On Monday this week, I did a talk at the Nordic Software Security Summit conference in Stockholm Sweden. I titled it CVEMITRECVSSNVDCNAOSS WTF with the subtitle “Keeping the world from Burning”.
The talk was well received and I think it added something to the conversation. Almost every other talk during the rest of the conference that I saw referred back to it.
Since the talk was not recorded (no talks were at this event), I intend to do the presentation again – from home. This time live-streamed and recorded.
This happens on:
Monday September 30, 2024 14:00 UTC (16:00 CEST)
The stream happens on Twitch where I as always am curlhacker. Join the chatroom, ask questions, have a good time. There will of course be room for a Q&A.
No registration. No fee. Just show up.
At the conference, I did the presentation in under thirty minutes. This version might go on a few more minutes.
Abstract
The abstract I provided for this talk to the conference says:
Bogus CVEs, know-better organizations, conflicting databases, AI hallucinations, inflated severity scoring, security scanners, Jia Tan. As the lead developer in the curl project, Daniel describes some of the challenges involved and what you need to do to stay on top of security when working in a high profile Open Source project running in some twenty billion instances. The talk will be involving many examples from real life.
Differences
Since this is a second run of a talk I already did and I have no script, it will not be identical. I will also try to polish some minor details that I felt could need some brush-ups.
I decided to bump the minor version number again because there is a new option: --qtrim.
This is the old --trim option made simpler and specialized for query components only. When we added originally --trim, the idea was that it would be similar to --set and --get and be able to trim different components – but over time we have realized that the only component the trimming operation really makes sense for is query.
Hence, now we have the query trim option and the old trim option is deprecated. The old option still works but is not advertised in the --help output.
Manpage
The trurl manpage now features a section describing the different URL components, how they work and some specific options that affect them. With examples.
The manpage has almost doubled in size compared to 0.15.1 and the nroff version is now over 800 lines long. All in the name of making sure every option and feature is understood properly.
Bugfixes
query normalization. When a name/value pair had a blank string on either side of the equals character, trurl messed it up.
user/password/options/fragment normalization. trurl now normalizes all these fields if provided.
lowercase %-encoding. In some instances trurl was not consistently using lowercase hexadecimal in its output.
Tests
I looked for white spots in the test suite: untested options and option combinations, and have worked to fill those voids. This release has around thirty new test cases and trurl is now verified using more than two hundred tests.
Welcome to this follow-up patch release, just a week after we shipped 8.10.0. A bunch of bugfixes.
Numbers
the 261th release 0 changes 7 days (total: 9,679) 24 bugfixes (total: 10,828) 50 commits (total: 33,259) 0 new public libcurl function (total: 94) 0 new curl_easy_setopt() option (total: 306) 0 new curl command line option (total: 265) 19 contributors, 7 new (total: 3,246) 9 authors, 1 new (total: 1,303) 0 security fixes (total: 158)
Download the new curl release from curl.se as always.
Release presentation
Bugfixes
These are the perhaps most important ones fixed this time:
fix configure –with-ca-embed. It could otherwise sometimes lead to an empty bundled CA store.
cmake: ensure CURL_USE_OPENSSL/USE_OPENSSL_QUIC are set in sync
cmake: fix MSH3 to appear on the feature list
runtests: accecpt ‘quictls’ as OpenSSL compatible. It would previously skip a few tests that are marked OpenSSL specific.
connect: store connection info when really done
fix FTP CRLF line endings for ASCII transfer regression. Perhaps most notably this problem was seen on directory listings, which are done using ASCII mode.
fix HTTP/2 end-of-stream handling when uploading data from stdin
http: make max-filesize check not count ignored bodies. Like in the case where a URL is redirected to a second place, the first URL might still provide a body that curl ignores.
fix AF_INET6 use outside of USE_IPV6. Made the build fail on systems without IPv6 support.
check that the multi handle is valid in curl_multi_assign. Perhaps not exactly libcurl’s responsibility, but we found at least one application that did this after the 8.10.0 upgrade.
on QUIC connects, keep on trying on draining server
request: correctly reset the eos_sent flag. When doing multiple HTTP/2 uploads using the same handle – this caused problems for git.
transfer: fix sendrecv() without interim poll. An optimization that optimized a little too much… Most commonly this problem was seen with PHP programs that often (but unwisely) skip the polling.
rustls: fixed minor logic bug in default cipher selection
rustls: support strong CSRNG data. Now every curl build using TLS ensures use of strong random numbers.
trurl is slowing growing up and maturing. This is a minor patch release following up the previous one done just a few weeks ago, fixing a few annoying bugs only.
