You might know that I’ve posted funny emails I’ve received on my blog several times in the past. The kind of emails people send me when they experience problems with some device they own (like a car) and they contact me because my email address happens to be visible somewhere.
People sometimes say I should get a different email address or use another one in the curl license file, but I’ve truly never had a problem with these emails, as they mostly remind me about the tough challenges the modern technical life bring to people and it gives me insights about what things that run curl.
But not all of these emails are “funny”.
Category: not funny
Today I received the following email
From: Al Nocai <[redacted]@icloud.com> Date: Fri, 19 Feb 2021 03:02:24 -0600 Subject: I will slaughter you
That subject.
As an open source maintainer since over twenty years, I know flame wars and personal attacks and I have a fairly thick skin and I don’t let words get to me easily. It took me a minute to absorb and realize it was actually meant as a direct physical threat. It found its ways through and got to me. This level of aggressiveness is not what I’m prepared for.
Attached in this email, there were seven images and no text at all. The images all look like screenshots from a phone and the first one is clearly showing source code I wrote and my copyright line:
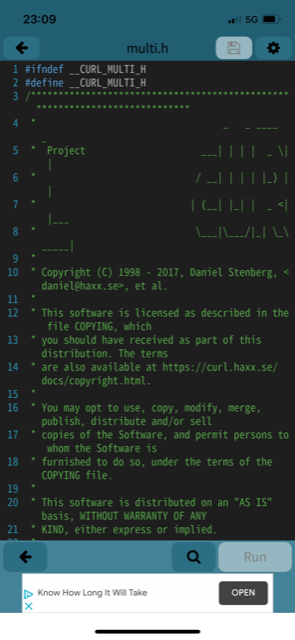
The other images showed other source code and related build/software info of other components, but I couldn’t spot how they were associated with me in any way.
No explanation, just that subject and the seven images and I was left to draw my own conclusions.
I presume the name in the email is made up and the email account is probably a throw-away one. The time zone used in the Date: string might imply US central standard time but could of course easily be phony as well.
How I responded
Normally I don’t respond to these confused emails because the distance between me and the person writing them is usually almost interplanetary. This time though, it was so far beyond what’s acceptable to me and in any decent society I couldn’t just let it slide. After I took a little pause and walked around my house for a few minutes to cool off, I wrote a really angry reply and sent it off.
This was a totally and completely utterly unacceptable email and it hurt me deep in my soul. You should be ashamed and seriously reconsider your manners.
I have no idea what your screenshots are supposed to show, but clearly something somewhere is using code I wrote. Code I have written runs in virtually every Internet connected device on the planet and in most cases the users download and use it without even telling me, for free.
Clearly you don’t deserve my code.
I don’t expect that it will be read or make any difference.
Update below, added after my initial post.
Al Nocai’s response
Contrary to my expectations above, he responded. It’s not even worth commenting but for transparency I’ll include it here.
I do not care. Your bullshit software was an attack vector that cost me a multimillion dollar defense project.
Your bullshit software has been used to root me and multiple others. I lost over $15k in prototyping alone from bullshit rooting to the charge arbitrators.
I have now since October been sandboxed because of your bullshit software so dipshit google kids could grift me trying to get out of the sandbox because they are too piss poor to know shat they are doing.
You know what I did to deserve that? I tried to develop a trade route in tech and establish project based learning methodologies to make sure kids aren’t left behind. You know who is all over those god damn files? You are. Its sickening. I got breached in Oct 2020 through federal server hijacking, and I owe a great amount of that to you.
Ive had to sit and watch as i reported:
- fireeye Oct/2020
- Solarwinds Oct/2020
- Zyxel Modem Breach Oct/2020
- Multiple Sigover attack vectors utilizing favicon XML injection
- JS Stochastic templating utilizing comparison expressions to write to data registers
- Get strong armed by $50billion companies because i exposed bullshit malware
And i was rooted and had my important correspondence all rerouted as some sick fuck dismantled my life with the code you have your name plastered all over. I cant even leave the country because of the situation; qas you have so effectively built a code base to shit all over people, I dont give a shit how you feel about this.
You built a formula 1 race car and tossed the keys to kids with ego problems. Now i have to deal with Win10 0-days because this garbage.
I lost my family, my country my friends, my home and 6 years of work trying to build a better place for posterity. And it has beginnings in that code. That code is used to root and exploit people. That code is used to blackmail people.
So no, I don’t feel bad one bit. You knew exactly the utility of what you were building. And you thought it was all a big joke. Im not laughing. I am so far past that point now.
/- Al
Al continues
Nine hours after I first published this blog post , Al replied again with two additional emails. His third and forth emails to me.
Email 3:
https://davidkrider.com/i-will-slaughter-you-daniel-haxx-se/
Step up. You arent scaring me. What led me here? The 5th violent attempt on my life. Apple terms of service? gtfo, thanks for the platform.
Amusingly he has found a blog post about my blog post.
Email 4:
There is the project: MOUT Ops Risk Analysis through Wide Band Em Spectrum analysis through different fourier transforms.
You and whoever the fuck david dick rider is, you are a part of this.
Federal server breaches-
Accomplice to attempted murder-
Fraud-
just a few.
I have talked to now: FBI FBI Regional, VA, VA OIG, FCC, SEC, NSA, DOH, GSA, DOI, CIA, CFPB, HUD, MS, Convercent, as of today 22 separate local law enforcement agencies calling my ass up and wasting my time.
You and dick ridin’ dave are respinsible. I dont give a shit, call the cops. I cuss them out wheb they call and they all go silent.
I’ve kept his peculiar formatting and typos. In email 4 there was also a PDF file attached named BustyBabes 4.pdf. It is apparently a 13 page document about the “NERVEBUS NERVOUS SYSTEM” described in the first paragraph as “NerveBus Nervous System aims to be a general utility platform that provides comprehensive and complex analysis to provide the end user with cohesive, coherent and “real-time” information about the environment it monitors.”. There’s no mention of curl or my name in the document.
Since I don’t know the status of this document I will not share it publicly, but here’s a screenshot of the front page:

Related
This topic on hacker news and reddit.
I have reported the threat to the Swedish police (where I live).
This person would later apologize.