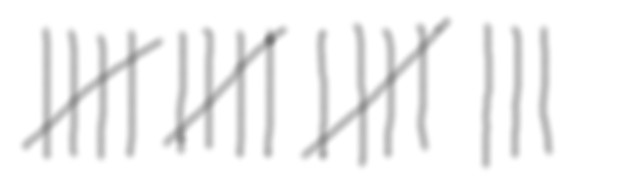On Monday August 7, 2000 at 14:49 UTC, we announced the release of the first libcurl version ever. Exactly twenty-four years ago today. We called it version 7.1. The simple reason we did a point one release as the first one was that we had shipped a whole range of 7.0 beta versions before that day and I wanted to make it clear to everyone that this was a bump up from those. To avoid confusions.
The last release we did before libcurl was born was called 6.5.2, which we did 139 days before 7.1 was uploaded (in March 2000). The longest release interval in the entire history of curl. Never before or after, have we spent that long time to prepare a single new curl release.
Howdy
I just put the curl 7.1 tarball on the curl site. It’ll take a while more for it to appear on the mirrors and for our friends to send in binary archives or report where there are updated archives for various platforms.
The original announcement. Not many frills there.
Contributors
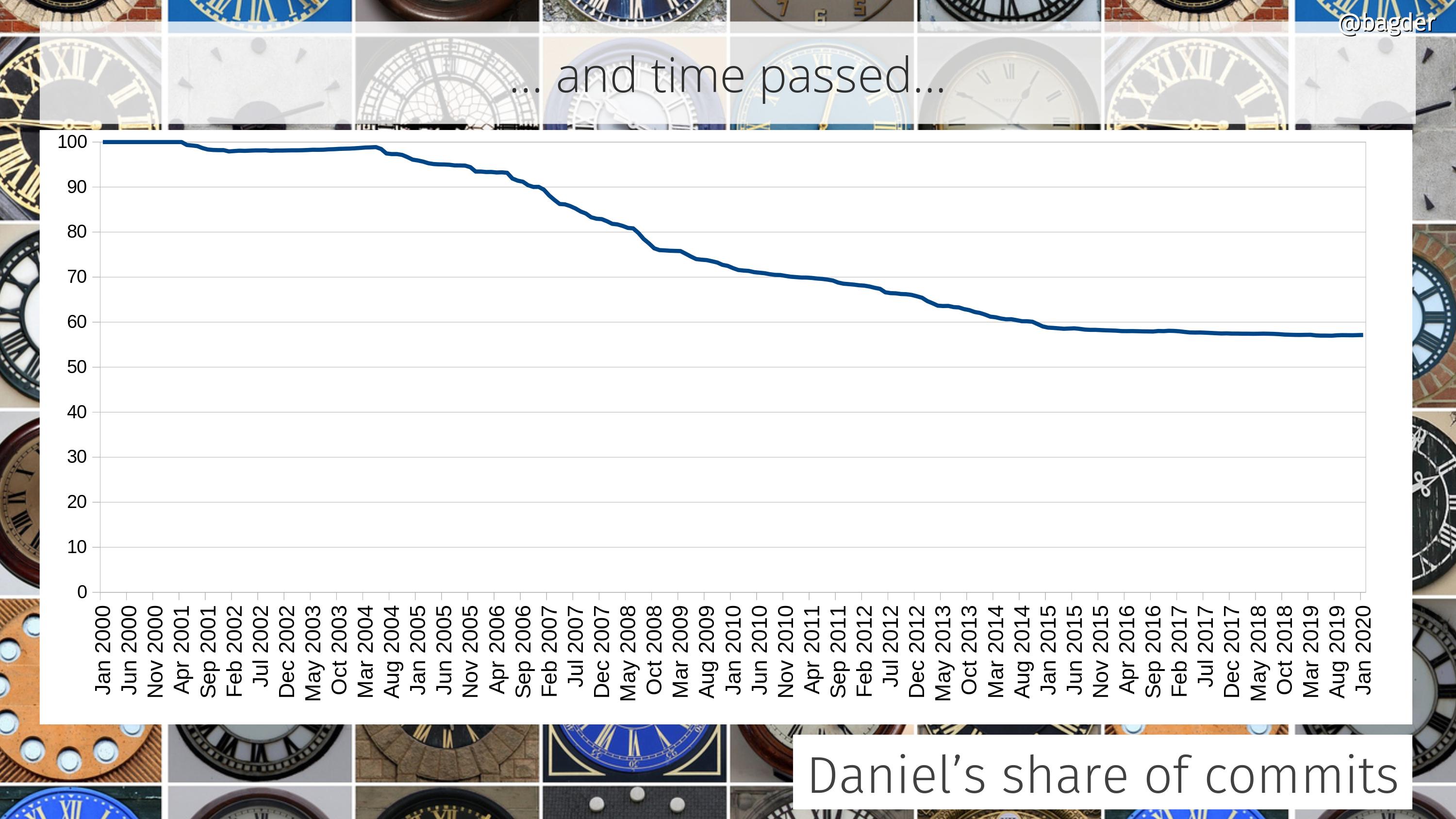
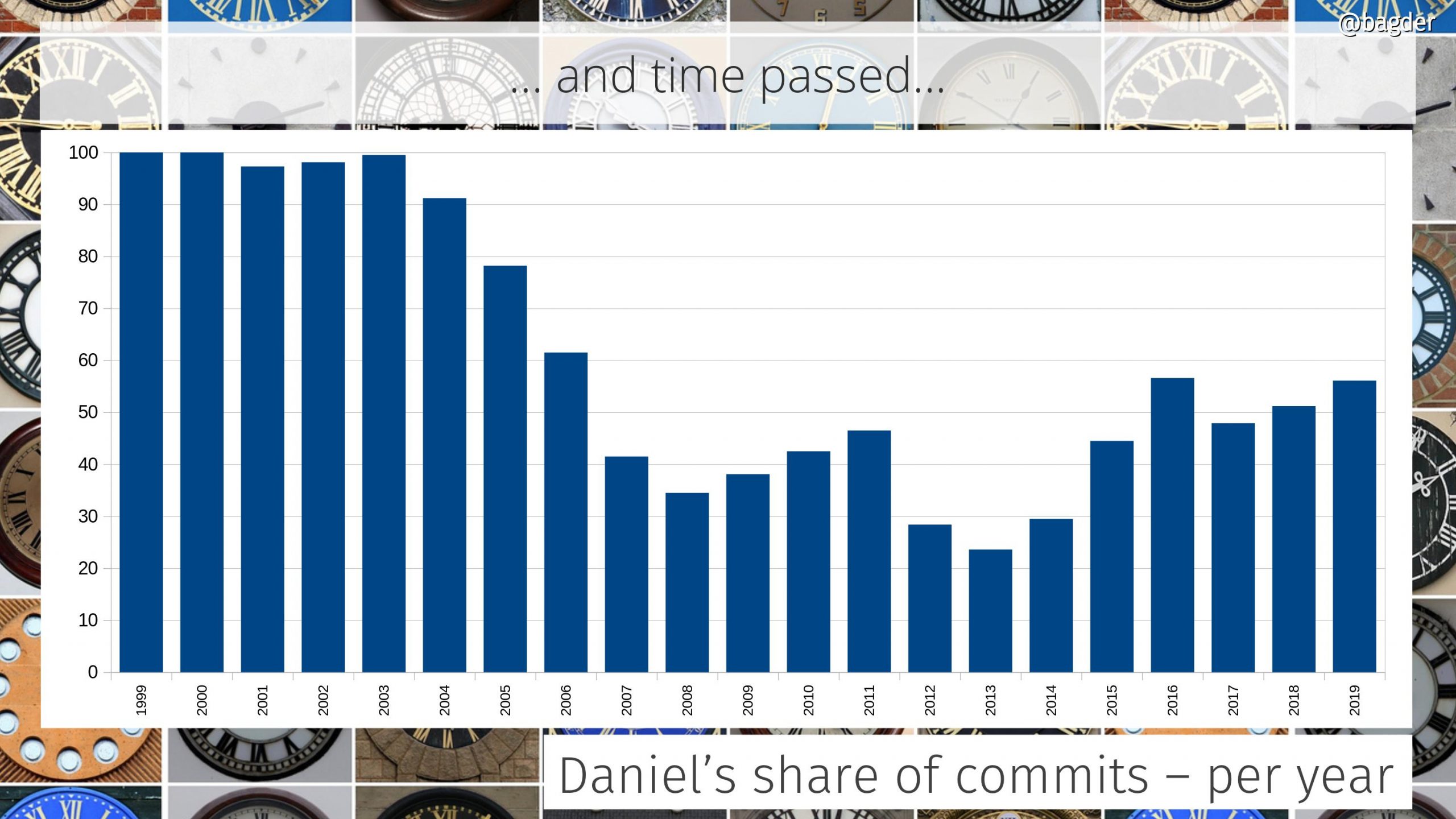
Most of the work that went into the creation of libcurl was done by me alone. While we already had contributors and lots of people helping out with bug reports and features, this kind of heavy lifting and huge refactor was not really a team effort. I spent the summer splitting the monolithic command line tool into two components: a library and a command line tool that uses the library.
Since the last days of 1999 the curl source code was hosted on Sourceforge using CVS so at least all this was done in a public source code repository with version control.
Why libcurl
I had already years before this time understood the powers of using shared libraries and how they are good ways to offer features and functionality to applications. I got an article published in a technical Amiga magazine in the early 1990s about how to do shared libraries on AmigaOS.