The query parameter normalization introduced in 0.15 did not properly handle query pairs when one of the sides of the ‘=’ was blank.
Make the generated manpage “source” to use the version number, not the title – which should be plain trurl.
A minuscule escaping mistake in the manual markdown made the output render wrongly.
Only install the manpage for ‘make install’ if there really is a manpage present – since it is generated and bundled in the release tarball it is not necessary present when users build their own
Future
I have this feeling that we still have use cases and combinations that we don’t have tested in the test suite so we probably need to do a few more minor or patch releases until we are ready to bump this baby to 1.0.
the 260th release 18 changes 42 days (total: 9,672) 245 bugfixes (total: 10,804) 461 commits (total: 33,209) 0 new public libcurl function (total: 94) 0 new curl_easy_setopt() option (total: 306) 2 new curl command line option (total: 265) 57 contributors, 28 new (total: 3,239) 27 authors, 14 new (total: 1,302) 1 security fixes (total: 158)
Download the new curl release from curl.se as always.
Release presentation
Security
CVE-2024-8096: OCSP stapling bypass with GnuTLS When curl is told to use the Certificate Status Request TLS extension, often referred to as OCSP stapling, to verify that the server certificate is valid, it might fail to detect some OCSP problems and instead wrongly consider the response as fine.
support for setting TLS version and ciphers for Rustls
stop offering ALPN http/1.1 for http2-prior-knowledge
support for sslcert/sslkey blob options for wolfSSL
release tarball 100% reproducible. We also provide verify-release a convenient shell script allowing anyone and everyone to easily verify curl release tarballs.
Bugfixes
See the full changelog for the complete list. Here follows my favorite subset:
build: add poll() detection for cross-builds
cmake: 40+ bugfixes
configure: fail if PSL is not disabled but not found
runtests: remove “has_textaware”
curl: find curlrc in XDG_CONFIG_HOME without leading dot
curl: make the progress bar detect terminal width changes
curl: bump maximum post data size in memory to 16GB
bearssl/mbedtls/rustls/wolfssl: fix setting tls version
gnutls/wolfssl: improve error message when certificate fails
gnutls: send all data
openssl: certinfo errors now fail correctly
sectransp: fix setting tls version
x509asn1: raise size limit for x509 certification information
ftp: always offer line end conversions
ftp: fix pollset for listening
http2: improved upload eos handling
idn: support non-UTF-8 input under AppleIDN
ngtcp2: use NGHTTP3 prefix instead of NGTCP2 for errors in h3 callbacks
pop3: fix multi-line responses
managen: fix superfluous leading blank line in quoted sections. Nicer HTML version of the manpages.
managen: in man output, remove the leading space from examples
managen: wordwrap long example lines in ASCII output. Nicer curl --manual and -h output.
manpage: ensure a maximum width for the text version.
connect: always prefer ipv6 in IP eyeballing
aws_sigv4: fix canon order for headers with same prefix
cf-socket: prevent KEEPALIVE_FACTOR being set to 1000 for Windows
rand: only provide weak random when needed
sigpipe: init the struct so that first apply ignores
Date: September 5, 2024 Time: 17:00 UTC (19:00 CEST, 10:00 PDT)
Everyone uses curl, the Swiss army knife of Internet transfers. While this tool has performed transfers and provided and a solid set of command line options for decades, new ones are added over time.
This talk goes through and focuses on some of the most powerful and interesting additions to curl done in recent years. The perhaps lesser known curl tricks that might enrich your command lines, extend your “tool belt” and make you more productive. Also trurl, the recently created companion tool for URL manipulations you maybe did not yet realize you need.
This presentation might just help you curl better.
The presentation will be followed by a Q&A session for all your curl questions.
You can select which one to view/attend. On the Zoom call, you will be able to ask questions via voice and on both you can ask questions via text/chat.
The Zoom version must be signed-up for to attend. The Twitch version you can just show up to.
