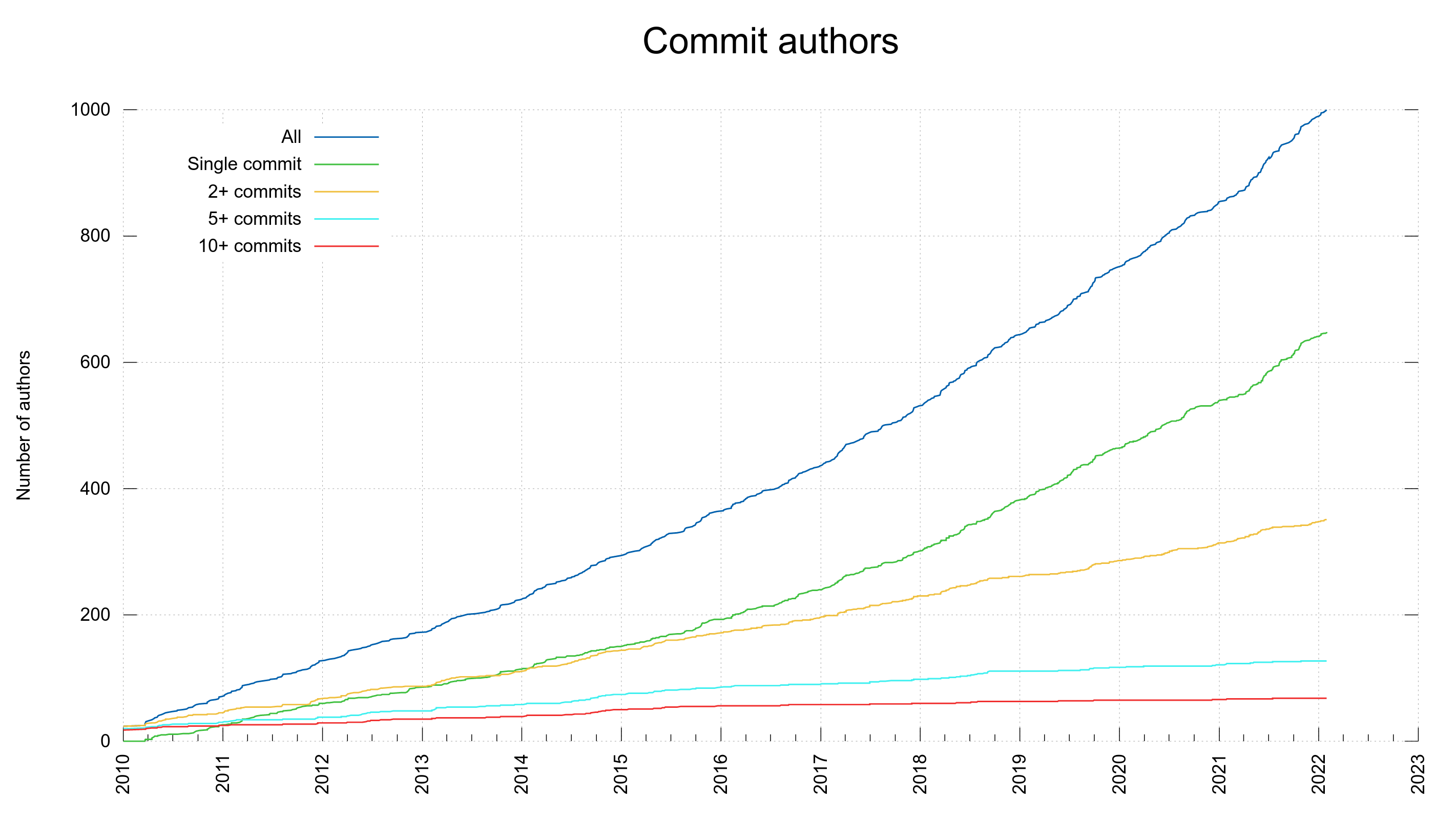
The number of commit authors in curl has gradually been increasing over time.
1998-03-20: 1 author recorded in the premiere curl release. It actually took until May 30th 2001 for the second recorded committer (partly of course because we used CVS). 1167 days to bump up the number one notch.
2014-05-06: 250 authors took 5891 days to reach.
