The NTLM authentication method was always a beast.
It is a proprietary protocol designed by Microsoft which was reverse engineered a long time ago. That effort resulted in the online documentation that I based the curl implementation on back in 2003. I then also wrote the NTLM code for wget while at it.
NTLM broke with the HTTP paradigm: it is made to authenticate the connection instead of the request, which is what HTTP authentication is supposed to do and what all the other methods do. This might sound like a tiny and insignificant detail, but it has a major impact in all HTTP implementations everywhere. Indirectly it is also the cause for quite a few security related issues in HTTP code, because NTLM needs many special exceptions and extra unique treatments.
curl has recorded no less than seven past security vulnerabilities in NTLM related code! While that may not be only NTLM’s fault, it certainly does not help.
The connection-based concept also makes the method incompatible with HTTP/2 and HTTP/3. NTLM requires services to stick to HTTP/1.
NTLM (v1) uses super weak cryptographic algorithms (DES and MD5), which makes it a bad choice even when disregarding the other reasons.
We are slowly deprecating NTLM in curl, but we are starting out by making it opt-in. Starting in curl 8.20.0, NTLM is disabled by default in the build unless specifically enabled.
Microsoft themselves have deprecated NTLM already. The wget project looks like it is about to make their NTLM support opt-in.
SMB
curl only supports SMB version 1. This protocol uses NTLM for the authentication and it is equally bad in this protocol. Without NTLM enabled in the build, SMB support will also get disabled.
But also: SMBv1 is in itself a weak protocol that is barely used by curl users, so this protocol is also opt-in starting in curl 8.20.0. You need to explicitly enable it in the build to get it added.
Not removed yet
I want to emphasize that we have not removed support for these ancient protocols, we just strongly discourage using them and I believe this is a first step down the ladder that in a future will make them get removed completely.
In May 2010 we merged support for the RTMP protocol suite into curl, in our desire to support the world’s internet transfer protocols.
RTMP
The protocol is an example of the spirit of an earlier web: back when we still thought we would have different transfer protocols for different purposes. Before HTTP(S) truly became the one protocol that rules them all.
RTMP was done by Adobe, used by Flash applications etc. Remember those? RTMP is an ugly proprietary protocol that simply was never used much in Open Source.
The common Open Source implementation of this protocol is done in the rtmpdump project. In that project they produce a library, librtmp, which curl has been using all these years to handle the actual binary bits over the wire. Build curl to use librtmp and it can transfer RTMP:// URLs for you.
librtmp
In our constant pursuit to improve curl, to find spots that are badly tested and to identify areas that could be weak from a security and functionality stand-point, our support of RTMP was singled out.
Here I would like to stress that I’m not suggesting that this is the only area in need of attention or improvement, but this was one of them.
As I looked into the RTMP situation I realized that we had no (zero!) tests of our own that actually verify RTMP with curl. It could thus easily break when we refactor things. Something we do quite regularly. I mean refactor (but also breaking things). I then took a look upstream into the librtmp code and associated project to investigate what exactly we are leaning on here. What we implicitly tell our users they can use.
I quickly discovered that the librtmp project does not have a single test either. They don’t even do releases since many years back, which means that most Linux distros have packaged up their code straight from their repositories. (The project insists that there is nothing to release, which seems contradictory.)
Is there perhaps any librtmp tests perhaps in the pipe? There had not been a single commit done in the project within the last twelve months and when I asked one of their leading team members about the situation, I was made clear to me that there is no tests in the pipe for the foreseeable future either.
How about users?
In November 2025 I explicitly asked for RTMP users on the curl-library mailing list, and one person spoke up who uses it for testing.
In the 2025 user survey, 2.2% of the respondents said they had used RTMP within the last year.
The combination of few users and untested code is a recipe for pending removal from curl unless someone steps up and improves the situation. We therefor announced that we would remove RTMP support six months into the future unless someone cried out and stepped up to improve the RTMP situation.
We repeated this we-are-doing-to-drop-RTMP message in every release note and release video done since then, to make sure we do our best to reach out to anyone actually still using RTMP and caring about it.
If anyone would come out of the shadows now and beg for its return, we can always discuss it – but that will of course require work and adding test cases before it would be considered.
Compatibility
Can we remove support for a protocol and still claim API and ABI backwards compatibility with a clean conscience?
This is the first time in modern days we remove support for a URL scheme and we do this without bumping the SONAME. We do not consider this an incompatibility primarily because no one will notice. It is only a break if it actually breaks something.
(RTMP in curl actually could be done using six separate URL schemes, all of which are no longer supported: rtmp,rtmpe,rtmps, rtmpt,rtmpte,rtmpts.)
The offical number of URL schemes supported by curl is now down to 27: DICT, FILE, FTP, FTPS, GOPHER, GOPHERS, HTTP, HTTPS, IMAP, IMAPS, LDAP, LDAPS, MQTT, MQTTS, POP3, POP3S, RTSP, SCP, SFTP, SMB, SMBS, SMTP, SMTPS, TELNET, TFTP, WS and WSS.
When
The commit that actually removed RTMP support has been merged. We had the protocol supported for almost sixteen years. The first curl release without RTMP support will be 8.20.0 planned to ship on April 29, 2026
In the spring of 2020 I decided to finally do something about the lack of visualizations for how the curl project is performing, development wise.
How does the line of code growth look like? How many command line options have we had over time and how many people have done more than 10 commits per year over time?
I wanted to have something that visually would show me how the project is doing, from different angles, viewpoints and probes. In my mind it would be something like a complicated medical device monitoring a patient that a competent doctor could take a glance at and assess the state of the patient’s health and welfare. This patient is curl, and the doctors would be fellow developers like myself.
GitHub offers some rudimentary graphs but I found (and still find) them far too limited. We also ran gitstats on the repository so there were some basic graphs to get ideas from.
Make it myself
I did a look-around to see what existing frameworks and setups that existed that I should base this one, as I was convinced I would have to do quite some customizing myself. Nothing I saw was close enough to what I was looking for. I decided to make my own, at least for a start.
I decided to generate static images for this, not add some JavaScript framework that I don’t know how to use to the website. Static daily images are excellent for both load speed and CDN caching. As we already deny running JavaScript on the site that saved me from having to work against that. SVG images are still vector based and should scale nicely.
SVG is also a better format from a download size perspective, as PNG almost always generate much larger images for this kind of images.
When this started, I imagined that it would be a small number of graphs mostly showing timelines with plots growing from lower left to upper right. It would turn out to be a little naive.
gnuplot
I knew some basics about gnuplot from before as I had seen images and graphs generated by others in the past. Since gitstats already used it I decided to just dive in deeper and use this. To learn it.
gnuplot is a 40 year old (!) command line tool that can generate advanced graphs and data visualizations. It is a powerful tool, which also means that not everything is simple to understand and use at once, but there is almost nothing in terms of graphs, plots and curves that it cannot handle in one way or another.
I happened to meet Lee Phillips online who graciously gave me a PDF version of his book aptly named gnuplot. That really helped!
Produce data to feed gnuplot
I decided that for every graph I want to generate, I first gather and format the data with one script, then render an image in a separate independent step using gnuplot. It made it easy to work on them in separate steps and also subsequently tune them individually and to make it easy to view the data behind every graph if I ever think there’s a problem in one etc.
