If you are anything like me, you appreciate solving your every day simple tasks directly from the command line. Creating crafty single shot command lines or a small shell script to solve that special task you figured out you needed and makes your day go a little smoother. A fellow command line cowboy.
Video presentation
Background
To make life easier for curl users, the tool supports “config files“. They are a set of command line options written in a text file that you can point the curl tool to use. By default curl will check for and use such a config file named .curlrc if placed in your home directory.
One day not too long ago, a user over in the curl IRC channel asked me if it was possible to use environment variables in such config files to avoid having to actually store secrets directly in the file.
Variables
This new variable system that we introduce in curl 8.3.0 (commit 2e160c9c65) makes it possible to use environment variable in config files. But it does not stop there. It allows lots of other fun things.
First off, you can set named variables on the command line. Like :
curl --variable name=content
or in the config file:
variable=name=content
A variable name must only consist of a-z, A-Z, 0-9 or underscore (up to 128 characters). If you set the same name twice, the second set will overwrite the first.
There can be an unlimited amount of variables. A variable can hold up to 10M of content. Variables are set in a left to right order as curl parses the command line or config file.
Assign
You can assign a variable a plain fixed string as shown above. Optionally, you can tell curl to populate it with the contents of a file:
curl --variable name@filename
or straight from stdin:
curl --variable name@-
Environment variables
The variables mentioned above are only present in the curl command line. You can also opt to “import” an environment variable into this context. To import $HOME:
curl --variable %HOME
In this case above, curl will exit if there is no environment variable by that name. Optionally, you can set a default value for the case where the variable does not exist:
curl --variable %HOME=/home/nouser
Expand variables
All variables that are set or “imported” as described above can be used in subsequent command line option arguments – or in config files.
Variables must be explicitly asked for, to make sure they do not cause problems for older command lines or for users when they are not desired. To accomplish this, we introduce the --expand- option prefix.
Only when you use the --expand- prefix in front of an option will the argument get variables expanded.
You reference (expand) a variable like {{name}}. That means two open braces, the variable name and then two closing braces. This sequence will then be replaced by the contents of the variable and a non-existing variable will expand as blank/nothing.
Trying to show a variable with a null byte causes error
Examples
Use the variable named ‘content’ in the argument to --data, telling curl what to send in a HTTP POST:
--expand-data “{{content}}”
Create the URL to operate on by inserting the variables ‘host’ and ‘user’.
--expand-url “https://{{host}}/user/{{user}}”
Expand variables
--variable itself can be expanded when you want to create a new variable that uses content from one or more other variables. Like:
the 221st release 0 changes 7 days (total: 9,259) 27 bug-fixes (total: 9,194) 37 commits (total: 30,646) 0 new public libcurl function (total: 91) 0 new curl_easy_setopt() option (total: 303) 0 new curl command line option (total: 255) 20 contributors, 7 new (total: 2,927) 13 authors, 3 new (total: 1,173) 0 security fixes (total: 146)
Bugfixes
Here are some the most important fixes in this release
configure: check for nghttp2_session_get_stream_local_window_size
We use this function now, introduced in nghttp2 1.15.0, released in September 2016.
return IPv6 first for localhost resolves
Resolving “localhost” did not return the (fixed) addresses in the correct order. It now returns IPv6 as the first.
http2 regression on upload EOF handling
When we added an optimization in the previous release we missed a code path that sometimes lead to “hanging” uploads over HTTP/2.
os400: correct EXPECTED_STRING_LASTZEROTERMINATED
curl builds fine for “IBM i” again.
quiche: fix lookup of transfer at multi
Doing multiplexed HTTP/3 over multiple connections with quiche works much better.
mkhelp: strip off escape sequences
The command sequence that generates the man page display code for the --manual option did at some point regress to include escape sequences. Now those sequences are properly filtered out.
fix build when SIZEOF_CURL_OFF_T > SIZEOF_OFF_T
A build problem was fixed for these rare platforms.
do not clear the credentials on redirect to absolute URL
Yet another regression that we allowed because we apparently did not have a test for this! Now we have a test and redirects to the same origin when using -u for credentials now send the credentials even in the redirected request.
