Time flies when you are having fun. Today is curl‘s 25th birthday.

The curl project started out very humbly as a small renamed URL transfer tool that almost nobody knew about for the first few years. It scratched a personal itch of mine,
Me back then
I made that first curl release and I’ve packaged every single release since. The day I did that first curl release I was 27 years old and I worked as a software engineer for Frontec Tekniksystem, where I mostly did contract development on embedded systems for larger Swedish product development companies. For a few years in the late 90s I would for example do quite a few projects at and for the telecom giant Ericsson.
I have enjoyed programming and development ever since I got my first computer in the mid 80s. In the 1990s I had already established a daily schedule where I stayed up late when my better half went to bed at night, and I spent another hour or two on my spare time development. This is basically how I have manged to find time to devote to my projects the first few decades. Less sleep. Less other things.
Gradually and always improving
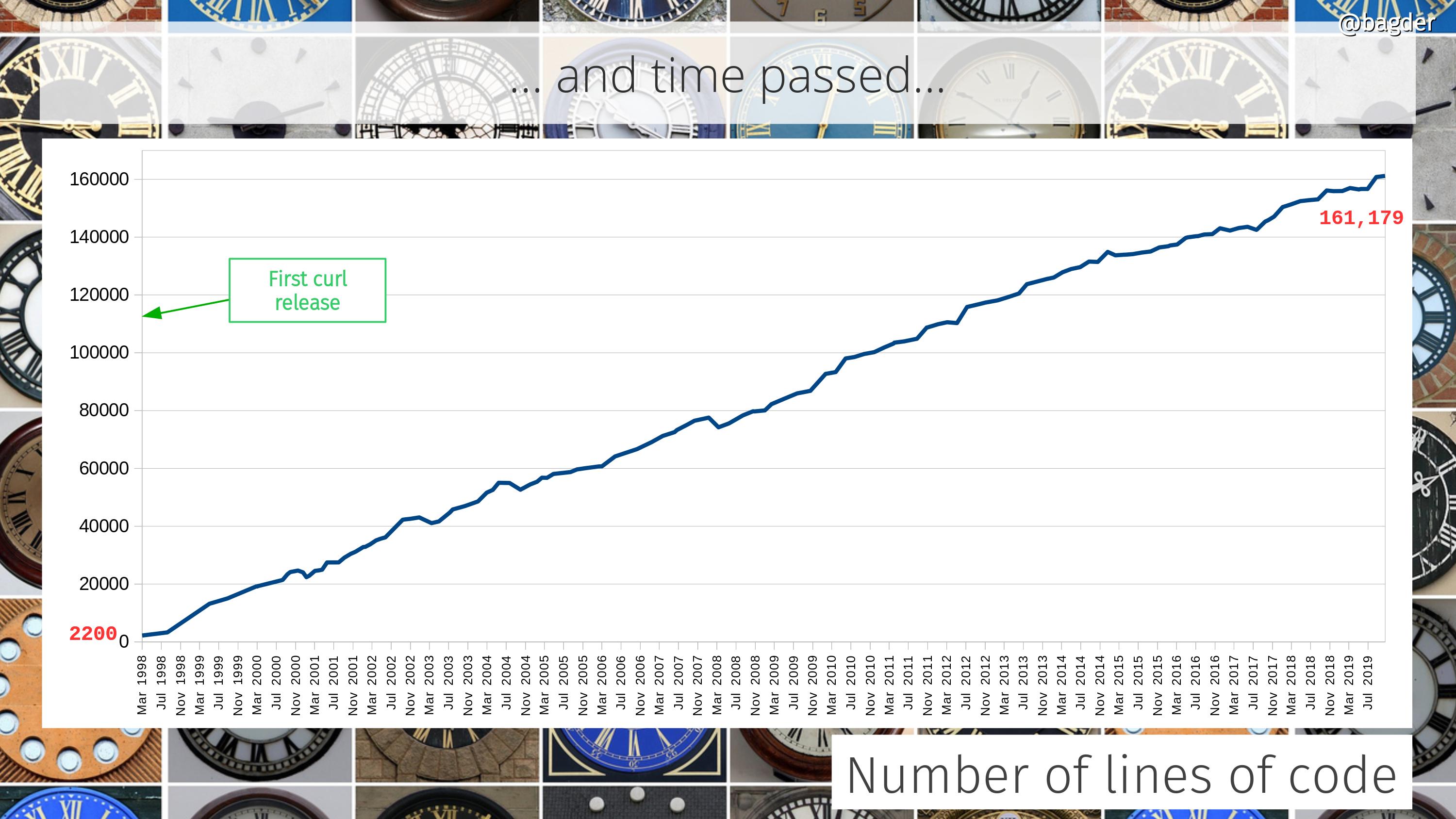
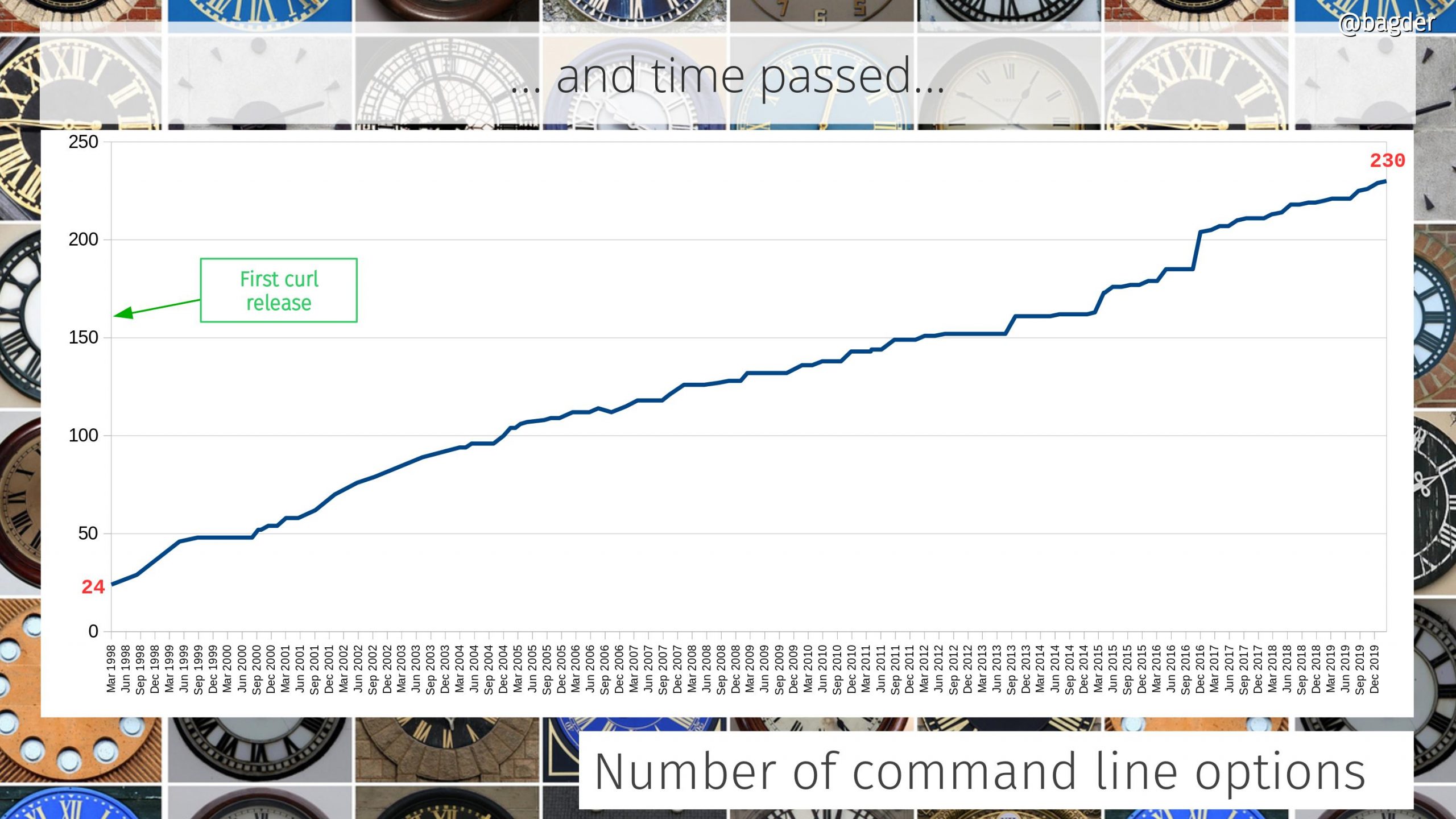
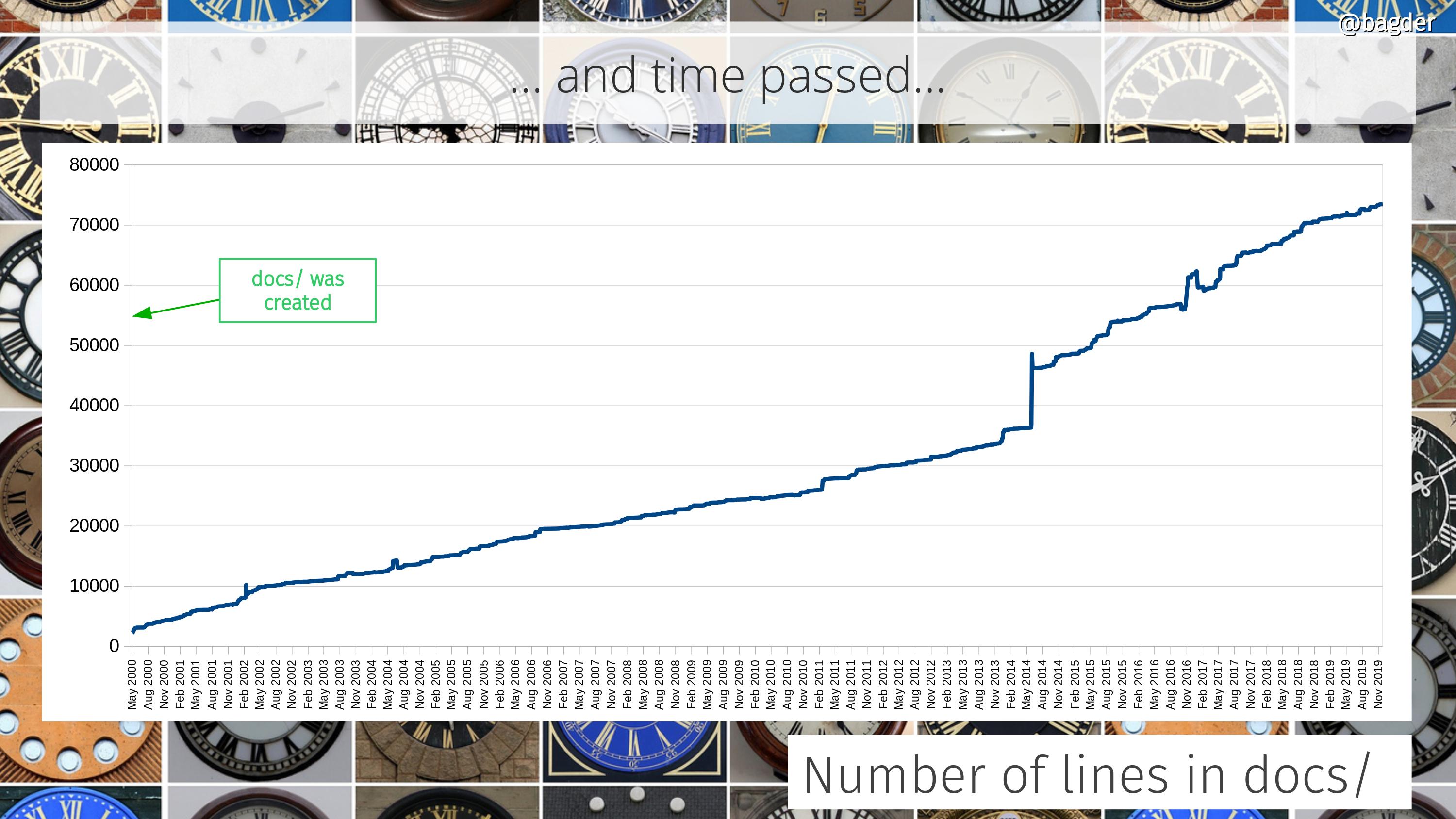
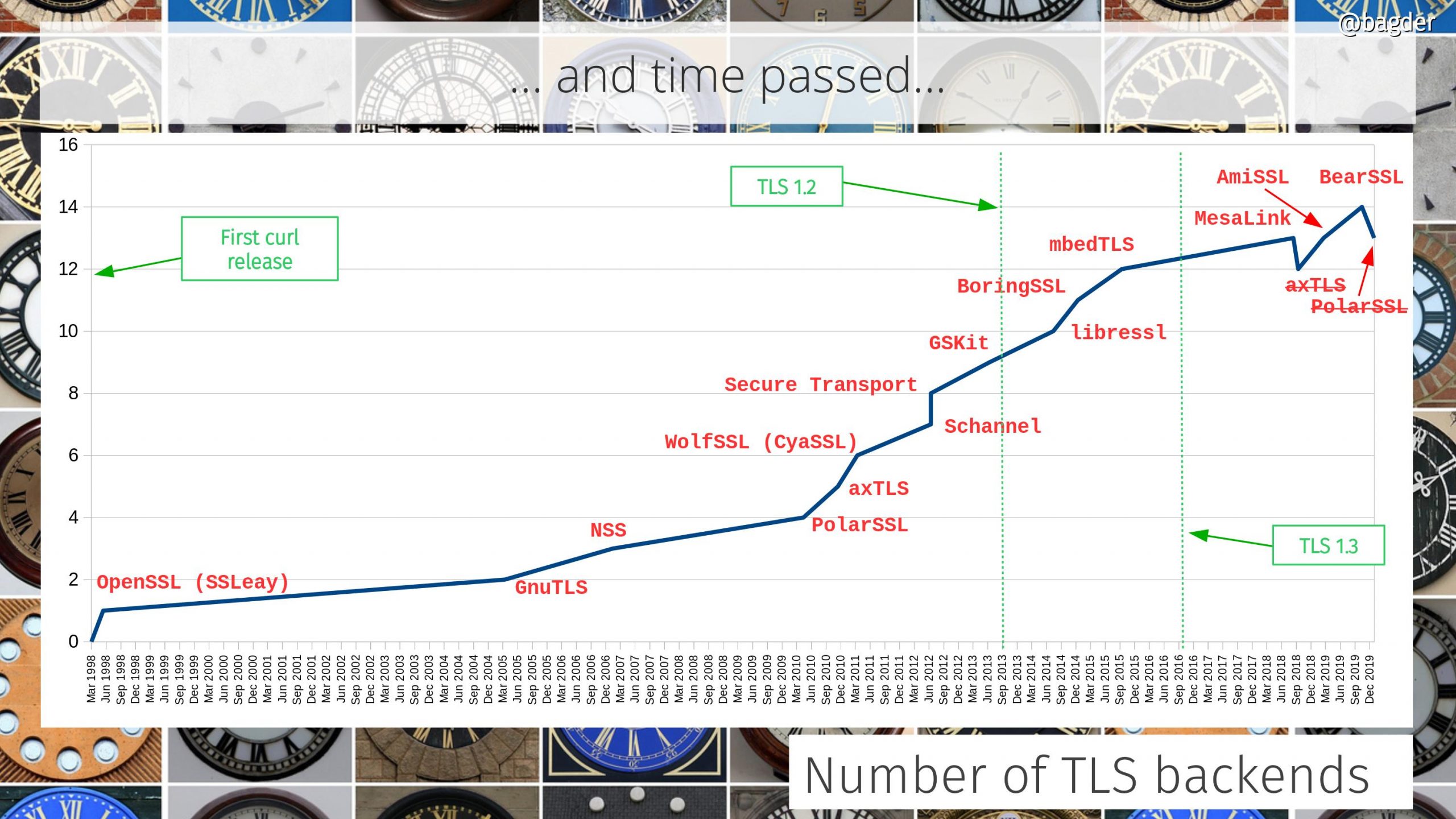
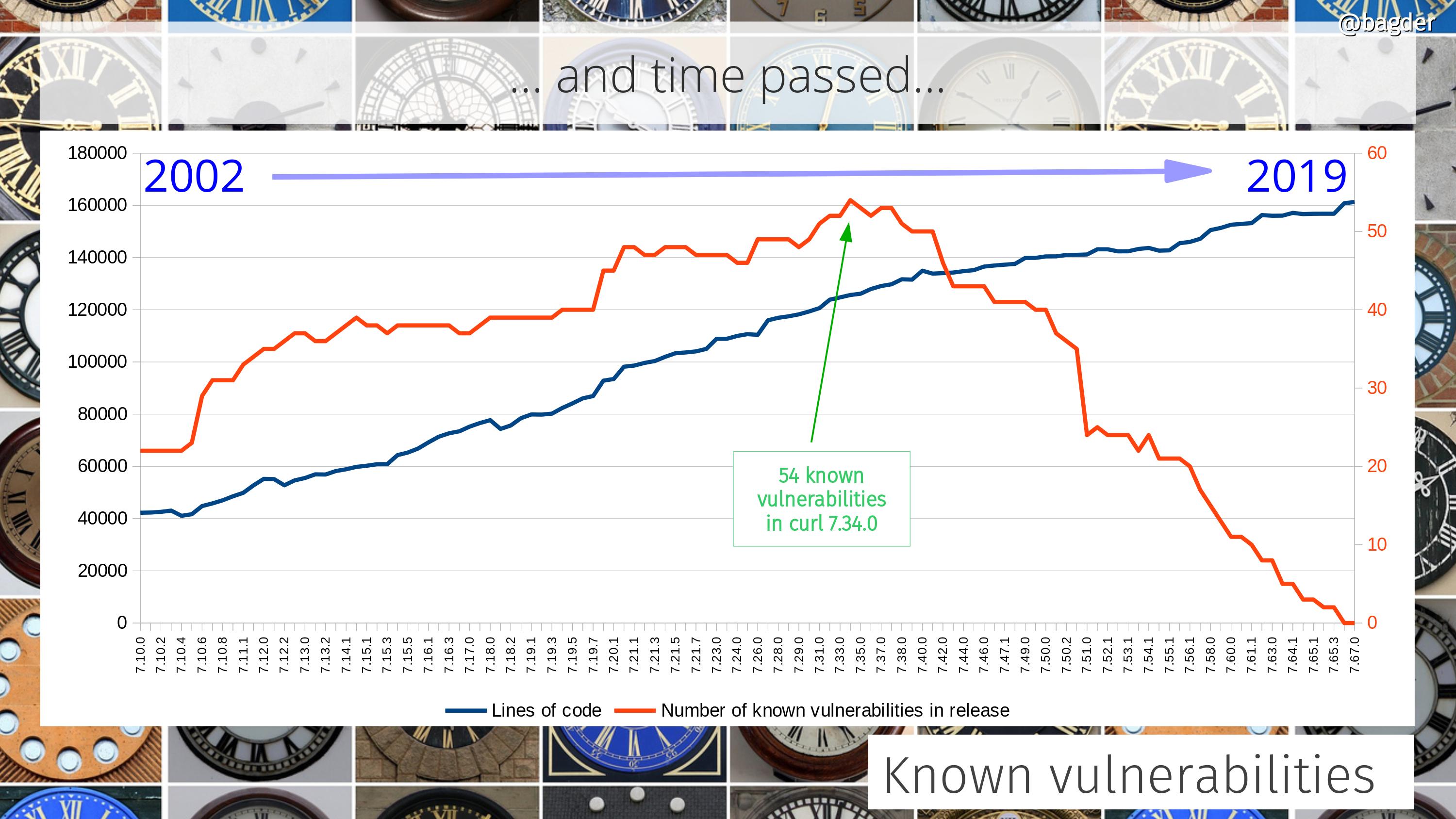
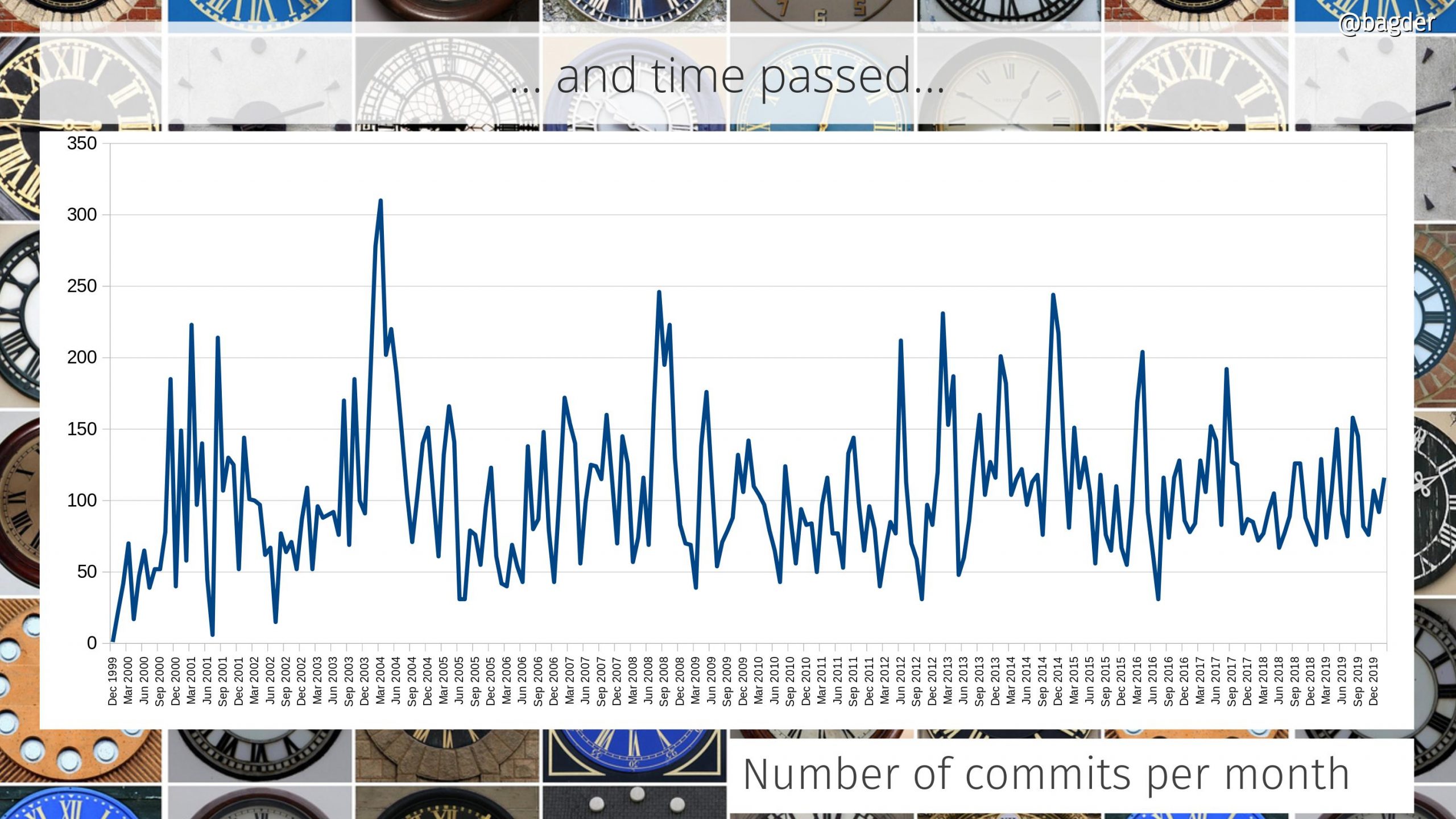
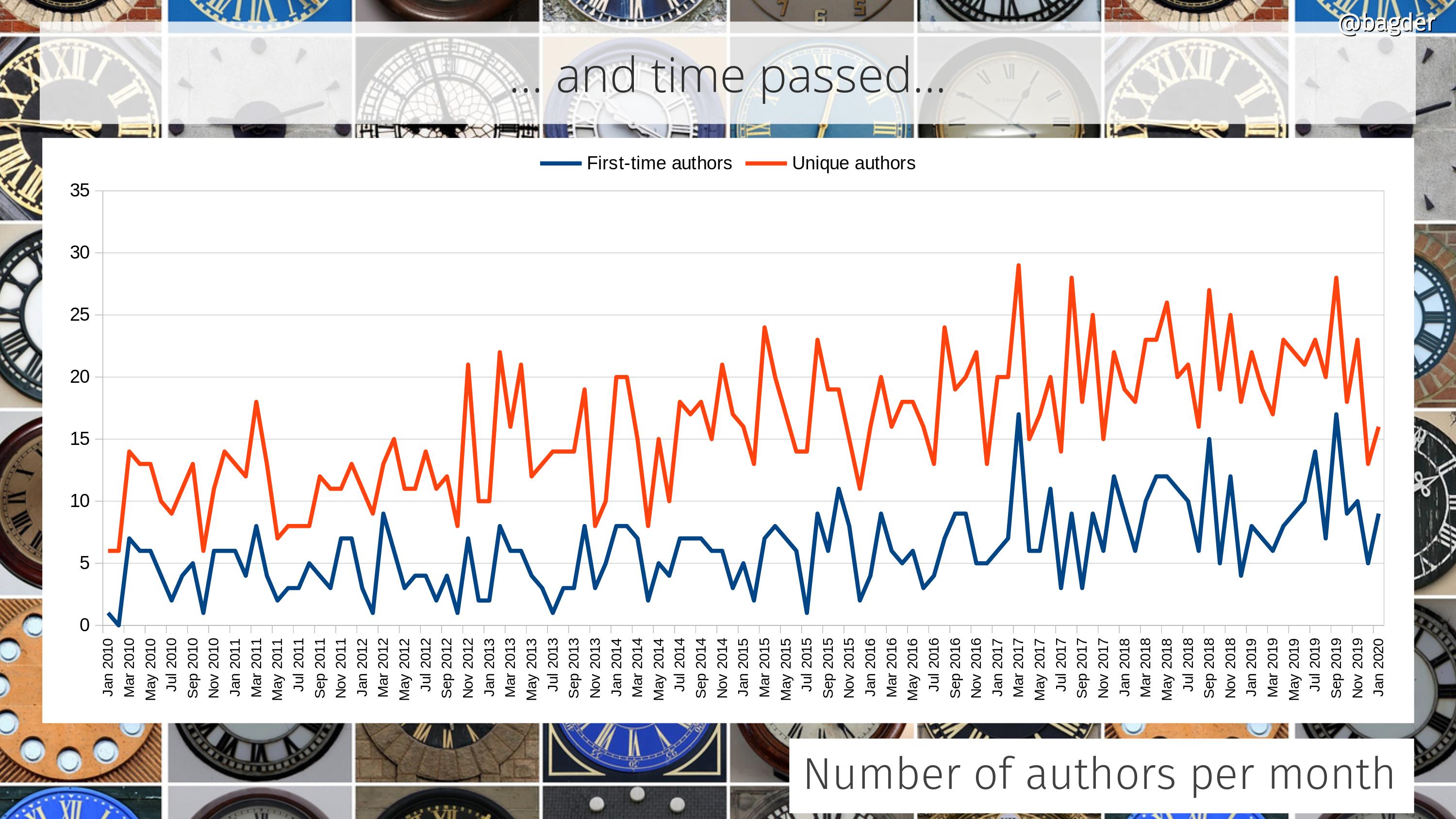
The concept behind curl development has always been to gradually and iteratively improve all aspects of it. Keep behavior, but enhance the code, add test cases, improve the documentation. Over and over, year after year. It never stops. As the timeline below helps showing.