It took me about about two weeks of on and off working in the background to get a first set of graphs visualizing curl development status.
I then created the glue scripting necessary to add a first dashboard with the existing graphs to the curl website. Static HTML showing static SVG images.
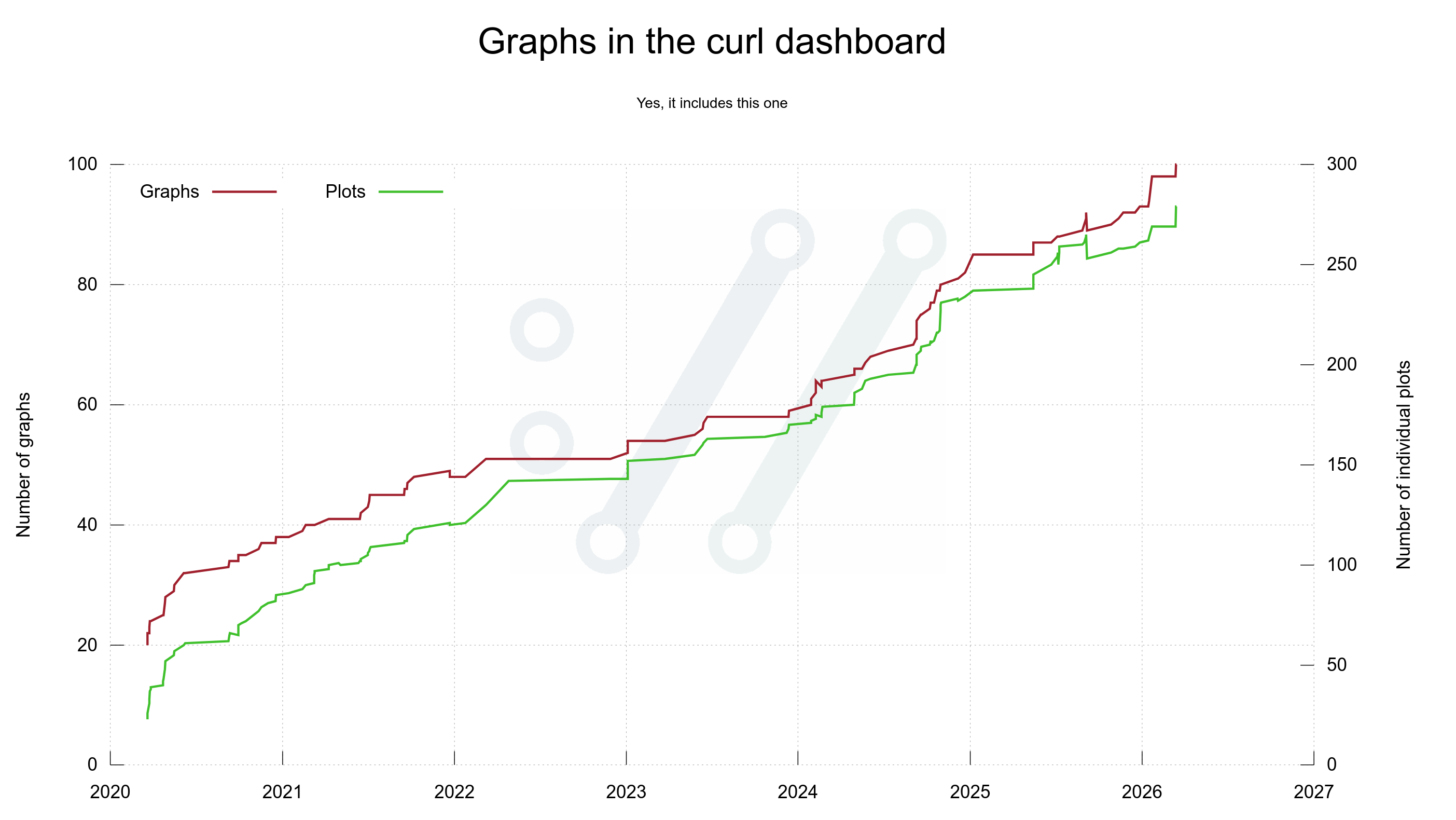
On March 20, 2020 the first version of the dashboard showed no less than twenty separate graphs. I refer to “a graph” as a separate image, possibly showing more than one plot/line/curve. That first dashboard version had twenty graphs using 23 individual plots.
Since then, we display daily updated graphs there.
The data
All data used for populating the graphs is open and available, and I happily use whatever is available:
git repository (source, tags, etc)
GitHub issues
mailing list archives
curl vulnerability data
hackerone reports
historic details from the curl past
Open and transparent as always.
Then it grew
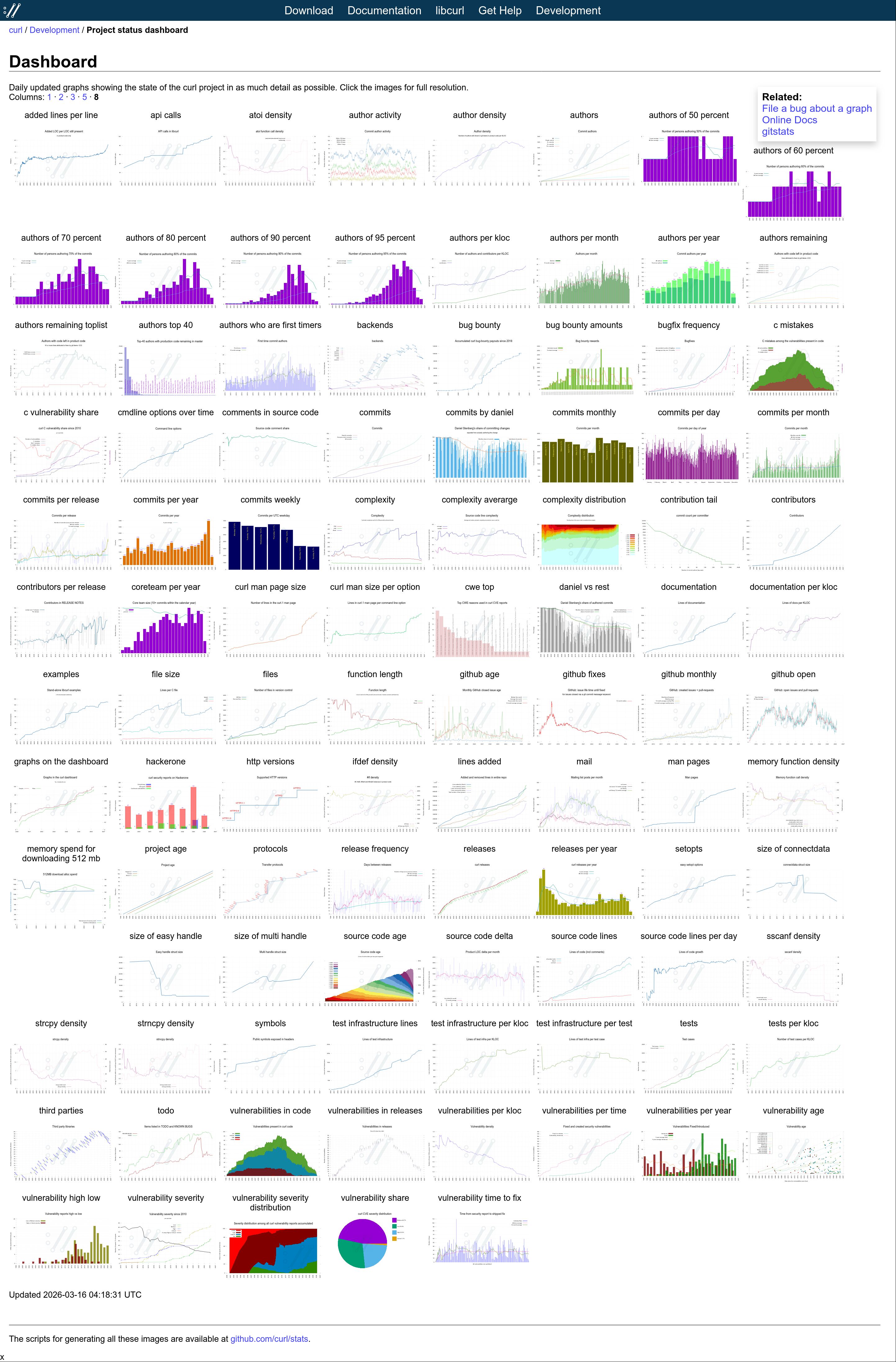
Every once in a while since then I get to think of something else in the project, the code, development, the git history, community, emails etc that could be fun or interesting to visualize and I add a graph or two more to the dashboard. Six years after its creation, the initial twenty images have grown to one hundred graphs including almost 300 individual plots.
