set of tarballs, bumped the version and uploaded the new set. The new release is 8.7.1 but of course it has the same set of changes. We just pretend we did not upload 8.7.0.
Release presentation
Security
CVE-2024-2004: Usage of disabled protocol. (low) When a protocol selection parameter option disables all protocols without adding any then the default set of protocols would remain in the allowed set due to an error in the logic for removing protocols.
CVE-2024-2398: HTTP/2 push headers memory-leak. (medium) When an application tells libcurl it wants to allow HTTP/2 server push, and the amount of received headers for the push surpasses the maximum allowed limit (1000), libcurl aborts the server push. When aborting, libcurl inadvertently does not free all the previously allocated headers and instead leaks the memory.
CVE-2024-2379: QUIC certificate check bypass with wolfSSL. (low) libcurl skips the certificate verification for a QUIC connection under certain conditions, when built to use wolfSSL. If told to use an unknown/bad cipher or curve, the error path accidentally skips the verification and returns OK, thus ignoring any certificate problems.
CVE-2024-2466: TLS certificate check bypass with mbedTLS. (medium) libcurl did not check the server certificate of TLS connections done to a host specified as an IP address, when built to use mbedTLS.
Changes
configure: add –disable-docs flag. This skips the step generating the manpages, which for many people is unnecessary.
CURLINFO_USED_PROXY: return bool whether the proxy was used. Useful when having a filter that only lets some transfers use the proxy.
write-out: add ‘%{proxy_used}’. The same as above but for the tool.
digest: support SHA-512/256. Support more modern digest authentication.
DoH: add trace configuration. Now you get more DoH tracing/logging using the general trace mechanism.
Bugfixes
Some of the bugfixes from this cycle that might be worth noticing:
configure: find libpsl with pkg-config. Makes configure better at finding libpsl and making use of the correct flags and sub-dependencies when linking with it.
configure: find rustls with pkg-config. Similar adjustment but for rustls.
cookie: if psl fails, reject the cookie. A run-time failure should not allow the cookie through.
curl: exit on config file parser errors. We can insist on the config file to be correct as otherwise something unintended might go through.
curl: make –libcurl output better CURLOPT_*SSLVERSION. This option takes a bitmask made out of two separate enum ranges.
file: use xfer buf for file:// transfers. The main effect being that it can use a larger buffer which can make faster transfers.
http: better error message for HTTP/1.x response without status line
https-proxy: use IP address and cert with ip in alt names. Connecting to a HTTPS proxy using an IP address with a URL also using an IP address and those addresses were different versions, curl would get it wrong.
mprintf: fix format prefix I32/I64 for windows compilers
OpenSSL QUIC: adapt to v3.3.x. Pending improvements in OpenSSL is going to enhance curl’s ability to do HTTP/3 using it.
paramhlp: fix CRLF-stripping files with “-d @file”. curl would do wrong for line ending consisting of CR only
rustls: make curl compile with 0.12.0. Adjusted to use the modified APIs.
schannel: fix hang on unexpected server close
sendf: ignore response body to HEAD. A regression made curl complain if a HEAD request would get body data.
smtp: fix STARTTLS. Another regression fixed.
strtoofft: fix the overflow check. The previous overflow check was relying on undefined behavior. This is in code only for platforms without a proper native parser for 64 bit sized numbers.
TLS: start shutdown only when peer did not already close.
curl: only parse etag + content-disposition for 2xx.
curl: accept a blank -w “”
curl: handle non-existing (out of range) short-options
curl: change precedence of server Retry-After time
curl: shorter –help texts. With some polish to make the output look nicer, in particular “curl –help all”.
transfer.c: break receive loop in speed limited transfers, To make libcurl adapt more precisely to the network speed limit set by the application.
On March 21 2024 we had a curl distro meeting where people from at least ten different distros and curl project members had a video meeting and talked curl and distro related topics for a while.
Here is my summary of what we talked about and concluded.
Attendees
We had about 25 persons attending. At least the following organizations had representation:
curl
Debian
Mageia
RHEL/Fedora
Windows 10/11
MacPorts
Homebrew
Yocto Project
AlmaLinux
Arch Linux
Rocky Linux
There were also a few interested people present without any particular association.
Agenda
Daniel went through a few slides and talked about vulnerabilities, curl features, testing, issues, long term support etc.
PSL
Be aware: you most probably want PSL support enabled in your curl build if your users ever use cookies.
HTTP/3
We had a discussion around the problems for distros to enable HTTP/3 because of the TLS situation. One way to somewhat untangle the situation would be to support using a different TLS library for QUIC than for everything else, but that is also a lot of work and probably brings its own set of unique problems as well.
curl’s support for OpenSSL’s QUIC (together with nghttp3) and OpenSSL’s upcoming improvements in that area (coming in OpenSSL 3.3) are for many users perhaps the most viable route to HTTP/3.
Tests
Distros seem to mostly run the curl test suite to verify that curl works for them – on each platform that they ship on. It was also noted that some distros’ habit of also running tests on all dependencies help them to catch things.
curl has introduced parallel tests the last few years and we encourage distros to try that out to possibly speed up the tests substantially.