Similarly, there was no sudden specific moment when suddenly curl became popular and the number of users skyrocketed. Instead, the number of users and the popularity of the tool and library has gradually and continuously grown. In 1998 there were few users. By 2010 there were hundreds of millions.
We really have no idea exactly how many users or installations of libcurl there are now. It is easy to estimate that it runs in way more than ten billion installations purely based on the fact that there are 7 billion smart phones and 1 billion tablets in the world , and we know that each of them run at least one, but likely many more curl installs.
Before curl
My internet transfer journey started in late 1996 when I downloaded httpget 0.1 to automatically download currency rates daily to make my currency exchange converter work correctly for my IRC bot. httpget had some flaws so I sent back fixes, but Rafael, the author, quickly decided I could rather take over maintenance of the thing. So I did.
I added support for GOPHER, change named of the project, added FTP support and then in early 1998 I started adding FTP upload support as well…
1998
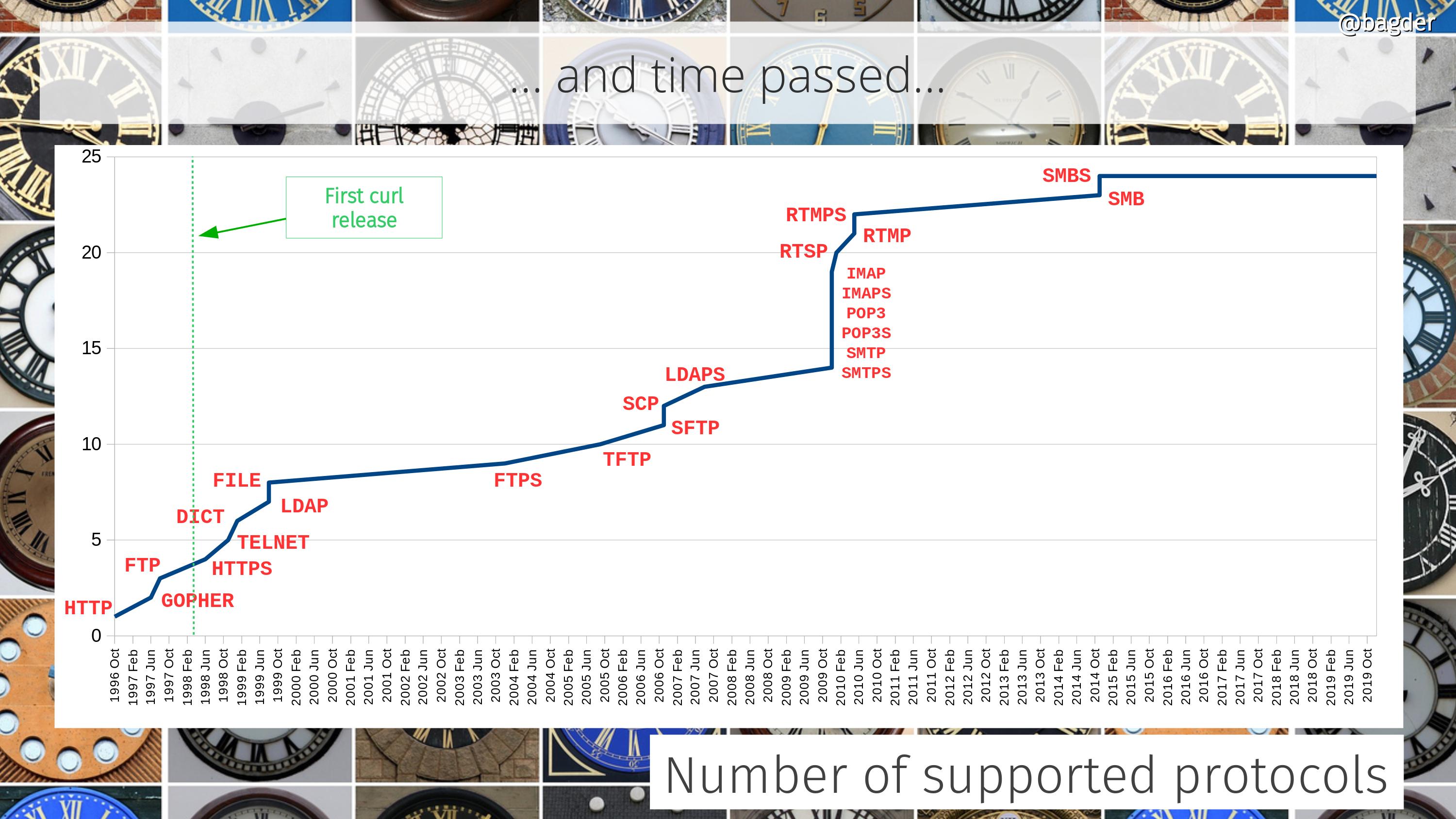
On March 20 1998, curl 4.0 was released and it was already 2,200 lines of code on its birthday because it was built on the projects previously named httpget and urlget. It then supported three protocols: HTTP, GOPHER and FTP and featured 24 glorious command line options.