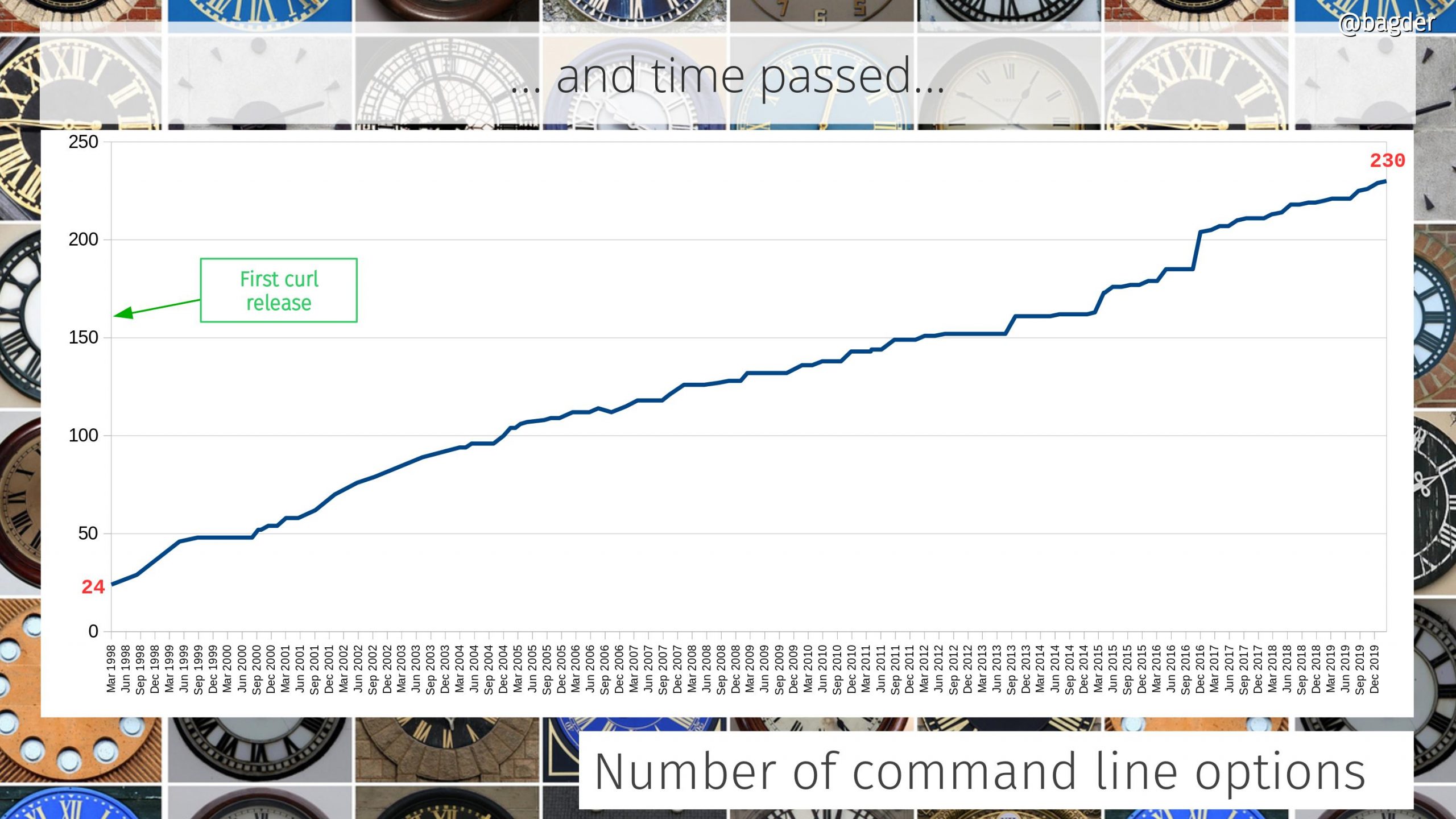
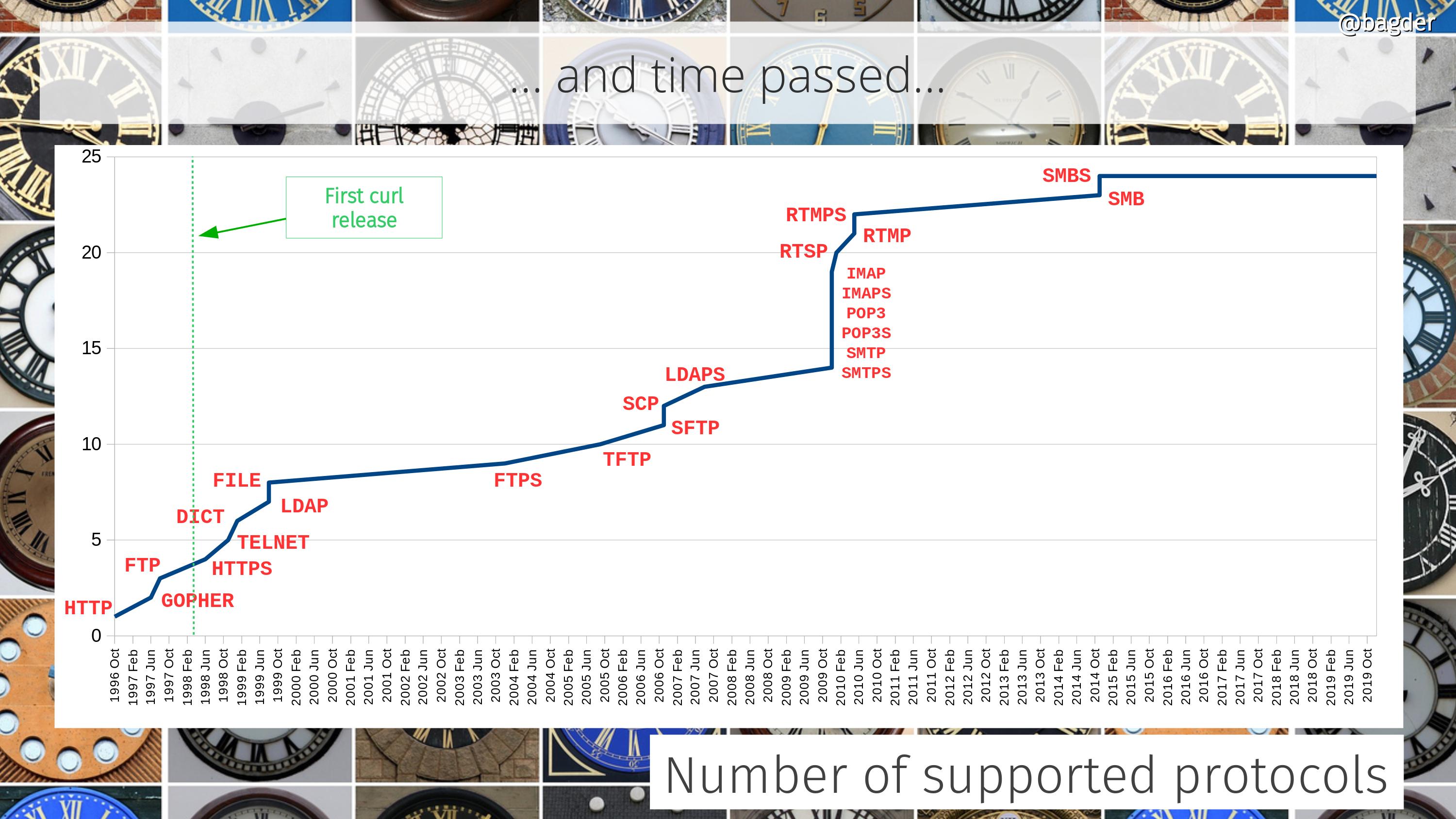
As the command line tool curl started to get somewhere and was already two years old at that point (the curl tool was born on March 20 1998), I imagined that there could be an application or two that could benefit from getting easy access to doing Internet transfers. It was just a gut feeling and a guess. I did not know. I did not research this or anything, I just took the plunge and figured we will eventually realize if I was right or wrong.
With me having written some portable libraries in the past already, curl was already written with the mindset that it could at time point get converted to a library + command line tool. This eased the conversion.
Already on day one libcurl built and ran on numerous operating systems offering the same API.
Name
When I decided to make a library from the core of the curl tool I opened the discussion to see if someone had any ideas for what this library should be called. Naming is hard and I had no particularly bright ideas myself so we quite soon landed on the simplest take possible. Let’s just call it libcurl.
API
How do you design an internet transfer library API?
I had this idea to offer multiple different API “sets” but I figured I needed to start with something basic. It ended up getting called the “easy” interface because it was intended to be straight-forward to use and I decided I could always add something more advanced later. I wanted to provide a fairly low level API and if someone wanted something more high-level, such an API can get built on top of this.
I knew that I wanted the API to be somewhat extensible without having to change the API all the time, and I found inspiration in how the ioctl() and fcntl() and similar functions work. I made curl_easy_setopt() follow that pattern. For good and bad.
I wanted the API to be decently protocol agnostic, since curl could already handle several different ones and I figured it could be appreciated by users who might not always be Internet protocol experts.
Mostly due to luck we managed to ship an API that even though it has its quirks has survived remarkably well.
Using C
There was never any consideration to use another language than C for the library and there was really no decent options to select from either. In theory I suppose C++ could have been used, but I have never been a friend of C++ so I rather not. Not then, not now.
There was never even a discussion about what language to use.
Resilience
The API that gradually was created in that summer of 2000 turned out to be fairly good and has survived and done surprisingly good.