Welcome to another curl release. You know how this dance goes…
Numbers
the 220th release 5 changes 50 days (total: 9,252) 122 bug-fixes (total: 9,167) 177 commits (total: 30,606) 0 new public libcurl function (total: 91) 1 new curl_easy_setopt() option (total: 303) 4 new curl command line option (total: 255) 55 contributors, 34 new (total: 2,922) 35 authors, 20 new (total: 1,170) 1 security fixes (total: 146)
Release presentation
Security
fopen race condition (medium)
CVE-2023-32001. libcurl can be told to save cookies, HSTS and/or alt-svc data to files. When doing this, it called stat() followed by fopen() in a way that made it vulnerable to a TOCTOU (Time of Check, Time of Use) race condition problem.
By exploiting this flaw, an attacker could trick the victim to create or overwrite protected files holding this data in ways it was not intended to.
Changes
curl: add –ca-native and –proxy-ca-native
The command line tool (and library) got new options to ask it to use the systems “native” CA storage. Currently only work on Windows when curl is built to use an OpenSSL fork.
curl: add –trace-ids
This option makes the trace log files include connection and transfer identifiers, which greatly helps debugging transfers doing many (parallel) transfers.
Now users of the tool (and library) pass on specific IP addresses instead of simply using the current one.
add CURLINFO_CONN_ID and CURLINFO_XFER_ID
Two options that allows the application to extract the connection and transfer “Id” of the current transfer, presumably from a debugfunction callback and the likes.
Bugfixes
We have again fixed more than a hundred problems in this release cycle. Here follows a subset that I suspect might be among the most interesting ones.
examples: we’ve added and extended numerous
The ambition is to gradually over time provide examples that show use of all curl_easy_setopt options. We are still way off from that.
http2: numerous smaller and larger fixes
Several regressions and cleanups have been done that improves how HTTP/2 works compared to previous releases.
http2: send HEADER and DATA together
When sending POST requests, libcurl now does a better job in putting the initial outgoing HEADER and DATA frames together, most likely in the same TLS frame.
http3: upload EAGAIN handling
EAGAIN handling for HTTP/3 uploads was fixed, like it was for HTTP/2 as well.
http: fix the outgoing Cookie: header length check
The check that would prevent too long outgoing cookie headers was off by up to a few hundred bytes.
libssh2: use custom memory functions (again)
Bring back use of custom memory functions with libssh2 as otherwise it actually cannot be used with a debug build of curl (or when libssh2 is used as a DLL on windows) due to naive presumptions in the libssh2 API.
A regression caused curl misbehave on end of connection using TLS when built to use Secure Transport.
timeval: use CLOCK_MONOTONIC_RAW if available
For platforms with this clock option, curl now prefers that in an effort to avoid a time that can go backwards.
tool_writeout_json: fix encoding of control characters
The output of control codes in the generated JSON with --json now works better.
urlapi: have *set(PATH) prepend a slash if one is missing
Setting a path using the URL API without a leading slash would previously generate a broken URL when it was extracted. Starting now, libcurl will prepend a slash if there is none.
urlapi: scheme must start with alpha
The URL parser would previously allow a few other characters to start a scheme as well. No more.
tool_parsecfg: accept line lengths up to 10M
The config file parser now allows lines to be up to 10 megabytes. For those odd users generating files with huge data components embedded.
The curl user survey 2023 ran for two full weeks in the end of May, in the same fashion we run it every year.
I have then collected all the answers, ran the numbers and looked at the trends and put all the conclusions and graphs into a single document for everyone to enjoy.