The first release of curl was not that special event since I had been shipping httpget and urlget releases for over a year already, so while this was a new name it was also “just another release” as I had done many times already.
We would add HTTPS and TELNET support already the first curl year, which also introduced the first ever curl man page. curl started out GPL licensed but I switched to MPL already within that first calendar year 1998.
The first SSL support was powered by SSLeay. The project that in late 1998 would transition over into becoming OpenSSL.
In August 1998, we added curl on the open source directory site freshmeat.net.
The first curl web page was published at http://www.fts.frontec.se/~dast. (the oldest version archived by the wayback machine is from December 1998)
In November 1998 I added a note to the website about the mind-blowing success as the latest release had been downloaded 300 times! Success and popularity were far from instant.

During this first year, we shipped 20 curl releases. We have never repeated that feat again.
1999
We created the first configure script, added support for cookies and appeared as a package in Debian Linux.
The curl website moved to http://curl.haxx.nu.
We added support for DICT, LDAP and FILE through the year. Now supporting 8 protocols.
In the last days of 1999 we imported the curl code to the cool new service called Sourceforge. All further commit counts in curl starts with this import. December 29, 1999.
2000
Privately, I switched jobs early 2000 but continued doing embedded contract development during my days.
The rules for the TLD .se changed and we moved the curl website to curl.haxx.se.
I got married.