Most of them show something relevant, while a few of them are in the more silly and fun category. It’s a mix.
Graph 100
The 100th graph was added on March 15, 2026 when I brought back the “vulnerable releases” graph (appearing on the site on March 16 for the first time). It shows the number of known vulnerabilities each past release has. I removed it previously because it became unreadable, but in this new edition I made it only show the label for every 4th release which makes it slightly less crowded than otherwise.
vulnerabilities in releases
This day we also introduce a new 8-column display mode.
Screenshot showing 100 graphs in the dashboard
Custom but available
Many of the graphs are internal and curl specific of course. The scripts for this, and the entire dashboard, remain written specifically for curl and curl’s circumstances and data. They would need some massaging and tweaking in order to work for someone else.
All the scripts are of course open and available for everyone.
I used to also offer all the CSV files generated to render the graphs in an easy accessible form on the site, but this turned out to be work done for virtually no audience, so I removed that again. If you replace the .svg extension with .csv, you can still get most of the data – if you know.
Data is knowledge
The graphs and illustrations are not only silly and fun. They also help us see development from different angles and views, and they help us draw conclusions or at least try to. As an established and old project that makes an effort to do right, some of what we learn from this curl data might be possible to learn from and use even in other projects. Maybe even use as basis when we decide what to do next.
I personally have used these graphs in countless blog posts, Mastodon threads and public curl presentations. They help communicate curl development progress.
The jokes
On Mastodon I keep joking about me being a graphaholic and often when I have presented yet another graph added the collection, someone has asked the almost mandatory question: how about a graph over number of graphs on the dashboard?
Early on I wrote up such a script as well, to immediately fulfill that request. On March 14 2026, I decided to add it it as a permanent graph on the dashboard.
Graphs in the curl dashboard
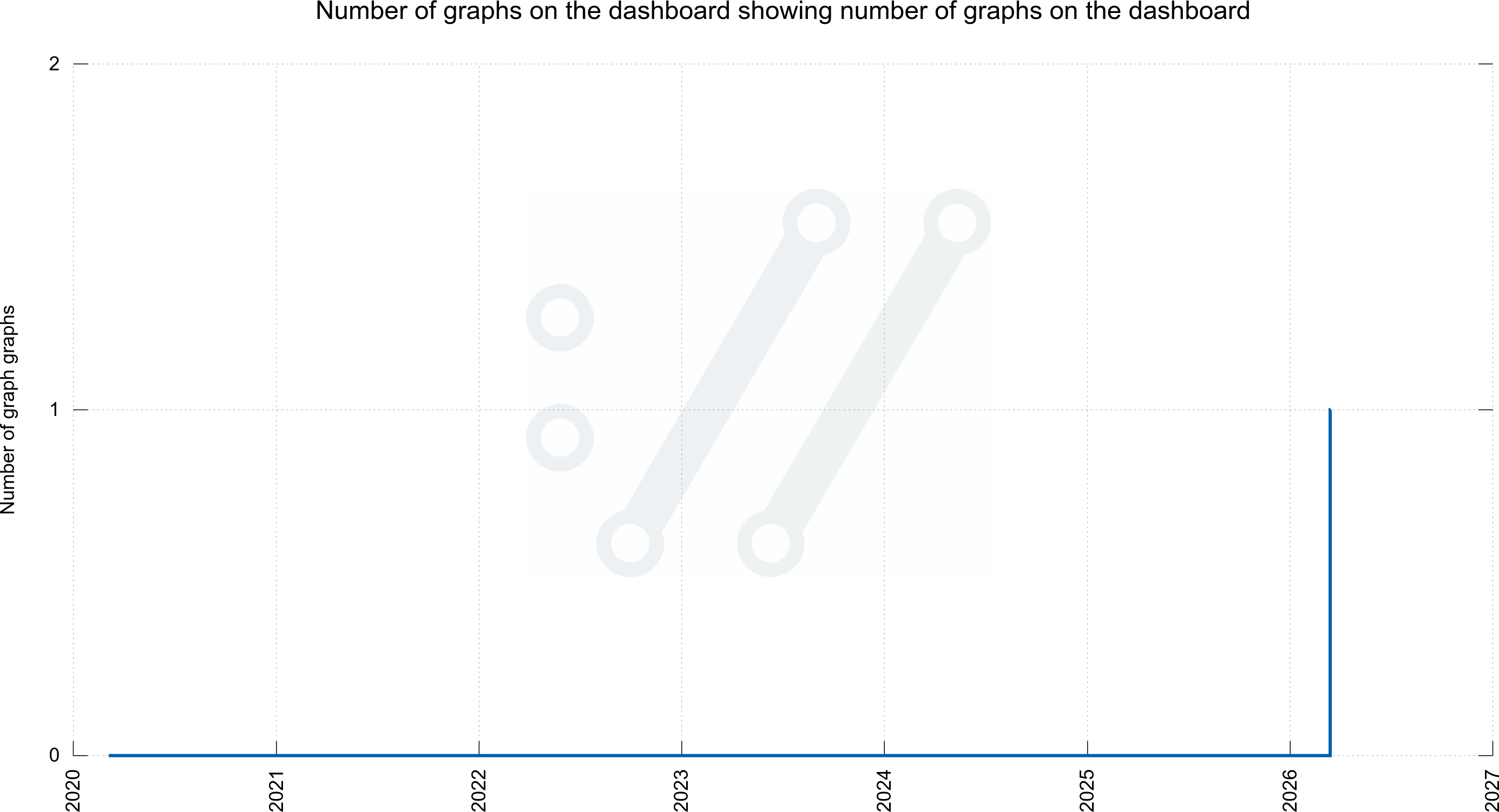
The next-level joke (although some would argue that this is not fun anymore) is then to ask me for a graph showing the number of graphs for graphs. As I aim to please, I have that as well. Although this is not on the dashboard:
Number of graphs on the dashboard showing number of graphs on the dashboard
More graphs
I am certain I (we?) will add more graphs over time. If you have good ideas for what source code or development details we should and could illustrate, please let me know.