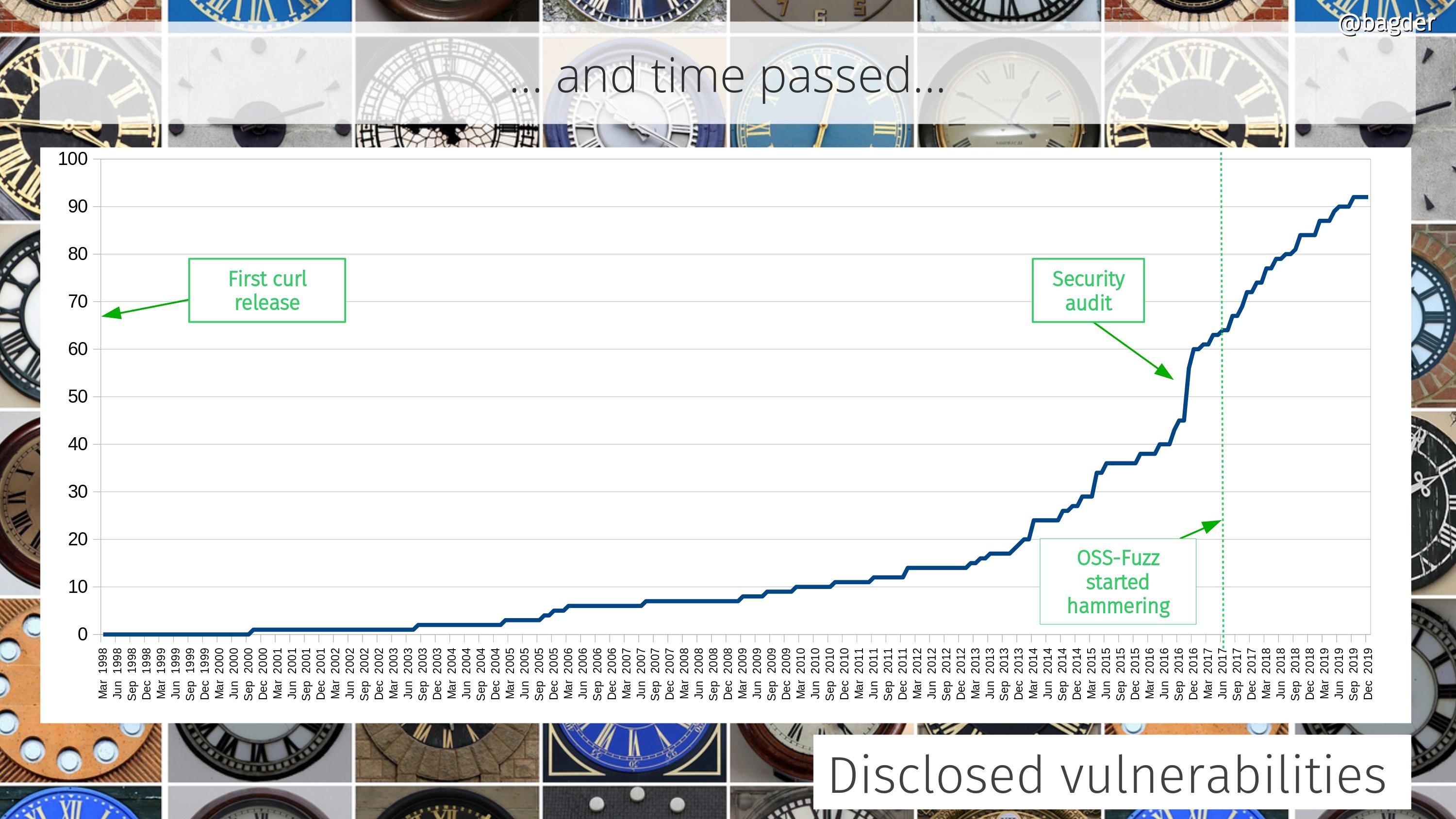
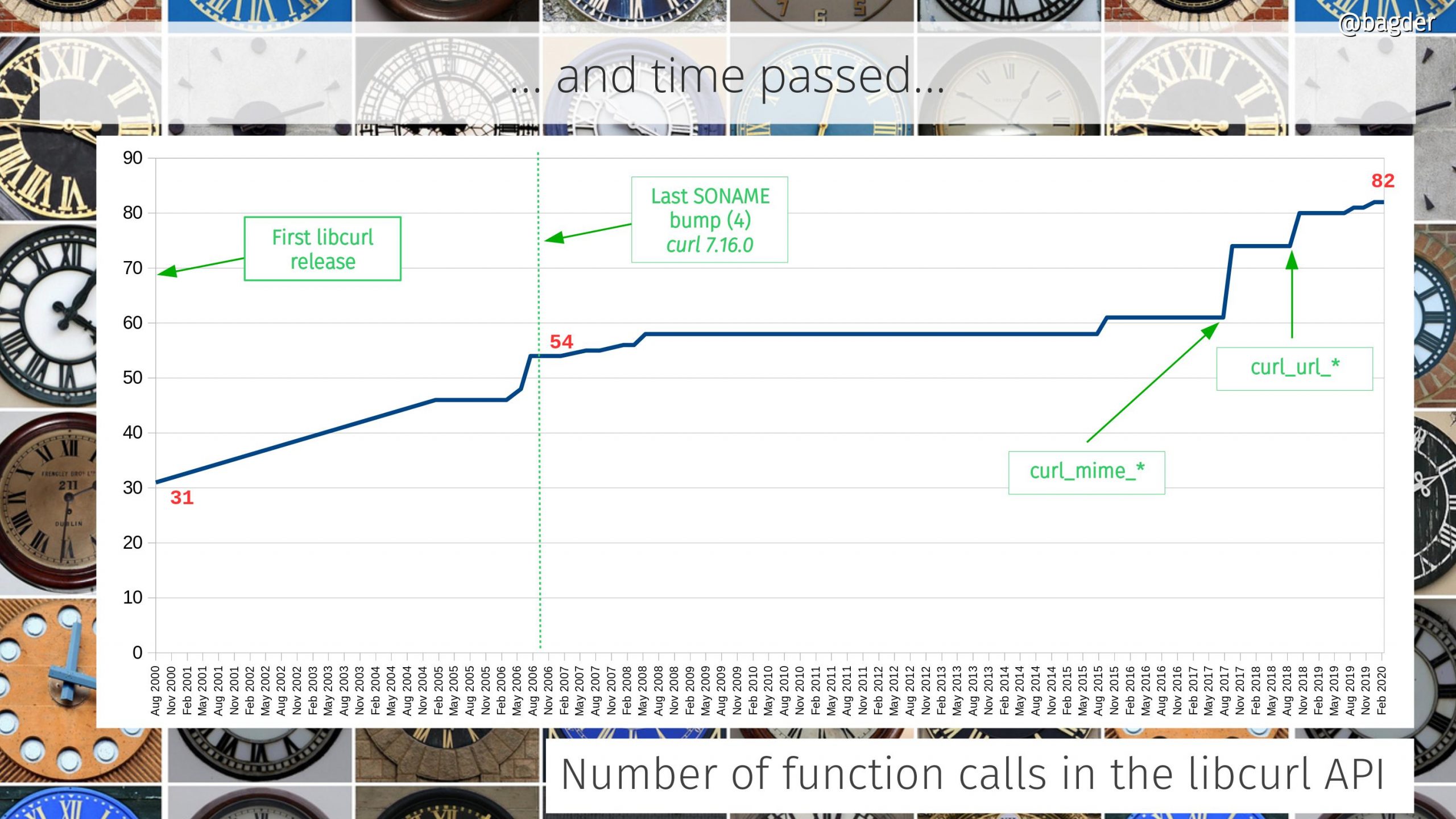
There are 17 API functions still in use today that were introduced in 7.1. In fact, much code written for the API from back then can still be compiled and run using the latest libcurl!
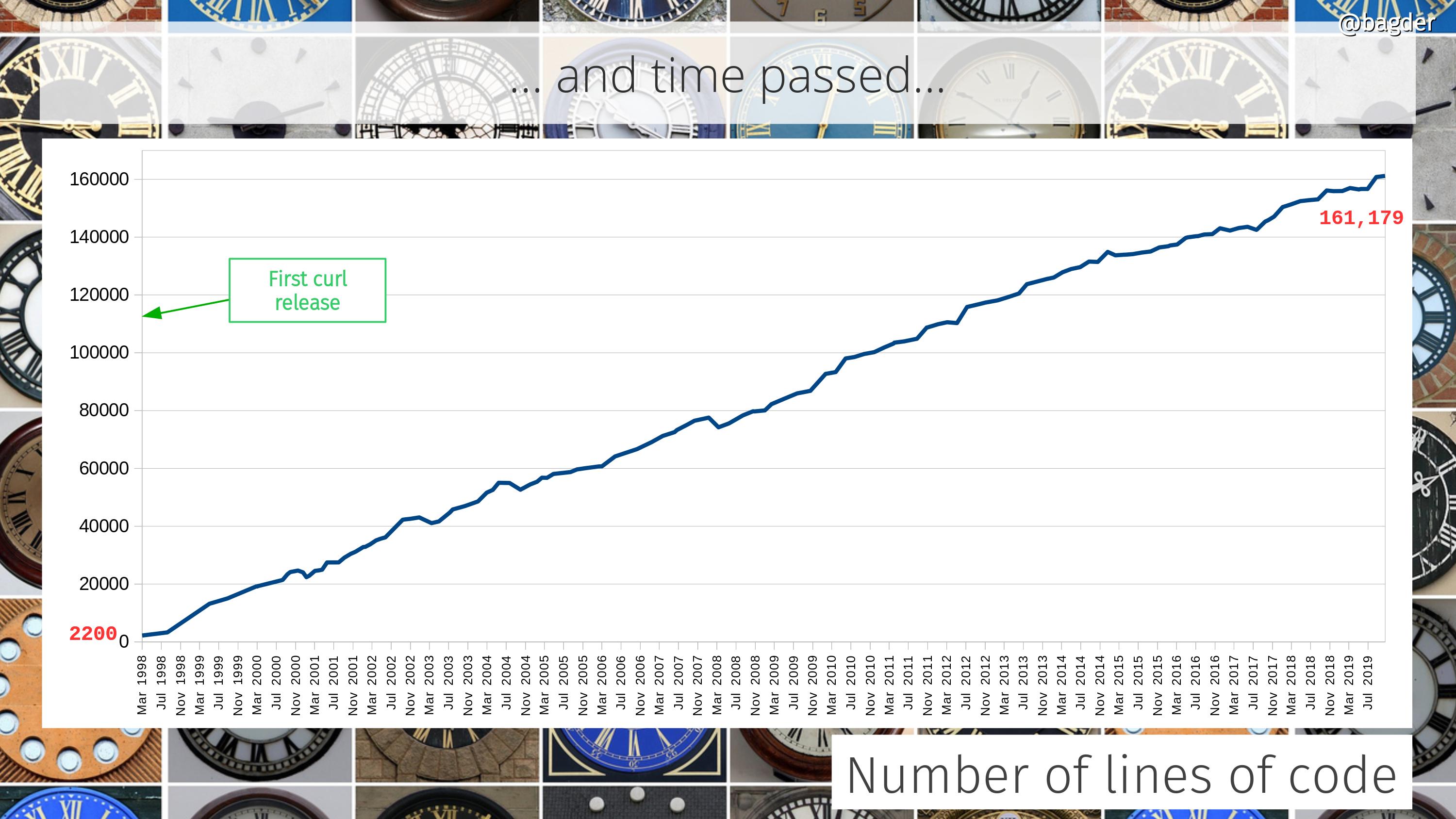
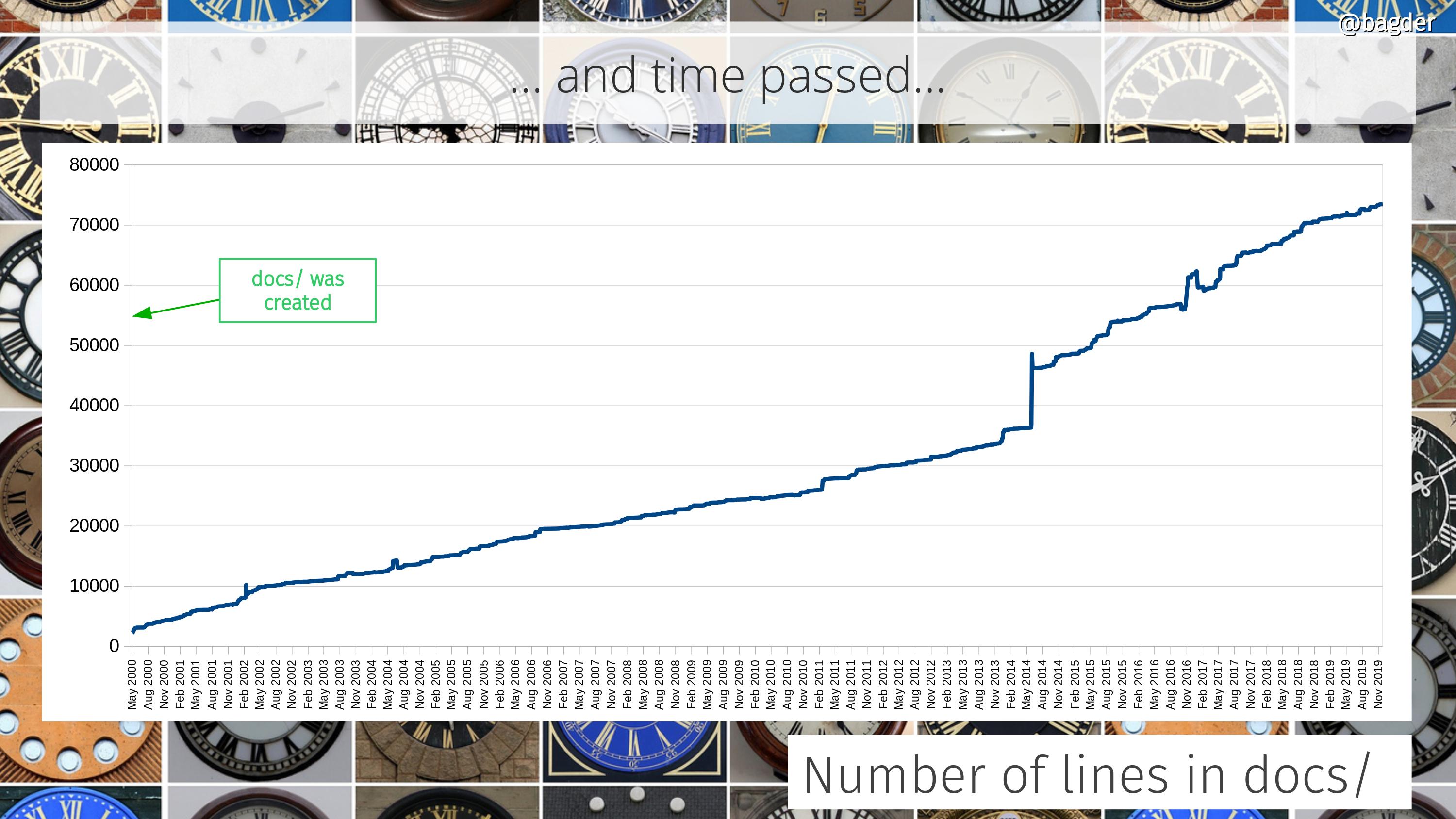
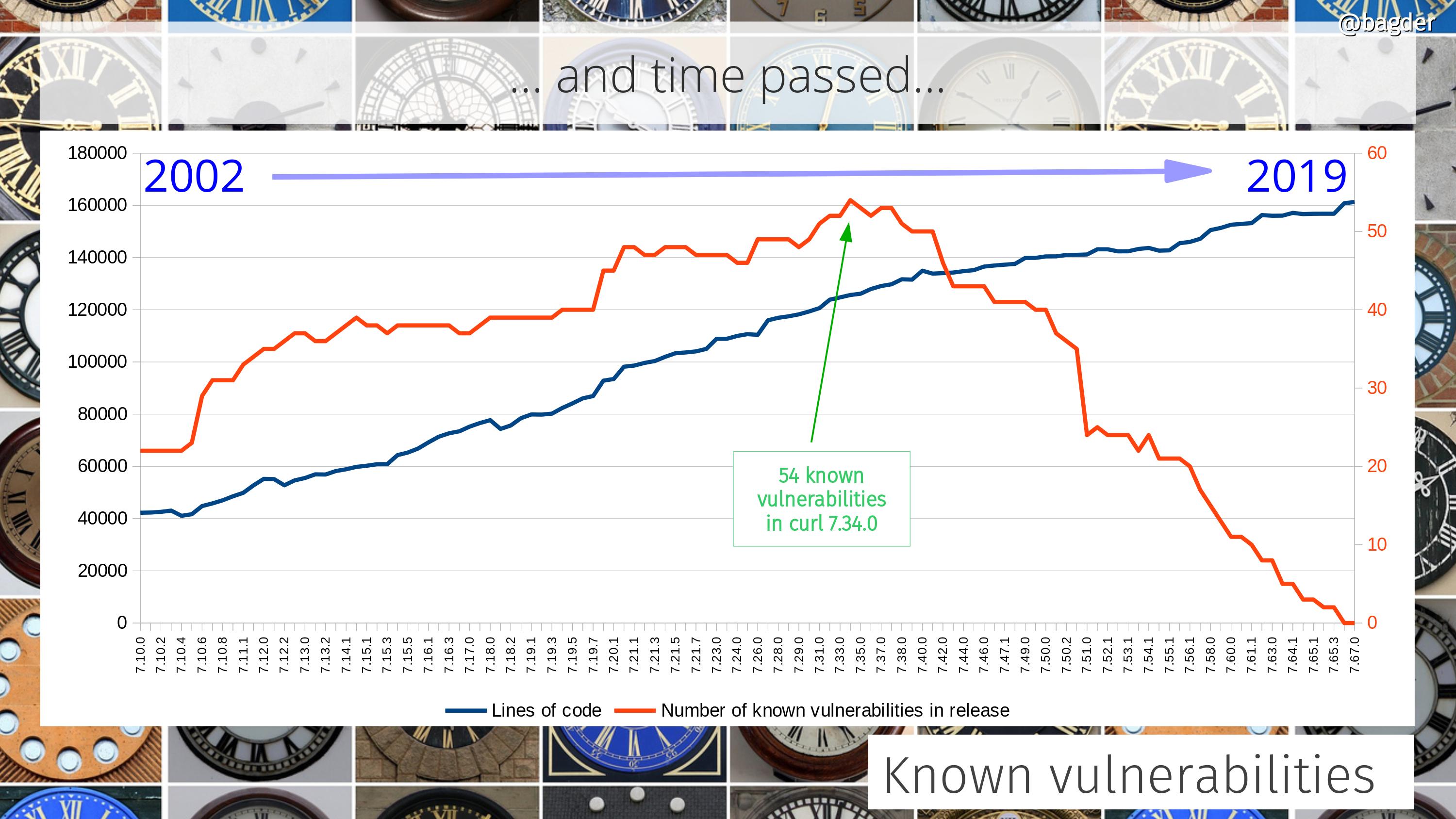
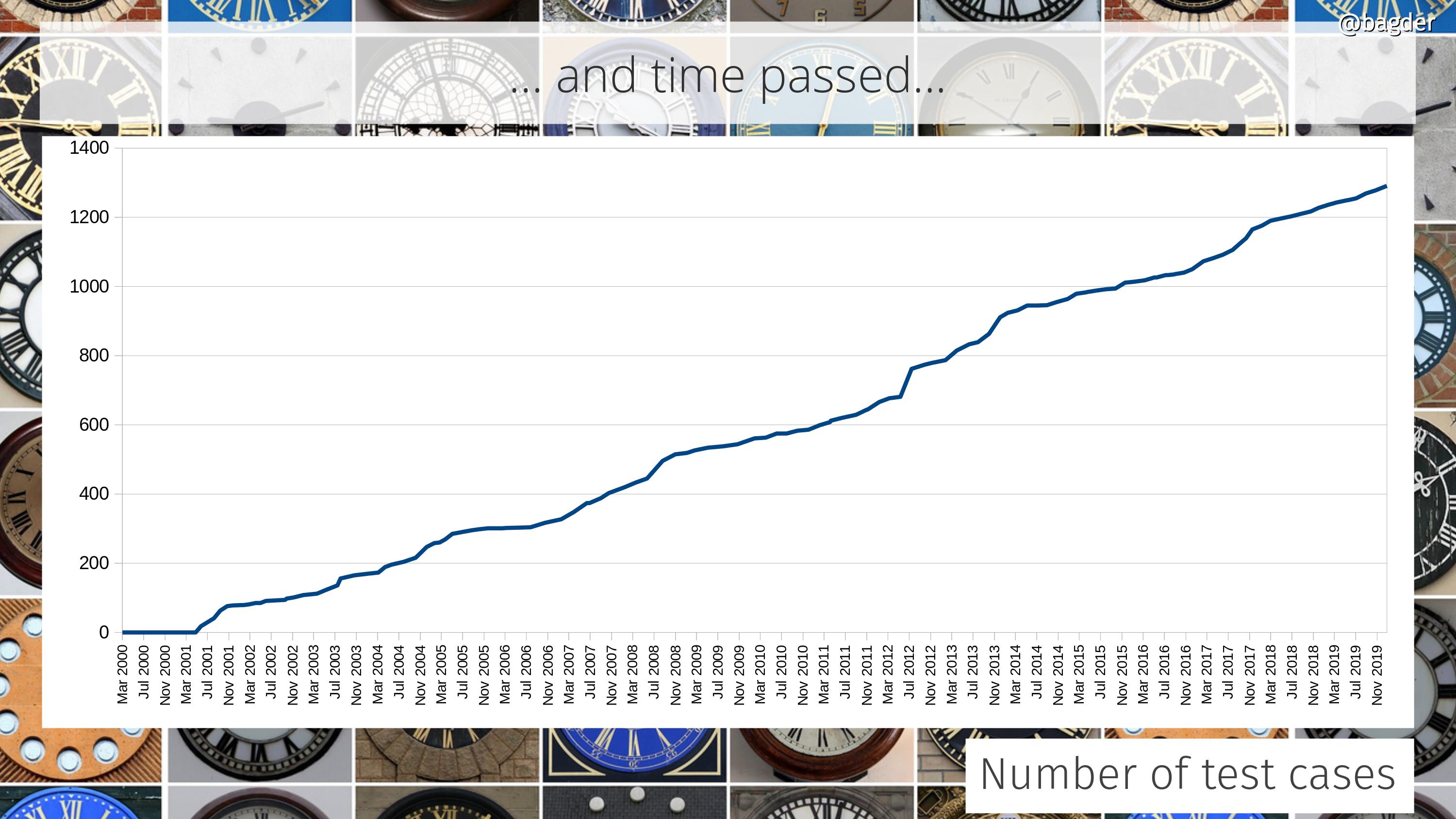
At the time of the first libcurl release there was about 17,000 lines of product code. Today, twenty-four years later, we recently surpassed 171,000 lines.
The API has over the years even proved itself to endure “revolutionary” protocol changes such as HTTP/2 introducing multiplexing multiple transfers over the same connection and HTTP/3, which switches from TCP to UDP. This, mostly because it offers a high enough abstraction level.
Users
The same month we shipped the first libcurl ever, the PHP project built the first libcurl binding. When PHP 4.0.2 was released on August 29 2000, curl was a bundled, blessed and official extension. PHP’s early and unconditional adoption of libcurl helped us get users, get testing, get bugreports and helped us mature.