Five quick things
If you are in too much of a hurry to read it all, here are five key facts this year’s survey revealed:
curl users leave Twitter and join Mastodon in notable amounts
Windows 11 is growing quickly as a platform curl users are on
HTTP/3 is used by a quarter of all curl users
WebSocket reached the top-10 of most used protocols before its first birthday
The positive comments in section 21 are heart-warming
The document
The final document is a 3MB 36 page PDF with collected data and conclusions. You find it here:
I will do a dedicated live-streamed video presentation of this curl user survey 2023 analysis and talk about how I see the numbers, the trends and maybe also show some additional data that was left out from the final document.
Previous years
This is the 10th year we run the survey. Here are links to five previous analysis documents:
June 15, 2023 10:00 AM PST (19:00 CEST, 17:00 UTC)
Register Here
This will be was an overview by Daniel Stenberg of the new WebSocket support in curl and in particular how to use this API with libcurl in your applications. It is followed by a live Q&A.
The session will be recorded and made available after the fact.
This webinar is done as a registration-only event on Zoom. If this is problematic for you, there will be a separate second version of this webinar done over Twitch at a later date.
There is something about having your product installed in over twenty billion instances all over the world and even out of the globe. In my case it helps me remain focused on and committed to working on the security aspects of curl. Ideally, we will never have our heartbleed moment.
Security is also a generally growing concern in the world around us and Open Source security perhaps especially so. This is one reason why NVD making things up is such a big problem.
The National Vulnerability Database (NVD) has a global presence. They host and share information about security vulnerabilities. If you search for a CVE Id using your favorite search engine, it is likely that the first result you get is a link to NVD’s page with information about that specific CVE. They take it upon themselves to educate the world about security issues. A job that certainly is needed but also one that puts a responsibility and requirement on them to be accurate. When they get things wrong they help distributing misinformation. Misinformation makes people potentially draw the wrong conclusions or act in wrong, incomplete or exaggerated ways.
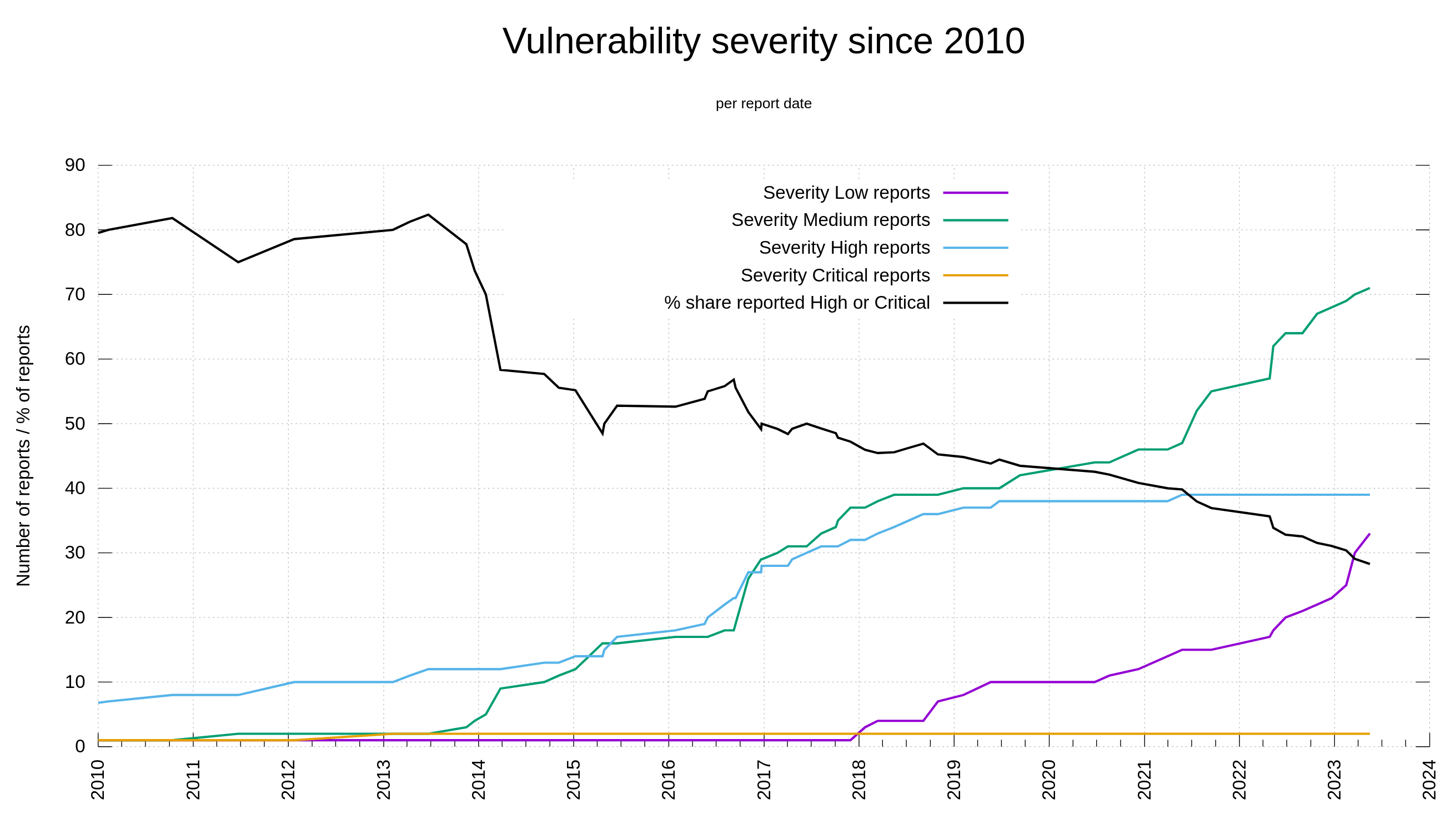
Low or Medium severity issues
There are well-known, recognized and reputable Open Source projects who by policy never issue CVEs for security vulnerabilities they rank severity low or medium. (I will not identify such projects here because it is not the point of this post.)