This is episode four in my mini-series about shiny new features in the upcoming curl 8.10.0 release.
One of the most commonly used curl command line options is the dash capital O (-O) which also is known as dash dash remote-name (--remote-name) in its long form.
This option tells curl to create a local file using the name from the filename part of the provided URL when downloading. I.e. when you tell curl
curl -O https://example.com/file.html
This command line conveniently creates a local file called file.html in which it saves the downloaded data.
The -O option has been supported with this functionality since curl first shipped, in March 1998. An important point here is that it picks the name from the URL so that a user can tell what filename it creates. No surprises. The remote server is not involved in naming it.
What about no filename scenarios?
URLs do not necessarily need to have filename parts. Like these examples:
Since there are no filename parts in these URLs, they used to cause curl to refuse to operate with -O and instead return error. curl could not create a local filename to use:
$ curl -O http://example.com/ curl: Remote filename has no length curl: (23) Failed writing received data to disk/application
Trying harder
Starting in curl 8.10.0, curl works a little harder to come up with a filename to store the download in when -O is used. While there is no filename part in the URL, the user did ask curl to download the URL to a local file so it now tries a few extra steps:
Use the filename part from the URL if there is one, like before.
If there is no filename but there is a path provided in the URL, extract the right-most directory name from the URL and use as filename.
If there is neither a filename nor a path in the URL, curl uses a default, fixed, filename as a final backup: curl_response. This name intentionally has no extension because curl has no idea what data that will come and using an extension could mislead users into believing it says something about the type of content.
Several people have insisted that index.html would be better and sensible default file name. I cannot agree with that, since it might just as well be an image or a tarball of your favorite open source project. I think naming such a file index.html would be more misleading than simply sticking to the neutral curl_response.
Let me give you a little table showing what filenames that will be used with curl -O and a given set of URLs:
URL
local filename
http://example.com/one.html
one.html
http://example.com/one.html?clues=no
one.html (curl ignores the query part)
http://example.com/one/two/?id=42
two (because it is the right-most directory piece)
http://example.com/path/
path (because it is the right-most directory piece)
http://example.com/
curl_response (because no filename nor directory to use)
Find out which name
You can use curl’s -w, –write-out option and its %{filename_effective} variable to learn exactly which name that was used.
Prefer another name?
There is always the -o (lowercase o) option that lets you specify whatever filename you like. You do not have to let curl pick the filename for you.
Clobber or not
curl will by default overwrite, clobber if you will, any previously existing file using the same name. If you rather curl took a more careful approach, consider using –no-clobber in your command lines. It makes curl pick an alternative filename if the chosen one already exists when curl is about to download data into a local file.
This new command line option in curl 8.10.0 is a simple one that has been requested by users repeatedly over the years so I figure it was about time we actually provide it.
If the target file already exists on disk, skip downloading it.
It is exactly as simple as that. No date check, no size check, no checking if the file is even what you want it to be. If the target file is present and exists that is a signal enough that the file should not be downloaded; to skip the transfer.
A real-world command line using this feature could then look like this:
To avoid a previous broken download remainder to linger around and cause future transfers to get skipped, remember that curl also has a –remove-on-errror option.
Ships
In curl 8.10.0, on September 11, 2024.
Image
From a movie with a suitable if even perhaps subtle reference.
I received an email today. What follows is a slightly edited version (for brevity).
From: DOE Attestation <doe.attestation@hq.doe.gov> Subject: [ACTION REQUIRED] U.S. Department of Energy Secure Software Development Attestation Submission Request
OMB Control No. 1670-0052 Expires: 03/31/2027
Hello Haxx
** The following communication contains important DOE Secure Software Development Attestation Submission instructions. Please read this communication in its entirety. **
The U.S. Department of Energy (DOE) has identified your company's software as affected by this request. The list of impacted software products and versions can be found below.
DOE Request:
In support of the Office of Management and Budget (OMB) requirement to collect attestations per M-22-18, please complete the U.S. Department of Energy Secure Software Development Attestation Form (DOE Common Form). If you are unable to attest to all secure software development framework (SSDF) practices, please be sure to attach your Plan of Action and Milestones (POA&M). The software listed below has been identified as being associated with your company and requires DOE to collect an attestation for the software.
