Numbers
the 258th release
11 changes
63 days (total: 9,623)
260 bugfixes (total: 10,531)
423 commits (total: 32,704)
0 new public libcurl function (total: 94)
1 new curl_easy_setopt() option (total: 306)
4 new curl command line option (total: 263)
80 contributors, 38 new (total: 3,209)
47 authors, 16 new (total: 1,288)
2 security fixes (total: 157)
Download the new curl release from curl.se as always.
Release presentation
Security
Today we fix two security vulnerabilities and publish all details about them.
- CVE-2024-6197: freeing stack buffer in utf8asn1str. (severity medium) libcurl’s ASN1 parser has this utf8asn1str() function used for parsing an ASN.1 UTF-8 string. It can detect an invalid field and return error. Unfortunately, when doing so it also invokes free() on a 4 byte local stack buffer.
- CVE-2024-6874: macidn punycode buffer overread. (severity low) libcurl’s URL API function curl_url_get() offers punycode conversions, to and from IDN. Asking to convert a name that is exactly 256 bytes, libcurl ends up reading outside of a stack based buffer when built to use the macidn IDN backend. The conversion function then fills up the provided buffer exactly – but does not null terminate the string.
Changes
- –ip-tos (IP Type of Service / Traffic Class). Lets users set this IP header field to a number.
- –mptcp. Asks curl to enable the Multipath TCP option for this connection, which if the server also allows it may make the TCP connection to go over multiple network paths.
- –vlan-priority. Makes curl set the VLAN priority field for its IP traffic. This is typically a field used in the network layer below IP (think Ethernet), so it is not likely to survive through IP routers. A local network thing.
- –keepalive-cnt (and CURLOPT_TCP_KEEPCNT). Specify how many keeplive probes curl should send before it considers the connection to be dead.
- –write-out ‘%{num_retries}’ is a new variable for the info output that outputs the number of retries that were done for the previous transfer (when –retry was used).
- gnutls now supports CA caching. For libcurl using applications, this can really speed up doing serial TLS connections.
- mbedtls supports CURLOPT_CERTINFO. Returns certificate information to the application.