Such a policy successfully avoids the risk that NVD will greatly inflate their issues since they can already only be high or critical. But is it helping the users and the ecosystem at large?
In the curl project we have a policy which makes us register a CVE for every single reported or self-detected problem that can have a security impact. Either at will or by mistake. This includes a fair amount of low and medium issues. The amount of low and medium issues as a total of all issues increases over time as we keep finding issues, but the really bad ones are less frequently reported.
As we have all data recorded and stored, we can visualize this development over time. Below is a graph showing the curl vulnerability and severity level trends since 2010.
Severity distribution in reported curl vulnerabilities since 2010
Out of the 145 published curl security vulnerabilities so far, 28% have been rated severity high or critical while 104 of them were set low or medium by the curl security team.
I think this trend is easy to explain. It is because of two separate developments:
We as a project have matured and have learned over time how to test better, write code better to minimize risk and we have existed for a while to have a series of truly bad flaws already found (and fixed). We make less serious bugs these days.
Since 2010, lots of more people look for security problems and these days we are much better better at identifying problems as security related and we have better tools, while for a few years ago the same problem would just have become “a bug fix”.
Deciding severity
When a security problem is reported to curl, the curl security team and the reporter collaborate. First to make sure we understand the full width of the problem and its security impact. What can happen and what is required for that badness to trigger? Further, we assess what the likeliness that this can be done on purpose or by mistake and how common those situations and required configurations might be. We know curl, we know the code but we also often go back and double-check exactly what the documentation says and promises to better assess what users should be expected to know and do, and what is not expected from them etc. And we re-read the involved code again and again.
curl is currently a little over 160,000 lines of feature packed C code (excluding blank lines). It might not always be straight forward to a casual observer exactly how everything is glued together even if we try to also document internals to help you find deeper knowledge.
I think it is fair to say that it requires a certain amount of experience and time spent with the code to be able to fully understand a curl security issue and what impact it might have. I believe it is difficult or next to impossible for someone without knowledge about how it works to just casually read our security advisories and try to second-guess our assessments and instead make your own.