Product Name Version Number
libcurl 8.3
The U.S. Department of Energy Secure Software Development Attestation Form (DOE Common Form) can be found at DOE F 205.2 Secure Software Development Attestation Form. The DOE Common Form identifies the minimum secure software development requirements a Software Producer must meet, and attest to meeting, before software subject to the requirements of M-22-18 as updated by M-23-16, may be used by Federal agencies. This form is used by Software Producers to attest that the software they produce is developed in conformity with specified secure software development practices and standards.
Regards,
DOE OCIO C-SCRM Team
Don’t you just love the personal touch in the signature in the end?
I could add that I have never been in contact with them before. I did not know they use libcurl before this email. I do not know what they use it for.
I find it amusing they insist this is “required” .
My response
I am not impossible and I will not deny them this information. So I pressed reply and immediately sent an answer back.
Hello Department of Energy,
I cannot find that you are an existing customer of ours, so we cannot fulfill this request.
libcurl is a product we work on. It is open source and licensed under an MIT-like license in which the distribution and use conditions are clearly stated.
If you contact support@wolfssl.com we can remedy this oversight and can then arrange for all the paperwork and attestations you need.
I have this tradition of mentioning occasional network related quirks on Windows on my blog so here we go again.
This round started with a bug report that said
curl is slow to connect to localhost on Windows
It is also demonstrably true. The person runs a web service on a local IPv4 port (and nothing on the IPv6 port), and it takes over 200 milliseconds to connect to it. You would expect it to take no less than a number of microseconds, as it does on just about all other systems out there.
The command
curl http://localhost:4567
Connecting
Buckle up, this is getting worse. But first, let’s take a look at this exact use case and what happens.
The hostname localhost first resolves to ::1 and 127.0.0.1 by curl. curl actually resolves this name “hardcoded”, so it does this extremely fast. Hardcoded meaning that it does not actually use DNS or any resolver functionality. It provides this result “fixed” for this hostname.
When curl has both IPv6 and IPv4 addresses to connect to and the host supports both IP families, it will first start the IPv6 attempt(s) and only if it did not succeed to connect over IPv6 after two hundred millisecond does it start the IPv4 attempts. This way of connecting is called Happy Eyeballs and is the de-facto and recommended way to connect to servers in a dual-stack since years back.
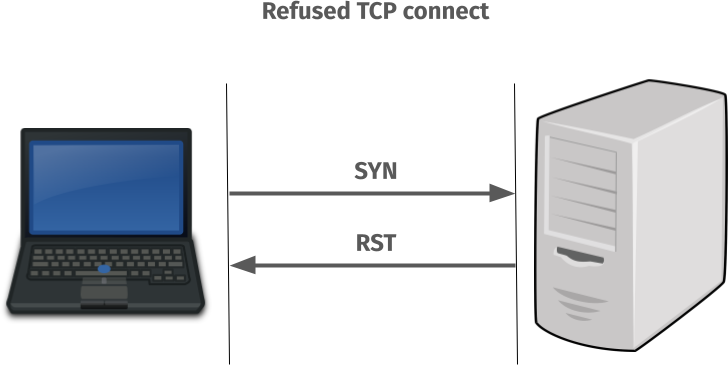
On all systems except Windows, where the IPv6 TCP connect attempt sends a SYN to a TCP port where nothing is listening, it gets a RST back immediately and returns failure. ECONNREFUSED is the most likely outcome of that.
On all systems except Windows, curl then immediately switches over to the IPv4 connect attempt instead that in modern systems succeeds within a small fraction of a millisecond. The failed IPv6 attempt is not noticeable to a user.