2017-08-18: 500 authors required additional 1200 days
2019-12-20: 750 authors was reached after only 854 more days
2022-01:30: reaching 1000 authors took an additional 772 days.
Jan-Piet Mens became the thousandth author by providing pull-request #8354.
These 1,000 authors have done in total 28,163 commits. This equals 28.2 commits on average while the median commit author only did a single one – more than 60% of the authors are one-time committers after all! Only fourteen persons in the project have authored more than one hundred commits.
It took us 8,717 days to reach 1,000 authors, making it one new committer in the project per 8.7 days on average, over the project’s life time so far. The latest 250 authors have “arrived” at a rate of one new author per 3.1 days.
In 2021 we had more commit authors than ever before and also more first-timers than ever. It will certainly be a challenge to reach that same level or maybe even break the record again in 2022.
It took almost 24 years to reach 1,000 authors. How long until we double this?
Visualized on video
To celebrate this occasion, I did a fresh gource video of curl development so far; for the duration of the first 1,000 committers. I spiced it up by adding 249 annotations of source related facts laid out in time.
If you look at the curl/curl repository on GitHub, it appears to be short of a few hundred committers. It says 792 right now.
This is because GitHub can’t count commit authors. The theory is that they somehow ignore committers that do not have GitHub accounts. My author count is instead based on plain git access and standard git commands run against a plain git clone:
On Friday January 21, 2022 I received this email. I tweeted about it and it took off like crazy.
The email comes from a fortune-500 multi-billion dollar company that apparently might be using a product that contains my code, or maybe they have customers who do. Who knows?
My guess is that they do this for some compliance reasons and they “forgot” that their open source components are not automatically provided by “partners” they can just demand this information from.
I answered the email very briefly and said I will be happy to answer with details as soon as we have a support contract signed.
I think maybe this serves as a good example of the open source pyramid and users in the upper layers not at all thinking of how the lower layers are maintained. Building a house without a care about the ground the house stands on.
In my tweet and here in my blog post I redact the name of the company. I most probably have the right to tell you who they are, but I still prefer to not. (Especially if I manage to land a profitable business contract with them.) I suspect we can find this level of entitlement in many companies.
The level of ignorance and incompetence shown in this single email is mind-boggling.
While they don’t even specifically say which product they are using, no code I’ve ever been involved with or have my copyright use log4j and any rookie or better engineer could easily verify that.
In the picture version of the email I padded the name fields to better anonymize the sender, and in the text below I replaced them with NNNN.
(And yes, it is very curious that they send queries about log4j now, seemingly very late.)
Continue down for the reply.
The email
Dear Haxx Team Partner,
You are receiving this message because NNNN uses a product you developed. We request you review and respond within 24 hours of receiving this email. If you are not the right person, please forward this message to the appropriate contact.
As you may already be aware, a newly discovered zero-day vulnerability is currently impacting Java logging library Apache Log4j globally, potentially allowing attackers to gain full control of affected servers.
The security and protection of our customers' confidential information is our top priority. As a key partner in serving our customers, we need to understand your risk and mitigation plans for this vulnerability.
Please respond to the following questions using the template provided below.
1. If you utilize a Java logging library for any of your application, what Log4j versions are running?
2. Have there been any confirmed security incidents to your company?
3. If yes, what applications, products, services, and associated versions are impacted?
4. Were any NNNN product and services impacted?
5. Has NNNN non-public or personal information been affected?
6. If yes, please provide details of affected information NNNN immediately.
7. What is the timeline (MM/DD/YY) for completing remediation? List the NNNN steps, including dates for each.
8. What action is required from NNNN to complete this remediation?
In an effort to maintain the integrity of this inquiry, we request that you do not share information relating to NNNN outside of your company and to keep this request to pertinent personnel only.
Thank you in advance for your prompt attention to this inquiry and your partnership!
Sincerely,
NNNN Information Security
The information contained in this message may be CONFIDENTIAL and is for the intended addressee only. Any unauthorized use, dissemination of the information, or copying of this message is prohibited. If you are not the intended addressee, please notify the sender immediately and delete this message.
Their reply
On January 24th I received this response, from the same address and it quotes my reply so I know they got it fine.
Hi David,
Thank you for your reply. Are you saying that we are not a customer of your organization?
