Time for another checkup. Where are we right now with HTTP/3 support in curl for users?

I think curl’s situation is symptomatic for a lot of other HTTP tools and libraries. HTTP/3 has been and continues to be a much tougher deployment journey than HTTP/2 was.
curl supports four alternative HTTP/3 solutions
You can enable HTTP/3 for curl using one of these four different approaches. We provide multiple different ones to let “the market” decide and to allow different solutions to “compete” with each other so that users eventually can get the best one. The one they prefer. That saves us from the hard problem of trying to pick a winner early in the race.
More details about the four different approaches follow below.
Why is curl not using HTTP/3 already?
It already does if you build it yourself with the right set of third party libraries. Also, the curl for windows binaries provided by the curl project supports HTTP/3.
For Linux and other distributions and operating system packagers, a big challenge remains that the most widely used TLS library (OpenSSL) does not offer the widely accepted QUIC API that most other TLS libraries provide. (Remember that HTTP/3 uses QUIC which uses TLS 1.3 internally.) This lack of API prevents existing QUIC libraries to work with OpenSSL as their TLS solution forcing everyone who want to use a QUIC library to use another TLS library – because curl does not easily allows itself to get built using multiple TLS libraries . Having a separate TLS library for QUIC than for other TLS based protocols is not supported.
Debian tries an experiment to enable HTTP/3 in their shipped version of curl by switching to GnuTLS (and building with ngtcp2 + nghttp3).
HTTP/3 backends
To get curl to speak HTTP/3 there are three different components that need to be provided, apart from the adjustments in the curl code itself:
- TLS 1.3 support for QUIC
- A QUIC protocol library
- An HTTP/3 protocol library
Illustrated