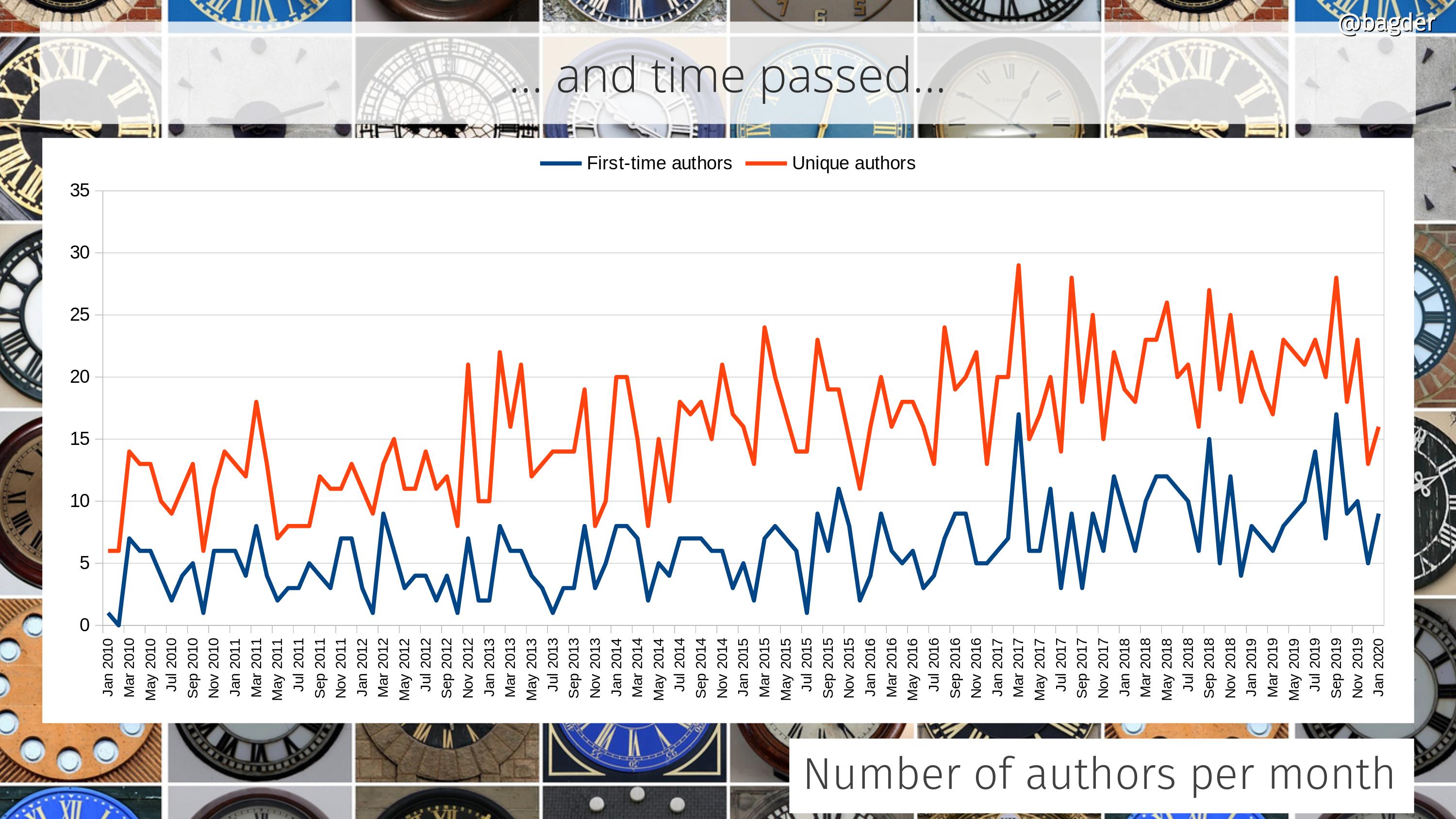
Soon other users, projects, tools and devices adopted libcurl and built things using it. Gradually, it grew in popularity.
multi interface
In the spring of 2002, we expanded the libcurl API with the “multi” API. Using this API family, libcurl offers an unlimited number of concurrent parallel Internet transfers in the same thread.
In 2006, we later expanded the multi interface to offer the multi_action way, which expands the API to allow use of event-based mechanisms for the event loop, like epoll etc, thus allowing scaling up parallel transfers to the thousands or more without sacrificing performance.
SONAME
Put simply, SONAME is the version number of the binary interface. We bumped it several times in the early years as we adjusted API details that we did not get right from the beginning.
Years later (in 2006), we did the last major SONAME bump and by then libcurl had enough usage to make a lot of people squeal and complain about the agony that bump caused. That event and its reactions was a strong contributing factor to me making the decision: To as far as we possibly can never again break the ABI. So far we have managed to stick to this promise and goal – barring bugs of course.
Every libcurl program since 2006 can be compiled against the latest libcurl. Of course, the underlying protocols (especially TLS) and URLs etc have changed and moved significantly since then which makes most URLs from that time to not work anymore.
Higher level API
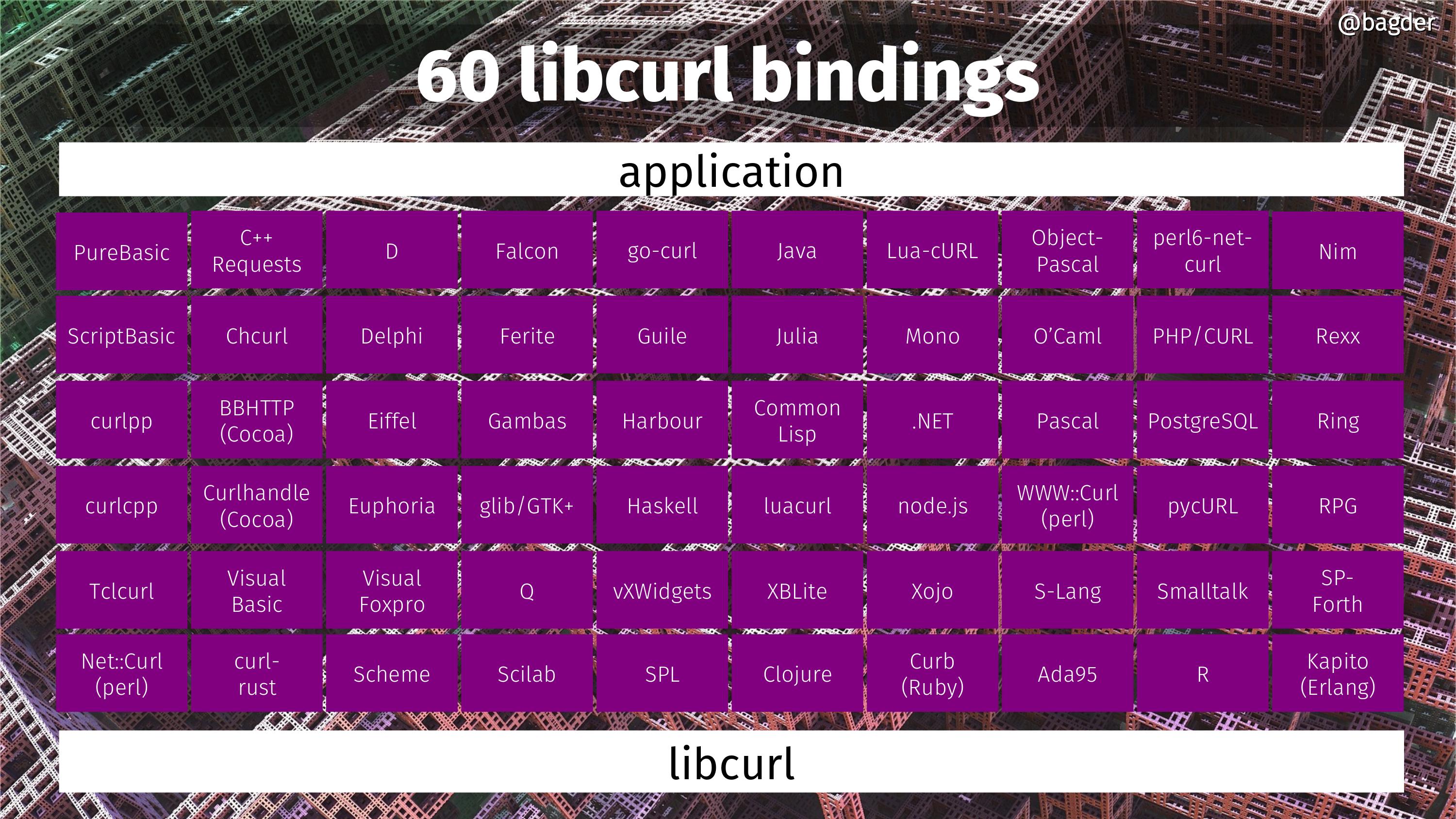
I think in many ways my original hopes of others doing higher level APIs to build on top of what libcurl provides has been realized primarily through the means of language bindings.
We have records of at least 65 different language bindings created for libcurl, for almost as may different languages and environments. This expands the reach of libcurl powers and makes it virtually independent of programming language of choice. It also lowers the bar, as many of those languages and bindings might be easier and perhaps less intimidating to use than the C API, and yet they still offer the unparalleled super powers of the libcurl engine under the hood.
Success
I think no matter how you count or view it, libcurl can be considered a success.