/ [a first name]
My second reply
I replied again (22:29 CET on Jan 24) to this mail that identified me as “David”. Now there’s this great story about a David and some giant so I couldn’t help myself…
Hi Goliath,
No, you have no established contract with me or anyone else at Haxx whom you addressed this email to, asking for a lot of information. You are not our customer, we are not your customer. Also, you didn't detail what product it was regarding.
So, we can either establish such a relationship or you are free to search for answers to your questions yourself.
I can only presume that you got our email address and contact information into your systems because we produce a lot of open source software that are used widely.
Best wishes,
Daniel
The image version of the initial email
The company
Update on February 9: The email came from MetLife.
The well-known log4j security vulnerability of December 2021 triggered a lot of renewed discussions around software supply chain security, and sometimes it has also been said to be an Open Source related issue.
This was not the first software component to have a serious security flaw, and it will not be the last.
What can we do about it?
This is the 10,000 dollar question that is really hard to answer. In this post I hope to help putting some light on to why it is such a hard problem. This comes from my view as an Open Source author and contributor since almost three decades now.
In this post I’m going to talk about security as in how we make our products have less bugs in the code we write and land on purpose. There is also a lot to be said about infrastructure problems such as consumers not verifying dependencies so that when malicious actors purposely destroy a component, users of that don’t notice the problem or supply chain security issues that risk letting bad actors insert malicious code into components. But those are not covered in this blog post!
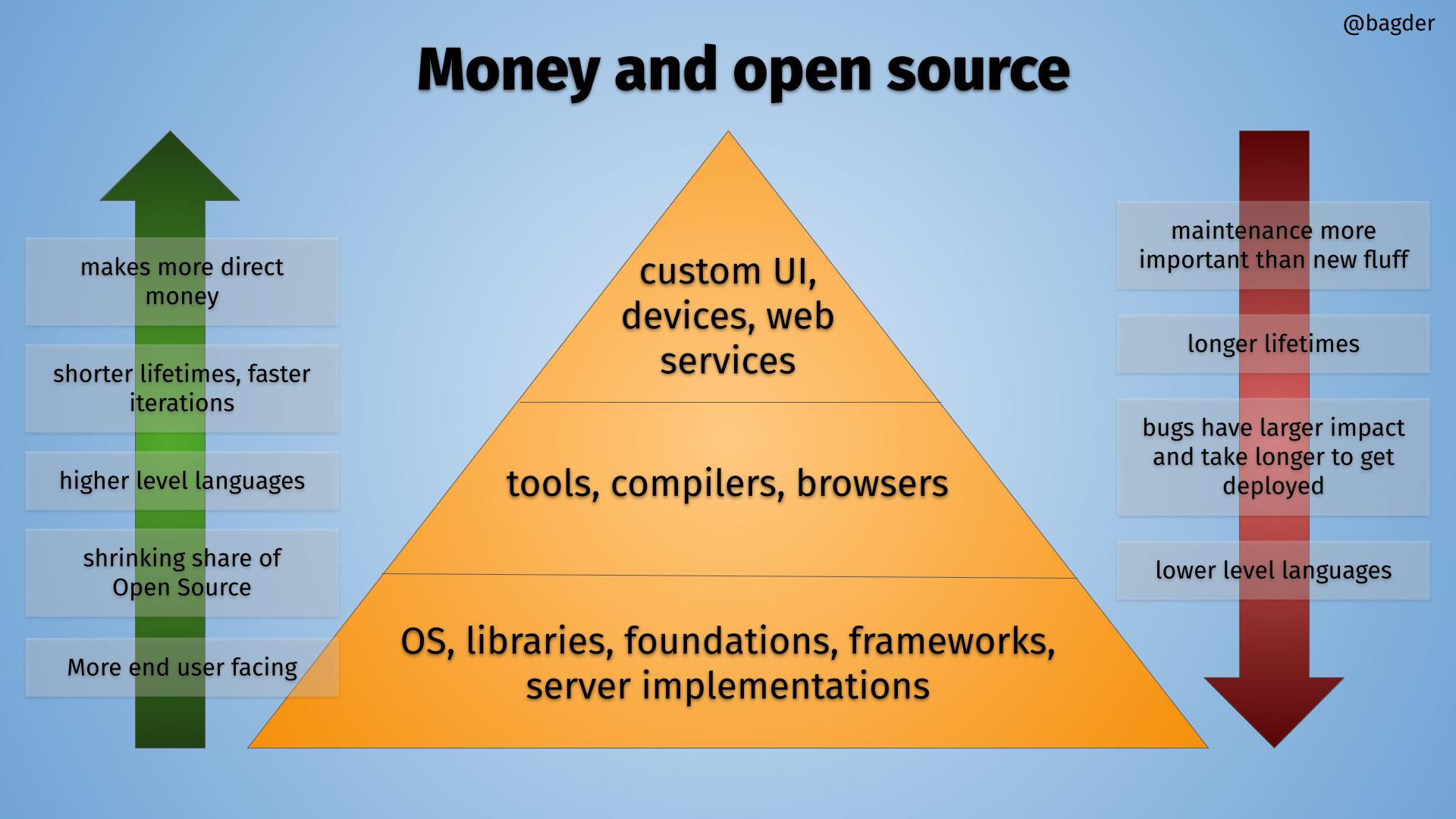
The OSS Pyramid
I think we can view the world of software and open source as a pyramid, and I made this drawing to illustrate.