Below, you can see the four different HTTP/3 solutions supported by curl in different columns. All except the right-most solution are considered experimental.
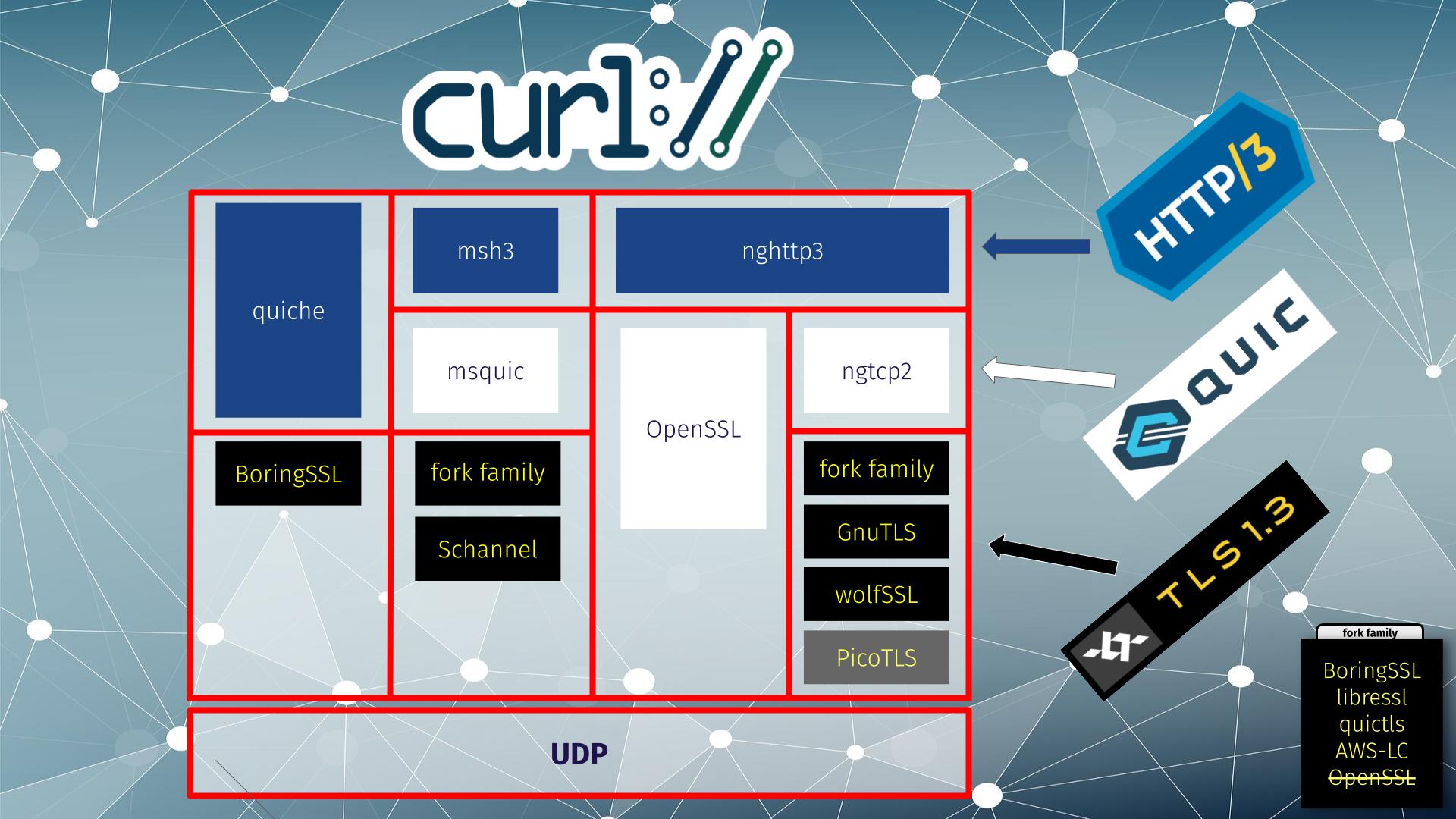
From left to right:
- the quiche library does both QUIC and HTTP/3 and it works with BoringSSL for TLS
- msh3 is an HTTP/3 library that uses mquic for QUIC and either a fork family or Schannel for TLS
- nghttp3 is an HTTP/3 library that in this setup uses OpenSSL‘s QUIC stack, which does both QUIC and TLS
- nghttp3 for HTTP/3 using ngtcp2 for QUIC can use a range of different TLS libraries: fork family, GnuTLS and wolfSSL. (picotls is supported too, but curl itself does not support picotls for other TLS use)
ngtcp2 is ahead
ngtcp2 + nghttp3 was the first QUIC and HTTP/3 combination that shipped non-beta versions that work solidly with curl, and that is the primary reason it is the solution we recommend.
The flexibility in TLS solutions in that vertical is also attractive as this allows users a wide range of different libraries to select from. Unfortunately, OpenSSL has decided to not participate in that game so this setup needs another TLS library.
OpenSSL QUIC
OpenSSL 3.2 introduced a QUIC stack implementation that is not “beta”. As the second solution curl can use. In OpenSSL 3.3 they improved it further. Since early 2024 curl can get built and use this library for HTTP/3 as explained above.
However, the API OpenSSL provide for doing transfers is lacking. It lacks vital functionality that makes it inefficient and basically forces curl to sometimes busy-loop to figure out what to do next. This fact, and perhaps additional problems, make the OpenSSL QUIC implementation significantly slower than the competition. Another reason to advise users to maybe use another solution.
We keep communicating with the OpenSSL team about what we think needs to happen and what they need to provide in their API so that we can do QUIC efficiently. We hope they will improve their API going forward.
