In the beginning of every year I jot down a couple of “larger things” I would like to work on during the year. Some of the ideas are more in the maybe category and meant to be tested on the audience and users to see what others think and want, others are features I believe are ripe and ready for addition.
I talk about what I personally plan and consider to work on as I cannot control or decide what volunteers and random contributors will do this year, but of course with the hope that feedback from users and customers will guide me.
If you have use cases, applications or devices with needs or interests in particular topics going forward: let me know! At this webinar or outside of it.
The curl roadmap 2022 webinar will happen on February 17th at 09:00 PST (17:00 UTC, 18:00 CET). Register to attend on this link:
I’m the lead developer in the curl project. We make the command line tool curl and the library libcurl, for doing Internet transfers. The command line tool uses the library for all the internet transfer heavy lifting.
The command line tool is somewhat of a shell binding to access libcurl.
We make these things. We recently surpassed 1,000 authors. I lead the project and I have done the most number of commits per month in curl for the last 79 months, and in fact in 222 of the 267 months we have stats for.
The tool came first
curl was born in 1998 as a command line tool only. Two years in, we (well, mostly me actually) remodeled some internals and shipped the first libcurl to the world in August 2000. The idea was (and still is) to provide the same Internet transfer powers the tool has to any application or device out there that need it.
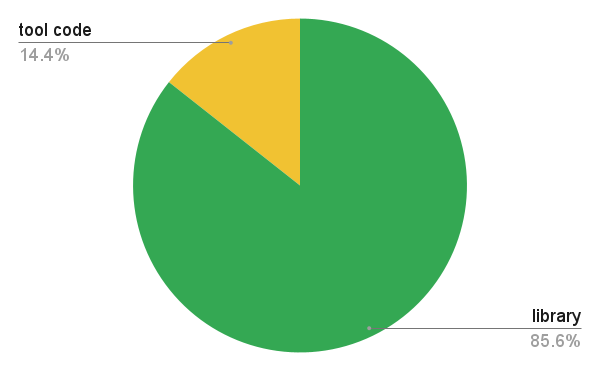
Code sizes
The library side of things is right now about 85% of the total product code. A little over 120,000 lines right now, including comments.
Pie chart showing code distribution between tool and library
Users at scale
Many users think of the curl project as equivalent to the curl tool and the command line tool certainly has a lot of users. It is available for and on all the popular platforms. It is impossible to count curl command users, but millions should not be an exaggeration.
While it seems likely that more users are using the tool than is writing applications that use libcurl, each product, service or device that uses libcurl can themselves scale up the volumes. A single libcurl user can use libcurl in an application used by billions. A few hundreds or thousands of libcurl users populate the world with things transferring data with our library. (A noticeable share of the current Internet traffic is likely driven by libcurl.)
The net result is therefore that libcurl runs in several thousand times more installations than the tool.
If we visualize the number of curl users as a yellow ball and the libcurl installations as a green ball, putting them next to each other would look something like this:
Planet curl is barely visible next to planet libcurl. Install and user numbers are estimated.
(Image math: 3 million curl users, 10 billion libcurl installations. Yellow sphere radius is 90 vs the green’s 1340)
Complexity
Making a command line tool is much easier than doing a library. The command line tool has just one entry point and the interface is limited. A command line and associated files and pipes to read from. In our case, the tool lets libcurl deal with a lot of platform specifics which makes the command line code generic and mostly identical on all platforms it runs on.
A library has many more entry points, each that needs to be written to care for what the users might pass in to them. libcurl has code to work with millions of build combinations, and (right now) up to 35 different external libraries. (13 different TLS libraries, 3 different SSH libraries, 2 different QUIC/HTTP/3 libraries, 3 different compression libraries etc.)
libcurl is used in many more challenging environments such as niche operating systems, scaled up to thousands of concurrent transfers, systems that never exits and in builds with a creative set of features disabled at build-time.
Compared to the curl tool, libcurl is way more advanced. A bug in the command line tool is often much easier to fix than one in the library. Such bugs are also rarer since it is much simpler and a smaller amount of code.
Where it matters
Because of what I have outlined above, I focus my curl work on library related changes. Both when it comes to bug-fixes and adding features. It scales better to the world, and as one of the designers and architects of most solutions used in libcurl I am in many cases a suitable engineer to work on many of the more complicated problems.
