(Season three, episode two)
(Season three, episode two)
Previously, on the HTTP Workshop. Yesterday ended with a much appreciated group dinner and now we’re back energized and eager to continue blabbing about HTTP frames, headers and similar things.
Martin from Mozilla talked on “connection management is hard“. Parts of the discussion was around the HTTP/2 connection coalescing that I’ve blogged about before. The ORIGIN frame is a draft for a suggested way for servers to more clearly announce which origins it can answer for on that connection which should reduce the frequency of 421 needs. The ORIGIN frame overrides DNS and will allow coalescing even for origins that don’t otherwise resolve to the same IP addresses. The Alt-Svc header, a suggested CERTIFICATE frame and how does a HTTP/2 server know for which origins it can do PUSH for?
A lot of positive words were expressed about the ORIGIN frame. Wildcard support?
Willy from HA-proxy talked about his Memory and CPU efficient HPACK decoding algorithm. Personally, I think the award for the best slides of the day goes to Willy’s hand-drawn notes.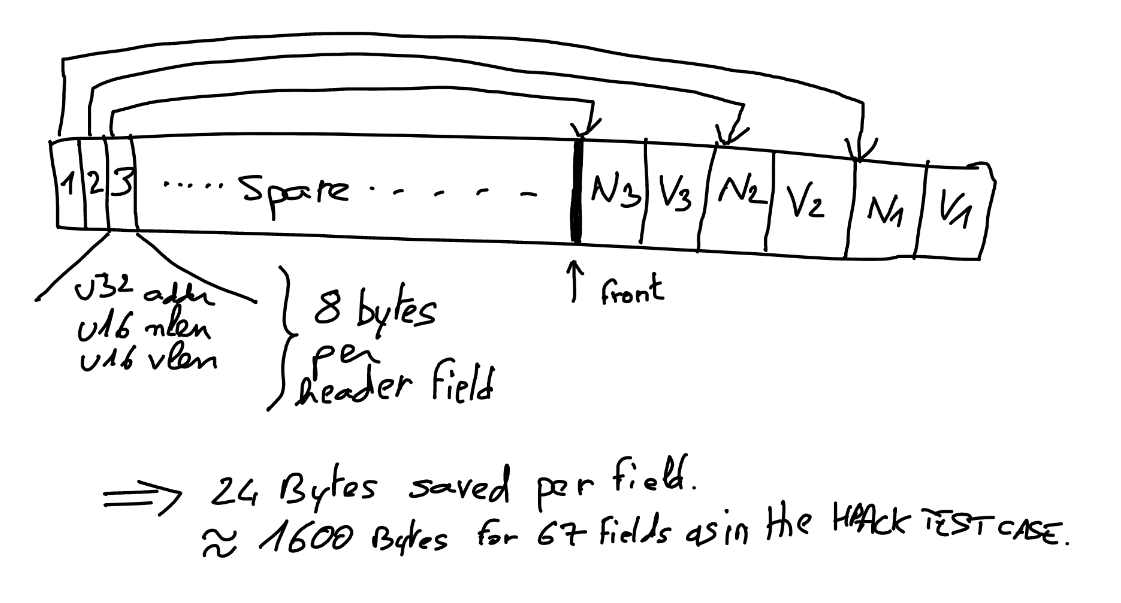
Lucas from BBC talked about usage data for iplayer and how much data and number of requests they serve and how their largest share of users are “non-browsers”. Lucas mentioned their work on writing a libcurl adaption to make gstreamer use it instead of libsoup. Lucas talk triggered a lengthy discussion on what needs there are and how (if at all) you can divide clients into browsers and non-browser.
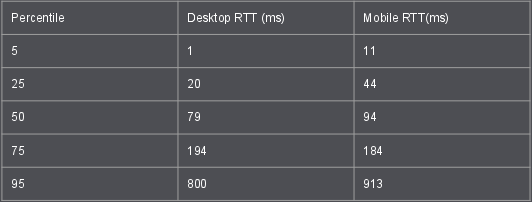
Wenbo from Google spoke about Websockets and showed usage data from Chrome. The median websockets connection time is 20 seconds and 10% something are shorter than 0.5 seconds. At the 97% percentile they live over an hour. The connection success rates for Websockets are depressingly low when done in the clear while the situation is better when done over HTTPS. For some reason the success rate on Mac seems to be extra low, and Firefox telemetry seems to agree. Websockets over HTTP/2 (or not) is an old hot topic that brought us back to reiterate issues we’ve debated a lot before. This time we also got a lovely and long side track into web push and how that works.
Roy talked about Waka, a HTTP replacement protocol idea and concept that Roy’s been carrying around for a long time (he started this in 2001) and to which he is now coming back to do actual work on. A big part of the discussion was focused around the wakli compression ideas, what the idea is and how it could be done and evaluated. Also, Roy is not a fan of content negotiation and wants it done differently so he’s addressing that in Waka.
Vlad talked about his suggestion for how to do cross-stream compression in HTTP/2 to significantly enhance compression ratio when, for example, switching to many small resources over h2 compared to a single huge resource over h1. The security aspect of this feature is what catches most of people’s attention and the following discussion. How can we make sure this doesn’t leak sensitive information? What protocol mechanisms exist or can we invent to help out making this work in a way that is safer (by default)?
Trailers. This is again a favorite topic that we’ve discussed before that is resurfaced. There are people around the table who’d like to see support trailers and we discussed the same topic in the HTTP Workshop in 2016 as well. The corresponding issue on trailers filed in the fetch github repo shows a lot of the concerns.
Julian brought up the subject of “7230bis” – when and how do we start the work. What do we want from such a revision? Fixing the bugs seems like the primary focus. “10 years is too long until update”.
Kazuho talked about “HTTP/2 attack mitigation” and how to handle clients doing many parallel slow POST requests to a CDN and them having an origin server behind that runs a new separate process for each upload.
And with this, the day and the workshop 2017 was over. Thanks to Facebook for hosting us. Thanks to the members of the program committee for driving this event nicely! I had a great time. The topics, the discussions and the people – awesome!