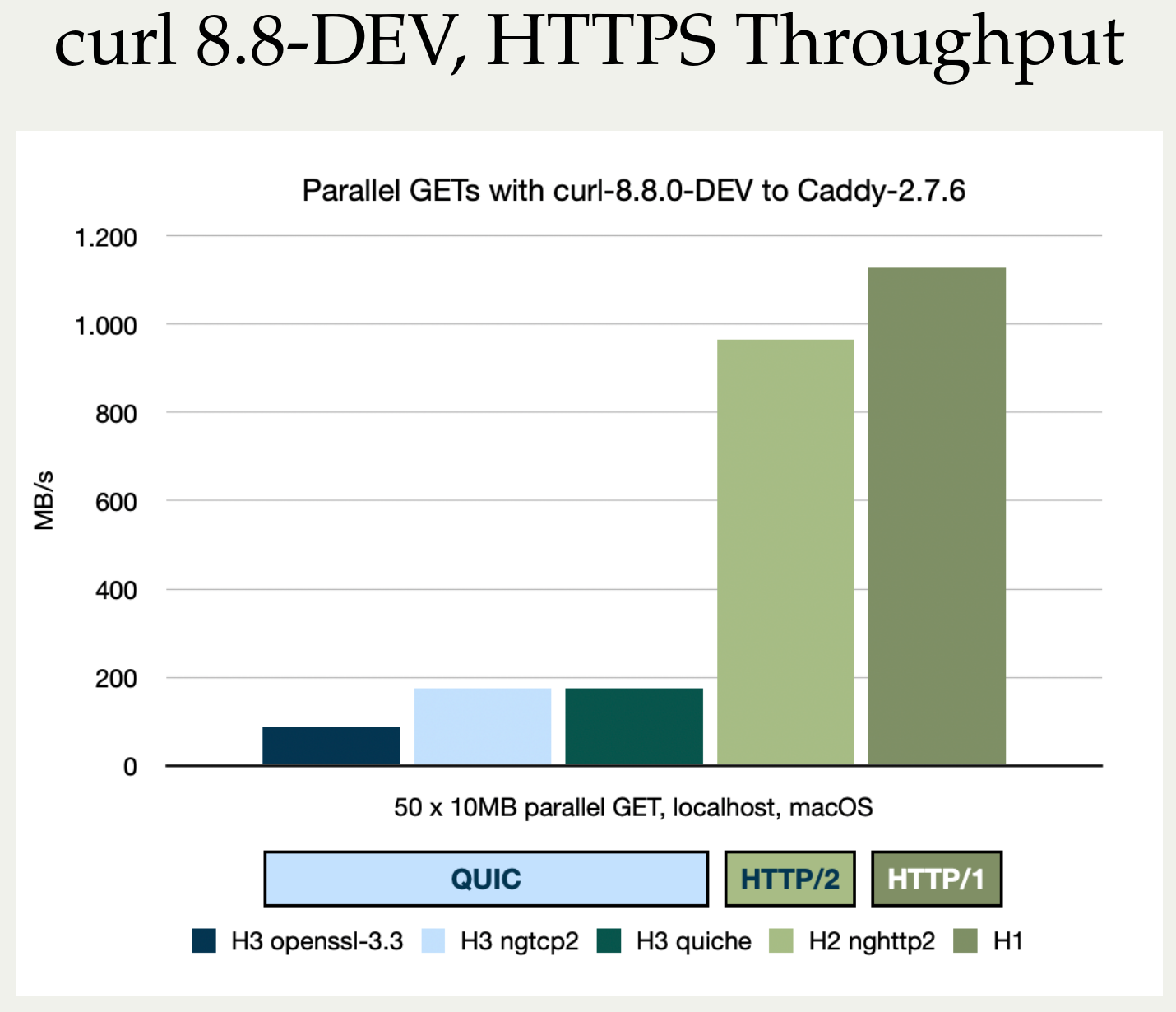
Stefan Eissing produced nice comparisons graph that I have borrowed from his Performance presentation (from curl up 2024. Stefan also blogged about h3 performance in curl earlier.). It compares three HTTP/3 curl backends against each other. (It does not include msh3 because it does not work good enough in curl.)
As you can see below, in several test setups OpenSSL is only achieving roughly half the performance of the other backends in both requests per second and raw transfer speed. This is on a localhost, so basically CPU bound transfers.