It is smarter for the entire project for me to leave the slightly less complicated problems and more easily understood features to be fixed and added by others. It scales better. After all, I have a finite number of hours per week to spend on curl. I want to make the best use of my time as I can.
Therefore, I tend to leave tool-related things for others to work on.
Where it pays
I work on curl for a living. The companies that pay for support have higher priority than almost any other bug reports, and they tend to be libcurl related. Keeping my paying customers happy is crucial to me. And in a funny way also to others, since that work usually end up benefiting all curl users.
Where its fun
As I work on curl full-time during my workdays and also during a good chunk of my spare time, I need to “lighten up” my work at times and get some variation. Sometimes I can go about and find new little things to work on in the project that maybe isn’t top priority by any means, but are things that could use some polish and are different enough from what I spent the rest of my week on. To give me variation. To keep the fun.
Also, sometimes scratching the surface on a new somewhat forgotten place brings up more important stuff.
Theory meets practice
Years ago I even for a while considered to hand over maintenance of the curl tool to someone else and more distinctly say that I would only work on the library as they are separate entities and could possibly benefit from being worked on independently from each other.
My idea of focusing my work on the more complicated issues, to work on design and architecture and help newcomers find their way into the code doesn’t always work out.
I never gave up maintenance of the tool and a lot of things that someone else could implement or fix in the project aren’t, which makes me eventually get to work on that too anyway. For the good of the project. Also, it makes my work day more varied and fun if I take occasional strolls around the project every now and then and put on some new paint on areas I find could use some.
Summary
Most of my work efforts go into libcurl matters. But I work on the tool too.
The curl “cockpit” is yet again extended with a new command line option: --json. The 245th command line option.
curl is a generic transfer tool for sending and receiving data across networks and it is completely agnostic as to what it transfers or even why.
To allow users to craft all sorts of transfers, or requests if you will, it offers a wide range of command line options. This flexibility has made it possible for a large number of users to keep using curl even as network ecosystems and its (HTTP) use have changed over time.
Craft content to send
curl offers a few convenience options for creating contents to send in HTTP “uploads” . Options such as -F for building multi-part formposts, and --data-urlencode for URL-encoding POST data.
JSON is the new popular kid
When curl was born, JSON didn’t exist. Over the decades since, JSON has grown to become a very commonly used format for structured data, often used in “REST API” calls and more. curl command lines sending and receiving JSON are very common now.
When asking users today what features they would like to see added in curl, and when asking them what good features they see in curl alternatives, a huge chunk of them mention JSON support in one way or another.
Partly because dealing with JSON with curl sometimes make the involved command lines rather long and quirky.
JSON in curl
The discussion has been ignited in the curl community about what, if anything, we should do in curl to make it a smoother and better tool when working with JSON. The offered opinions range from nothing (“curl is content agnostic”) to full-fledged JSON generator, parser and pretty-printer (or a combination in between). I don’t think we are ready to put our collective foot down on where we should go with this.
Introducing --json
While the discussion is ongoing, we still bring a first JSON oriented feature to the tool as a first step. The --json option. This is a new option that basically works as an alias, or shortcut, to sending JSON to an endpoint. You use it like this:
If you want another Content-Type or Accept header, then you can override them as usual with -H. If you use multiple --json options on the same command line, the contents from them will be concatenated before sent off.
Ships!
This new json option was merged in this commit and will be available and present in curl 7.82.0, to be released in early March 2022. Of course you can build it from git or a daily snapshot already now to test it out!
Future JSON stuff
I want to at least experiment a little with some level of JSON creation for curl. To help users who want to create basic JSON on the command line to send off. Lots of users run into problems with this since JSON uses double quotes a lot and then the combination of quoting and unquoting and the shell often make users confused or even frustrated.
Exactly how or to what level is still to be determined. Your opinions and feedback are very valuable and helpful.
jo+curl+jq
This trinity of commands helps you send correctly formatted data and show the returned JSON easily. Like in a command line similar to:
jo name=daniel tool=curl | curl --json @- https://httpbin.org/post | jq
In this presentation I talk about how libcurl’s most important aspect is the stable ABI and API. If we just maintain those, we can change the internals however we like.
libcurl has a system with build-time selected components, called backends. They are usually powered by third party libraries. With the recently added HTTP backend there are now seven “flavors” of backends.
A backend can be provided by a library written in rust, as long as that rust component provides a C interface that libcurl can use. When it does, it being rust or not is completely transparent and a non-issue for libcurl.
curl currently supports components written in rust for three different backends: