Let’s take a look back and remember some of what this year brought.
commits
At more than 3,400 commits we did 40% more commits in curl this year than any single previous year!
Since at some point during 2025, all the other authors in the project have now added more lines in total to the curl repository than I have. Meaning that out of all the lines ever added in the curl repository, I have now added less than half.
More than 150 individuals authored commits we merged during the year. Almost one hundred of them were first-timers. Thirteen authors wrote ten or more commits.
Viktor Szakats did the most number of commits per month for almost all months in 2025.
Stefan Eissing has now done the latest commit for 29% of the product source code lines – where my share is 36%.
About 598 authors have their added contributions still “surviving” in the product code. This is down from 635 at end of last year.
tests
We have 232 more tests at the end of this year compared to last December (now at 2179 separate test cases), and for the first time ever we have more than twelve test cases per thousand lines of product source code.
(Sure, counting test cases is rather pointless and weird since a single test can be small or big, simple or complex etc, but that’s the only count we have for this.)
releases
The eight releases we did through the year is a fairly average amount:
- 8.12.0
- 8.12.1
- 8.13.0
- 8.14.0
- 8.14.1
- 8.15.0
- 8.16.0
- 8.17.0
No major revolution happened this year in terms of big features or changes.
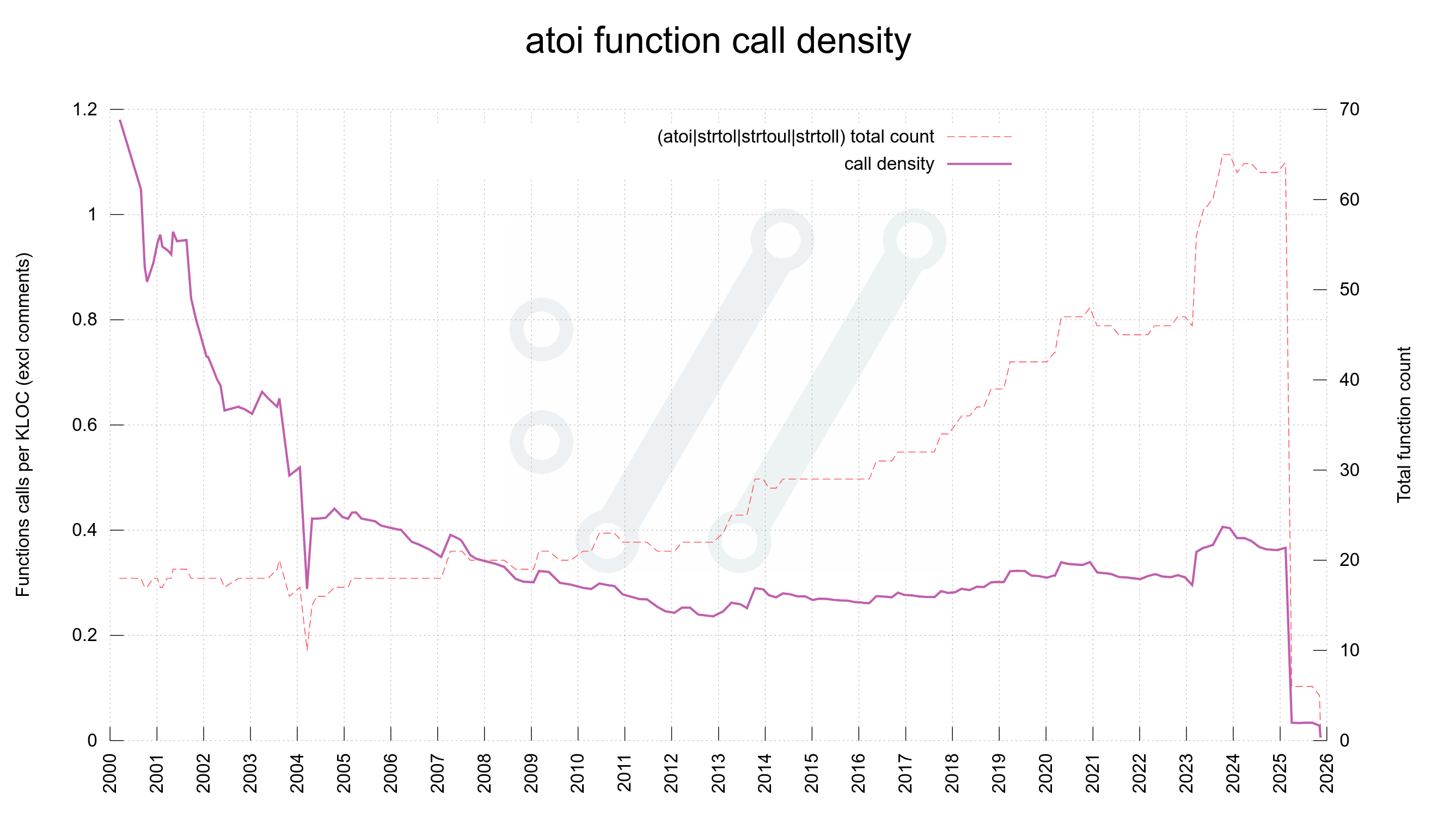
We reduced source code complexity a lot. We have stopped using some more functions we deem were often the reasons for errors or confusion. We have increased performance. We have reduced numbed of used allocations.