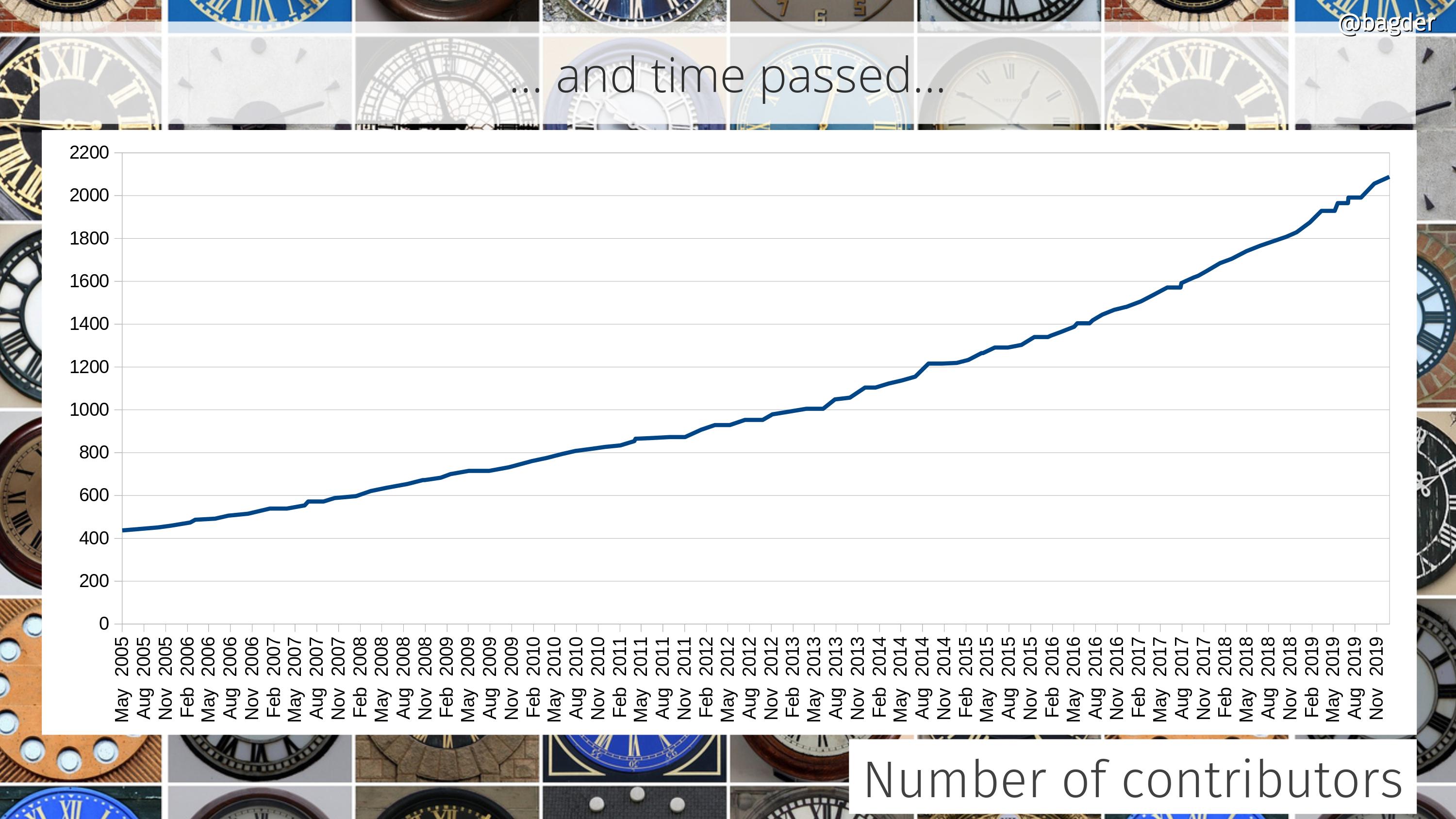
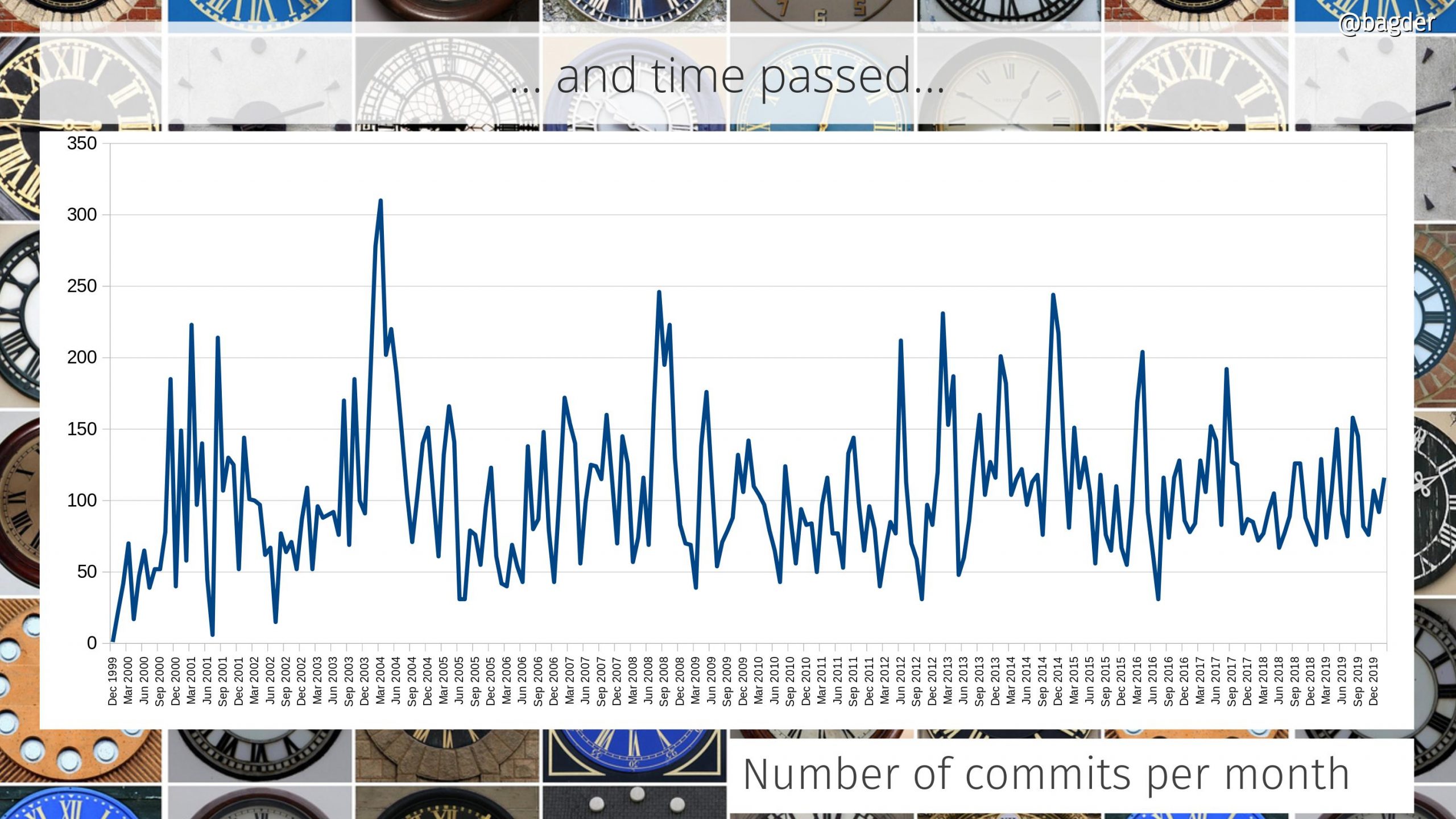
This success was possible only because of the people involved. The thousands of contributors who reported bugs, debugged problems, tested patches, ran crazy experiments in production, voiced their opinions, provided ideas and added features. I may be the captain of the ship, but I was never alone and it would never have been even close to possible if I had been.
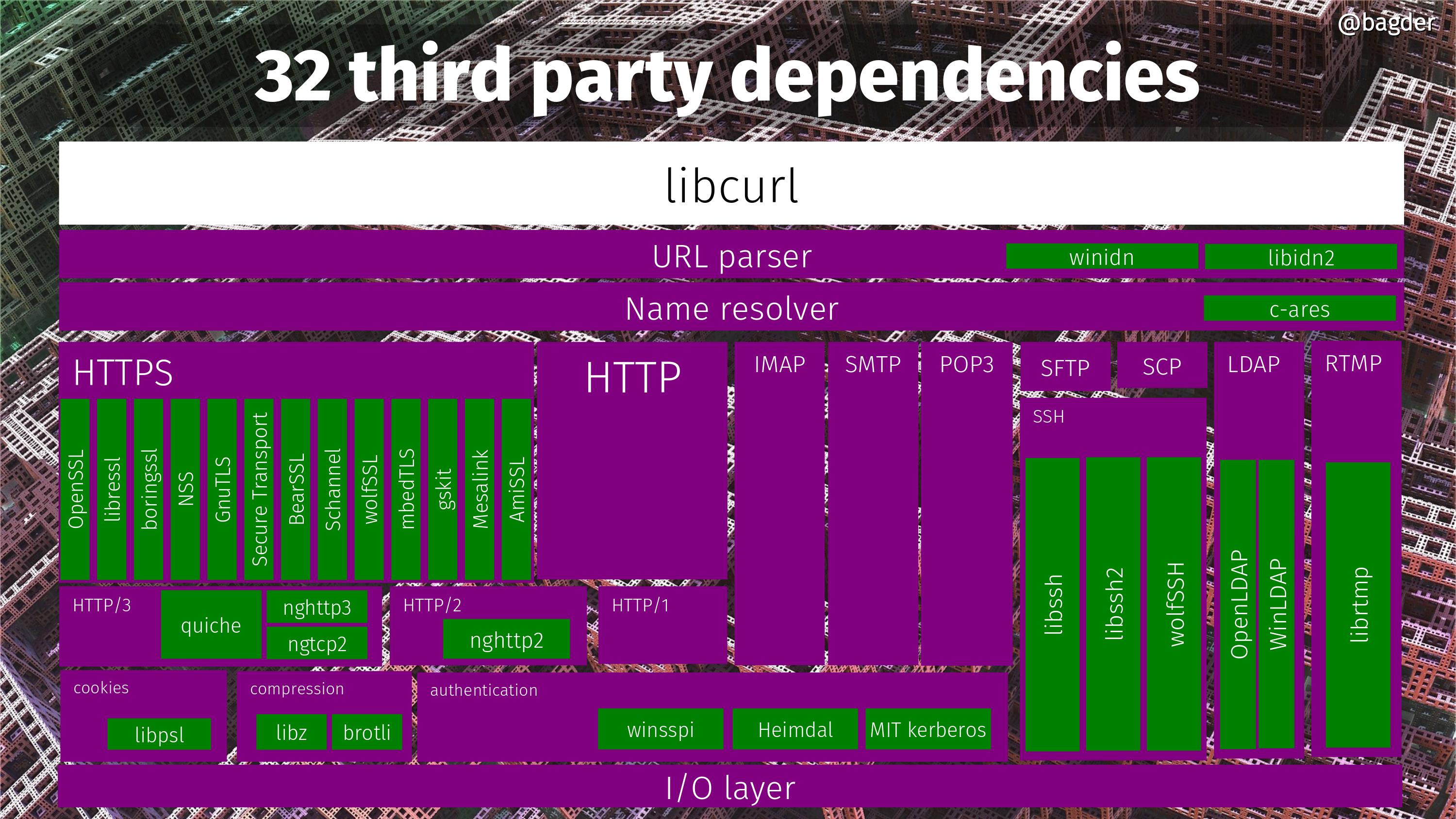
libcurl has been made to run on at least 103 operating systems and 28 CPU architectures. Everyone can always just opt to use libcurl in whatever thing they need Internet transfers in.