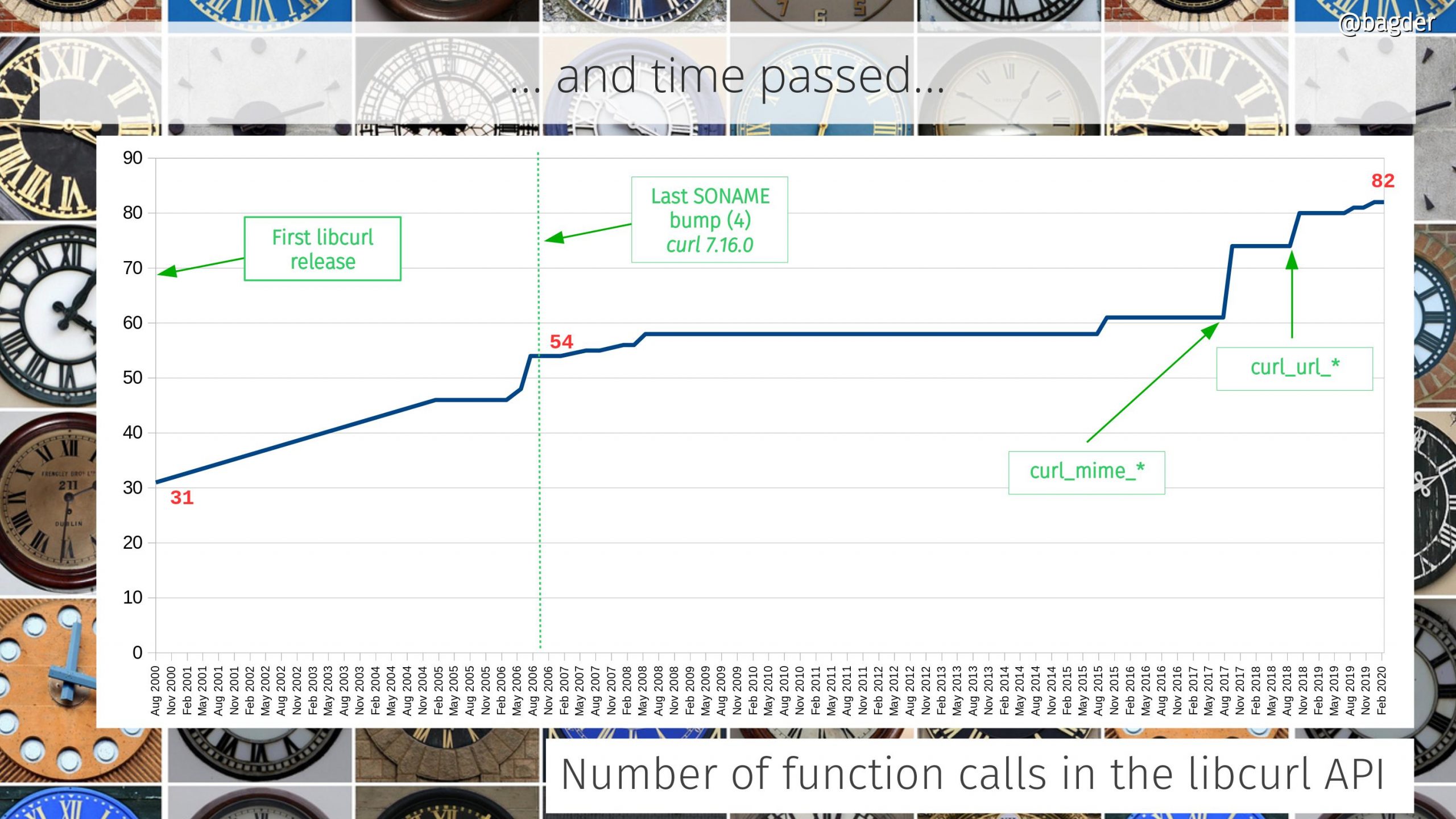
In August 2000, we shipped curl 7.1 and things changed. This release introduced the library we decided to call libcurl because we couldn’t come up with a better name. At this point the project were at 17,200 lines of code.
The libcurl API was inspired by how fopen() works and returns just an opaque handle, and how ioctl() can be used to set options.
Creating a library out of curl was an idea I had almost from the beginning, as I’ve already before that point realized the power a good library can bring to applications.
The first CVE for curl was reported.
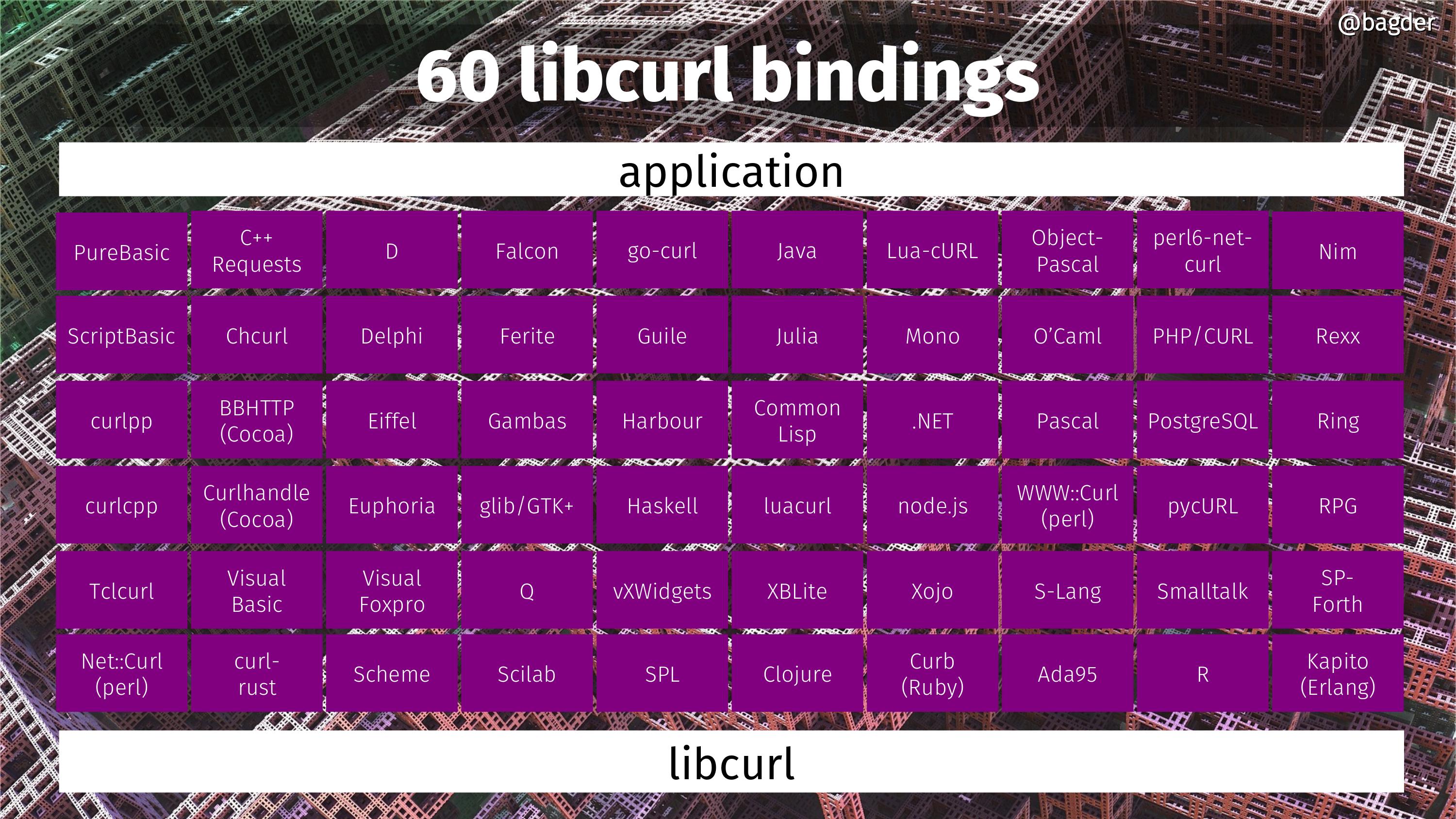
Users found the library useful and increased the curl uptake. One of the first early adopters of libcurl was the PHP language, which decided to use libcurl as their default HTTP/URL transfer engine.
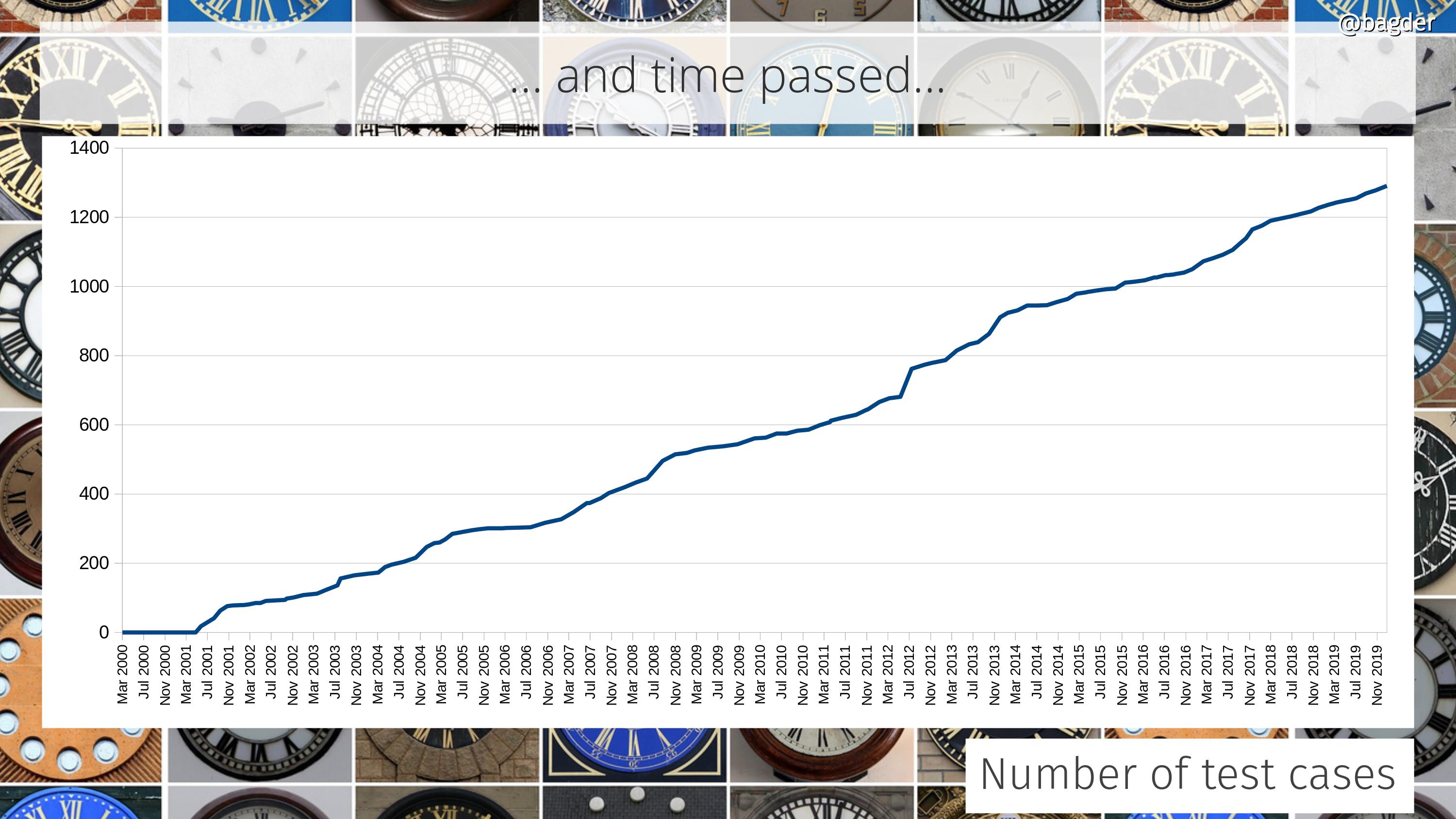
We created the first test suite.
2001
We changed the license and offered curl under the new curl license (effectively MIT) as well as MPL. The idea to slightly modify the curl license was a crazy one, but the reason for that has been forgotten.