We added experimental support for HTTPS-RR, the DNS record.
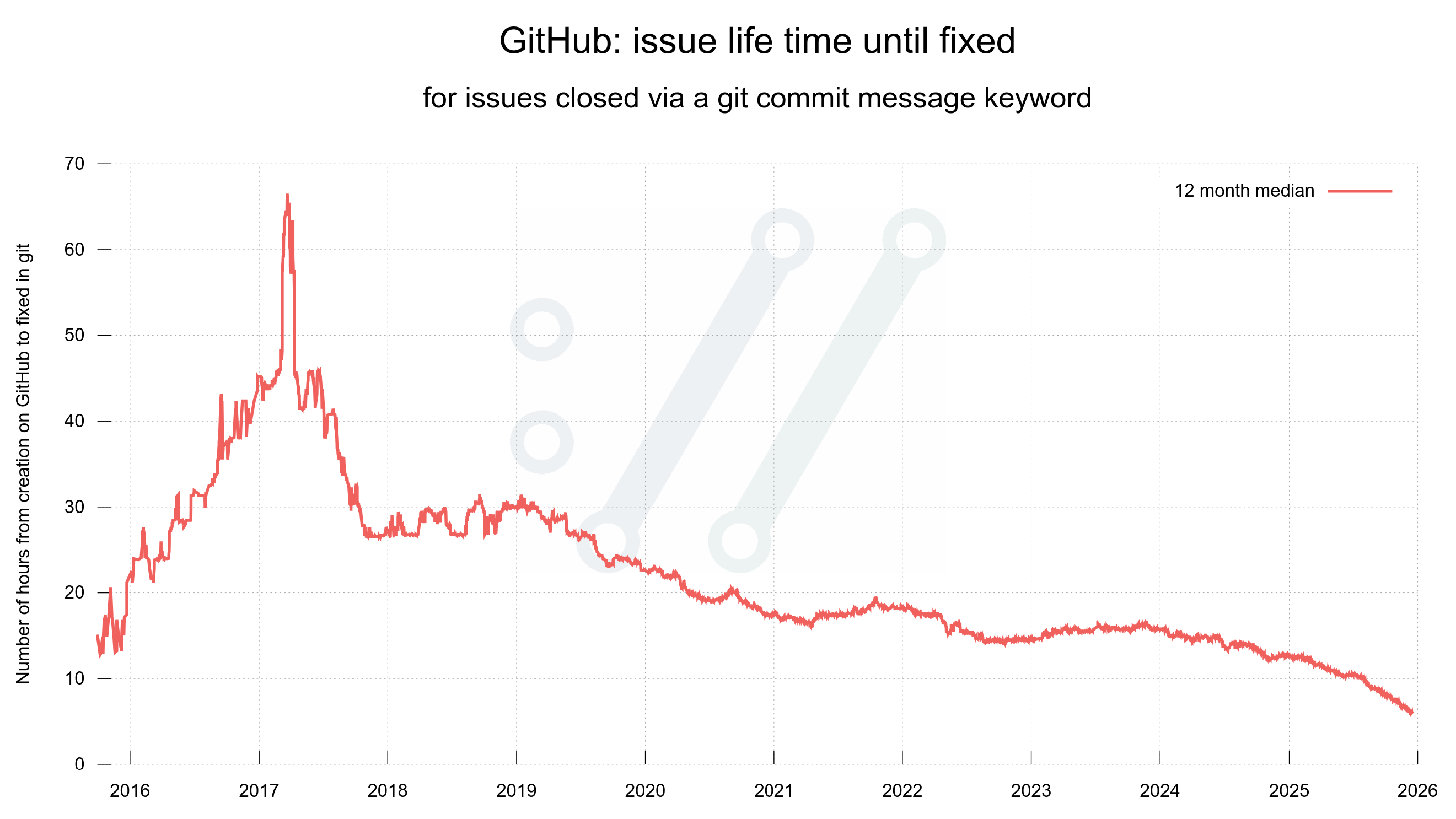
The bugfix frequency rate beat new records towards the end of the year as nearly 450 bugfixes shipped in curl 8.17.0.