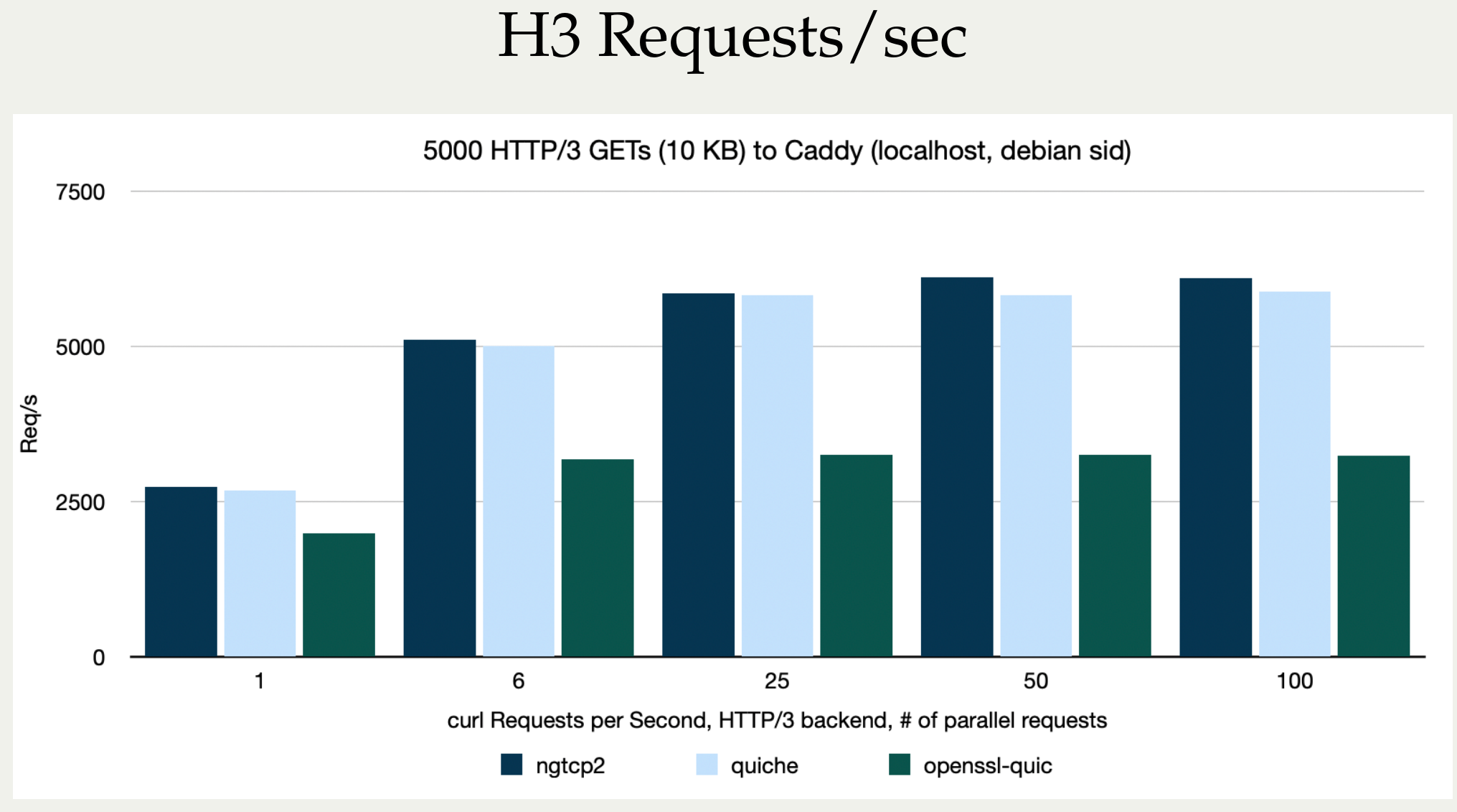
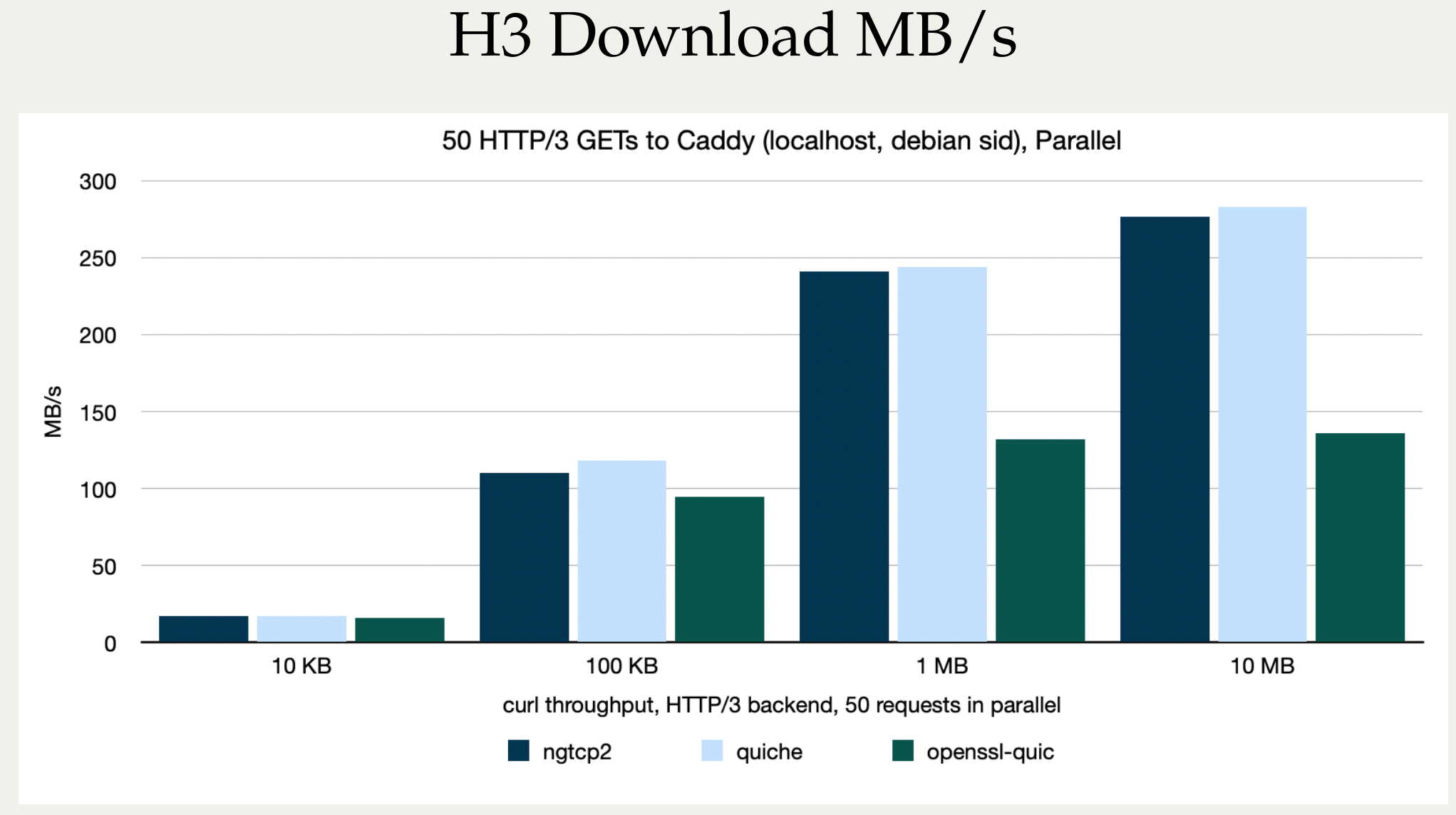
I believe OpenSSL needs to work on their QUIC performance in addition to providing an improved API.
quiche and msh3
quiche is still labeled beta and is only using BoringSSL which makes it harder to use in a lot of situations.
msh3 does not work at all right now in curl after a refactor a while ago.
HTTP/3 is a CPU hog
This is not news to anyone following protocol development. I have been repeating this over and over in every HTTP/3 presentation I have done – and I have done a few by now, but I think it is worth repeating and I also think Stefan’s graphs for this show the situation in a crystal clear way.
HTTP/3 is slow in terms of transfer performance when you are CPU bound. In most cases of course, users are not CPU bound because typically networks are the bottlenecks and instead the limited bandwidth to the remote site is what limits the speed on a particular transfer.
HTTP/3 is typically faster to completing a handshake, thanks to QUIC, so a HTTP/3 transfer can often get the first byte transmitted sooner than any other HTTP version (over TLS) can.
To show how this looks with more of Stefan’s pictures, let’s first show the faster handshakes from his machine somewhere in Germany. These tests were using a curl 8.8.0-DEV build, from a while before curl 8.8.0 was released.