Background: nuget.org is a Microsoft owned and run service that allows users to package software and upload it to nuget so that other users can download it. It is targeted for .Net developers but there is really no filter in what you can offer through their service.
Three years ago I reported on how nuget was hosting and providing ancient, outdated and insecure curl packages. Random people download a curl tarball, build curl and then upload it to nuget, and nuget then offers those curl builds to the world – forever.
To properly celebrate the three year anniversary of that blog post, I went back to nuget.org, entered curl into the search bar and took a look at the results.
I immediately found at least seven different packages where people were providing severely outdated curl versions. The most popular of those, rmt_curl, reports that it has been downloaded almost 100,000 times over the years and is still downloaded almost 1,000 times/week the last few weeks. It is still happening. The packages I reported three years ago are gone, but now there is a new set of equally bad ones. No lessons learned.
rmt_curl claims to provide curl 7.51.0, a version we shipped in November 2016. Right now it has 64 known vulnerabilities and we have done more than 9,000 documented bugfixes since then. No one in their right mind should ever download or use this version.
Conclusion: the state of nuget is just as sad now as it was three years ago and this triggered another someone is wrong on the internet moments for me. I felt I should do my duty and tell them. Again. Surely they will act this time! Surely they think of the security of their users?
Trusting randos
The entire nuget concept is setup and destined to end up like this: random users on the internet put something together, upload it to nuget and then the rest of the world downloads and uses those things – trusting that whatever the description says is accurate and well-meaning. Maybe there are some additional security scans done in the background, but I don’t see how anyone can know that they don’t contain any backdoors, trojans or other nasty deliberate attacks.
And whatever has been uploaded once seems to then be offered in perpetuity.
I reported this again
Like three years ago I listed a bunch of severely outdated curl packages in my report. nuget says I can email them a report, but that just sent me a bounce back saying they don’t accept email reports anymore. (Sigh, and yes I reported that as a separate issue.)
I was instead pointed over to the generic Microsoft security reporting page where there is not even any drop-down selection to use for “nuget” so I picked “.NET” instead when I submitted my report.
“This is not a Microsoft problem”
Almost identically to three years ago, my report was closed within less than 48 hours. It’s not a nuget problem they say.
Thank you again for submitting this report to the Microsoft Security Response Center (MSRC).
After careful investigation, this case has been assessed as not a vulnerability and does not meet Microsoft’s bar for immediate servicing. None of these packages are Microsoft owned, you will need to reach out directly to the owners to get patched versions published. Developers are responsible for removing their own packages or updating the dependencies.
In other words: they don’t think it’s nuget’s responsibility to keep the packages they host, secure and safe for their users. I should instead report these things individually to every outdated package provider, who if they cared, would have removed or updated these packages many years ago already.
Also, that would imply a never-ending wack-a-mole game for me since people obviously keep doing this. I think I have better things to do in my life.
Outdated efforts
In the cases I reported, the packages seem to be of the kind that once had the attention and energy by someone who kept them up-to-date with the curl releases for a while and then they stopped and since then the packages on nuget has just collected dust and gone stale.
Still, apparently users keep finding and downloading them, even if maybe not at terribly high numbers.
Thousands of fooled users per week is thousands too many.
How to address
The uploading users are perfectly allowed to do this, legally, and nuget is perfectly allowed to host these packages as per the curl license.
I don’t have a definite answer to what exactly nuget should do to address this problem once and for all, but as long as they allow packages uploaded nine years ago to still get downloaded today, it seems they are asking for this. They contribute and aid users getting tricked into downloading and using insecure software, and they are indifferent to it.
A rare few applications that were uploaded nine years ago might actually still be okay but those are extremely rare exceptions.
Conclusion
The last time I reported this nuget problem nothing happened on the issue until I tweeted about it. This time around, a well-known Microsoft developer (who shall remain nameless here) saw my Mastodon post about this topic when mirrored over to Bluesky and pushed for the case internally – but not even that helped.
The nuget management thinks this is okay.
If I were into puns I would probably call them chicken nuget for their unwillingness to fix this. Maybe just closing our eyes and pretending it doesn’t exist will just make it go away?
curl and libcurl are written in C. Rather low level components present in many software systems.
They are typically not part of any ecosystem at all. They’re just a tool and a library.
In lots of places on the web when you mention an Open Source project, you will also get the option to mention in which ecosystem it belongs. npm, go, rust, python etc. There are easily at least a dozen well-known and large ecosystems. curl is not part of any of those.
Recently there’s been a push for PURLs (Package URLs), for example when describing your specific package in a CVE. A package URL only works when the component is part of an ecosystem. curl is not. We can’t specify curl or libcurl using a PURL.
SBOM generators and related scanners use package managers to generate lists of used components and their dependencies. This makes these tools quite frequently just miss and ignore libcurl. It’s not listed by the package managers. It’s just in there, ready to be used. Like magic.
It is similarly hard for these tools to figure out that curl in turn also depends and uses other libraries. At build-time you select which – but as we in the curl project primarily just ships tarballs with source code we cannot tell anyone what dependencies their builds have. The additional libraries libcurl itself uses are all similarly outside of the standard ecosystems.
Part of the explanation for this is also that libcurl and curl are often shipped bundled with the operating system many times, or sometimes perceived to be part of the OS.
Most graphs, SBOM tools and dependency trackers therefore stop at the binding or system that uses curl or libcurl, but without including curl or libcurl. The layer above so to speak. This makes it hard to figure out exactly how many components and how much software is depending on libcurl.
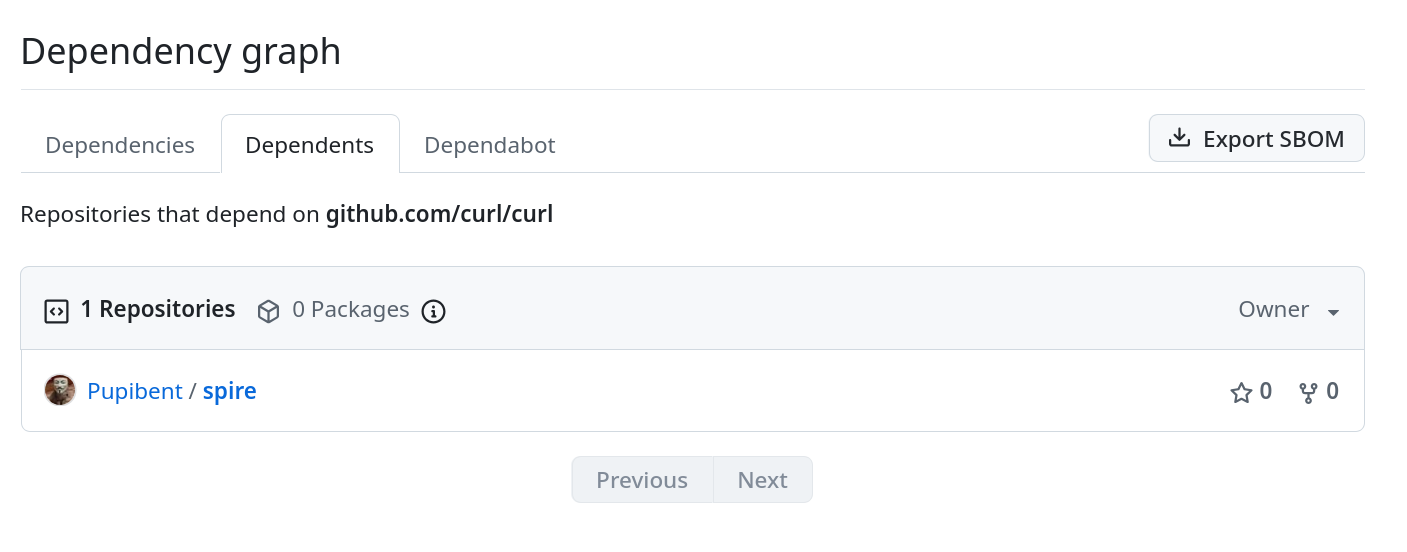
A perfect way to illustrate the problem is to check GitHub and see how many among its vast collection of many millions of repositories that depend on curl. After all, curl is installed in some thirty billion installations, so clearly it used a lot. (Most of them being libcurl of course.)