The OSS pyramid, click for bigger version.
Inside the pyramid there is a hierarchy where things using software are build on top of others, in layers. The higher up you go, the more you stand on the shoulders of open source components below you.
At the very bottom of the pyramid are the foundational components. Operating systems and libraries. The stuff virtually everything runs or depends upon. The components you really don’t want to have serious security vulnerabilities.
Going upwards
In the left green arrow, I describe the trend if you look at software when climbing upwards the pyramid.
Makes more direct money
Shorter lifetimes, faster iterations
Higher level languages
Shrinking share of Open Source
More end user facing
At the top, there are a lot of things that are not Open Source. Proprietary shiny fronts with Open Source machines in the basement.
Going downwards
In the red arrow on the right, I describe the trend if you look at software when going downwards in the pyramid.
Maintenance is more important than new fluff
Longer lifetimes
Bugs have larger impact, fixes take longer to get deployed
Lower level languages
At the bottom, almost everything is Open Source. Each component in the bottom has countless users depending on them.
It is in the bottom of the pyramid each serious bug has a risk of impacting the world in really vast and earth-shattering ways. That is where tightening things up may have the most positive outcomes. (Even if avoiding problems is mostly invisible unsexy work.)
Zoom out to see the greater picture
We can argue about specific details and placements within the pyramid, but I think largely people can agree with the greater picture.
Skyscrapers using free bricks
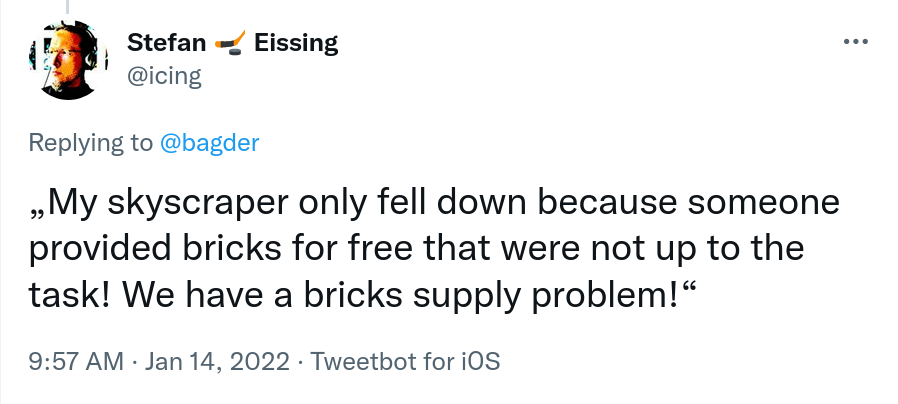
A little quote from my friend Stefan Eissing:
As a manufacturer of skyscrapers, we decided to use the free bricks made available and then maybe something bad happened with them. Where is the problem in this scenario?
Market economy drives “good enough”
As long as it is possible to earn a lot of money without paying much for the “communal foundation” you stand on, there is very little incentive to invest in or pay for maintenance of something – that also incidentally benefits your competitors. As long as you make (a lot of) money, it is fine if it is “good enough”.