Yet this is exactly what NVD does. They don’t even ask us for help or for clarifications of anything. They think they can assess the severity of our problems without knowing curl nor fully understanding the reported issues.
A case to prove my point
In March 2023 we published a security advisory for the problem commonly referred to as CVE-2023-27536.
This is potentially a security problem, probably never hurts anyone and is in fact quite unlikely to ever cause a problem. But it might. So after deliberating we accepted it and ranked it severity low.
Bear with me here. I’ll spend two paragraphs revealing some details from the internal libcurl engine:
The problem is of a kind we have had several times in the past: curl has a connection pool and when a user makes a subsequent request which this particular option modified (compared to how it was when the previous connection was setup) it would wrongly reuse the first connection thinking they had the exact same properties.
The second would then accidentally get the wrong rights because it was setup differently. Still, the first connection would need the correct credentials and everything and so would the second one, it would just differ depending on what “GSSAPI delegation” that is allowed.
NVD ranks this
The person or team at NVD whose job it is to make up stuff for security vulnerabilities ranked this as CRITICAL 9.8. Almost as bad as it gets apparently. 10 is the max as you might recall.
When realizing this, at the end of May, I first fell off my chair in shock by this insanity, but after a quick recovery I emailed them (again) and complained (yet again) on setting this severity for *27536. I used the word “ridiculous” in my email to describe their actions. Why and who benefits from them scaremongering the world like this? It makes no sense. On the contrary, this is bad for everyone.
As a reaction to my complaint, someone at NVD went back and agreed to revise the CVSS string they had set and suddenly it was “only” ranked HIGH 7.2. I say “someone” because they never communicate with names and never sign the emails which whomever I talk to. They are just “NVD”.
I objected to their new CVSS string as well. It is just not a high severity security problem!
In my new argument I changed two particular details in the CVSS string (compared to the one they insisted was good) and presented arguments for that. For your pleasure, I include my exact wording below. (Some emphasis is added here for display purposes.)
How I motivated a downgrade
I could possibly live with: AV:N/AC:H/PR:H/UI:N/S:U/C:H/I:N/A:N (4.4) - even if that means Medium and we argue Low.
These are two changes and my motivations:
Attack complexity high - because how this requires that you actually have a working first communication and then do a second is slightly changed and you would expect the second to be different but in reality it accidentally reuse the first connection and therefore gives different/elevated rights.
It is a super-niche and almost impossible attack and there has been no report ever of anyone having suffered from this or even the existence of an application that actually would enable it to happen.
It is more likely to only happen by mistake by an application, but it also seems unlikely to ever be used by an application in a way that would trigger it since having the same user credentials with different values for GSS delegation and assume different access levels seems … weird.
This almost impossible chance of occurring is the primary reason we think this is a Low severity. With CVSS, it seems impossible to reach Low.
Privileges Required high - because the only way you can trigger this flaw is by having full privileges for the *same* user credentials that is later used again but with changed GSS API delegation set. While the previous connection is still live in the connection pool.
It would also only be an attack or a flaw if that second transfer actually assumes to have different access properties, which is probably debatable if users of the API would expect or not
CVSS still sucks
CVSS is a crap system so using this single-dimension number it seems next to impossible to actually get severity low report.
NVD wants “public sources”
NVD does not just take my word for how curl works. I mean, I only wrote a large chunk of it and am probably the single human that knows most about its internals and how it works. I also wrote the patch for this issue, I wrote the connection pool logic and I understand the problem exactly. Nope, just because I say so does not make it true.
My claims above about this issue can of course be verified by reading the publicly available source code and you can run tests to reproduce my claims. Not to mention that the functionality in question is documented.
But no.
They decided to agree to one of my proposed changes, which further downgraded the severity to MEDIUM 5.9. Quite far away from their initial stance. I think it is at least a partial victory.
For the second change to the CVSS string I requested, they demand that I provide more information for them. In their words:
There is no publicly available information about the CVE that clarifies your statement so we must request clarification from you and additionally have this detail added to the HackerOne report or some other public interface for transparency purposes prior to making changes to the CVSS vector.