Maintaining old curl versions
(the curl project does not maintain old versions/branches, it only releases new releases off the master branch)
Distributions have long-lived branches with curl versions they stick to for years. We spent a long time brain-storming around what can be done to improve the situation for everyone and to make things easier and more streamlined for distros to do this. A problem is that distros tend to have different priorities, schedules and selection criteria, which make them end up selecting different curl versions to stick to.
Therefore, at any given time, there is a large amount of old curl versions that get security fixes and serious bugfixes bugreported by distros.
That is also a reason for why introducing some sort of long term branch support in the curl project itself might not help much. Since that branch/version might not actually suit very many distros and trying to get everyone to agree on a specific one would be challenging.
But still: a backported fix to curl version N might be easy enough to also make work for version N-1 rather than starting from the beginning with the patch that was done against the latest release. Coordination and awareness around what patches have been made could help everyone.
We discussed the possibility of hosting back-ported (security) patches in repositories managed by upstream to make it easier for distros to share such efforts. To be discussed further on the mailing list. Could be worth trying to see if we can make it work in productive way.
Learning about issues
We also identified that an area for improvements is cross-distro communication when it comes to learning about issues against various curl versions. When a user submits an issue against curl version Y on distro X, sometimes distro Z has already fixed it. Perhaps with backport.
Regressions on latest release
A special kind of issues are regressions on the latest curl version. Sometimes such fixes are done upstream but the distros don’t necessarily notice if they do not trigger a dot release. When the change is small enough to upstream to not be worthy of patch release, but the distro considers it patch worthy.
Communication
Several of the topics touched how things could be improved by better communications between curl and distros and cross-distros about their curl work and related issues.
We are setting up this new mailing list: curl-distros with the sole purpose of facilitating information exchange curl <=> distros and distro <=> distro in curl related questions. Patches, bugfixes, challenges, anything.
The curl project creates a DISTROS document in the curl git repository that contains pointers to the curl home, curl pataches and curl issues for all distros that we can find information about.
We have a mailing list created now for increased communication, but we discussed perhaps doing this kind of meeting again on an annual schedule.
Maybe do some kind of meetup in association with FOSDEM? We will sync that on the mailing list for sure.
Thanks!
Thanks a lot to everyone who participated! I felt that we got quite a lot of value out of this and I hope this was the beginning of more communication and improved collaboration going forward. For the benefit for curl users.
It feels like it was not very long ago that we had the big curl 25 year celebrations. I still have plenty of fluid left in my 25 year old whiskey from last year and I believe I will treat myself a drink from that tonight.
I have worked on curl full-time and spare time for another year. We have taken this old thing further forward, we refurbished lots of internals over the last year while we also added a bunch of improvements. To make sure curl stays fit and remains a rock solid Internet transfer foundation for many more years.
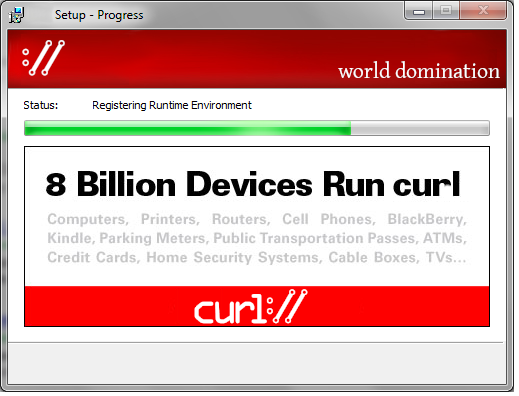
The other day I created an image in jest based on an old Java installer screenshot.
The image says 8 billion but it might just as well be 10 or 14, we just don’t know and can’t tell. I made image say 8 simply because it was easy to modify the original image into an 8 from the original 3.
I often repeat the number twenty billion installations for curl, but several of those installations are typically running in the same device. Like how most mobile phones include two to ten separate curl installations – because many apps bundle their own installations in addition to the one the OS itself uses.
And I don’t know that there are twenty billion either. Maybe there are just eighteen. Or forty.
I am doing another webinar on March 28 2024, introducing newcomers to how to Internet transfers using the libcurl API.
Starting at 10am Pacific time. 17:00 UTC. 18:00 CET.
Agenda
libcurl basics
synchronous transfers
getting transfer information
concurrent transfers
URL parser
Q&A
The plan is to spend about 30 minutes going through the topics in the agenda and then take as long as necessary to let the attendees ask all and every question you may have about curl, the libcurl API and Internet transfers.
I have run this webinar before. The setup will be similar but not identical to previous runs. I believe attending the webinar is way better than watching a video recording of it in particular because you get the opportunity to interact and ask questions. Whatever detail you think is unclear or you would like to know more about, I can tell you all about it.
Using the libcurl API is not complicated, but it is a powerful machine and not everything is immediately obvious or straight forward.
See you on March 28.
(The event will be recorded and made available after the fact, and so will the slides.)