It lists one dependency for curl.
Repositories that depend on curl/curl: one. Screenshot taken on March 9, 2026
What makes this even more amusing is that it looks like this single dependent repository (Pupibent/spire) lists curl as a dependency by mistake.
The Linux Foundation, the organization that we want to love but that so often makes that a hard bargain, has created something they call “Insights” where they gather lots of metrics on Open Source projects.
I held back so I never blogged and taunted OpenSSF for their scorecard attempts that were always lame and misguided. This Insights thing looks like their next attempt to “grade” and “rate” Open Source. It is so flawed and full of questionable details that I decided there is no point in me listing them all in a blog post – it would just be too long and boring. Instead I will just focus on a single metric. The one that made me laugh out loud when I saw it.
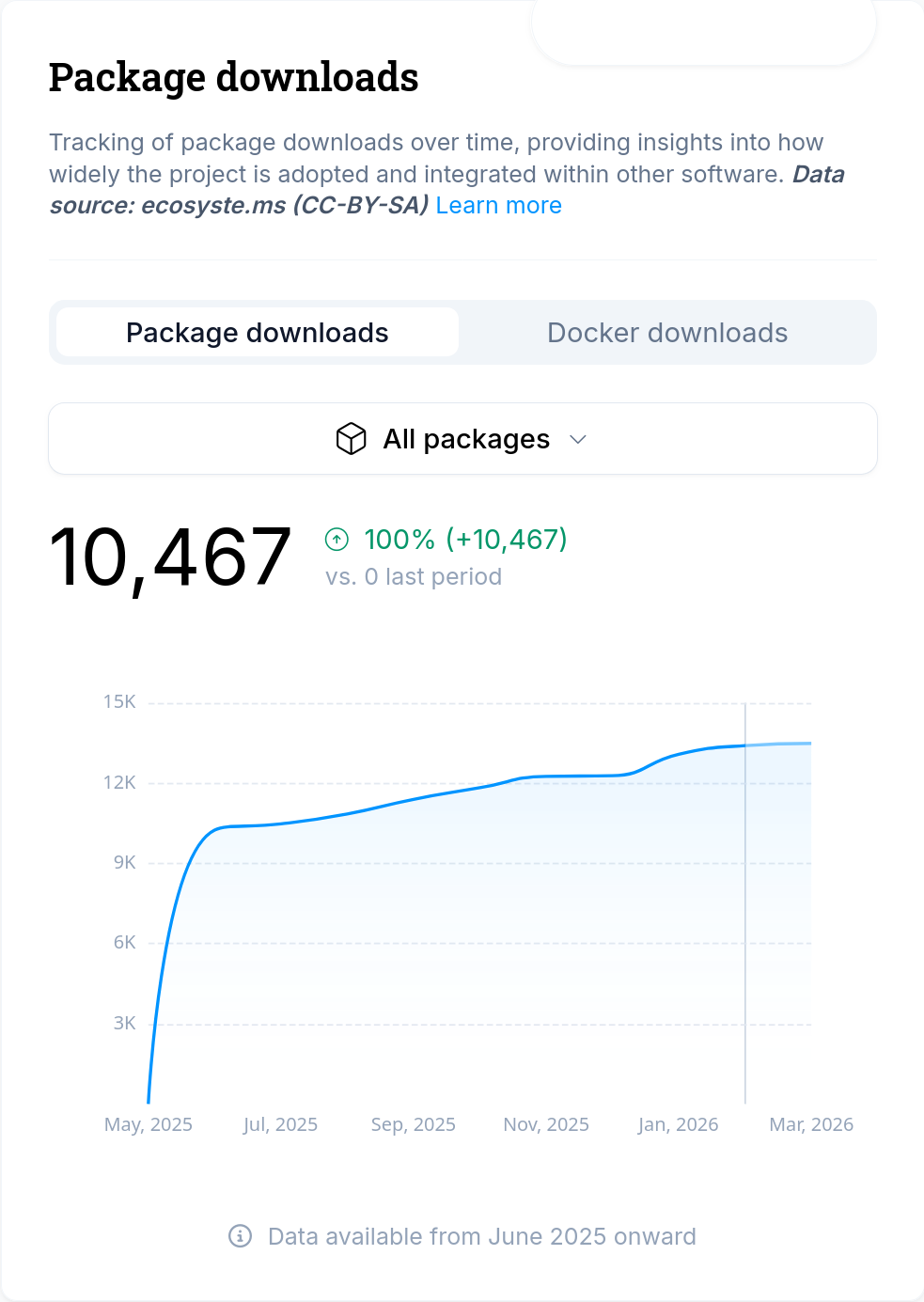
Package downloads
They claim curl was downloaded 10,467 times the last year. (source)
Number of curl downloads the last 365 days according to Linux Foundation
What does “a download” mean? They refer to statistics from ecosyste.ms, which is an awesome site and service, but it has absolutely no idea about curl downloads.
How often is curl “downloaded”?
curl release tarballs are downloaded from curl.se at a rate of roughly 250,000 / month.
curl images are currently pulled from docker at a rate of around 400,000 – 700,000 / day. curl is pulled from quay.io at roughly the same rate.
curl’s git repository is cloned roughly 32,000 times / day
curl is installed from Linux and BSD distributions at an unknown rate.
curl, in the form of libcurl, is bundled in countless applications, games, devices, cars, TVs, printers and services, and we cannot even guess how often it is downloaded as such an embedded component.
curl is installed by default on every Windows and macOS system since many years back.
The annual curl users and developers meeting, curl up, takes place May 23-24 2026 in Prague, Czechia.
We are in fact returning to the same city and the exact same venue as in 2025. We liked it so much!
curl up
This is a cozy and friendly event that normally attracts around 20-30 attendees. We gather in a room through a weekend and we talk curl. The agenda is usually setup with a number of talks through the two days, and each talk ends with a follow-up Q&A and discussion session. So no big conference thing, just a bunch of friends around a really large table. Over a weekend.
