Welcome to another release! We did more bug-fixes than in any previous release (176). We paid more in bug-bounties than during any previous release cycle (4,200 USD) and we thank more contributors in the RELEASE-NOTES than ever before (83).
Release presentation
Numbers
the 201st release
6 changes
56 days (total: 8,524)
176 bug-fixes (total: 7,142)
263 commits (total: 27,465)
0 new public libcurl function (total: 85)
0 new curl_easy_setopt() option (total: 290)
0 new curl command line option (total: 242)
83 contributors, 49 new (total: 2,459)
56 authors, 32 new (total: 933)
5 security fixes (total: 108)
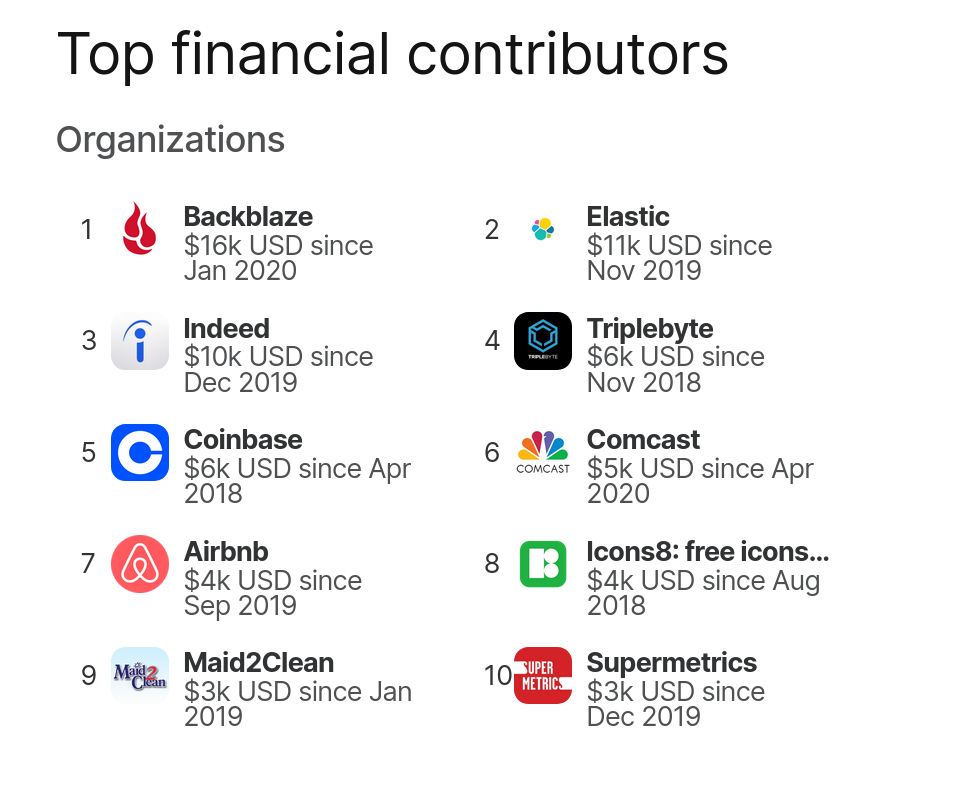
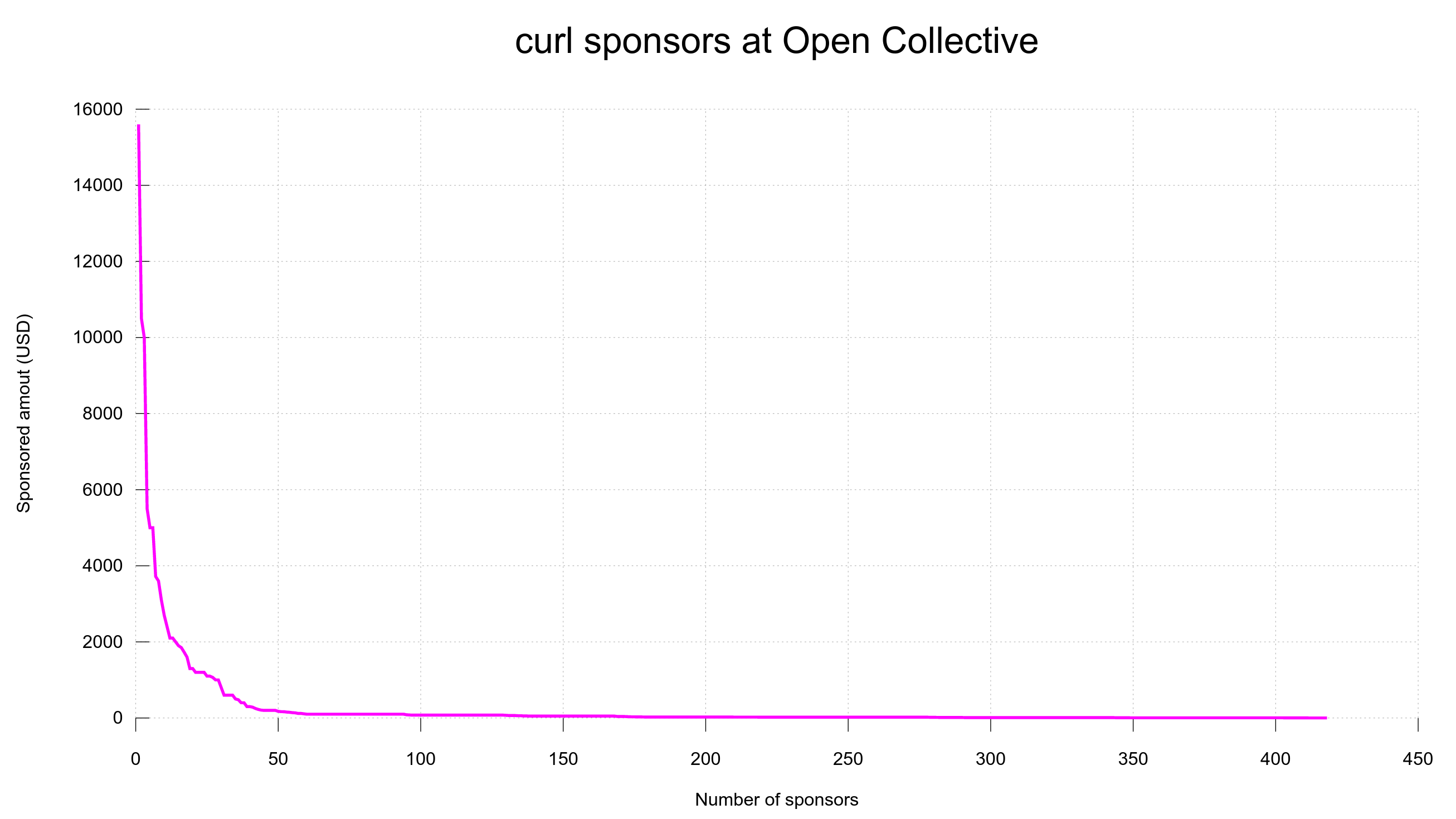
4,200 USD paid in Bug Bounties (total: 13,200 USD)
Security
This time we announce no less than 5 separate security advisories and we are once again setting a new bug-bounty record. This release cycle we spent 4,200 USD on rewarding security researchers.
Let’s do them in numerical order. Click the CVE links to get to the full and much more detailed advisories.
CVE-2021-22922: Wrong content via metalink not discarded
This was one of the problems we found that that all together made us take the drastic decision to completely remove metalink support.
The metalink format has a hash for the content so that a client can detect faulty contents. curl didn’t act properly if the has mismatched and it could easily make users not realize the bad content.
CVE-2021-22923: Metalink download sends credentials
If you download the metalink file using credentials, the subsequent download(s) of the file mentioned in that XML file will also get the same credentials passed to those servers, unexpectedly, thus potentially leaking sensitive information to other parties!
CVE-2021-22924: Bad connection reuse due to flawed path name checks
libcurl keeps previously used connections in a connection pool for subsequent transfers to reuse, if one of them matches the setup.