On December 28 2023, bugreport 12604 was filed in the curl issue tracker. We get a lot issues filed most days so this fact alone was hardly anything out of the ordinary. We read the reports, investigate, ask follow-up questions to see what we can learn and what we need to address.
The friendly reporter showed how the curl version bundled with macOS behaves differently than curl binaries built entirely from open source. Even when running the same curl version on the same macOS machine.
The curl command line option --cacert provides a way for the user to say to curl that this is the exact set of CA certificates to trust when doing the following transfer. If the TLS server cannot provide a certificate that can be verified with that set of certificates, it should fail and return error.
This particular behavior and functionality in curl has been established since many years (this option was added to curl in December 2000) and of course is provided to allow users to know that it communicates with a known and trusted server. A pretty fundamental part of what TLS does really.
When this command line option is used with curl on macOS, the version shipped by Apple, it seems to fall back and checks the system CA store in case the provided set of CA certs fail the verification. A secondary check that was not asked for, is not documented and plain frankly comes completely by surprise. Therefore, when a user runs the check with a trimmed and dedicated CA cert file, it will not fail if the system CA store contains a cert that can verify the server!
This is a security problem because now suddenly certificate checks pass that should not pass.
I reported this as a security problem in an email sent to Product Security at Apple on December 29 2023, 08:30 UTC. It’s not a major problem, but it is an issue.
Apple’s says it is fine
On March 8, 2024 Apple Product Security responded with their wisdom:
Hello,
Thank you again for reporting this to us and allowing us time to investigate.
Apple’s version of OpenSSL (LibreSSL) intentionally uses the built-in system trust store as a default source of trust. Because the server certificate can be validated successfully using the built-in system trust store, we don't consider this something that needs to be addressed in our platforms.
Best regards,
KC
Apple Product Security
Case closed.
I disagree
Obviously I think differently. This undocumented feature makes CA cert verification with curl on macOS totally unreliable and inconsistent with documentation. It tricks users.
Be aware.
Since this is not a security vulnerability in the curl version we ship, we have not issued a CVE or anything for this problem. The problem is strictly speaking not even in curl code. It comes with the version of LibreSSL that Apple ships and builds curl to use on their platforms.
The project was still early back then and lots of things had not settled yet. In that release, which came only two weeks after 5.1, we introduced the --manual option, or -M for short.
Long before I started working on curl I learnt to value and appreciate Unix manpages. I more or less learned C programming using them, and I certainly learned my first ways around Unix shells and command lines reading manpages. My first Unix I spent a lot of time on was AIX. It was in the early 1990s, several years before I first used Linux.
Since some systems don’t have the fine concept of manpages, I decided I would help those users by bundling the curl man page into the tool itself. You can ask curl to show the curl manpage, with the -M option. The entire thing, looking very similar – mostly just lacking font details such as bold, italics and underline.
How do you bundle a manpage?
I suppose there are many ways to go about to make such a thing happen. In our case, we were already making and shipping a manpage in the nroff manpage format so it became a question of generating a text version using that page as a source and then convert the text version into C source code.
Converting a manpage to text was done with nroff. nroff is an ancient Unix tool that has been around for a long time and it existed on virtually every Unix flavor already back then. It seemed like a no-brainer to go with that, so that is what the curl build system would use.
Once the build scripts were tweaked it continued to just work. It became problematic only on platforms that lacked nroff – but to help smooth over that obstacle we also shipped the generated source file in distribution tarballs.
nroff really?
nroff is quirky tool. It generates the output differently based on environment details and over the years it would also subtly change its output several times that forced us to adjust the scripts as well.
Still, for as long as the curl manpage was primarily written in nroff format, it was challenging to generate the ASCII version any other way. We stuck with nroff.
Even after that switch we still generated the built-in manual with nroff from the curl.1 manpage, that then was created entirely from a large set of source files written in markdown. The manpage was generated by our own custom tool.
The time was ripe
With firm control of the input file format and generating the output entirely with our own tool, it became a viable (and attractive) option to tweak the tool to offer an alternative output format. Allow it to render the output either as a manpage formatted file, or as an ASCII text file. Without involving or using nroff.
The time had come. We had suffered long enough. It was time to address this friction in the build system.
Yesterday, I merged the pull-request that finally, after 25 years, 2 months, 21 days removed the use of nroff from the curl build scripts.
The curl -M output after this change is not 100% identical, but it is close enough and looks very good and similar in style as before. I did not actually even try to make it a complete clone. In fact, when we generate the output directly from markdown instead of going via the manpage, we can actually make it a better text-only version than we could before.
I opted to still use a justified right margin of the text, because that is what it always used and after some casual initial comparisons I think it looked better than without an aligned right column.
nroff does hyphenation of words, which helps somewhat to make justified text easier and nicer, and our own script does not – at least not until I have figured out a decent way to do it. Like if the word “variable” is the last word on a line, it could be written as “vari-” on the end of the line and “able” could start the next line. I believe doing it badly is worse than not doing it at all.
Building this is easier
It is now (much) easier to build this from source, even on esoteric platforms like Windows.
I don’t think a single person will miss the old way of doing this.