… which just emphasizes exactly what I have stated already in this post. They set a severity on this without understanding the issue, with no knowledge of the feature that gets this wrong and without clues about what is actually necessary to trigger this flaw in the first place.
For people intimately familiar with curl internals, we actually don’t have to spell out all these facts with excruciating details. We know how the connection pool works, how the reuse of connections should work and what it means when curl gets it wrong. We have also had several other issues in this areas in the past. (It is a tricky area to get right.)
But it does not make this CVE more than a Low severity issue.
Conclusion
This issue is now stuck at this MEDIUM 5.9at NVD. Much less bad than where they started. Possibly Low or Medium does not make a huge difference out there in the world.
I think it is outrageous that I need to struggle and argue for such a big and renowned organization to do right. I can’t do this for every CVE we have reported because it takes serious time and energy, but at the same time I have zero expectation of them getting this right. I can only assume that they are equally lost and bad when assessing security problems in other projects as well.
A completely broken and worthless system. That people seem to actually use.
It is certainly tempting to join the projects that do not report Low or Medium issues at all. If we would stop doing that, at least NVD would not shout wolf and foolishly claim they are critical.
My response
That is a ridiculous request.
I'm stating *verifiable facts* about the flaw and how curl is vulnerable to it. The publicly available information this is based on is the actual source code which is openly available. You can also verify my claims by running code and checking what happens and then you'd see that my statements match what the code does.
The fact that you assess the severity of this (and other) CVE without understanding the basic facts of how it works and what the vulnerability is, just emphasizes how futile your work is: it does not work. If you do not even bother to figure these things out then of course you cannot set a sensible severity level or CVSS score. Now I understand your failures much better.
We in the curl project's security team already know how curl works, we understand this vulnerability and we set the severity accordingly. We don't need to restate known facts. curl functionality is well documented and its source code has always been open and public.
If you have questions after having read that, feel free to reach out to the curl security team and we can help you. You reach us at security@curl.se
I recommend that you (NVD) always talk to us before you set CVSS scores for curl issues so that we can help guide you through them. I think that could make the world a better place and it would certainly benefit a world of curl users who trust the info you provide.
/ Daniel
Several years ago when someone highlighted the fact for me that curl was credited in the ending sequence of the megahit game Grand Theft Auto V, I got a brief moment of acknowledgement from my kids that I might be doing cool stuff before they forgot and moved on.
GTA V ending sequence
Later I would find curl credits in more games and it started to become somewhat of a pattern. I collect screenshotted curl credits and awesome people help me point them out. Many of them are from games.
Battle.netBaldur’s Gate 3Diablo IVMarvels Spider ManRed Dead Redemption 2Ghost of Tsushima
Finding out they use curl is rarely straight forward. They virtually never told us before hand. Many list the curl license somewhere, sometimes you can find the DLL and some actually include a mention in on-screen credits displays.
Fortnite uses libcurl
PUBG: Battlegrounds uses libcurl
ROBLOX uses libcurl
As this little subset shows, some of the most popular games in the world use libcurl. We rarely get to know exactly for what purpose they use libcurl but we are left to guessing and assumptions. Modern games do a fair amount of internet transfers and what better library to do that with?
Game consoles bundle it
libcurl is also shipped as an OS component in several game consoles.
Nintendo Switch
Valve Steam Deck
Sony Playstation 5
Microsoft Xbox 360
List of curl credits
libcurl (often mentioned as plain curl) has been frequently used in games for almost twenty years already. Doom 3, from 2004 uses libcurl, just as well as well as Diablo IV, released just days ago in June 2023.
Doom 3 from 2004 used libcurl
Diablo IV from 2023 uses libcurl
The site mobygames.com maintains a database of people getting credits in games. The entry for me, since my name is the one used in the curl license, right now lists me (curl really) credited in no less than 136 games – and then the two games listed immediately above here are not even mentioned there so there are reasons to suspect there are others missing as well. Also, as mentioned before, the fact that a game is using curl is sometimes a well hidden secret.