Anyone is welcome to attend – for free – and everyone is encouraged to submit a talk proposal – anything that is curl and Internet transfer related goes.
We make an effort to attract and lure the core curl developers and the most active contributors of recent years into the room. We do this by reimbursing their travel and hotel expenses.
Agenda
The agenda is a collaborative effort and we are going to work on putting it together from now all the way until the event, in order to make sure we make the best of the weekend and we get to talk to and listen to all the curl related topics we can think of!
Meeting up in the real world as opposed to doing video meetings helps us get to know each other better, allows us to socialize in ways we otherwise never can do and in the end it helps us work better together – which subsequently helps us write better code and produce better outcomes!
It also helps us meet and welcome newcomers and casual contributors. Showing up at curl up is an awesome way to dive into the curl world wholeheartedly and in the deep end.
Sponsor
Needless to say this event costs money to run. We pay our top people to come, we pay for the venue and pay for food.
We would love to have your company mentioned as top sponsor of the event or perhaps a social dinner on the Saturday? Get in touch and let’s get it done!
Attend!
Everyone is welcome and encouraged to attend – at no cost. We only ask that you register in advance (the registration is not open yet).
Video
We always record all sessions on video and make them available after the fact. You can catch up on previous years’ curl up sessions on the curl website’s video section.
We also live-stream all the sessions on curl up during both days. To be found on my twitch channel: curlhacker.
Friendly
Our events are friendly to everyone. We abide to the code of conduct and we never had anyone be even close to violating that,
When we announced the end of the curl bug-bounty at the end of January 2026, we simultaneously moved over and started accepting curl security reports on GitHub instead of its previous platform.
This move turns out to have been a mistake and we are now undoing that part of the decision. The reward money is still gone, there is no bug-bounty, no money for vulnerability reports, but we return to accepting and handling curl vulnerability and security reports on Hackerone. Starting March 1st 2026, this is now (again) the official place to report security problems to the curl project.
This zig-zagging is unfortunate but we do it with the best of intentions. In the curl security team we were naively thinking that since so many projects are already using this setup it should be good enough for us too since we don’t have any particular special requirements. We wrongly thought. Now I instead question how other Open Source projects can use this. It feels like an area and use case for Open Source projects that is under-focused: proper, secure and efficient vulnerability reporting without bug-bounty.
What we want from a security reporting system
To illustrate what we are looking for, I made a little list that should show that we’re not looking for overly crazy things.
Incoming submissions are reports that identify security problems.
The reporter needs an account on the system.
Submissions start private; only accessible to the reporter and the curl security team
All submissions must be disclosed and made public once dealt with. Both correct and incorrect ones. This is important. We are Open Source. Maximum transparency is key.
There should be a way to discuss the problem amongst security team members, the reporter and per-report invited guests.
It should be possible to post security-team-only messages that the reporter and invited guests cannot see
For confirmed vulnerabilities, an advisory will be produced that the system could help facilitate
If there’s a field for CVE, make it possible to provide our own. We are after all our own CNA.
Closed and disclosed reports should be clearly marked as invalid/valid etc
Reports should have a tagging system so that they can be marked as “AI slop” or other terms for statistical and metric reasons
Abusive users should be possible to ban/block from this program
Additional (customizable) requirements for the privilege of submitting reports is appreciated (rate limit, time since account creation, etc)
What’s missing in GitHub’s setup?
Here is a list of nits and missing features we fell over on GitHub that, had we figured them out ahead of time, possibly would have made us go about this a different way. This list might interest fellow maintainers having the same thoughts and ideas we had. I have provided this feedback to GitHub as well – to make sure they know.
GitHub sends the whole report over email/notification with no way to disable this. SMTP and email is known for being insecure and cannot assure end to end protection. This risks leaking secrets early to the entire email chain.
We can’t disclose invalid reports (and make them clearly marked as such)
Per-repository default collaborators on GitHub Security Advisories is annoying to manage, as we now have to manually add the security team for each advisory or have a rather quirky workflow scripting it. https://github.com/orgs/community/discussions/63041
We can’t edit the CVE number field! We are a CNA, we mint our own CVE records so this is frustrating. This adds confusion.
We want to (optionally) get rid of the CVSS score + calculator in the form as we actively discourage using those in curl CVE records
No CI jobs working in private forks is going to make us effectively not use such forks, but is not a big obstacle for us because of our vulnerability working process. https://github.com/orgs/community/discussions/35165
No “quote” in the discussions? That looks… like an omission.
We want to use GitHub’s security advisories as the report to the project, not the final advisory (as we write that ourselves) which might get confusing, as even for the confirmed ones, the project advisories (hosted elsewhere) are the official ones, not the ones on GitHub
No number of advisories count is displayed next to “security” up in the tabs, like for issues and Pull requests. This makes it hard to see progress/updates.
When looking at an individual advisory, there is no direct button/link to go back to the list of current advisories
In an advisory, you can only “report content”, there is no direct “block user” option like for issues
There is no way to add private comments for the team-only, as when discussing abuse or details not intended for the reporter or other invited persons in the issue
There is a lack of short (internal) identifier or name per issue, which makes it annoying and hard to refer to specific reports when discussing them in the security team. The existing identifiers are long and hard to differentiate from each other.
You quite weirdly cannot get completion help for @nick in comments to address people that were added into the advisory thanks to them being in a team you added to the issue?
There are no labels, like for issues and pull requests, which makes it impossible for us to for example mark the AI slop ones or other things, for statistics, metrics and future research
Email?
Sure, we could switch to handling them all over email but that also has its set of challenges. Including:
Hard to keep track of the state of each current issue when a number of them are managed in parallel. Even just to see how many cases are still currently open or in need of attention.
Hard to publish and disclose the invalid ones, as they never cause an advisory to get written and we rather want the initial report and the full follow-up discussion published.
Hard to adapt to or use a reputation system beyond just the boolean “these people are banned”. I suspect that we over time need to use more crowdsourced knowledge or reputation based on how the reporters have behaved previously or in relation to other projects.
Onward and upward
Since we dropped the bounty, the inflow tsunami has dried out substantially. Perhaps partly because of our switch over to GitHub? Perhaps it just takes a while for all the sloptimists to figure out where to send the reports now and perhaps by going back to Hackerone we again open the gates for them? We just have to see what happens.
We will keep iterating and tweaking the program, the settings and the hosting providers going forward to improve. To make sure we ship a robust and secure set of products and that the team doing so can do that
Gitlab, Codeberg and others are GitHub alternatives and competitors, but few of them offer this kind of security reporting feature. That makes them bad alternatives or replacements for us for this particular service.
Last spring I wrote a blog post about our ongoing work in the background to gradually simplify the curl source code over time.
This is a follow-up: a status update of what we have done since then and what comes next.
In May 2025 I had just managed to get the worst function in curl down to complexity 100, and the average score of all curl production source code (179,000 lines of code) was at 20.8. We had 15 functions still scoring over 70.
Almost ten months later we have reduced the most complex function in curl from 100 to 59. Meaning that we have simplified a vast number of functions. Done by splitting them up into smaller pieces and by refactoring logic. Reviewed by humans, verified by lots of test cases, checked by analyzers and fuzzers,
The current 171,000 lines of code now has an average complexity of 15.9.