Timing
I attribute a lot of our success on the lucky timing. We offered something that was working and decent at the right time, and we could following along and grow with the general Internet use growth. We had no idea where the Internet evolution was going, its explosion growth and we had no idea that just about every consumer device was going to get Internet connected twenty years layer. Devices that all could run libcurl.
Competition
Internet development and evolution never stop. When libcurl first shipped, people were using libwww and for several years I considered that to be our primary competitor. Today, few people even know it existed.
The time is now and if we do not keep up with development, fix bugs and offer the features that allow the world to do Internet transfers the way every wants, then libcurl could soon also be added to the pile of forgotten software projects.
These days, there are plenty of libcurl alternatives. Perhaps the most significant ones being native (HTTP) libraries included in or for programming languages like Python, Java, Rust or .Net.
I like to say that libcurl’s biggest selling point is that we have at least 18 years of proven API, ABI and general stability. Nothing you may consider to use instead of libcurl comes even close.
Future
Even more devices will get Internet access going forward. Where Internet goes, libcurl can be of use. I do not think we have reached peak libcurl yet.
The curl project needs to keep the product rock solid and never break the API. We need to continue support doing Internet transfers they way “the world” wants them done: the protocols, the versions and the methods deemed the right ones. Keep listening to our users. Keep making it easy for contributors to improve it.
I have never been good at forecasting or even guessing what the future holds. Will there ever be a moment or event in the future that suddenly makes libcurl irrelevant? Maybe. It’s not totally unlikely. More likely however, libcurl will continue to transfer Internet bytes for the world for many years to come. At some point it will be superseded by something else, but I cannot say when or by what.
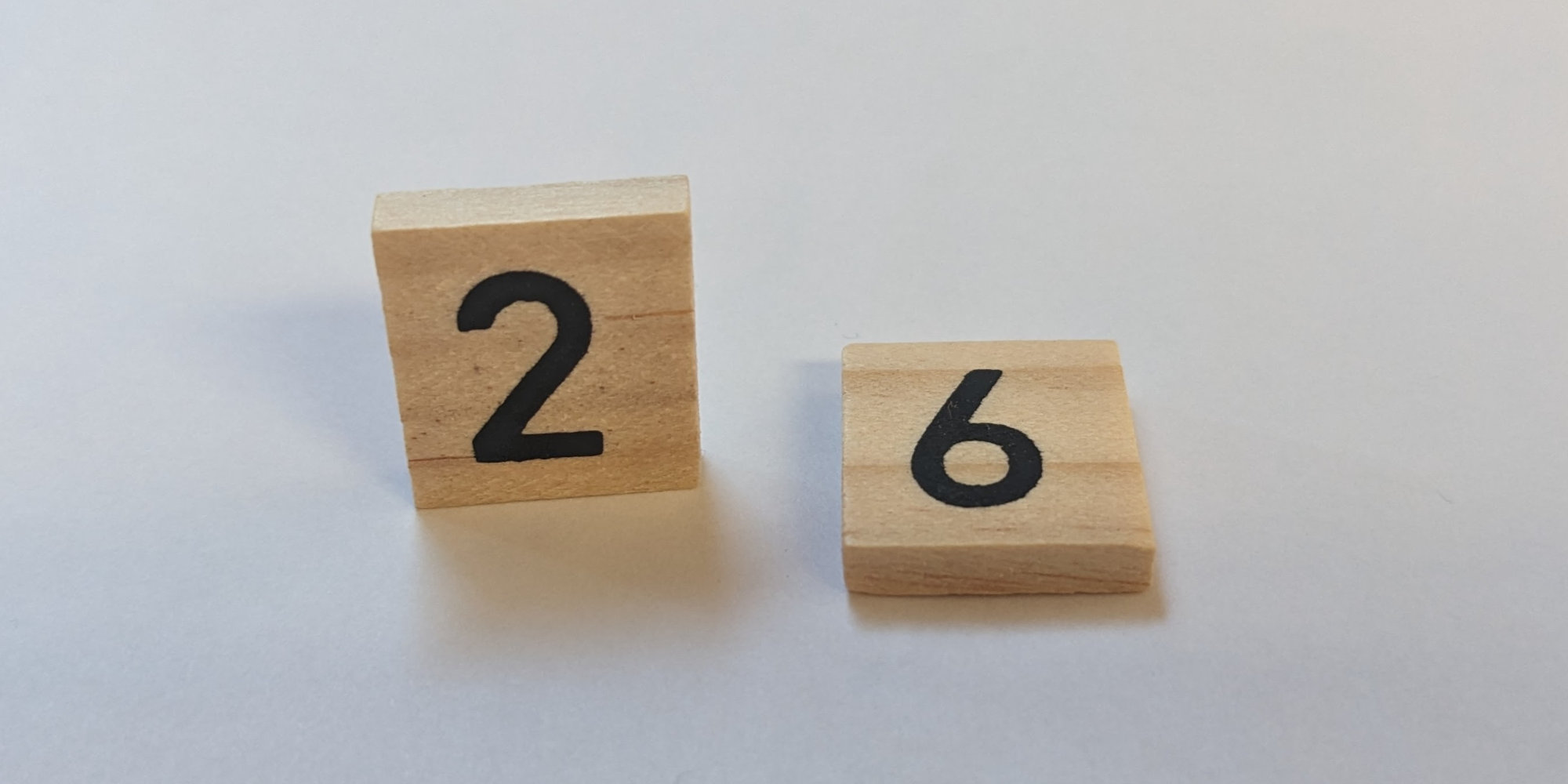












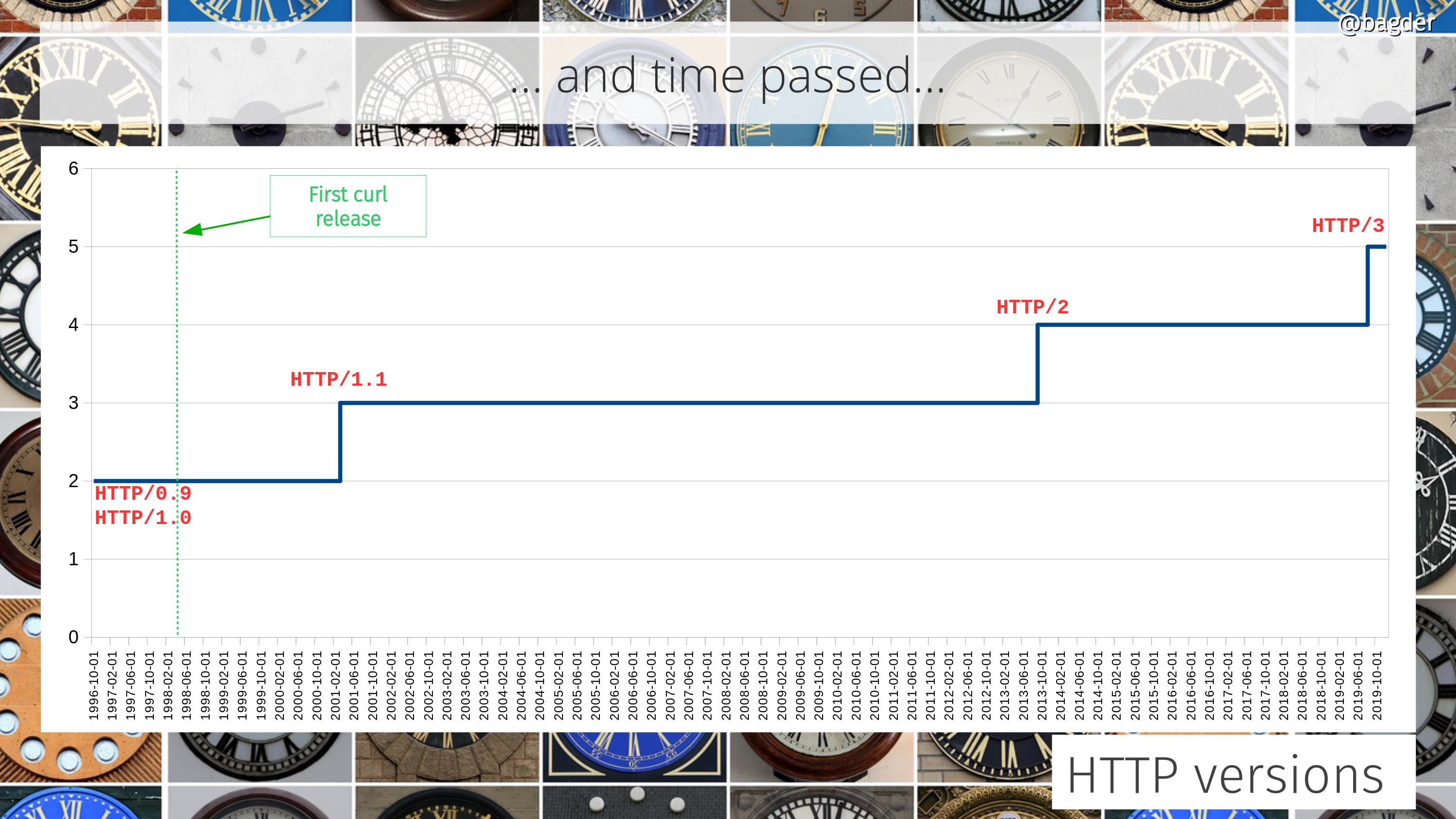
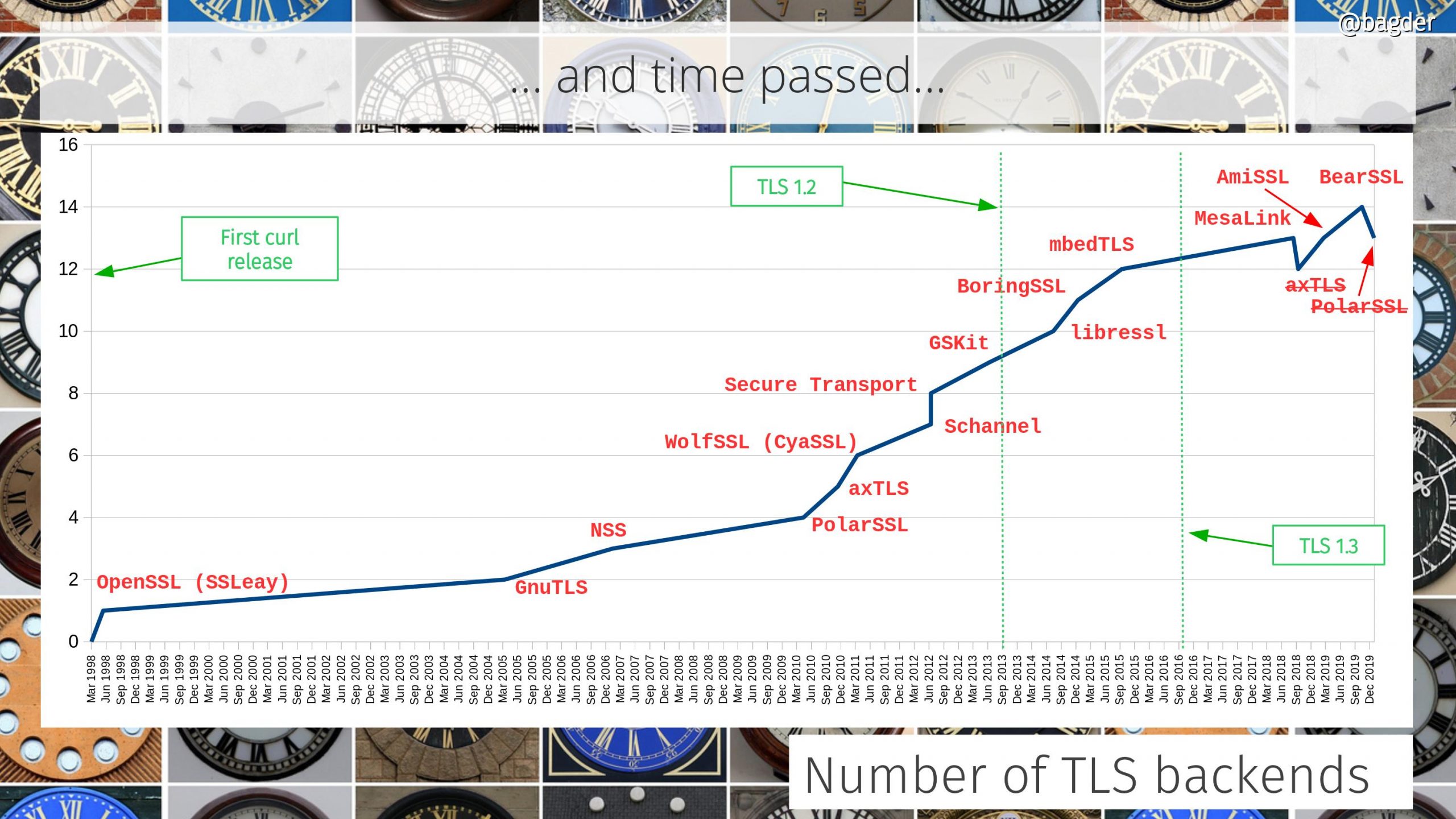
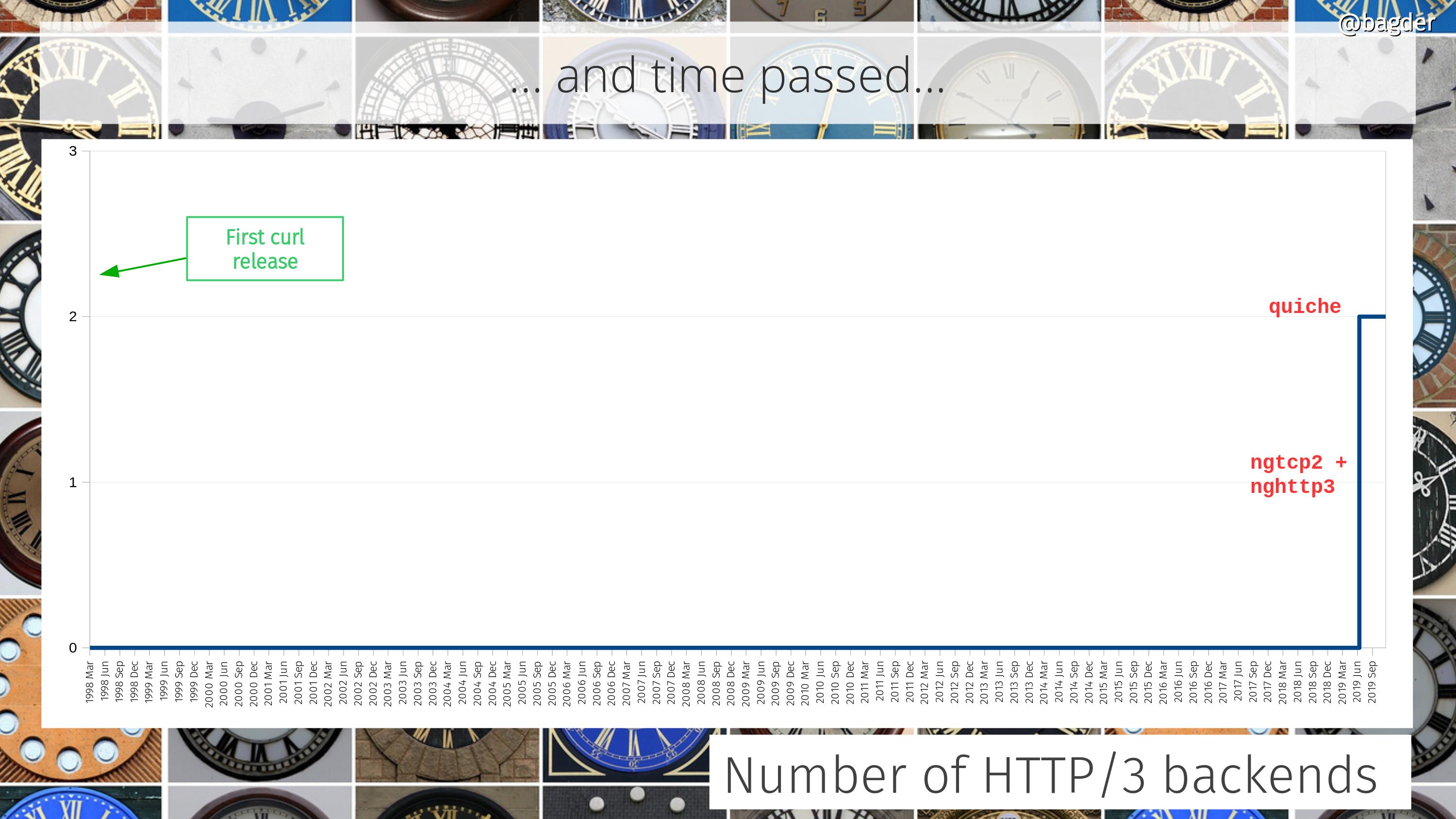
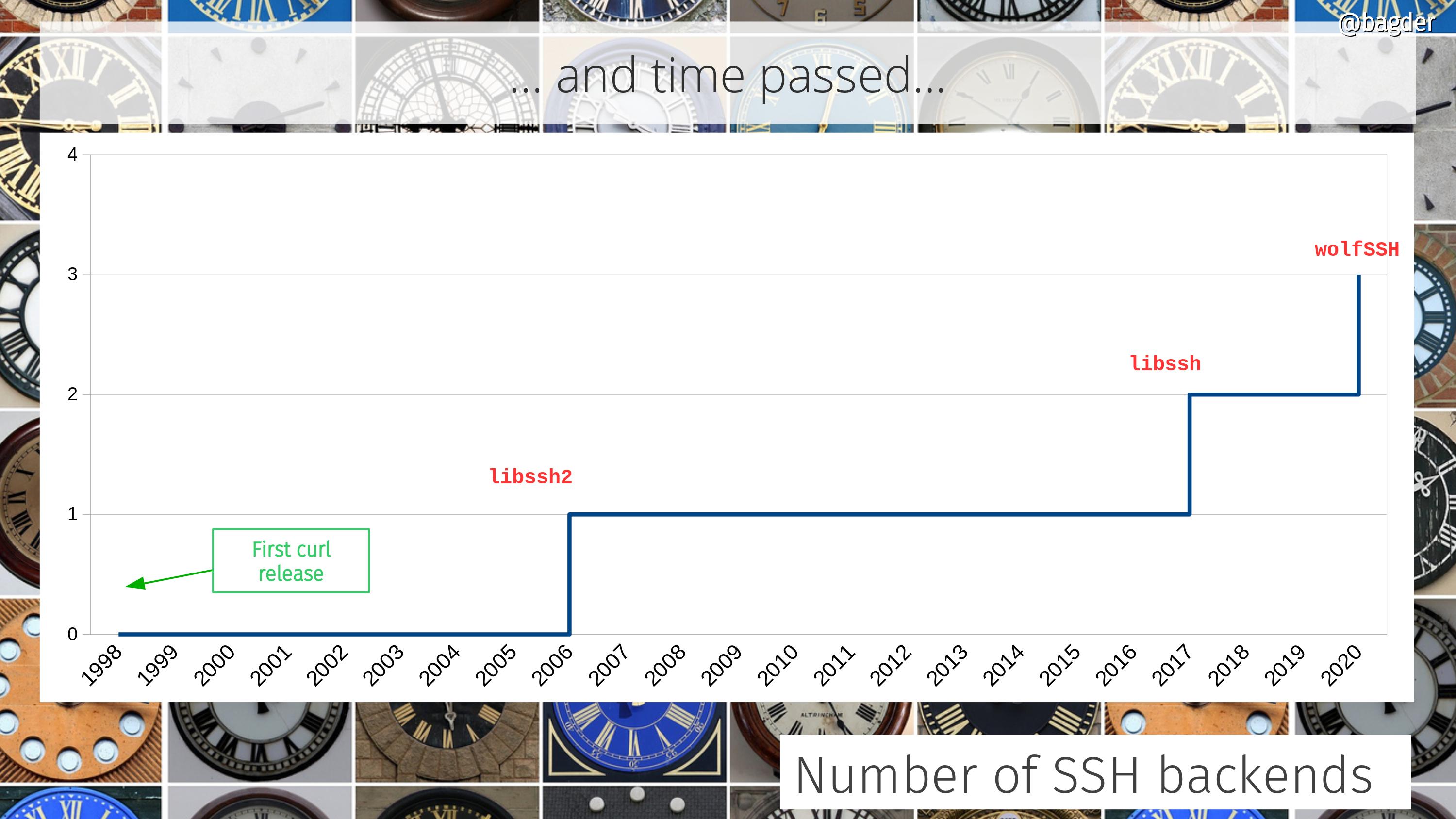





 First a quick reminder of the state of popular culture at the time: three days later, on the 23rd, the movie Titanic would tangent the record and win eleven academy awards. Its theme song “My heart will go on” was in the top of the music charts around this time.
First a quick reminder of the state of popular culture at the time: three days later, on the 23rd, the movie Titanic would tangent the record and win eleven academy awards. Its theme song “My heart will go on” was in the top of the music charts around this time.