This year we started doing release candidates. For every release we upload a series of candidates before the actual release so that people can help us and test what is almost the finished version. This helps us detect and fix regressions before the final release rather than immediately after.
Command line options
We end the year with 6 more curl command line options than we had last new year’s eve; now at 273 in total.
| 8.17.0 | –knownhosts |
| 8.16.0 | –out-null –parallel-max-host –follow |
| 8.14.0 | –sigalgs |
| 8.13.0 | –upload-flags |
| 8.12.0 | –ssl-sessions |
man page
The curl man page continued to grow; now more than 500 lines longer since last year (7090 lines), which means that even when counted number of man page lines per command line option it grew from 24.7 to 26.
Lines of code
libcurl grew with a mere 100 lines of code over the year while the command line tool got 1,150 new lines.
libcurl is now a little over 149,000 lines. The command line tool has 25,800 lines.
Most of the commits clearly went into improving the products rather than expanding them. See also the dropped support section below.
QUIC
This year OpenSSL finally introduced and shipped an API that allows QUIC stacks to use vanilla OpenSSL, starting with version 3.5.
As a direct result of this, the use of the OpenSSL QUIC stack has been marked as deprecated in curl and is queued for removal early next year.
As we also removed msh3 support during 2025, we are looking towards a 2026 with supporting only two QUIC and HTTP/3 backends in curl.
Security
This year the number of AI slop security reports for curl really exploded. The curl security team has gotten a lot of extra load because of this. We have been mentioned in media a lot during the year because of this.
The reports not evidently made with AI help have also gotten significantly worse quality wise while the total volume has increased – a lot. Also adding to our collective load.
We published nine curl CVEs during 2025, all at severity low or medium.
AI improvements
A new breed of AI-powered high quality code analyzers, primarily ZeroPath and Aisle Research, started pouring in bug reports to us with potential defects. We have fixed several hundred bugs as a direct result of those reports – so far.
This is in addition to the regular set of code analyzers we run against the code and for which we of course also fix the defects they report.
Web traffic
At the end of the year 2025 we see 79 TB of data getting transferred monthly from curl.se. This is up from 58 TB (+36%) for the exact same period last year.
We don’t have logs or analysis so we don’t know for sure what all this traffic is, but we know that only a tiny fraction is actual curl downloads. A huge portion of this traffic is clearly not human-driven.