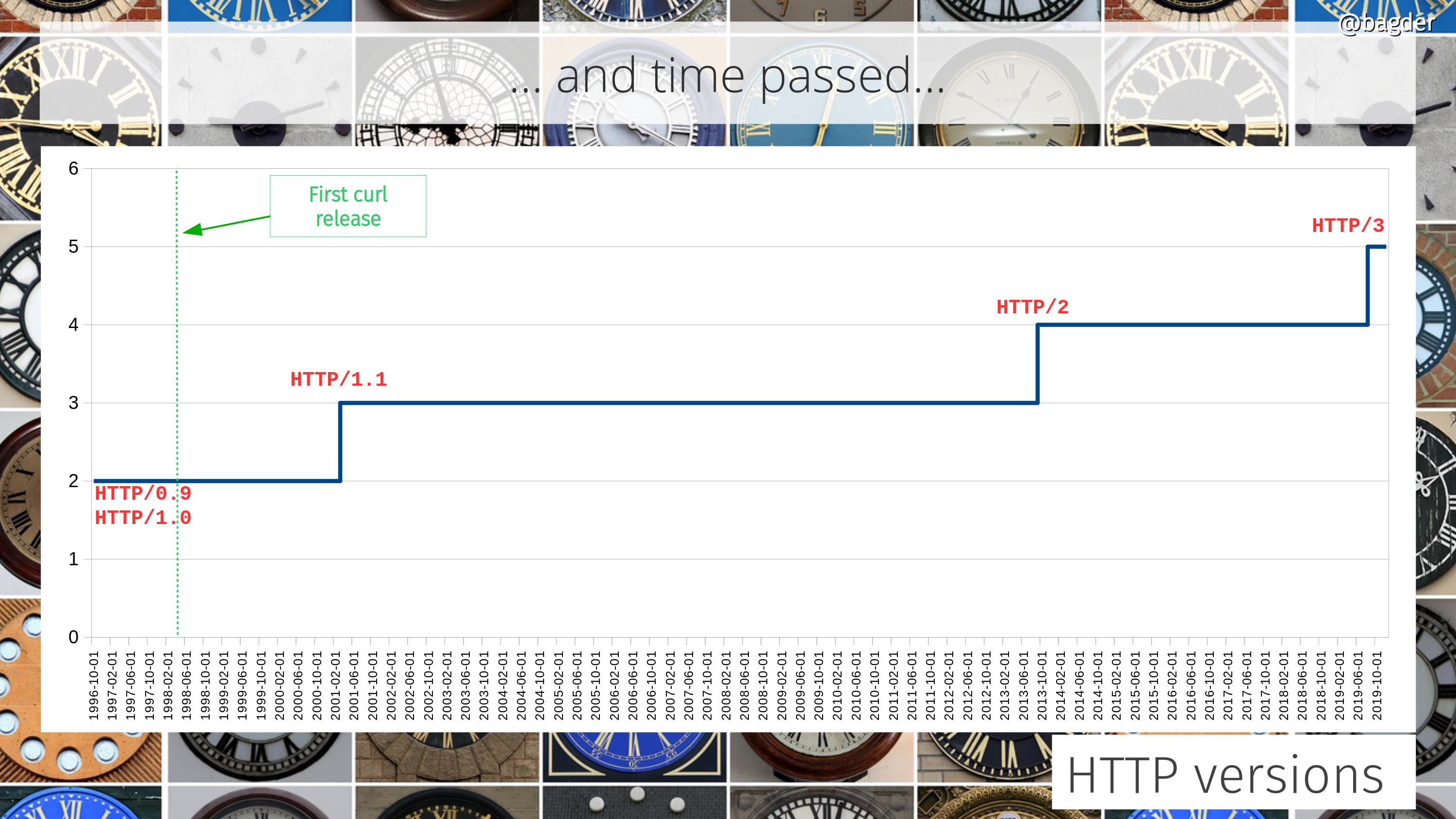
We added support for HTTP/1.1 and IPv6.

In June, the THANKS file counted 67 named contributors. This is a team effort. We surpassed 1,100 total commits in March and in July curl was 20,000 lines of code.
Apple started bundling curl with Mac OS X when curl 7.7.2 shipped in Mac OS X 10.1.
2002
The test suite contained 79 test cases.
We dropped the MPL option. We would never again play the license change game.
We added support for gzip compression over HTTP and learned how to use SOCKS proxies.
2003
The curl “autobuild” system was introduced: volunteers run scripts on their machines that download, build and run the curl tests frequently and email back the results to our central server for reporting and analyses. Long before modern CI systems made these things so much easier.
We added support for Digest, NTLM and Negotiate authentication for HTTP.

In August we offered 40 individual man pages.
Support for FTPS was added, protocol number 9.
My first child, Agnes, was born.
I forked the ares project and started the c-ares project to provide and maintain a library for doing asynchronous name resolves – for curl and others. This project has since then also become fairly popular and widely used.
2004
At the beginning of 2003, curl was 32,700 lines of code.
We made curl support “large files”, which back then meant supporting files larger than 2 and 4 gigabytes.
We implemented support for IDN, International Domain Names.
2005
GnuTLS become the second supported TLS library. Users could now select which TLS library they wanted their build to use.
Thanks to a grant from the Swedish “Internetfonden”, I took a leave of absence from work and could implement the first version of the multi_socket() API to allow applications to do more parallel transfers faster.
git was created and they quickly adopted curl for their HTTP(S) transfers.
TFTP became the 10th protocol curl supports.
2006
We decided to drop support for “third party FTP transfers” which made us bump the SONAME because of the modified ABI. The most recent such bump. It triggered some arguments. We learned how tough bumping the SONAME can be to users.
The wolfSSL precursor called cyassl became the third SSL library curl supported.
We added support for HTTP/1.1 Pipelining and in the later half of the year I accepted a contract development work for Adobe and added support for SCP and SFTP.
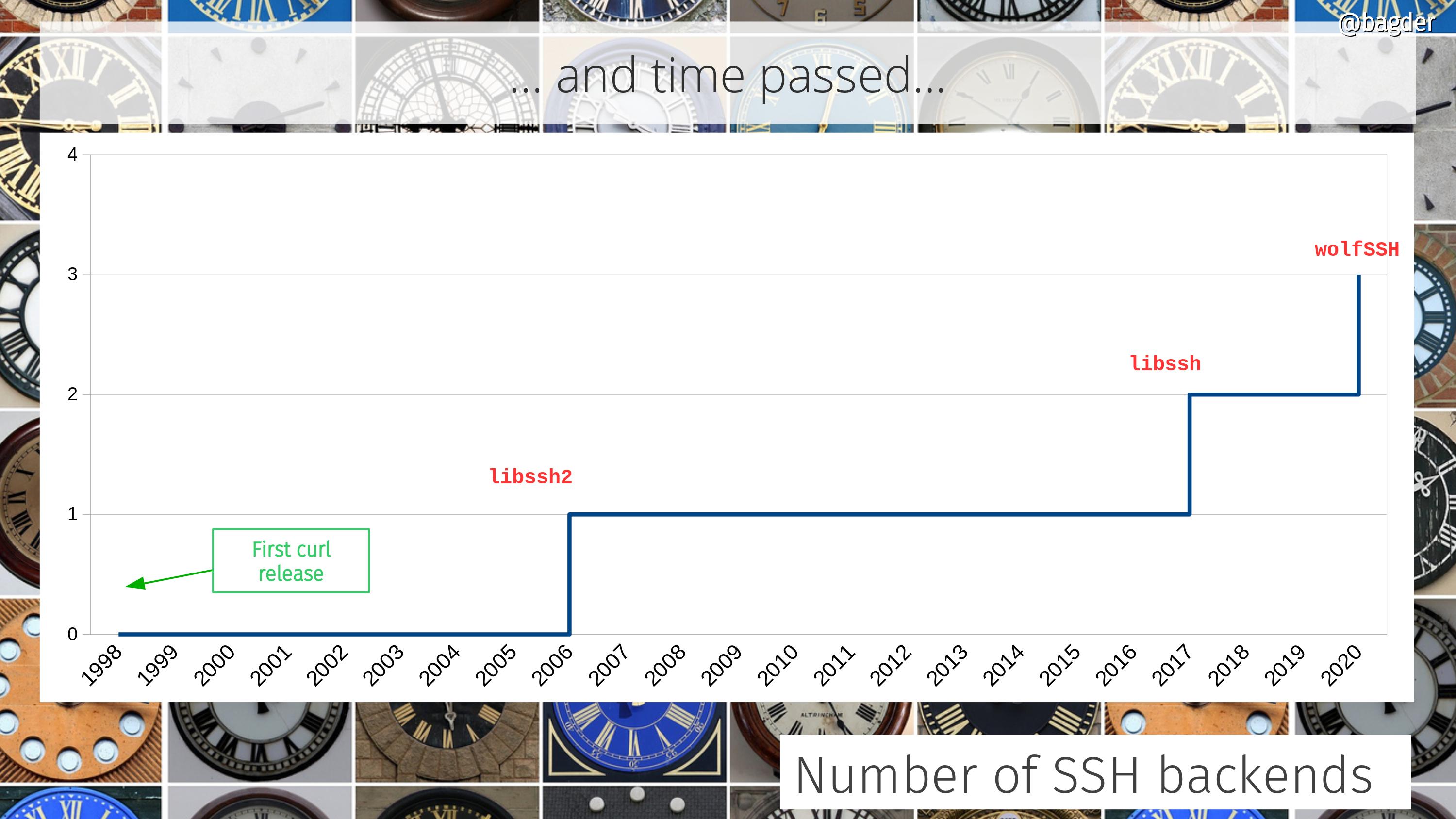
As part of the SCP and SFTP work, I took a rather big step into and would later become maintainer of the libssh2 project. This project is also pretty widely used.
I had a second child, my son Rex.
2007
Now at 51,500 lines of code we added support for a fourth SSL library: NSS
We added support for LDAPS and the first port to OS/400 was merged.
For curl 7.16.1 we added support for --libcurl. Possibly my single favorite curl command line option. Generate libcurl-using source code repeating the command line transfer.
In April, curl had 348 test cases.
2008
By now the command line tool had grown to feature 126 command line options. A 5x growth during curl’s ten first years.
In March we surpassed 10,000 commits.
I joined the httpbis working group mailing list and started slowly to actively participate within the IETF and the work on the HTTP protocol.
Solaris ships curl and libcurl. The Adobe flash player on Linux uses libcurl.