What for?
I have not been closely involved with any of the makers of these games. I don’t have insights or special knowledge about exactly what they use libcurl for. Whatever download or upload purposes they have I guess.
Why curl?
Because curl is Capable, Ubiquitous , Reliable and Libre. It knows how to transfer data in many different ways, is feature packed and it performs well. It runs everywhere so the API works on all platforms. It has proven itself stable and solid for decades without breaking APIs or ABIs. The being available cheap (at no purchase cost at least) is probably also a strong contributing factor combined with the others.
The curl test suite was born in November 2000. We wrote our own custom system, dedicated for us.
In May 2001 we changed the file format for individual tests and this is still today the format we use. During the Twenty-two years that have passed we have added some 1600 test cases to the collection and we make sure that they can run on virtually any platform and that each test case themselves specify what curl features they require to work so that builds with those features disabled can skip those tests.
Only a thorough test suite provides the necessary confidence you need to promise to users that we keep existing behaviors and yet we still can and do repeatedly rewrite, refactor and replace large chunks of the internals.
Synchronous in a single thread
In 2000 we all had single cores and single CPUs. We made the test suite run the tests one by one, in a serial fashion. Some are quick, some take a little longer. While CPUs certainly have grown significantly faster over the lifetime of curl, the amount of test cases have also grown.
Today, on my fast modern machine, running all test cases in the main test suite takes about 10 minutes. If we run them with valgrind enabled (it then invokes all curl related commands and functions with the valgrind tool to monitor that it doesn’t do any serious memory violations or leaks), the same process takes close to 30 minutes.
This might not sound terribly bad, but it also not unusual to run the tests on slower machines that spend two or maybe even five times longer to completion. If you want to run the tests on a few different build combinations to make sure they are all happy, you may need to rerun the set a number of times. It all adds up.
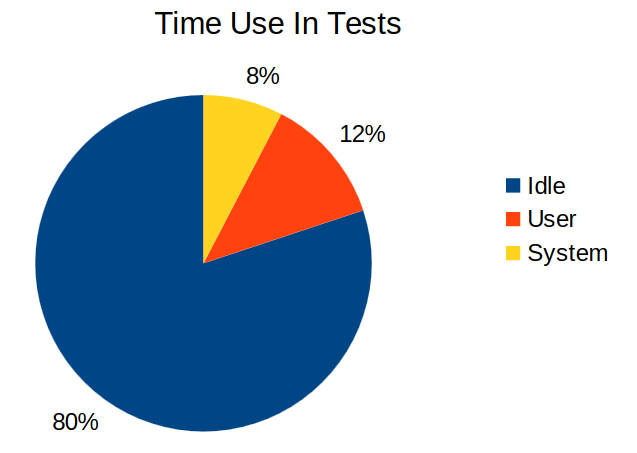
This is a rather ineffective use of time and available system resources. In researching and measuring the current state of curl testing, Dan Fandrich figured out that in a normal test round the CPU is idle 80% of the time! And that’s just one core.
Illustration from Dan’s “curl Parallel Testing Proposal”
Going parallel
In March 2023, Dan brought his curl Parallel Testing proposal (11 page PDF) to us, outlining an idea on how to convert the current single-threaded serial test runner into one that runs many separate worker processes and can run several test cases in parallel.
The general idea being that even on a single-core machine, running tests in parallel has the chance to speed up the process a lot. Because of that 80% number if nothing else.
Most (curl) developers of course also have machine with several or even many cores, making parallelism an even better idea.
We all loved the idea, gave Dan our thumbs up and arranged to fund his work on this improvement.
Port numbers
curl does Internet transfers, and for testing curl we have a set of test servers implemented that curl can talk to and get response back from. The specific tests control exactly how these servers respond and act for each test. To make sure that curl speaks the protocols correctly and consistently in both good and bad situations.