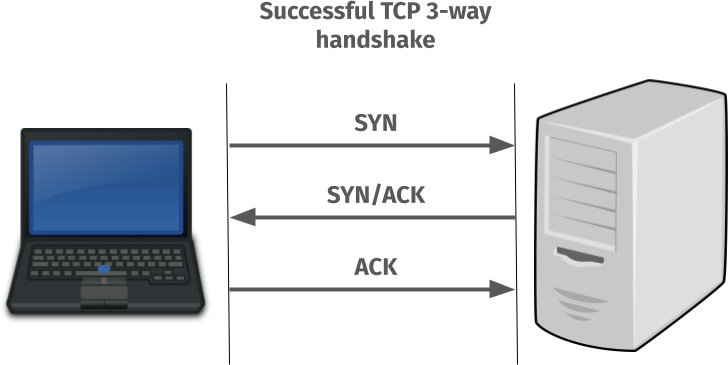
A TCP reminder
This is how a working TCP connect can be visualized like:
A successful TCP 3-way handshake
But when the TCP port in the server has no listener it actually performs like this
A refused TCP connect
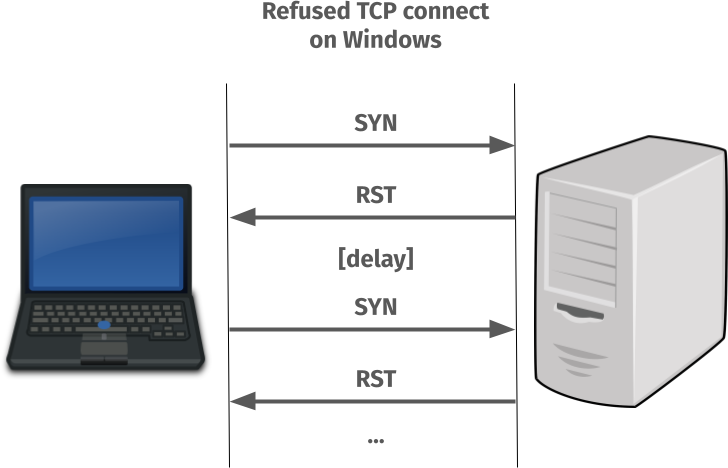
Connect failures on Windows
On Windows however, the story is different.
When the TCP SYN is sent to the port where nothing is listening and an RST is sent back to tell the client so, the client TCP stack does not return an error immediately.
Instead it decides that maybe the problem is transient and it will magically fix itself in the near future. It then waits a little and then keeps sending new SYN packets to see if the problem perhaps has fixed itself – until a maximum retry value is reached (set in the registry, this value defaults to 3 extra times).
Done on localhost, this retry-SYN process can easily take a few seconds and when done over a network, it can take even more seconds.
Since this behavior makes the leading IPv6 attempt not possible to fail within 200 milliseconds even when nothing is listening on that port, connecting to any service that is IPv4-only but has an IPv6 address by default delays curl’s connect success by two hundred milliseconds. On Windows.
Of course this does not only hurt curl. This is likely to delay connect attempts for countless applications and services for Windows users.
A refused TCP connect on Windows
Non-responding is different
I want to emphasize that there is a big difference when trying to connect to a host where the SYN packet is simply not answered. When the server is not responding. Because then it could be a case of the packet gotten lost on the way so then the TCP stack has to resend the SYN again a couple of times (after a delay) to see if it maybe works this time.
IPv4 and IPv6 alike
I want to stress that this is not an issue tied to IPv6 or IPv4. The TCP stack seems to treat connect attempts done over either exactly the same. The reason I even mention the IP versions is because how this behavior works counter to Happy Eyeballs in the case where nothing listens to the IPv6 port.
Is resending SYN after RST “right” ?
According to this exhaustive resource I found on explaining this Windows TCP behavior, this is not in violation of RFC 793. One of the early TCP specifications from 1981.
It is surprising to users because no one else does it like this. I have not found any other systems or TCP stacks that behave this way.
Fixing?
There is no way for curl to figure out that this happens under the hood so we cannot just adjust the code to error out early on Windows as it does everywhere else.
Workarounds
There is a registry key in Windows called TcpMaxConnectRetransmissions that apparently can be tweaked to change this behavior. Of course it changes this for all applications so it is probably not wise to do this without a lot of extra verification that nothing breaks.
The two hundred millisecond Happy Eyeballs delay that curl exhibits can be mitigated by forcibly setting –happy-eyballs-timeout-ms to zero.
If you know the service is not using IPv6, you can tell curl to connect using IPv4 only, which then avoids trying and wasting time on the IPv6 sinkhole: –ipv4.
Without changing the registry and trying to connect to any random server out there where nothing is listening to the requested port, there is no decent workaround. You just have to accept that where other systems can return failure within a few milliseconds, Windows can waste multiple seconds.
Windows version
This behavior has been verified quite recently on modern Windows versions.