Good enough software components will continue to have the occasional slip-ups (= horrible security flaws) and as long as those mistakes don’t truly hurt the moneymakers in this scenario, this world picture remains hard to change.
However, if those flaws would have a notable negative impact on the mountains of cash in the vaults, then something could change. It would of course require something extraordinary for that to happen.
What can bottom-dwellers do
Our job, as makers of bricks in the very bottom of the pyramid, is to remind the top brass of the importance of a solid foundation.
Our work is to convince a large enough share of software users higher up the stack that are relying on our functionality, that they are better off and can sleep better at night if they buy support and let us help them not fall into any hidden pitfalls going forward. Even if this also in fact indirectly helps their competitors who might rely on the very same components. Having support will at least put them in a better position than the ones who don’t have it, if something bad happens. Perhaps even make them avoid badness completely. Paying for maintenance of your dependencies help reduce the risk for future alarm calls far too early on a weekend morning.
This convincing part is often much easier said than done. It is only human to not anticipate the problem ahead of time and rather react after the fact when the problem already occurred. “We have used this free product for years without problems, why would we pay for it now?”
Software projects with sufficient funding to have engineer time spent on the code should be able to at least make serious software glitches rare. Remember that even the world’s most valuable company managed to ship the most ridiculous security flaw. Security is hard.
All producers of code should make sure dependencies of theirs are of high quality. High quality here, does not only mean that the code as of right now is working, but they should also make sure that the dependencies are run in ways that are likely to continue to produce good output.
This may require that you help out. Add resources. Provide funding. Run infrastructure. Whatever those projects may need to improve – if anything.
The smallest are better off with helping hands
I participate in a few small open source projects outside of curl. Small projects that produce libraries that are used widely. Not as widely as curl perhaps, but still millions and millions of users. Pyramid-bottom projects providing infrastructure for free for the moneymakers in the top. (I’m not naming them here because it doesn’t matter exactly which ones it is. As a reader I’m sure you know of several of this kind of projects.)
This kind of projects don’t have anyone working on the project full-time and everyone participates out of personal interest. All-volunteer projects.
Imagine that a company decides they want to help avoiding “the next log4j flaw” in such a project. How would that be done?
In the slightly larger projects there might be a company involved to pay for support or an individual working on the project that you can hire or contract to do work. (In this aspect, curl would for example count as a “slightly larger” kind.)
In these volunteers-only projects, all the main contributors work somewhere (else) and there is no established project related entity to throw money at to fix issues. In these projects, it is not necessarily easy for a contributor to take on a side project for a month or two – because they are employed to do something else during the days. Day-jobs have a habit of making it difficult to take a few weeks or months off for a side project.
Helping hands would, eh… help
Even the smallest projects tend to appreciate a good bug-fix and getting things from the TODO list worked on and landed. It also doesn’t add too much work load or requirements on the volunteers involved and it doesn’t introduce any money-problems (who would receive it, taxation, reporting, etc).
For projects without any existing way setup or available method to pay for support or contract work, providing man power is for sure a good alternative to help out. In many cases the very best way.
This of course then also moves the this is difficult part to the company that wants the improvement done (the user of it), as then they need to find that engineer with the correct skills and pay them for the allotted time for the job etc.
The entity providing such helping hands to smaller projects could of course also be an organization or something dedicated for this, that is sponsored/funded by several companies.
A general caution though: this creates the weird situation where the people running and maintaining the projects are still unpaid volunteers but people who show up contributing are getting paid to do it. It causes unbalances and might be cause for friction. Be aware. This needs to be done in close cooperating with the maintainers and existing contributors in these projects.
Not the mythical man month
Someone might object and ask what about this notion that adding manpower to a late software project makes it later? Sure, that’s often entirely correct for a project that already is staffed properly and has manpower to do its job. It is not valid for understaffed projects that most of all lack manpower.
Grants are hard for small projects
Doing grants is a popular (and easy from the giver’s perspective) way for some companies and organizations who want to help out. But for these all-volunteer projects, applying for grants and doing occasional short-term jobs is onerous and complicated. Again, the contributors work full-time somewhere, and landing and working short term on a project for a grant is then a very complicated thing to mix into your life. (And many employers actively would forbid employees to do it.)