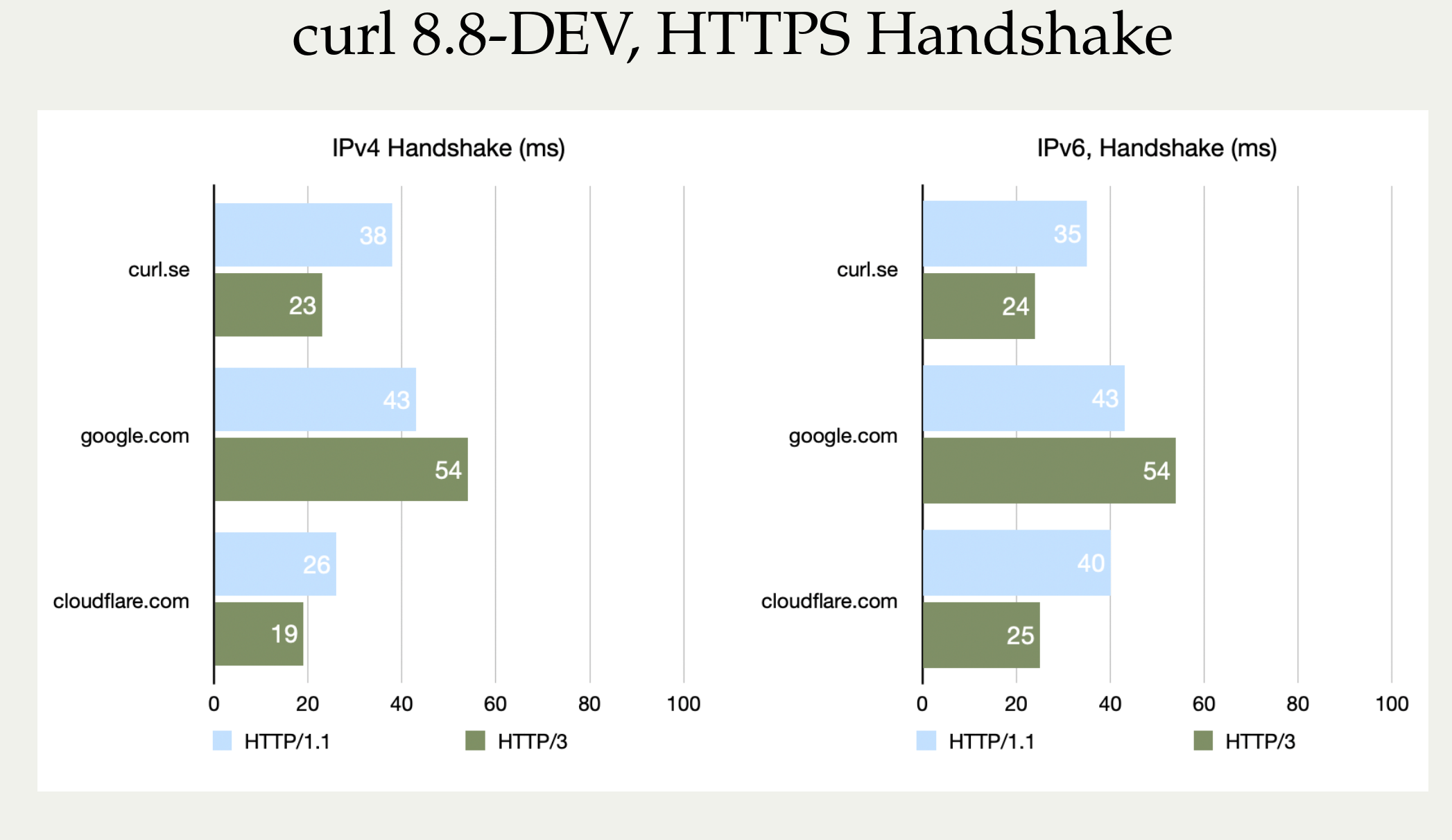
Nope, we cannot explain why google.com actually turned out worse with HTTP/3. It can be added that curl.se is hosted by Fastly’s CDN, so this is really comparing curl against three different CDN vendors’ implementations.
Again: these are CPU bound transfers so what this image really shows is the enormous amounts of extra CPU work that is required to push these transfers through. As long as you are not CPU bound, your transfers should of course run at the same speeds as they do with the older HTTP versions.
These comparisons show curl’s treatment of these protocols as they are not generic protocol comparisons (if such are even possible). We cannot rule out that curl might have some issues or weird solutions in the code that could explain part of this. I personally suspect that while we certainly always have areas for improvement remaining, I don’t think we have any significant performance blockers lurking. We cannot be sure though.
OpenSSL-QUIC stands out here as well, in the not so attractive end.
HTTP/3 deployments
w3techs, Mozilla and Cloudflare data all agree that somewhere around 28-30% of the web traffic is HTTP/3 right now. This is a higher rate than HTTP/1.1 for browser traffic.