A challenge with this is that the test suite actually has to fire up and run actual networking servers on the local machine for this purpose. Each such server has to listen to a dedicated TCP or UDP port for as long as the tests are still going.
Luckily, we reworked the port number use for test servers recently. Using fixed port numbers for test servers was problematic already with single threaded tests because you could not run a separate test case in a different shell on the same machine etc. They would also sometimes collide with other random services running on developers’ machines.
Since August 2020 all test servers listen on random port numbers. A fundamental criteria for being able to run tests in parallel.
Landed
After a lot of hard work to refactor the test internals, it can now fire up N worker processes, where each such process can run its own set of test servers, then make sure the main scheduler hands out test cases to all of the workers and collects and outputs the test results from all of them. On June 5, Dan merged the commits to master that made it possible for all of us to start test (!) driving this.
First impressions
Dan recommends maybe 7 workers per core, but it might be a little bit limited to how much system memory you have since every such worker might end up running a fairly large amount of test servers. It also depends on if you run the tests with or without valgrind.
I ran a first simple test shot on my machine using 80 workers. A full valgrind enabled round with 1606 tests completed in 87 seconds. That is more than twenty times faster than previously.
Some further polish needed
There are still some issues left that make the parallel test setup a little shakier than the normal serial style, so we do not yet enable this by default for people. We will work on fixing those issues and iron out the last wrinkles so that we can soon get everyone onboard on this.
This is the second follow-up patch release in the 8.1.x series due to regressions and bugs that are too annoying to leave lingering around.
Release video
Numbers
the 219th release 0 changes 7 days (total: 9,202) 14 bug-fixes (total: 9,045) 22 commits (total: 30,429 0 new public libcurl function (total: 91) 0 new curl_easy_setopt() option (total: 302) 0 new curl command line option (total: 251) 13 contributors, 3 new (total: 2,888) 5 authors, 2 new (total: 1,150) 0 security fixes (total: 145)
Bugfixes
configure: quote the assignments for run-compiler
A regression introduced in the previous release made configure fail if the $CC shell variable was set to something else than just a single command name. This now quotes the variable correctly.
configure: without pkg-config and no custom path, use -lnghttp2
Installations without pkg-config where nghttp2 is installed in a default directory would get a link error in the build.
http2: fix EOF handling on uploads with auth negotiation
This was a regression when using HTTP/2 for doing multi-phase authentication methods with POST, like for example Digest.
http3: send EOF indicator early as possible
By better tracking the amount of upload data, curl can avoid a superfluous final zero-length DATA packet and instead send the EOF sooner.
libcurl.m4: remove trailing ‘dnl’ that causes this to break autoconf
The configure macro we ship for other projects to use to detect installed libcurl version now works better.
libssh: when keyboard-interactive auth fails, try password
When a SSH server allows multiple auth methods, and curl tried keyboard-interactive it would wrongly skip trying the password method – if built to use libssh. This bug has been present all since libssh support shipped.
For widely used, widely distributed open source project such as curl, we often have little to no relation at all with our users and therefore it is hard to get feedback and learn what works and what is less good.
Our best and primary way is thus simply to ask users every year how they use curl.
user survey
For the tenth consecutive year, we put together a survey and we ask everyone we know and can reach who ever used curl or library within the last year, to donate a few minutes of their precious time and give us their honest opinions.
The survey is anonymous but hosted by Google. We do not care who you are, but we want to know how you think curl works for you.
The survey will remain online for submissions during 14 days. From Thursday May 25 2023 until midnight (CEST) Wednseday June 7 2023. Please tell your friends about it!
user survey
Post survey analysis
At June 5 the painstaking work of analyzing the results and putting together a summary and presentation begins. It usually takes me a few weeks to complete. Once that is done, the results will be shared for the entire world to enjoy.
Then we see what the curl project should take home and do as a direct result of what users say. Updating procedures, writing documentation and adding features to the roadmap are among the things that can happen and has happened after previous surveys.