Should you be able to take time off your job, applying for grants is hard and time consuming work and you might not even get the grant. Estimating time and amount of work to complete the job is super hard. How much do you apply for and how long will it take?
Some grant-givers even assume that you also will contribute so to speak, so the amount of money paid by the grant will not even cover your full-time wage. You are then, in effect, expected to improve the project by paying parts of the job yourself. I’m not saying this is always bad. If you are young, a student or early in your career that might still be perfect. If you are a family provider with a big mortgage, maybe less so.
In Nebraska since 2003
A more chaotic, more illustrative and probably more realistic way to show “the pyramid”, was done by Randall Munroe in his famous xkcd 2347 image, which, when applied onto my image looks like this:
Me shamelessly stealing image parts from xkcd 2347 to further make my point
Generalizing
Of course lots of projects in the bottom make money and are sufficiently staffed and conversely not all projects in the top are proprietary money printing business. This is a simplified image showing trends and the big picture. There will always be exceptions.
I have had my share of adventures with URL parsers and their differences in the past. The current state of my research on the topic of (failed) URL interoperability remains available in this GitHub document.
Use one and only one
There is still no common or standard URL syntax format in sight. A string that you think looks like a URL passed to one URL parser might be considered fine, but passed to a second parser it might be rejected or get interpreted differently. I believe the state of URLs in the wild has never before been this poor.
The problem
If you parse a URL with parser A and make conclusions about the URL based on that, and then pass the exact same URL to parser B and it draws different conclusions and properties from that, it opens up not only for strange behaviors but in some cases for downright security vulnerabilities.
This is easily done when you for example use two different libraries, frameworks or libraries that need to work on that URL, but the repercussions are not always easy to see at once.
The report EXPLOITING URL PARSERS: THE GOOD, BAD, AND INCONSISTENT (by Noam Moshe, Sharon Brizinov, Raul Onitza-Klugman and Kirill Efimov) was published today and I have had the privilege to have read and worked with the authors a little on this prior to its release.
As you see in the report, it shows that problems very similar to those mr Tsai reported and exploited back in 2017 are still present today, although perhaps in slightly different ways.
As the report shows, the problem is not only that there are different URL standards and that every implementation provides a parser that is somewhere in between both specs, but on top of that, several implementations often do not even follow the existing conflicting specifications!
The report authors also found and reported a bug in curl’s URL parser (involving percent encoded octets in host names) which I’ve subsequently fixed so if you use the latest curl that one isn’t present anymore.
curl’s URL API
In the curl project we attempt to help applications and authors to reduce the number of needed URL parsers in any given situation – to a large part as a reaction to the Tsai presentation from 2017 – with the URL API we introduced for libcurl in 2018.
Thanks to this URL parser API, if you are already using libcurl for transfers, it is easy to also parse and treat URLs elsewhere exactly the same way libcurl does. By sticking to the same parser, there is a significantly smaller risk that repeated parsing bring surprises.
Other work-arounds
If your application uses different languages or frameworks, another work-around to lower the risk that URL parsing differences will hurt you, is to use a single parser to extract the URL components you need in one place and then work on the individual components from that point on. Instead of passing around the full URL to get parsed multiple times, you can pass around the already separated URL parts.
Future
I am not aware of any present ongoing work on consolidating the URL specifications. I am not even aware of anyone particularly interested in working on it. It is an infected area, and I will get my share of blow-back again now by writing my own view of the state.
The WHATWG probably say they would like to be the steward of this and they are generally keen on working with URLs from a browser standpoint. It limits them to a small number of protocol schemes and from my experience, getting them to interested in changing something for the the sake of aligning with RFC 3986 parsers is hard. This is however the team that more than any other have moved furthest away from the standard we once had established. There are also strong anti-IETF sentiments oozing there. The WHATWG spec is a “living specification” which means it continues to change and drift away over time.
The IETF published RFC 3986 back in 2005, they saw the RFC 3987 pretty much fail and then more or less gave up on URLs. I know there are people and working groups there who would like to see URLs get brought back to the agenda (as I’ve talked to a few of them over the years) and many IETFers think that the IETF is the only group that can do it proper, but due to the unavoidable politics and the almost certain collision course against (and cooperation problems with) WHATWG, it is considered a very hot potato that barely anyone wants to hold. There are also strong anti-WHATWG feelings in some areas of the IETF. There is just a too small of a chance of a successful outcome from something that mostly likely will take a lot of effort, will, thick skin and backing from several very big companies.