Complexity
The complexity score in this case is just the cold and raw metric reported by the pmccabe tool. I decided to use that as the absolute truth, even if of course a human could at times debate and argue about its claims. It makes it easier to just obey to the tool, and it is quite frankly doing a decent job at this so it’s not a problem.
How to simplify
In almost all cases the main problem with complex functions is that they do a lot of things in a single function – too many – where the functionality performed could or should rather be split into several smaller sub functions. In almost every case it is also immediately obvious that when splitting a function into two, three or more sub functions with smaller and more specific scopes, the code gets easier to understand and each smaller function is subsequently easier to debug and improve.
Development
I don’t know how far we can take the simplification and what the ideal average complexity score of a the curl code base might be. At some point it becomes counter-effective and making functions even smaller then just makes it harder to follow code flows and absorbing the proper context into your head.
Graphs
To illustrate our simplification journey, I decided to render graphs with a date axle starting at 2022-01-01 and ending today. Slightly over four years, representing a little under 10,000 git commits.
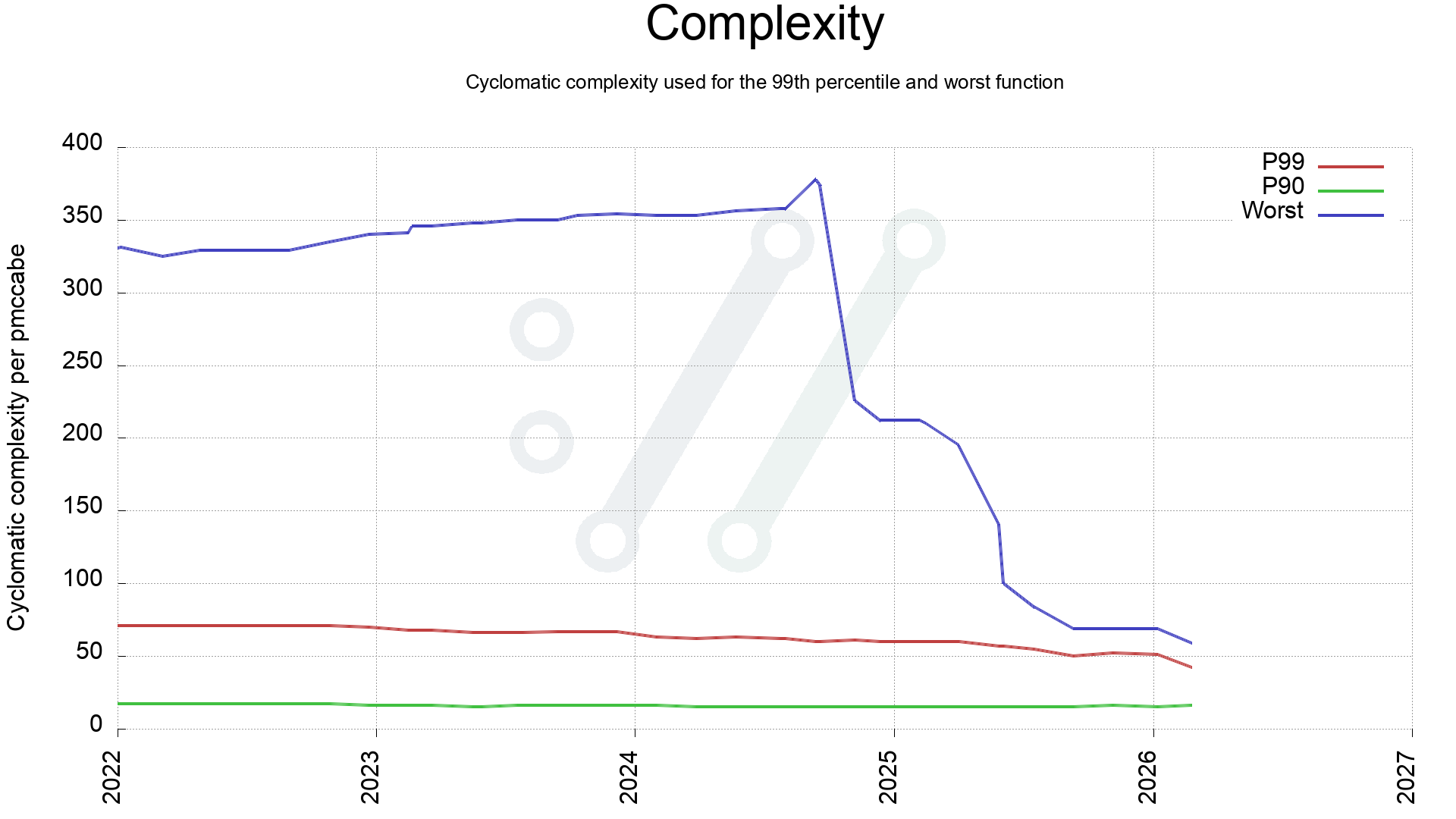
First, a look a the complexity of the worst scored function in curl production code over the last four years. Comparing with P90 and P99.
The most complex function in curl over time
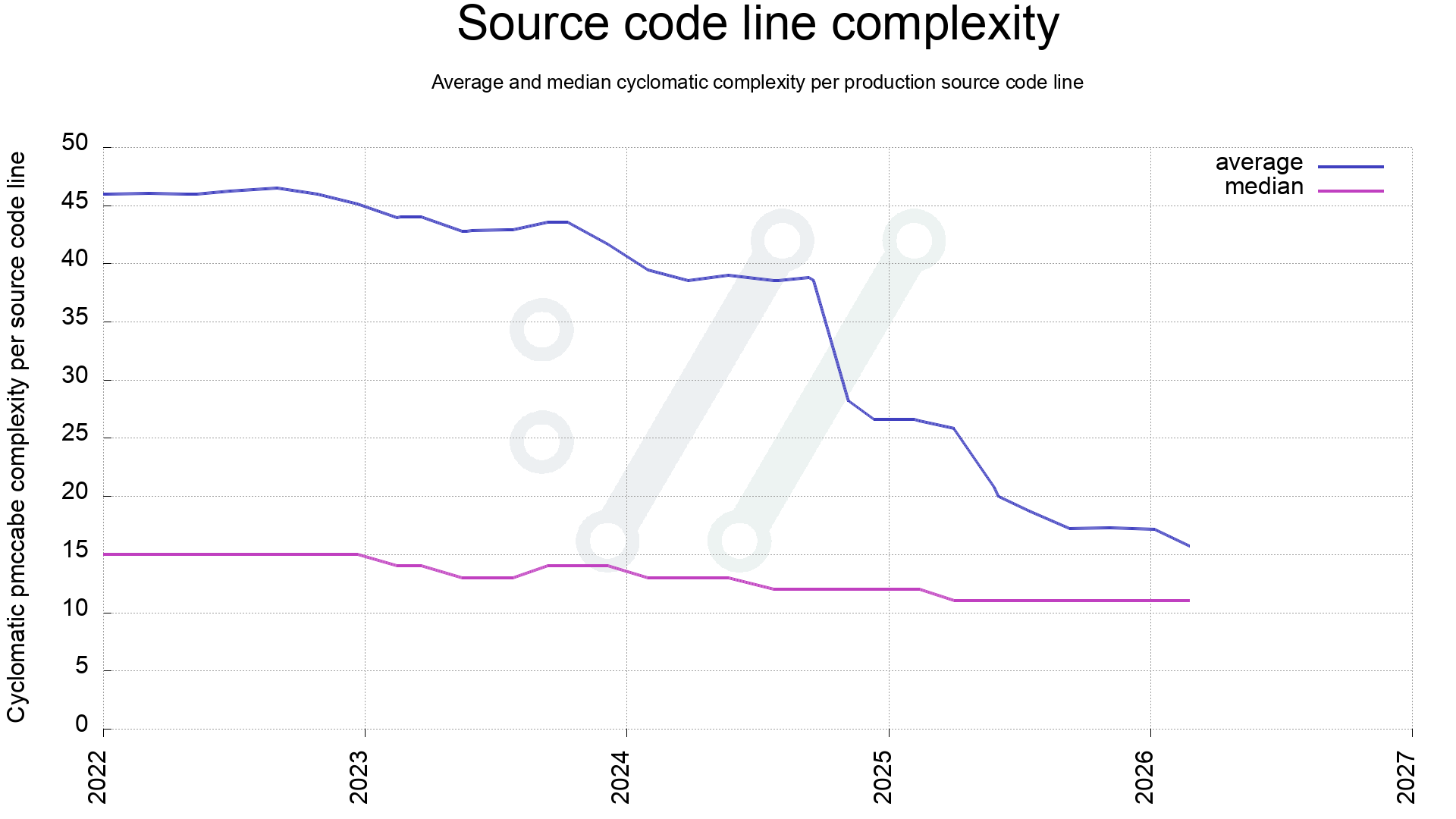
Identifying the worst function might not say too much about the code in general, so another check is to see how the average complexity has changed. This is calculated like this:
All functions get a complexity score by pmccabe
Each function has a number of lines
For all functions, add its function-score x function-length to a total complexity score, and in the end, divide that total complexity score on total number of lines used for all functions. Also do the same for a median score.