- noproxy patterns need to be comma separated. Space separation is no longer enough.
- Support binding a connection to both interface and IP, not just one of them.
- The URL API added CURLU_NO_GUESS_SCHEME, to allow an application to figure out if the scheme for a previously parsed URL was set or guessed.
- wolfssl now supports CA caching
Bugfixes
In no other release ever before in curl’s long history have there been this many bugfixes: 260. Some of my favorites are:
- cmake: 26 separate bugfixes
- configure: 10 separate bugfixes
- –help category cleanup and list categories in –help
- allow etag and content-disposition for 3xx reply
- docs: countless fixes, polish and corections
- show name and keywords for failed tests in summary
- avoid using GetAddrInfoExW with impersonation
- URL encode the canonical path for aws-sigv4
- fix DoH cleanup
- fix memory leak and zero-length HTTPS RR crash in DoH
- allow DoH transfers to override max connection limit
- fix ß with AppleIDN
- fix compilation with OpenSSL 1.x with md4 disabled
- do a final progress update on connect failure
- multi: fix pollset during RESOLVING phase
- enable UDP GRO for QUIC
- require at least OpenSSL 3.3 for QUIC
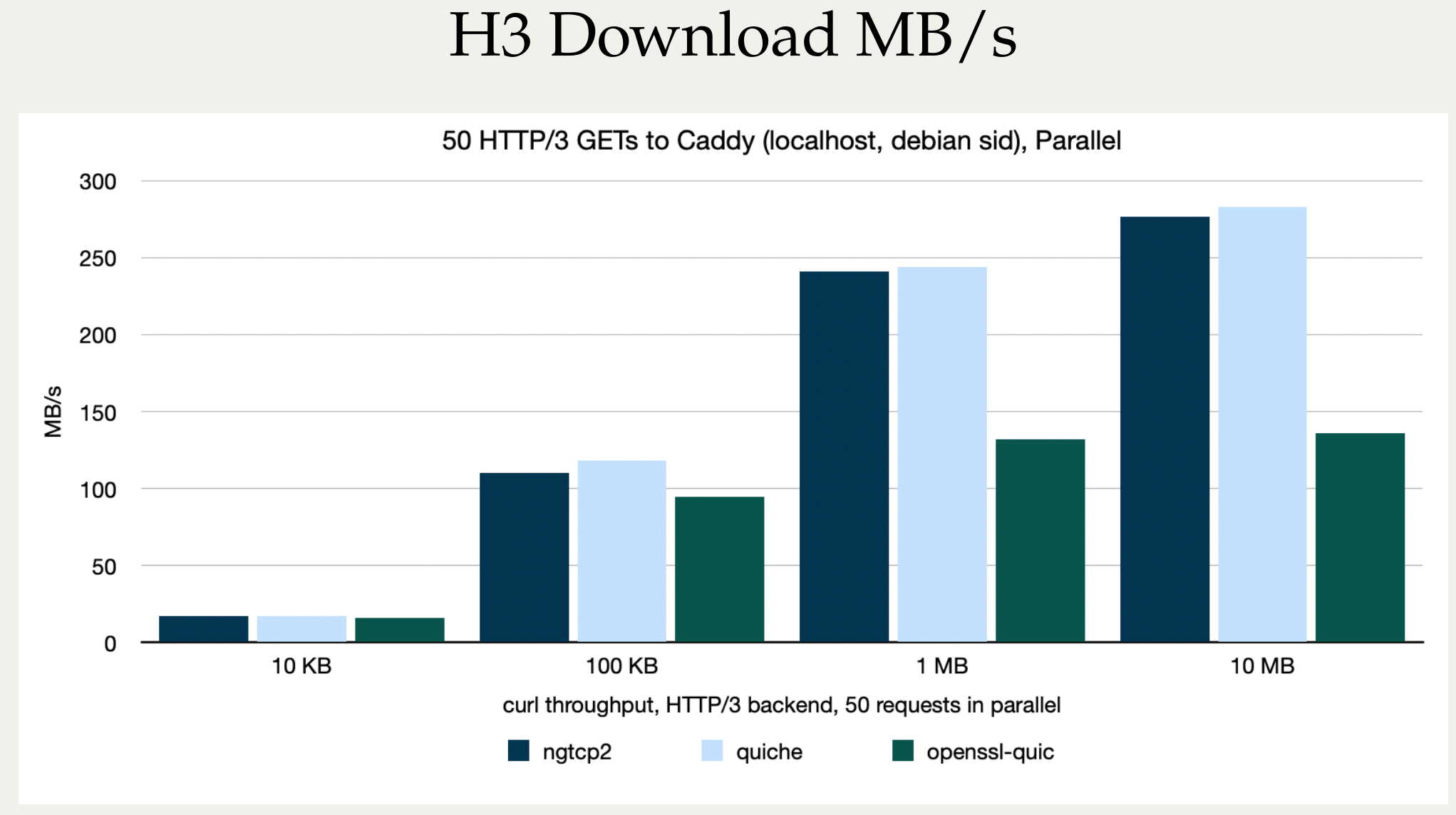
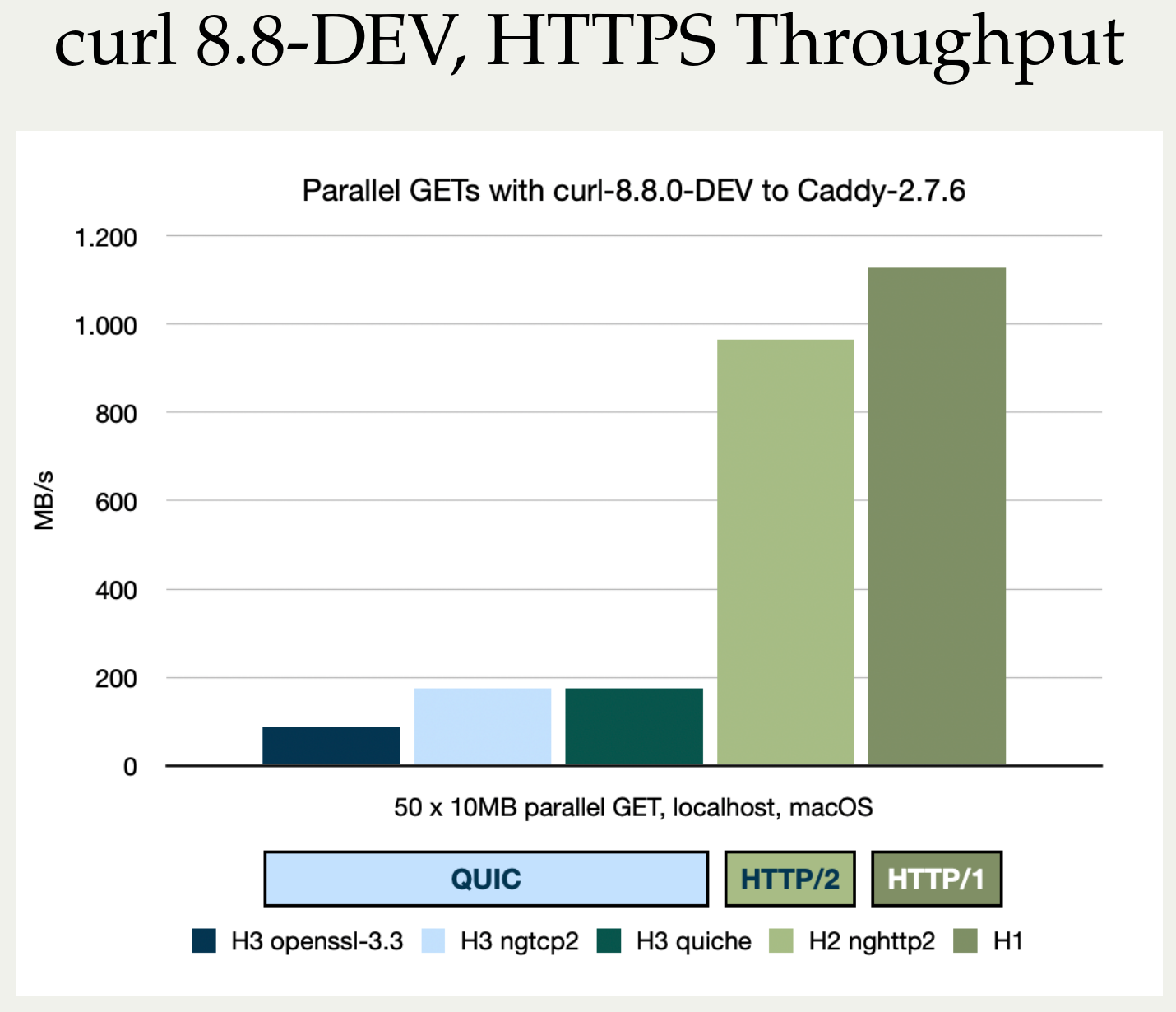
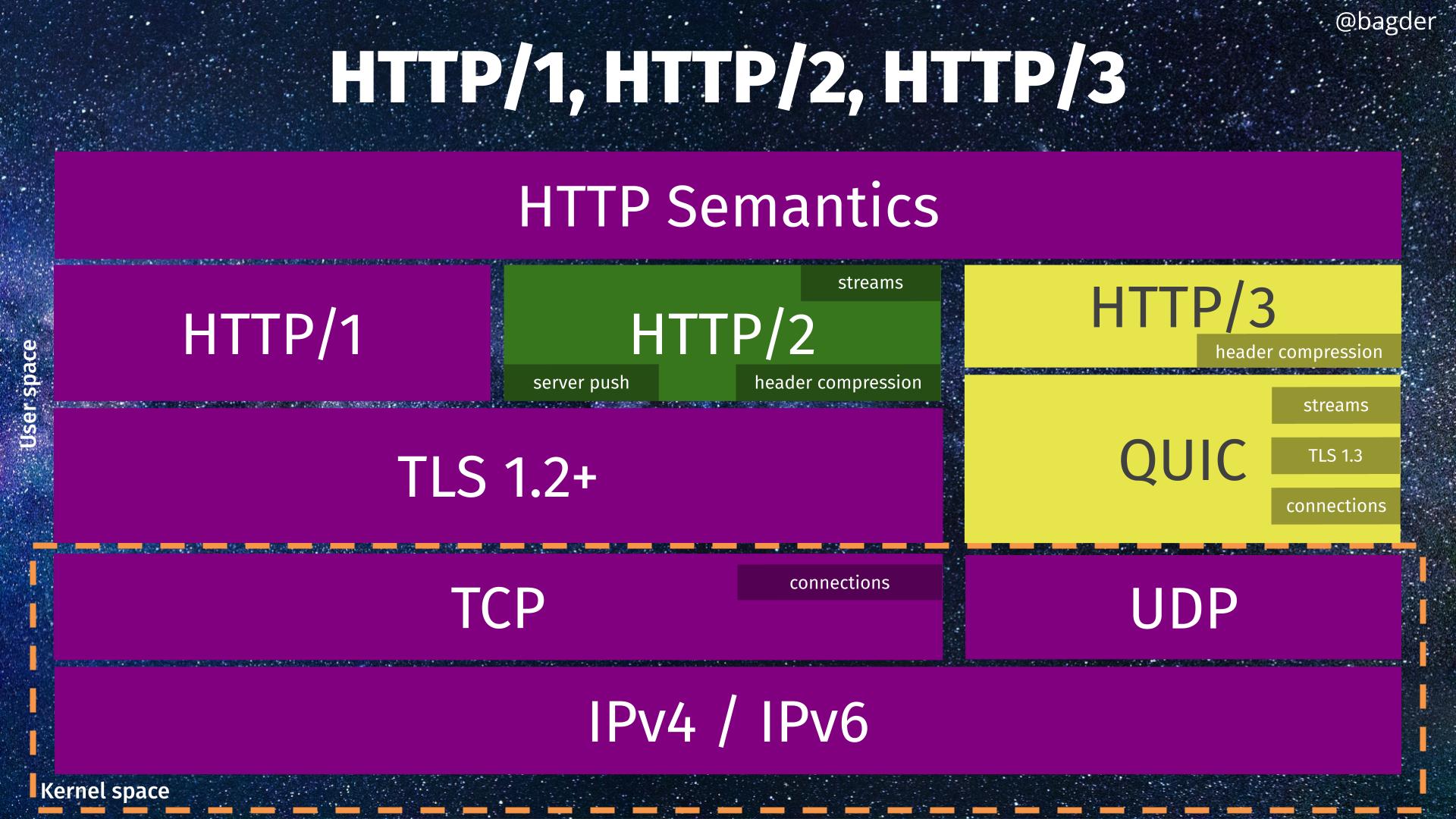
- add shutdown support for HTTP/3 (QUIC)
- fix CRLF conversion of input
- fixed starttls for SMTP
- change TCP keepalive from ms to seconds on DragonFly BSD
- support TCP keepalive parameters on Solaris <11.4
- shutdown TLS and TCP better
- gnutls: pass in SNI name, not hostname when checking cert
- gnutls: rectify the TLS version checks for QUIC
- mbedtls v3.6.0 workarounds
- several x509 asn.1 parser fixes
Next
Because the 8.9.0 release spent an extra week for its release cycle, the next one is going to be one week shorter. We do this by shortening the feature window to just two weeks this time, which might impact how many new features and changes we manage to merge.
We have a large amount of pull requests for changes already pending merge, waiting for the release window to open.
If all goes well, the next release is named 8.10.0 and eventually ships on September 11, 2024.