Due to errors in the logic, the config matching function did not take ‘issuer cert’ into account and it compared the involved paths case insensitively, which could lead to libcurl reusing wrong connections!
CVE-2021-22925: TELNET stack contents disclosure again
Possibly the most embarrassing security flaw in a long time.
When we shipped 7.77.0 we announced CVE-2021-22898, which was a flaw in the telnet code and an associated fix. Know what? The fix was incomplete and plain wrong so the original problem actually remained for a certain set of input.
This is thus the second advisory for the same problem and now we fix this again. Hopefully for real and for good this time…
CVE-2021-22926: CURLOPT_SSLCERT mixup with Secure Transport
When libcurl is built to use the macOS native TLS library Secure Transport, an application can ask for the client certificate by name or with a file name – using the same option. If the name exists as a file, it will be used instead of by name. This could be exploited in rare circumstances.
Changes
The six big changes this time around are:
curl_url_set now rejects spaces in the URL unless specifically asked to allow them.
CURLE_SETOPT_OPTION_SYNTAX is a brand new return code (name) for when libcurl detects an illegally formatted input passed to a setopt(), when it is detected later in the transfer.
localhost is now always local!
The mbedTLS backend now supports client certificate and key provided as “blob options” in memory instead of as files.
Now username and password can be used for MQTT transfers.
Bug-fixes
I’m doing this release in the midst of my vacation so I’m doing this section a little shorter than usual. Here are some bug-fixes to highlight:
Lots of tiny fixes when built to use hyper for HTTP. Now curl built to use hyper can run many more test cases. There’s more to do and more will be done going forward.