Average and median complexity per source code line in curl, over time.
When 2022 started, the average was about 46 and as can be seen, it has been dwindling ever since, with a few steep drops when we have merged dedicated improvement work.
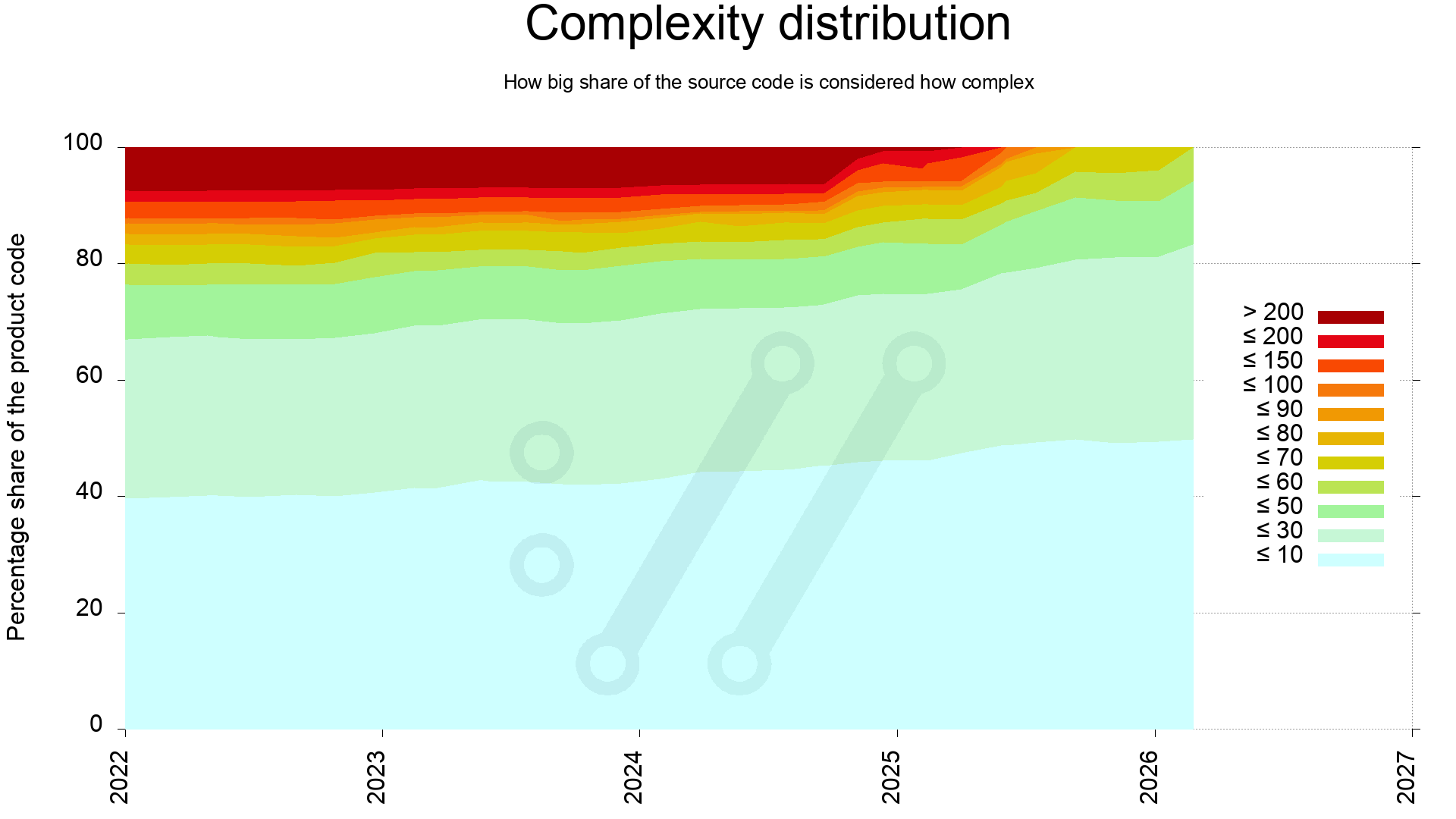
One way to complete the average and median lines to offer us a better picture of the state, is to investigate the complexity distribution through-out the source code.
How big portion of the curl source code is how complex
This reveals that the most complex quarter of the code in 2022 has since been simplified. Back then 25% of the code scored above 60, and now all of the code is below 60.
It also shows that during 2025 we managed to clean up all the dark functions, meaning the end of 100+ complexity functions. Never to return, as the plan is at least.
Does it matter?
We don’t really know. We believe less complex code is generally good for security and code readability, but it is probably still too early for us to be able to actually measure any particular positive outcome of this work (apart from fancy graphs). Also, there are many more ways to judge code than by this complexity score alone. Like having sensible APIs both internal and external and making sure that they are properly and correctly documented etc. The fact that they all interact together and they all keep changing, makes it really hard to isolate a single factor like complexity and say that changing this alone is what makes an impact.
Additionally: maybe just the refactor itself and the attention to the functions when doing so either fix problems or introduce new problems, that is then not actually because of the change of complexity but just the mere result of eyes giving attention on that code and changing it right then.
Maybe we just need to allow several more years to pass before any change from this can be measured?