I’ve been a gmail user for many years (maybe ten). Especially since the introduction of smart phones it has been a really convenient system to read email on the go. I rarely respond to email from my phone but I’ve done that occasionally too and it has worked adequately.
I’ve been a gmail user for many years (maybe ten). Especially since the introduction of smart phones it has been a really convenient system to read email on the go. I rarely respond to email from my phone but I’ve done that occasionally too and it has worked adequately.
All this time I’ve used my own domain and email address and simply forwarded a subset of my email over to gmail, and I had gmail setup so that when I emailed out from it, it would use my own email address and not the @gmail.com one. Nothing fancy, just convenient. The gmail spam filter is also pretty decent so it helped me to filter off some amount of garbage too.
It was fine until DMARC
However, with the rise of DMARC over the recent years and with Google insisting on getting on that bandwagon, it has turned out to be really hard to keep forwarding email to gmail (since gmail considers forwarded emails using such headers fraudulent and it rejects them). So a fair amount of email simply never showed up in my gmail inbox (and instead caused the senders to get a bounce from a gmail address they didn’t even know I had).
I finally gave up and decided gmail doesn’t work for this sort of basic email setup anymore. DMARC and its siblings have quite simply made it impossible to work with emails this way, a way that has been functional for decades (I used similar approaches already back in the mid 90s on my first few jobs).
Similarly, DMARC has turned out to be a pain for mailing lists since they too forward email in a similar fashion and this causes the DMARC police to go berserk. Luckily, recent versions of mailman has options that makes it rewrite the From:-lines from senders that send emails from domains that have strict DMARC policies. That mitigates most of the problems for mailman lists. I love the title of this old mail on the subject: “Yahoo breaks every mailing list in the world including the IETF’s”
I’m sure DMARC works for the providers in the sence that they block huge amounts of spam and fake users and that’s what it was designed for. The fact that it also makes ordinary old-school mail forwards really difficult and forces mailing list admins all over to upgrade mailman or just keep getting rejects since they use mailing list software that lacks the proper features, that’s probably all totally ignored. DMARC was as designed: it reduces spam at the big providers’ systems. Mission accomplished. The fact that they at the same time made world wide Internet email a lot less useful is probably not something they care about.
It’s done
gmail can read mails from remote inboxes, but it doesn’t support IMAP (only POP3) so simply switching to such a method wouldn’t even work. I just refuse to enable POP3 anywhere again.
Of course it isn’t an irreversible decision, but I’ve stopped the forward to gmail, cleared the inbox there and instead I’ve switched to Aqua mail on Android. It seems fairly feature complete and snappy. It isn’t quite as fancy and cool as the gmail client, but hopefully it will do its job.
The biggest drawback I’ve felt after a couple of weeks is the gmail  spam filter. I do run spamassassin on my server and it catches the large bulk of all spams, but having the gmail spam system on top of that was able to block more silliness from my phone than spamassassin does alone.
spam filter. I do run spamassassin on my server and it catches the large bulk of all spams, but having the gmail spam system on top of that was able to block more silliness from my phone than spamassassin does alone.
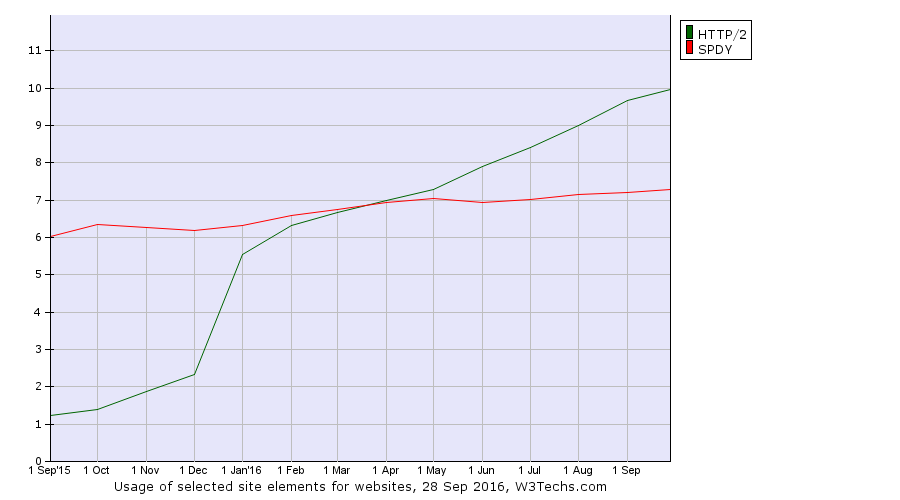
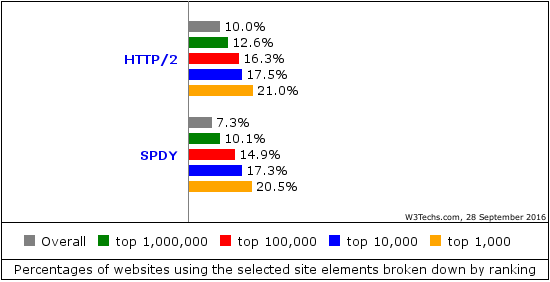




 The companies with most attendees present here were: Mozilla 5, Google 4, Facebook, Akamai and Apple 3.
The companies with most attendees present here were: Mozilla 5, Google 4, Facebook, Akamai and Apple 3. At 5pm we rounded off another fully featured day at the
At 5pm we rounded off another fully featured day at the