An interesting detail about this 30% traffic share is that all the big players and CDNs (Google, Facebook, Cloudflare, Akamai, Fastly, Amazon etc) run HTTP/3, and I would guess that they combined normally have a much higher share of all the web traffic than 30%. Meaning that there is a significant amount of browser web traffic that could use HTTP/3 but still does not. Unfortunately I don’t have the means to figure out explanations for this.
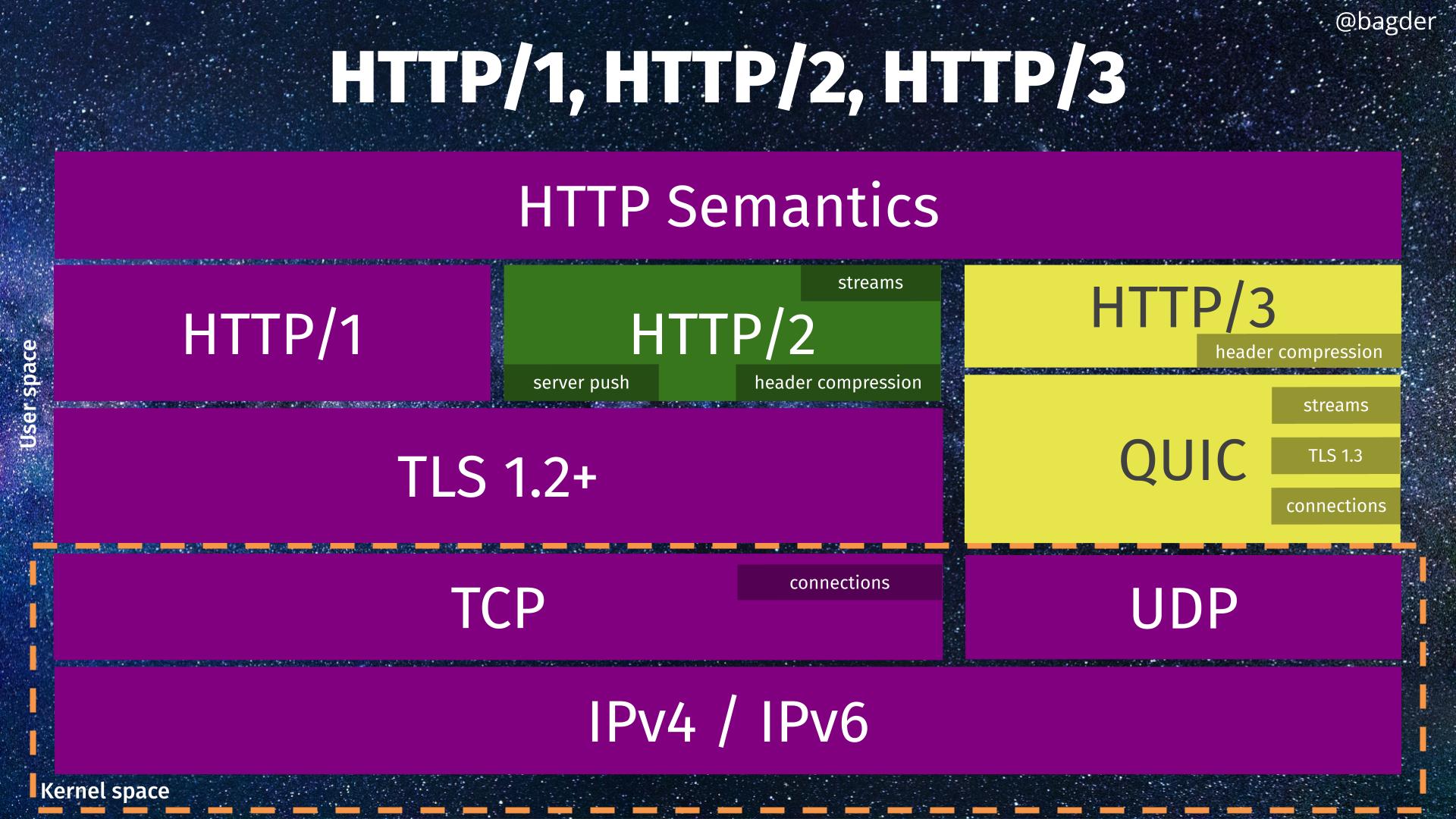
HTTPS stack overview
In case you need a reminder, here is how an HTTPS stack works.