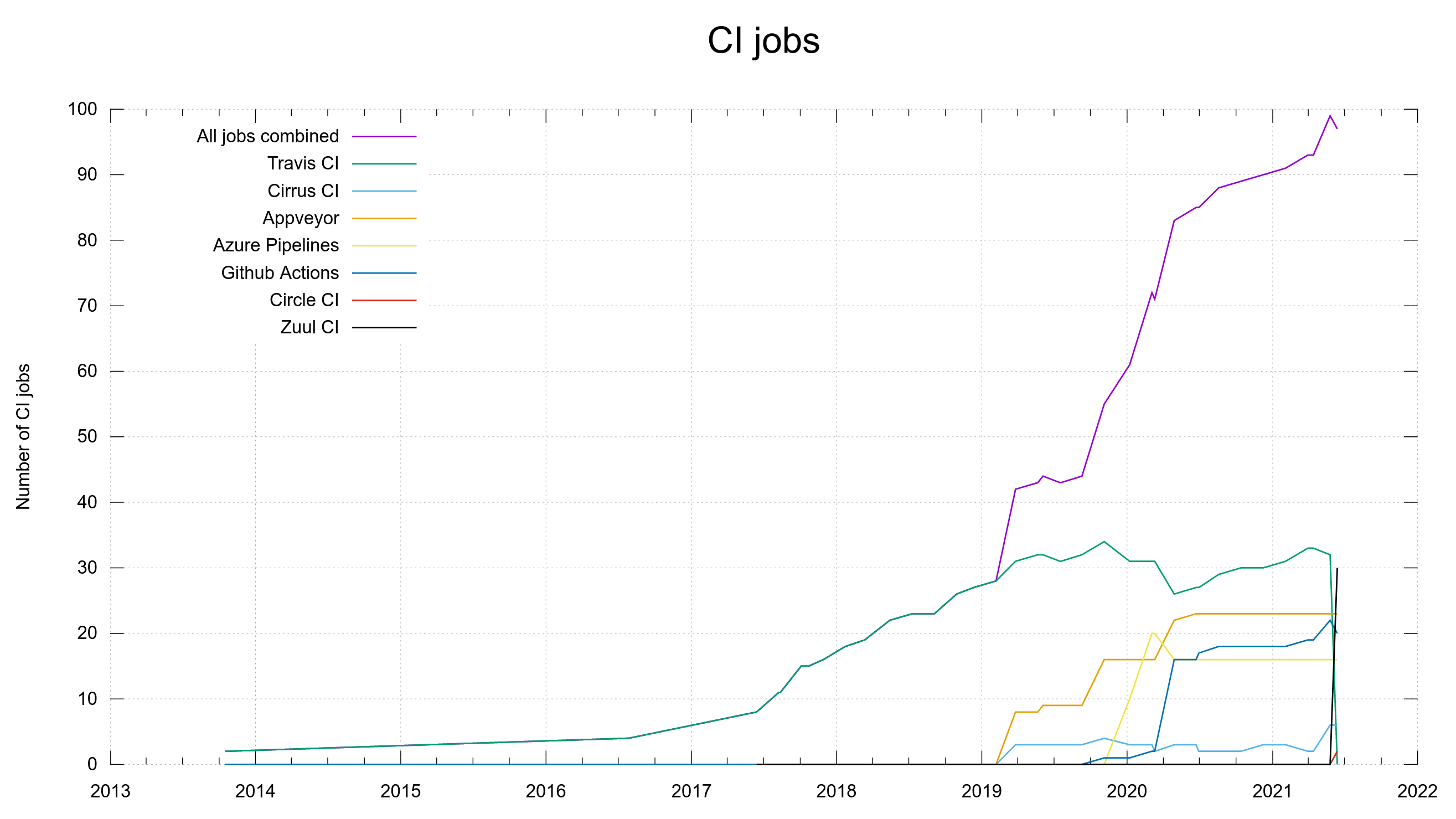
Travis CI is gone. Zuul and Circle CI are in.
GnuTLS: set the preferred TLS versions in correct order. Previously the occasional TLS connection would fail because of the wrong way the code would instruct GnuTLS…
on macOs: free returned memory of SCDynamicStoreCopyProxies. A small memory leak on Apple operating systems, possibly as many as one per name resolve?
HSTS: not experimental anymore. It is now built and provided by default.
netrc: skip ‘macdef’ definitions. The netrc parser is ancient but it turned out this kind of macro use could threw it off.
OpenSSL: don’t remove session id entry in disassociate. We had a regression that basically killed session-id use and made subsequent TLS handshakes to the same host much slower.
Next
The plans says we ship the next release on September 15th 2021. See you then!