GitHub activity
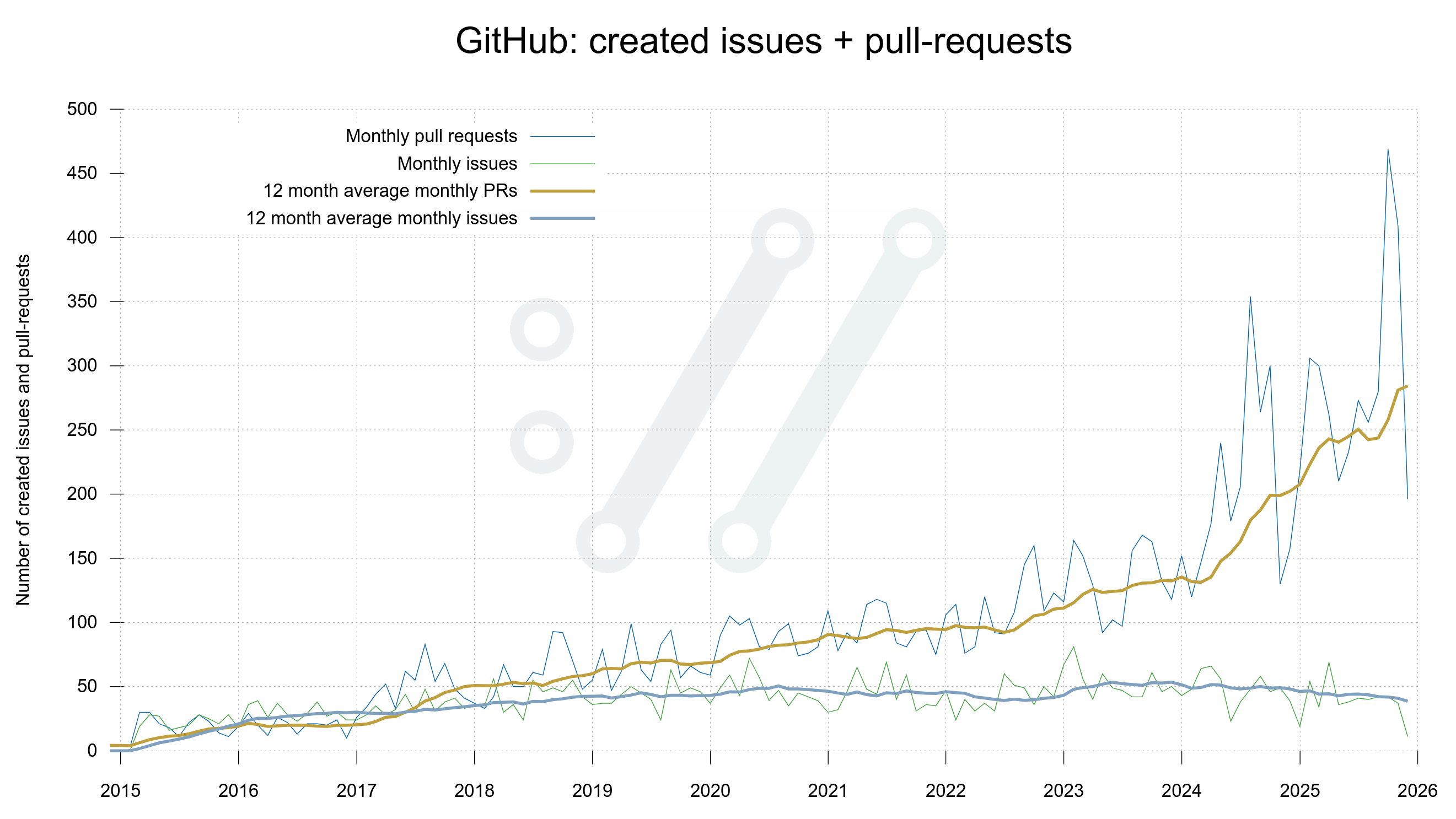
More than two hundred pull requests were opened each month in curl’s GitHub repository.
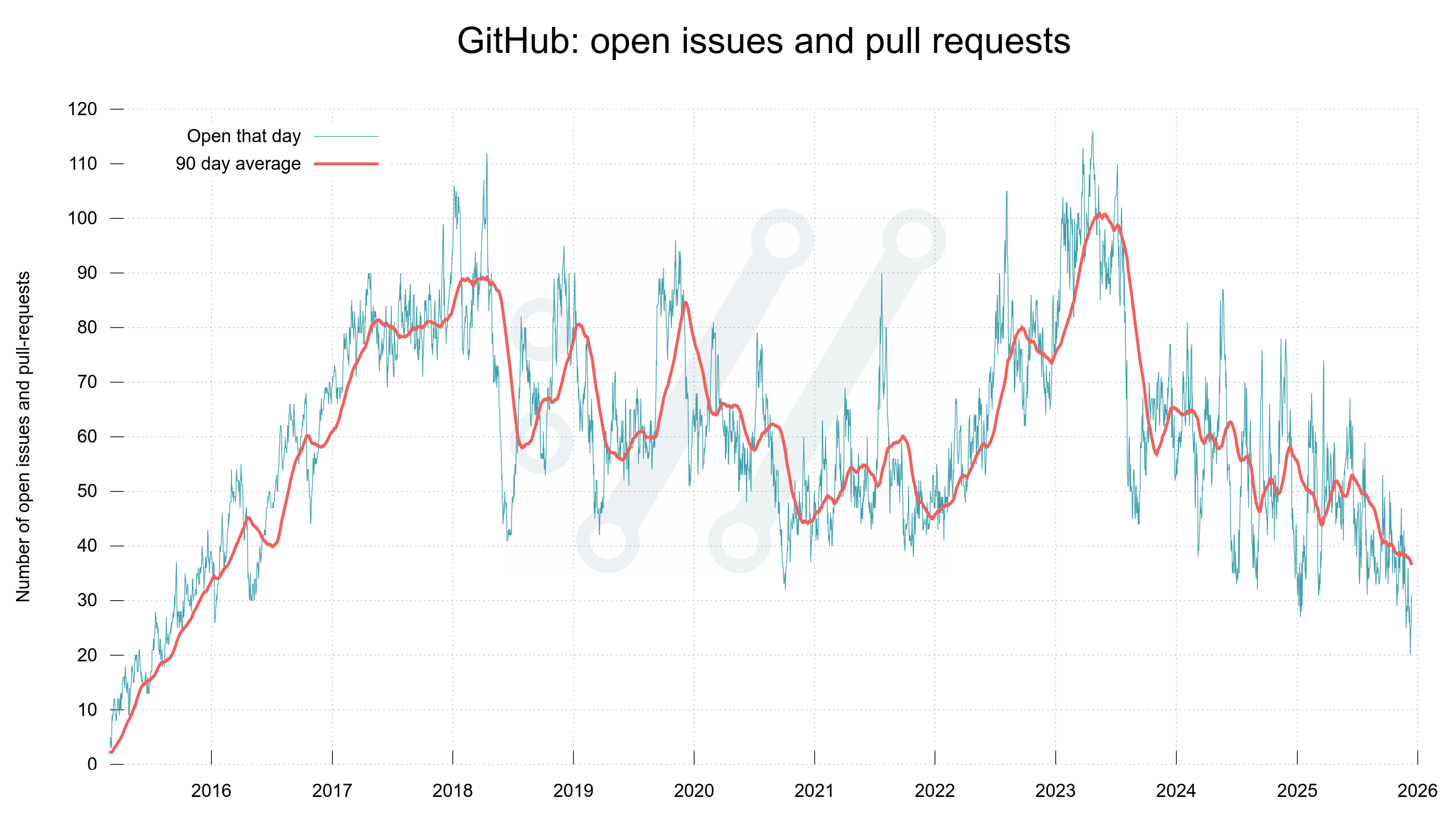
For a brief moment during the fall we reached zero open issues.
We have over 220 separate CI jobs that in the end of the year spend more than 25 CPU days per day verifying our ongoing changes.
Dashboard
The curl dashboard expanded a lot. I removed a few graphs that were not accurate anymore, but the net total change is still that we went up from 82 graphs in December 2024 to 92 separate illustrations in December 2025. Now with a total of 259 individual plots (+25).
Dropped support
We removed old/legacy things from the project this year, in an effort to remove laggards, to keep focus on what’s important and to make sure all of curl is secure.