We are stuck here. I foresee yet another report to be written a few years down the line that shows more and new URL problems.
As usual, here’s a set of selected favorite bug-fixes of mine from this cycle:
require “see also” for every documented option in curl.1
When the curl command man page is generated at build time, the script now makes sure that there is a “see also” for each option. This will help users find related info. More mandatory information for each option makes us do better documentation that ultimately helps users.
lazy-alloc the table in Curl_hash_add()
The internal hash functions moved the allocation of the actual hash table from the init() function to when the first add() is called to add something to the table. This delay simplified code (when the init function became infallible ) and does even avoid a few allocs in many cases.
enable haproxy support for hyper backend
Plus a range of code and test cases adjusted to make curl built with hyper run better. There are now less than 30 test cases still disabled for hyper. We are closing in!
mbedTLS: add support for CURLOPT_CAINFO_BLOB
Users of this backend can now also use this feature that allows applications to provide a CA cert store in-memory instead of using an external file.
multi: handle errors returned from socket/timer callbacks
It was found out that the two multi interface callbacks didn’t at all treat errors being returned the way they were documented to do. They are now, and the documentation was also expanded to clarify.
nss:set_cipher don’t clobber the cipher list
Applications that uses libcurl built to use NSS found out that if they would select cipher, they would also effectively prevent connections from being reused due to this bug.
openldap: implement STARTTLS
curl can now switch LDAP transfers into LDAPS using the STARTTLS command much like how it already works for the email protocols. This ability is so far limited to LDAP powered by OpenLDAP.
openssl: define HAVE_OPENSSL_VERSION for OpenSSL 1.1.0+
This little mistake made libcurl use the wrong method to extract and show the OpenSSL version at run-time, which most notably would make libcurl say the wrong version for OpenSSL 3.0.1, which would rather show up as the non-existing version 3.0.0a.
sha256/md5: return errors when init fails
A few internal functions would simply ignore errors from these hashing functions instead of properly passing them back to the caller, making them to rather generate the wrong hash instead of properly and correctly returning an error etc.
curl: updated search for a file in the homedir
The curl tool now searches for personal config files in a slightly improved manner, to among other things make it find the same .known_hosts file on Windows as the Microsoft provided ssh client does.
url: check ssl_config when re-use proxy connection
A bug in the logic for checking connections in the connection pool suitable for reuse caused flaws when doing subsequent HTTPS transfers to servers over the same HTTPS proxy.
ngtcp2: verify server certificate
When doing HTTP/3 transfers, libcurl is now doing proper server certificate verification for the QUIC connection – when the ngtcp2 backend is used. The quiche backend is still not doing this, but really should.
urlapi: accept port number zero
Years ago I wrote a blog post about using port zero in URLs to do transfers. Then it turned out port zero did not work like that with curl anymore so work was done and now order is restored again and port number zero is once again fine to use for curl.
urlapi: provide more detailed return codes
There are a whole range of new error codes introduced that help better identify and pinpoint what the problem is when a URL or a part of a URL cannot be parsed or will not be accepted. Instead of the generic “failed to parse URL”, this can now better tell the user what part of the URL that was found out to be bad.
socks5h: use appropriate ATYP for numerical IP address
curl supports using SOCKS5 proxies and asking the proxy to resolve the host name, what we call socks5h. When using this protocol and using a numerical IP address in the URL, curl would use the SOCKS protocol slightly wrong and pass on the wrong “ATYP” parameter which a strict proxy might reject. Fixed now.
Coming up?
The curl factory never stops. There are many pull-requests already filed and in the pipeline of possibly getting merged. There will also, without any doubts, be more ones coming up that none of us have yet thought about or considered. Existing pending topics might include:
the ManageSieve protocol
--no-clobber
CURLMOPT_STREAM_WINDOW_SIZE
Remove Mesalink support
HAproxy protocol v2
WebSockets
Export/import SSL session-IDs
HTTP/3 fixes
more hyper improvements
CURLFOLLOW_NO_CUSTOMMETHOD
Next release
March 2, 2022 is the scheduled date for what will most probably become curl 7.82.0.