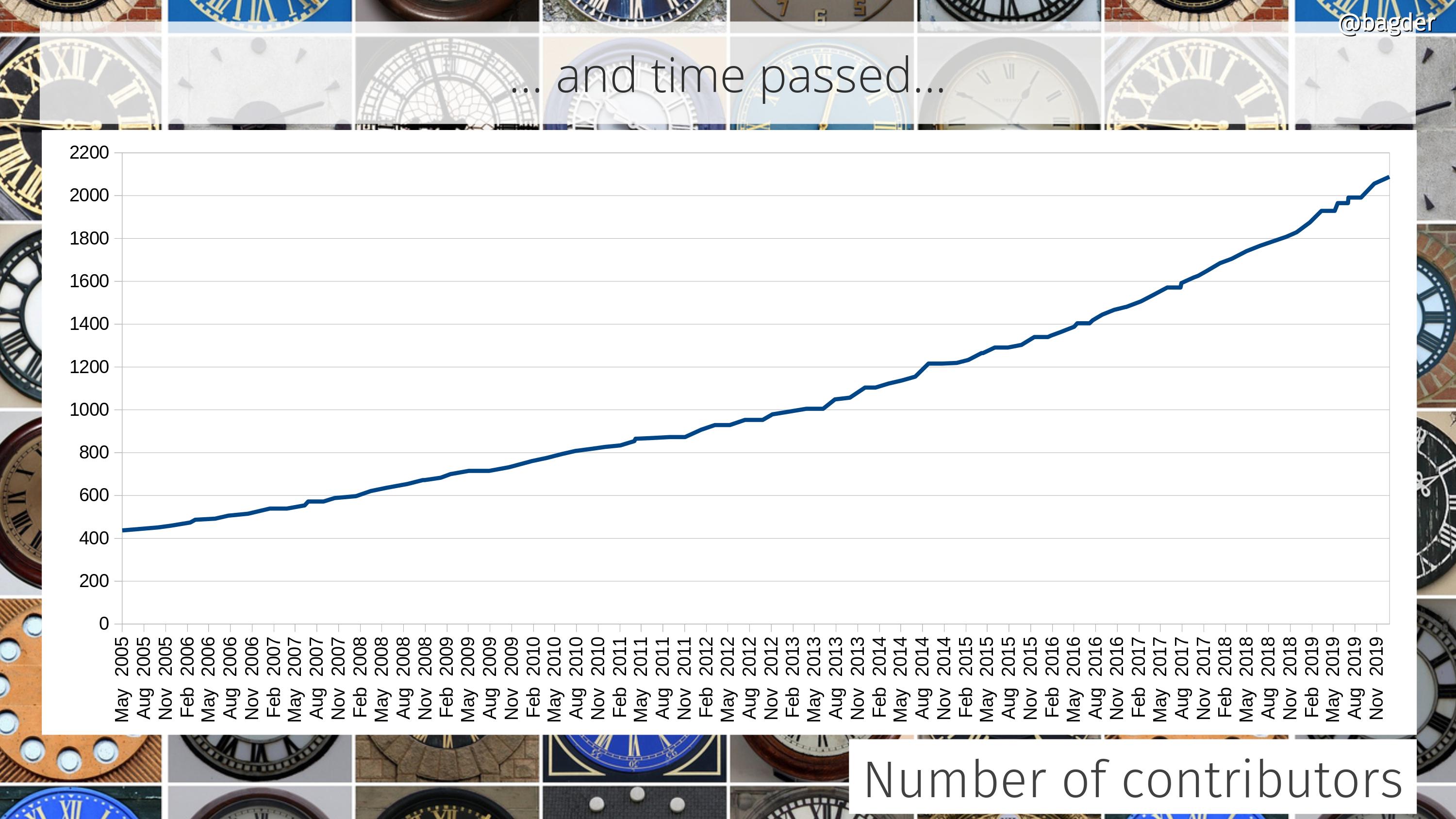
In September the total count of curl contributors reached 654.
2009

On FLOSS Weekly 51, I talked about curl on a podcast for the first time.
We introduced support for building curl with cmake. A decision that is still being discussed and questioned if it actually helps us. To make the loop complete, cmake itself uses libcurl.
In July the IETF 75 meeting was held in Stockholm, my home town, and this was the first time I got to physically meet several of my personal protocol heroes that created and kept working on the HTTP protocol: Mark, Roy, Larry, Julian etc.
In August, I quit my job to work for my own company Haxx, but still doing contracted development. Mostly doing embedded Linux by then.
Thanks to yet another contract, I introduced support for IMAP(S), SMTP(S) and POP3(S) to curl, bumping the number of supported protocols to 19.
I was awarded the Nordic Free Software Award 2009. For my work on curl, c-ares and libssh2.
2010
We added support for RTSP, and RTMP(S).
PolarSSL became the 6th supported SSL library.

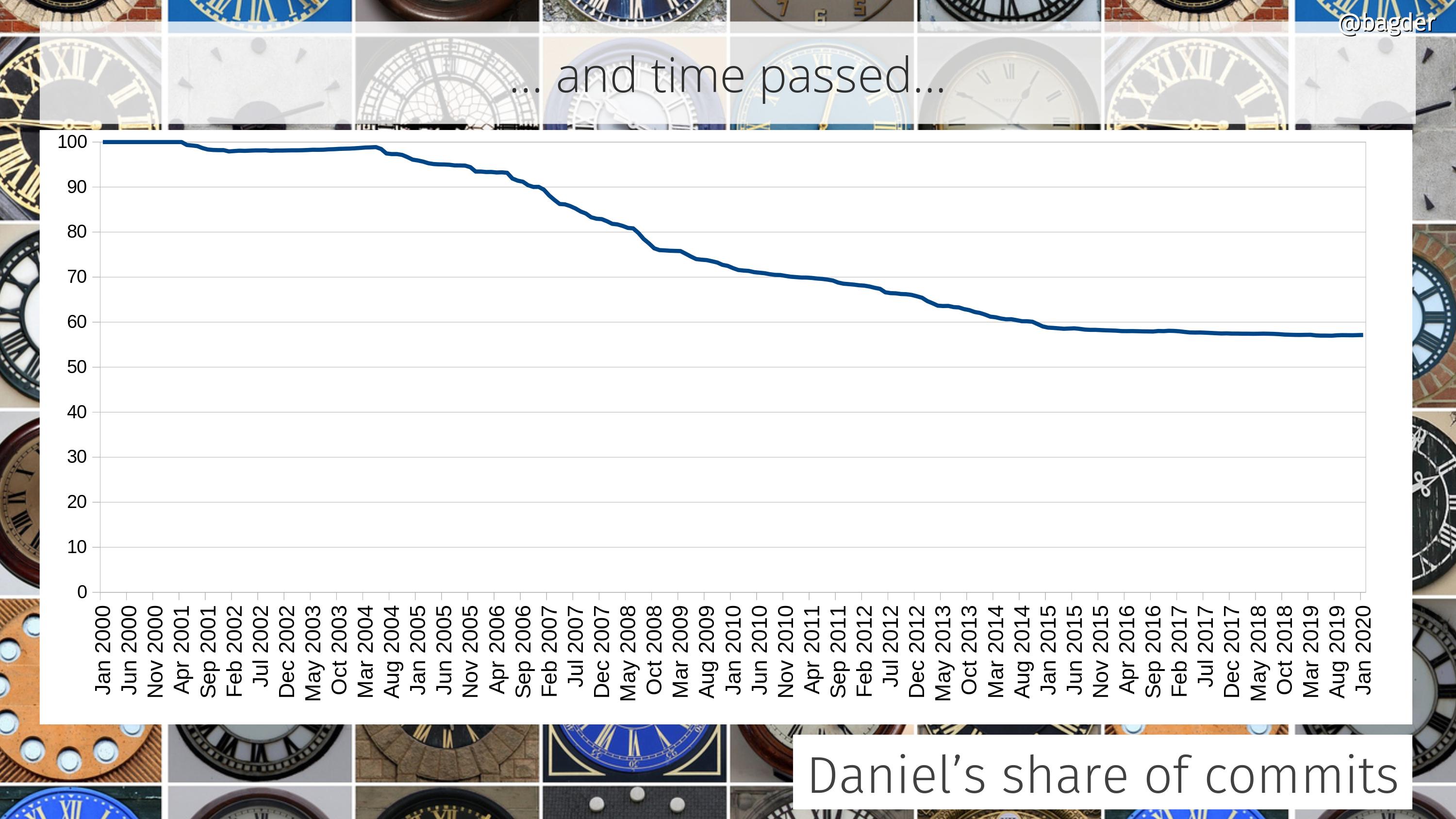
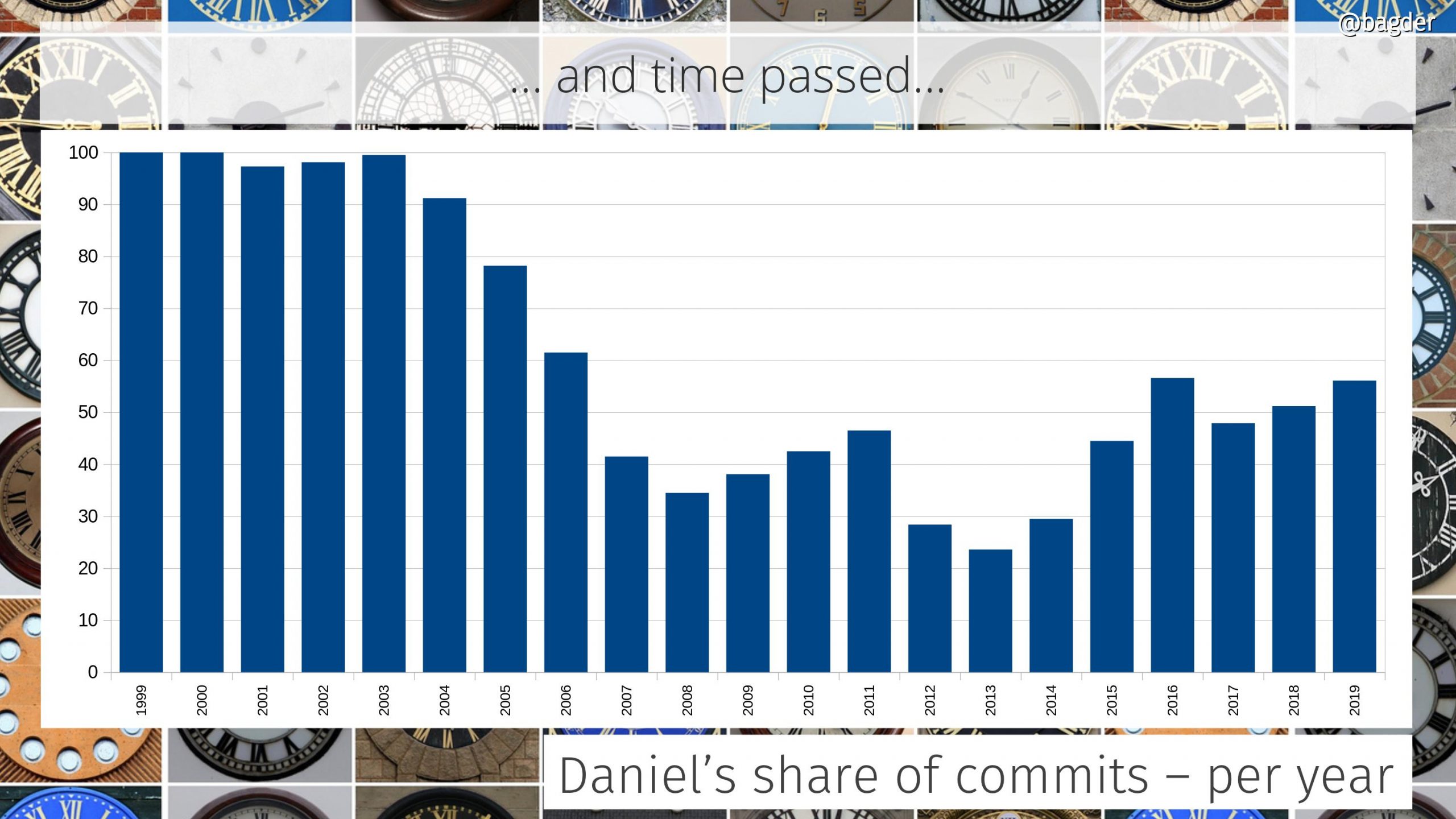
We switched version control system from CVS to git and at the same time we switched hosting from Sourceforge to GitHub. From this point on we track authorship of commits correctly and appropriately, something that was much harder to do with CVS.
Added support for the AxTLS library. The 7th.
2011
Over 80,000 lines of code.
The cookie RFC 6265 shipped. I was there and did some minor contributions for it.
We introduced the checksrc script that verifies that source code adheres to the curl code style. Started out simple, has improved and been made stricter over time.

I got a thank you from Googlers which eventually landed me some Google swag.
We surpassed 100 individual committers.
2012
149 command line options.
Added support for Schannel and Secure Transport for TLS.
When I did an attempt at a vanity count of number of curl users, I ended up estimating they were 550 million. This was one of the earlier realizations of mine that man, curl is everywhere!
During the entire year of 2012, there were 67 commit authors.
2013
Added support for GSKit, a TLS library mostly used on OS/400. The 10th supported TLS library.
In April the number of contributors had surpassed 1,000 and we reached over 800 test cases.