 observed 2x CPU usage increase for QUIC connections as compared to h2+TLS is mostly blamed on the Linux kernel which apparently is not at all up for this job as good is should be. Things have clearly been more optimized for TCP over the years, leaving room for improvement in the UDP areas going forward. “Making kernel bypassing an interesting choice”.
observed 2x CPU usage increase for QUIC connections as compared to h2+TLS is mostly blamed on the Linux kernel which apparently is not at all up for this job as good is should be. Things have clearly been more optimized for TCP over the years, leaving room for improvement in the UDP areas going forward. “Making kernel bypassing an interesting choice”.





 I’ve been a gmail user for many years (maybe ten). Especially since the introduction of smart phones it has been a really convenient system to read email on the go. I rarely respond to email from my phone but I’ve done that occasionally too and it has worked adequately.
I’ve been a gmail user for many years (maybe ten). Especially since the introduction of smart phones it has been a really convenient system to read email on the go. I rarely respond to email from my phone but I’ve done that occasionally too and it has worked adequately.
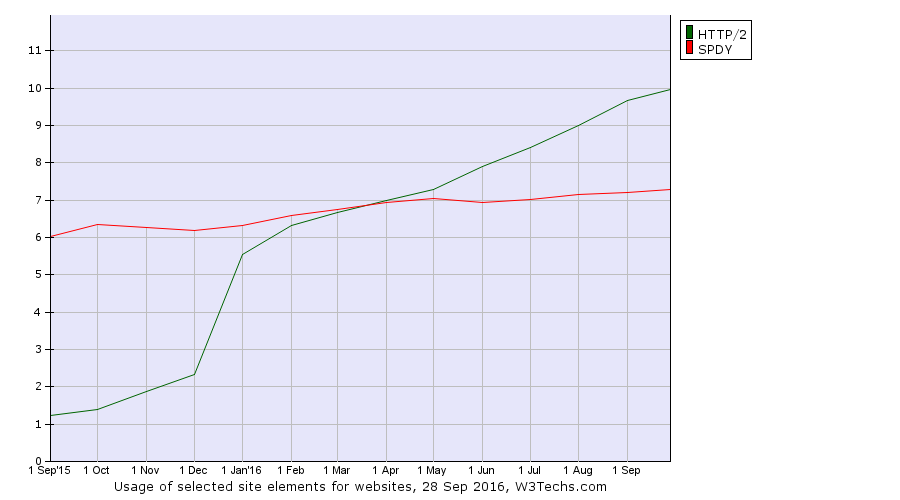
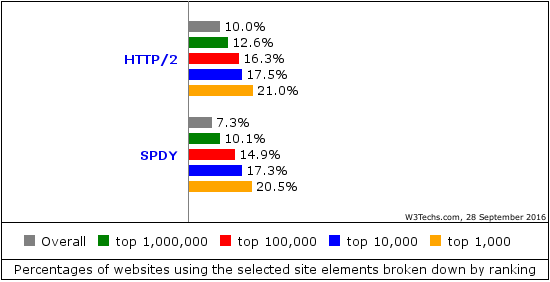




 At 5pm we rounded off another fully featured day at the
At 5pm we rounded off another fully featured day at the