- Support for Visual Studio 2005 and older (removed in 8.13.0)
- Secure Transport (removed in 8.15.0)
- BearSSL (removed in 8.15.0)
- msh3 (removed in 8.16.0)
- winbuild build system (removed in 8.17.0)
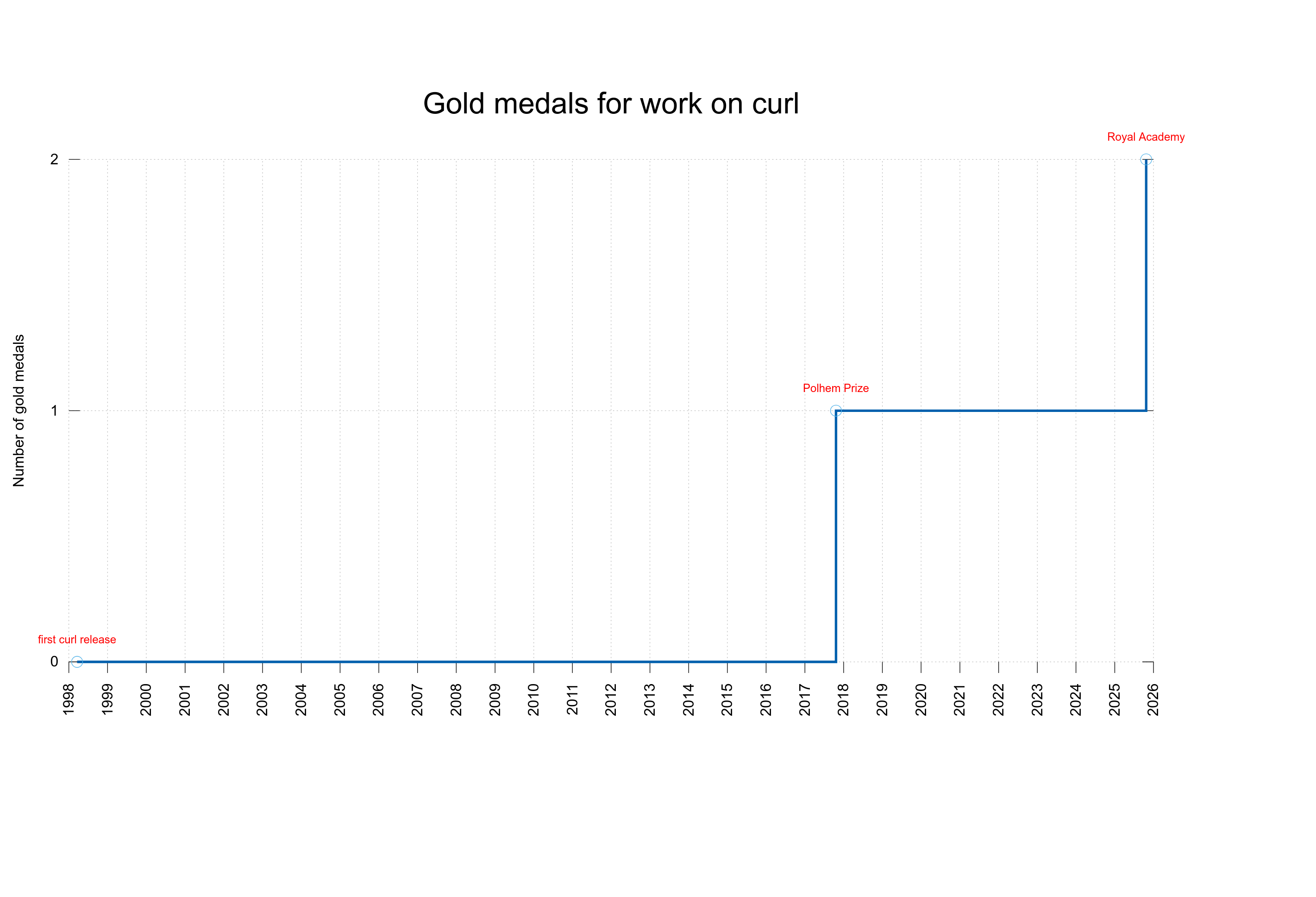
Awards
It was a crazy year in this aspect (as well) and I was honored with:
I also dropped out of the Microsoft MVP program during the year, to which I was accepted into in October 2024.
Conferences / Talks
I attended these eight conferences and talked – in five countries. My talks are always related to curl in one way or another.
- FOSDEM
- foss-north
- curl up
- Open Infra Forum
- Joy of Coding
- FrOSCon
- Open Source Summit Europe
- EuroBSDCon
Podcasts
I participated on these podcasts during the year. Always related to curl.
- Security Weekly
- Open Source Security
- Day Two DevOps
- Netstack.FM
- Software Engineering Radio
- OsProgrammadores