We refactored the internals to make sure everything is done non-blocking and what we call “use multi internally” so that the easy interface is just a wrapper for a multi transfer.
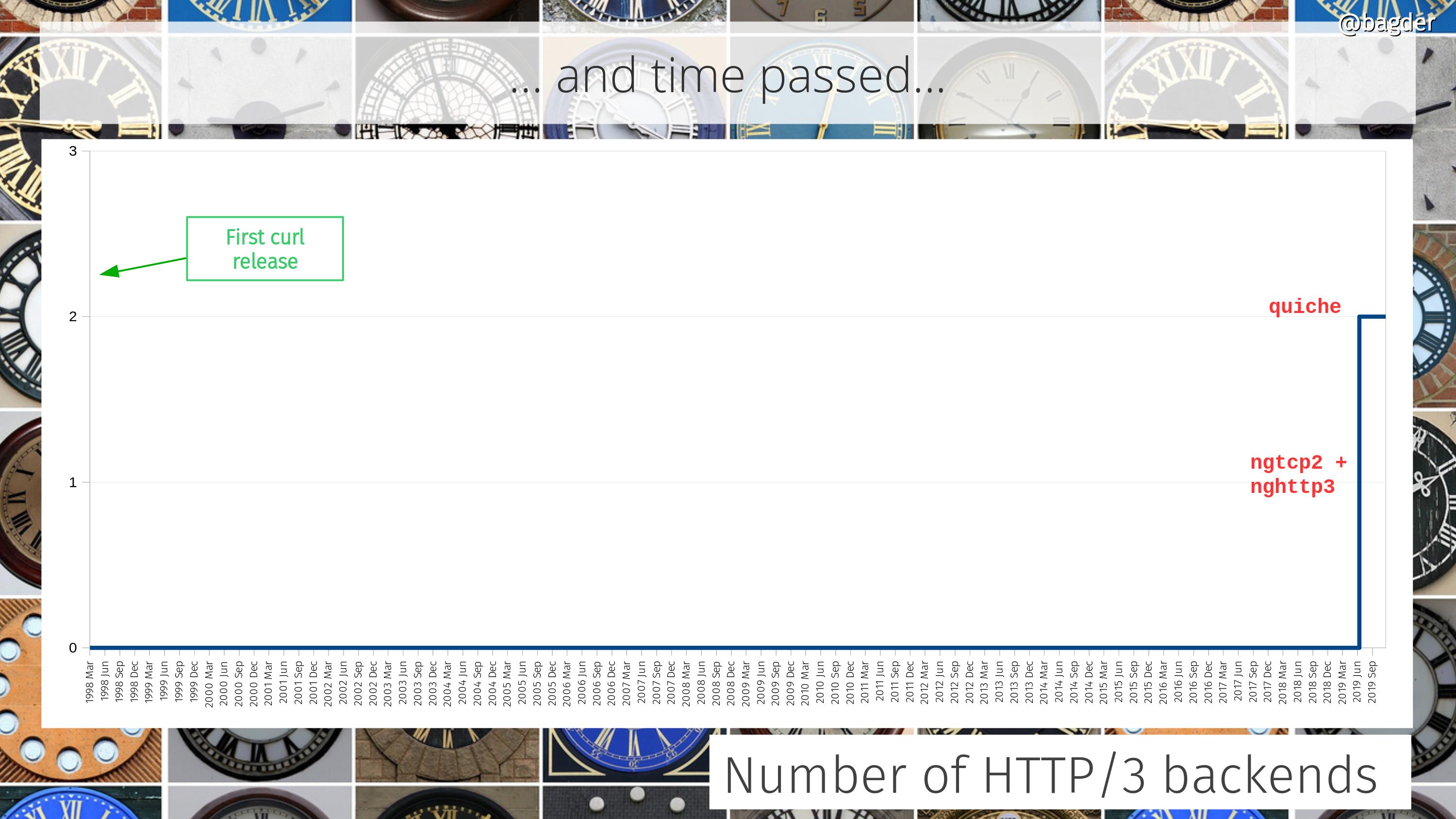
The initial attempts at HTTP/2 support were merged (powered by the great nghttp2 library) as well as support for doing connects using the Happy Eyeballs approach.
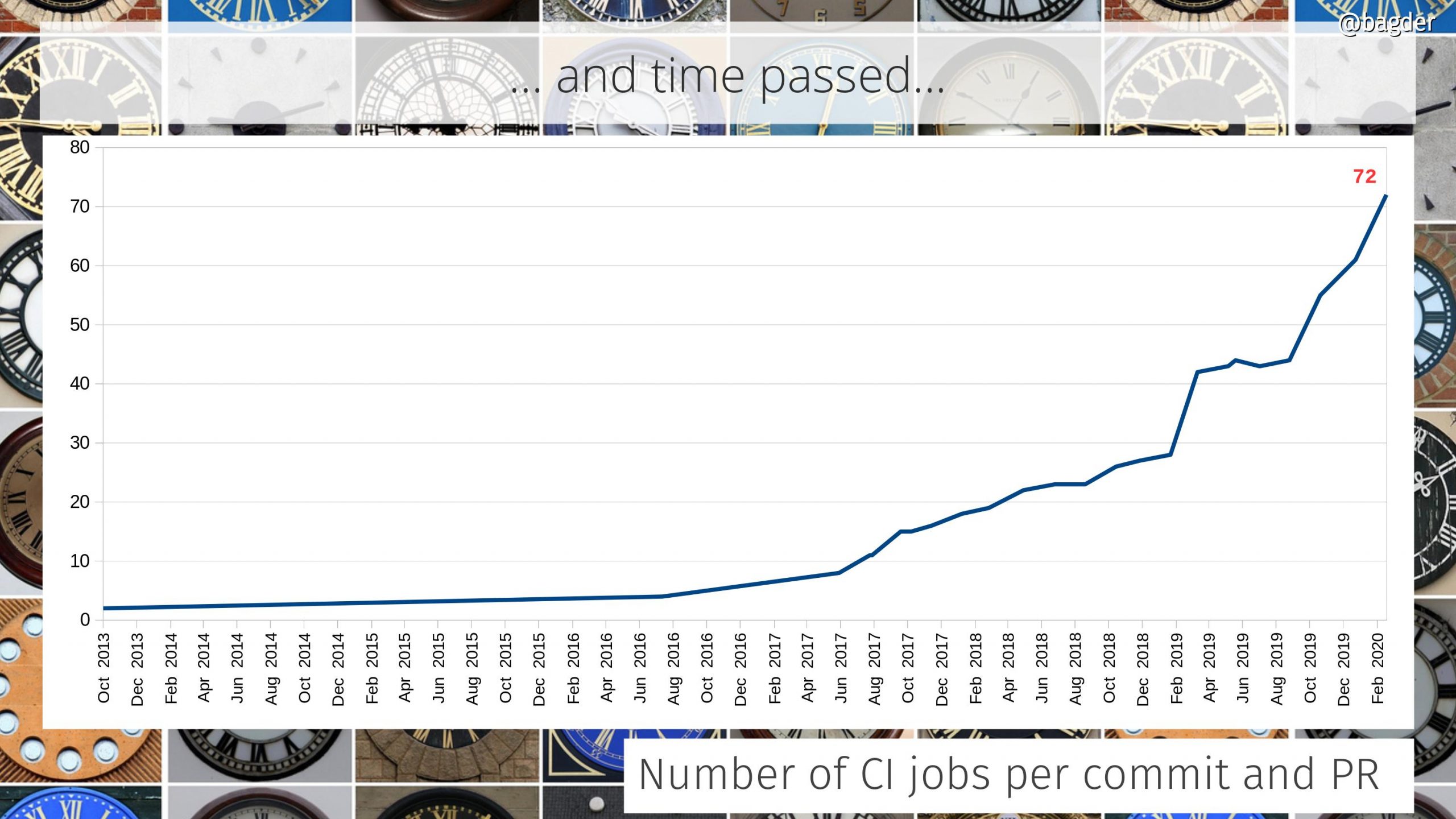
We created our first two CI jobs.
2014

I started working for Mozilla in the Firefox networking team, remotely from my house in Sweden. For the first time in my career, I would actually work primarily with networking and HTTP etc with a significant overlap with what curl is and does. Up until this point, the two sides of my life had been strangely separated. Mozilla allowed me to spend some work hours on curl.
At 161 command line options and 20 reported CVEs.
59 man pages exploded into 270 man pages in July when every libcurl option got its own separate page.
We added support for the libressl OpenSSL fork and removed support for QsoSSL. Still at 10 supported TLS libraries.
In September, there was 105,000 lines of code.
Added support for SMB(S). 24 protocols.
2015
Added support for BoringSSL and mbedTLS.
We introduced support for doing proper multiplexed transfers using HTTP/2. A pretty drastic paradigm change in the architecture when suddenly multiple transfers would share a single connection. Lots of refactors and it took a while until HTTP/2 support got stable.
It followed by our first support for HTTP/2 server push.
We switched over to the GitHub working model completely, using its issue tracker and doing pull-requests.
The first HTTP/2 RFC was published in May. I like to think I contributed a little bit to the working group effort behind it.
My HTTP/2 work this year was in part sponsored by Netflix and it was a dance to make that happen while still employed by and working for Mozilla.
20,000 commits.
I started writing everything curl.
We also added support for libpsl, using the Public Suffix List for better cookie handling.
2016
curl switched to using HTTP/2 by default for HTTPS transfers.
In May, curl feature 185 command line options.
We got a new logo, the present one. Designed by Adrian Burcea at Soft Dreams.
Added support for HTTPS proxies and TLS 1.3.
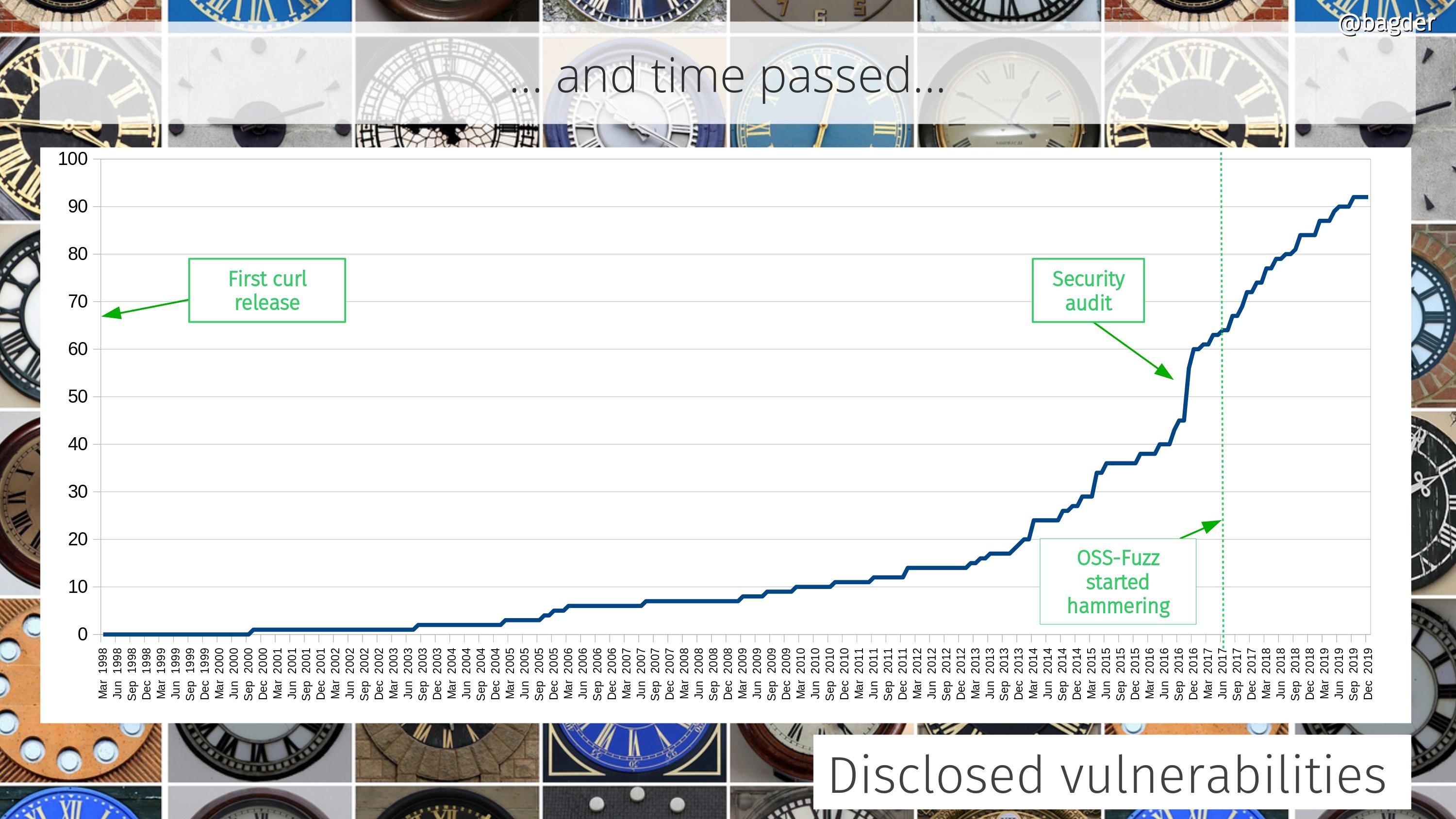
curl was audited by Cure 53.
A Swedish tech site named me 2nd best developer in Sweden. Because of my work on curl.
At 115,500 lines of code at the end of the year.
2017
curl got support for building with and using multiple TLS libraries and doing the choice of which to use at start-up.
Fastly reached out and graciously and generously started hosting the curl website as well as my personal website. This help putting the end to previous instabilities when blog posts got too popular for my site to hold up and it made the curl site snappier for more people around the globe. They have remained faithful sponsors of the project ever since.

In the spring of 2017, we had our first ever physical developers conference, curl up, as twenty something curl fans and developers went to Nuremberg, Germany to spend a weekend doing nothing but curl stuff.
In June I was denied traveling to the US. This would subsequently take me on a prolonged and painful adventure trying to get a US visa.
The first SSLKEYLOGFILE support landed, we introduced the new MIME API and support for brotli compression.
The curl project was adopted into the OSS-Fuzz project, which immediately started to point out mistakes in our code. They have kept fuzzing curl nonstop since then.

In October, I was awarded the Polhem Prize. Sweden’s oldest and probably most prestigious engineering award. This prize was established and has been awarded since 1876. A genuine gold medal, handed over to me by no other than his majesty the king of Sweden. The medal even has my name engraved.
2018
Added support for DNS over HTTPS and the new URL API was introduced to allow applications to parse URLs the exact same way curl does it.
I joined the Changelog podcast and talked about curl turning 20.
Microsoft started shipping curl bundled with Windows. But the curl alias remains.
We introduced support for a second SSH library, so now SCP and SFTP could be powered by libssh in addition to the already supported libssh2 library.
We added support for MesaLink but dropped support for AxTLS. At 12 TLS libraries.
129,000 lines of code. Reached 10,000 stars on GitHub.
To accept a donation it was requested we create an account with Open Collective, and so we did. It has since been a good channel for the project to receive donations and sponsorships.
In November 2018 it was decided that the HTTP-over-QUIC protocol should officially become HTTP/3.
At 27 CI jobs at the end of the year. Running over 1200 test cases.
2019
I started working for wolfSSL, doing curl full-time. It just took 21 years to make curl my job.
We added support for Alt-Svc and we removed support for the always so problematic HTTP/1.1 Pipelining.
We introduced our first curl bug bounty program and we have effectively had a bug bounty running since. In association with hackerone. We have paid almost 50,000 USD in reward money for 45 vulnerabilities (up to Feb 2023).
Added support for AmiSSL and BearSSL: at 14 libraries.
We merged initial support for HTTP/3, powered by the quiche library, and a little later also with a second library: ngtcp2. Because why not do many backends?
We started offering curl in an “official” docker image.
2020
The curl tool got parallel transfer powers, the ability to output data in JSON format with -w and the scary --help output was cleaned up and arranged better into subcategories.
In March, for curl 7.69.0, I started doing release video presentations, live-streamed.
The curl website moved to curl.se and everything curl moved over to the curl.dev domain.
MQTT become the 25th supported protocol.
The first support for HSTS was added, as well as support for zstd compression.
wolfSSH became the third supported SSH library.
We removed support for PolarSSL.
Initial support for hyper as an alternative backend for HTTP/1 and HTTP/2.
In November, in the middle of Covid, I finally got a US visa.
The 90th CI job was created just before the end of the year.
2021
Dropped support for MesaLink but added support for rustls. At 13 TLS libraries.

Ingenuity landed on Mars, and curl helped it happen.
Received a very unpleasant death threat over email from someone deeply confused, blaming me for all sorts of bad things that happened to him.
Reached 20,000 stars on GitHub.
Supports GOPHERS. 26 protocols.
187 individuals authored commits that were merged during the year.
2022
Merged initial support WebSocket (WS:// and WSS:// URLs) and a new API for handling it. At 28 protocols.
We added the --json command line option and libcurl got a new header API, which then also made the command line tool get new “header picking” ability added to -w. We also added --rate and --url-query.
The HTTP/3 RFC was published in June.

msh3 become the third supported HTTP/3 library.
Trail of Bits did a curl security audit, sponsored by OpenSSF.
The 212th curl release was done in December. Issue 10,000 was created on GitHub.
2023
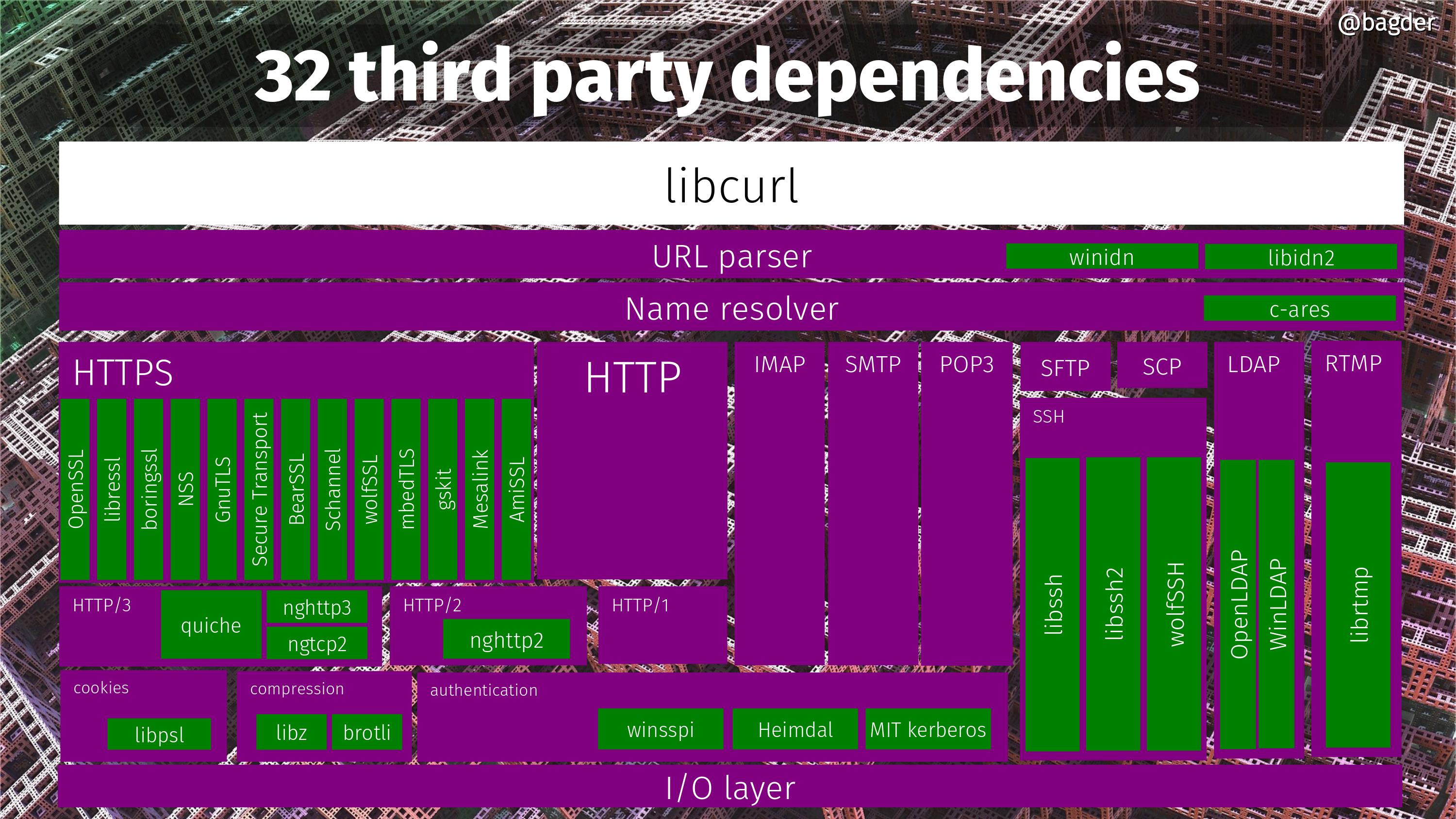
At the start of the year: 155,100 lines of code. 486 man pages. 1560 test cases. 2,771 contributors. 1,105 commit authors. 132 CVEs. 122 CI jobs. 29,733 commits. 48,580 USD rewarded in bug-bounties. 249 command line options. 28 protocols. 13 TLS libraries. 3 SSH libraries. 3 HTTP/3 libraries.
Introduce support for HTTP/3 with fall-back to older versions, making it less error-prone to use it.
On March 13 we surpassed 30,000 commits.
On March 20, we release curl 8.0.0. Exactly 25 years since the first curl release.
Staying relevant
Over the last 25 years we have all stopped using and forgotten lots of software, tools and services. Things come and go. Everything has its time and lots of projects simply do not keep up and gets replaced by something else at some point.
I like to think that curl is still a highly relevant software project with lots of users and use cases. I want to think that this is partly because we maintain it intensely and with both care and love. We make it do what users want it to do. Keep up, keep current, run the latest versions, support the latest security measures, be the project you would like to use and participate. Lead by example.
My life is forever curl tinted
Taking curl this far and being able to work full time on my hobby project is a dream come real. curl is a huge part of my life.

This said, curl is a team effort and it would never have taken off or become anything real without all our awesome contributors. People will call me “the curl guy” and some will say that it is “my” project, but everyone who has ever been close to the project knows that we are many more in the team than just me.
25 years
That day found httpget I was 26 years old. I was 27 by the time I shipped curl. I turned 52 last November.
I’ve worked on curl longer than I’ve worked for any company. None of my kids are this old. 25 years ago I did not live in my house yet. 25 years ago Google didn’t exist and neither did Firefox.
Many current curl users were not even born when I started working on it.

Beyond twenty-five
I feel obligated to add this section because people will ask.
I don’t know what the future holds. I was never good at predictions or forecasts and frankly I always try to avoid reading tea leaves. I hope to stay active in the project and to continue working with client-side internet transfers for as long as it is fun and people want to use the results of my work.
Will I be around in the project in another 25 years? Will curl still be relevant then? I don’t know. Let’s find out!