I’ve previously blogged about the possible backdoor threat to curl. This post might be a little repeat but also a refresh and renewed take on the subject several years later, in the shadow of the recent PHP backdoor commits of March 28, 2021. Nowadays, “supply chain attacks” is a hot topic.
Since you didn’t read that PHP link: an unknown project outsider managed to push a commit into the PHP master source code repository with a change (made to look as if done by two project regulars) that obviously inserted a backdoor that could execute custom code when a client tickled a modified server the right way.

The commits were apparently detected very quickly. I haven’t seen any proper analysis on exactly how they were performed, but to me that’s not the ultimate question. I rather talk and think about this threat in a curl perspective.
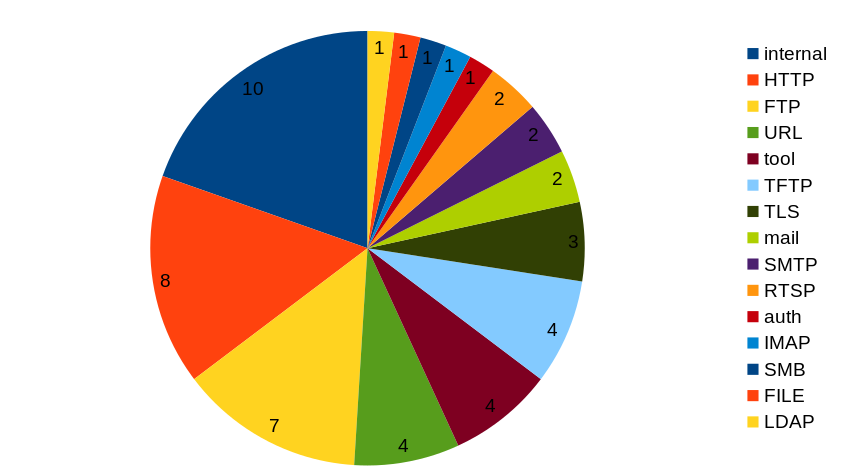
PHP is extremely widely used and so is curl, but where PHP is (mostly) server-side running code, curl is client-side.
How to get malicious code into curl
I’d like to think about this problem from an attacker’s point of view. There are but two things an attacker need to do to get a backdoor in and a third adjacent step that needs to happen:
- Make a backdoor change that is hard to detect and appears innocent to a casual observer, while actually still being able to do its “job”
- Get that changed landed in the master source code repository branch
- The code needs to be included in a curl release that is used by the victim/target
These are not simple steps. The third step, getting into a release, is not strictly always necessary because there are sometimes people and organizations that run code off the bleeding edge master repository (against our advice I should add).
Writing the backdoor code

As was seen in this PHP attack, it failed rather miserably at step 1, making the attack code look innocuous, although we can suspect that maybe that was done so on purpose. In 2010 there was a lengthy discussion about an alleged backdoor in OpenBSD’s IPSEC stack that presumably had been in place for years and even while that particular backdoor was never proven to be real, the idea that it can be done certainly is.
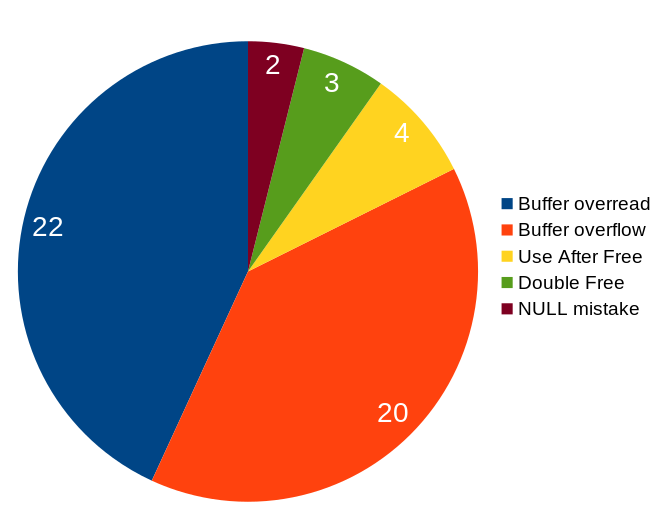
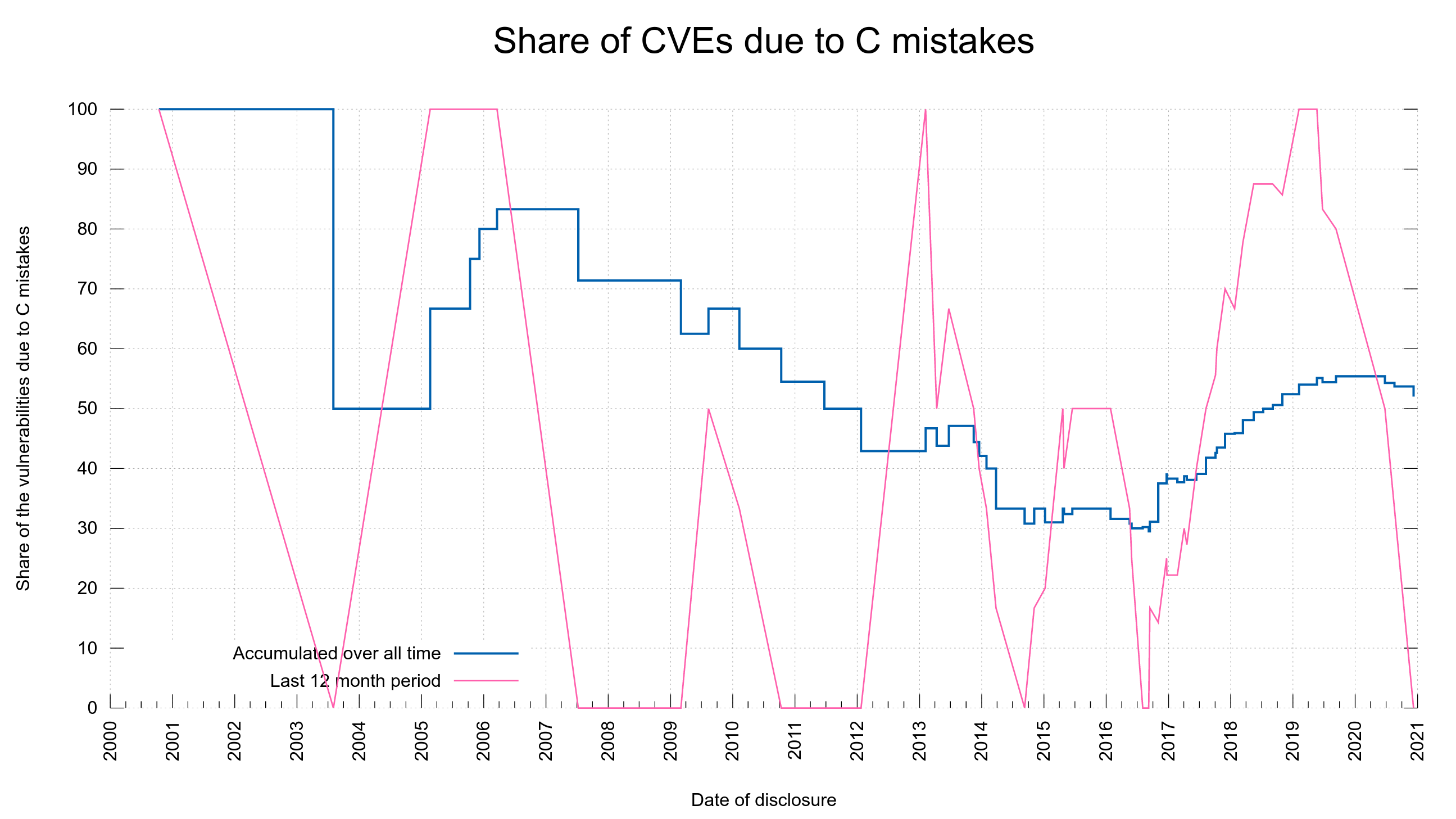
Every time we fix a security problem in curl there’s that latent nagging question in the back of our collective minds: was this flaw placed here deliberately? Historically, we’ve not seen any such attacks against curl. I can tell this with a high degree of certainty since almost all of the existing security problems detected and reported in curl was done by me…!
The best attack code would probably do something minor that would have a huge impact in a special context for which the attacker has planned to use it. I mean minor as in doing a NULL-pointer dereference or doing a use-after-free or something. This, because doing a full-fledged generic stack based buffer overflow is much harder to land undetected. Maybe going with a single-byte overwrite outside of a malloc could be the way, like it was back in 2016 when such a flaw in c-ares was used as the first step in a multi-flaw exploit sequence to execute remote code as root on ChromeOS…
Ideally, the commit should also include an actual bug-fix that would be the public facing motivation for it.
Get that code landed in the repo

Okay let’s imagine that you have produced code that actually is a useful bug-fix or feature addition but with an added evil twist, and you want that landed in curl. I can imagine several different theoretical ways to do it:
- A normal pull-request and land using the normal means
- Tricking or forcing a user with push rights to circumvent the review process
- Use a weakness somewhere and land the code directly without involving existing curl team members
The Pull Request method
I’ve never seen this attempted. Submit the pull-request to the project the usual means and argue that the commit fixes a bug – which could be true.
This makes the backdoor patch to have to go through all testing and reviews with flying colors to get merged. I’m not saying this is impossible, but I will claim that it is very hard and also a very big gamble by an attacker. Presumably it is a fairly big job just to get the code for this attack to work, so maybe going with a less risky way to land the code is then preferable? But then which way is likely to have the most reliable outcome?
The tricking a user method
Social engineering is very powerful. I can’t claim that our team is immune to that so maybe there’s a way an outsider could sneak in behind our imaginary personal walls and make us take a shortcut for a made up reason that then would circumvent the project’s review process.
We can even include more forced “convincing” such as direct threats against persons or their families: “push this code or else…”. This way of course cannot be protected against using 2fa, better passwords or things like that. Forcing a users to do it is also likely to eventually get known and then immediately make the commit reverted.
Tricking a user doesn’t make the commit avoid testing and scrutinizing after the fact. When the code has landed, it will be scanned and tested in a hundred CI jobs that include a handful of static code analyzers and memory/address sanitizers.
Tricking a user could land the code, but it can’t make it stick unless the code is written as the perfect stealth change. It really needs to be that good attack code to work out. Additionally: circumventing the regular pull-request + review procedure is unusual so I believe it is likely that such commit will be reviewed and commented on after the fact, and there might then be questions about it and even likely follow-up actions.
The exploiting a weakness method
A weakness in this context could be a security problem in the hosting software or even a rogue admin in the company that hosts the main source code git repo. Something that allows code to get pushed into the code repository without it being the result of one of the existing team members. This seems to be the method that the PHP attack was done through.
This is a hard method as well. Not only does it shortcut reviews, it is also done in the name of someone on the team who knows for sure that they didn’t do the commit, and again, the commit will be tested and poked at anyway.
For all of us who sign our git commits, detecting such a forged commit is easy and quickly done. In the curl project we don’t have mandatory signed commits so the lack of a signature won’t actually block it. And who knows, a weakness somewhere could even possibly find a way to bypass such a requirement.
The skip-git-altogether methods
As I’ve described above, it is really hard even for a skilled developer to write a backdoor and have that landed in the curl git repository and stick there for longer than just a very brief period.
If the attacker instead can just sneak the code directly into a release archive then it won’t appear in git, it won’t get tested and it won’t get easily noticed by team members!
curl release tarballs are made by me, locally on my machine. After I’ve built the tarballs I sign them with my GPG key and upload them to the curl.se origin server for the world to download. (Web users don’t actually hit my server when downloading curl. The user visible web site and downloads are hosted by Fastly servers.)
An attacker that would infect my release scripts (which btw are also in the git repository) or do something to my machine could get something into the tarball and then have me sign it and then create the “perfect backdoor” that isn’t detectable in git and requires someone to diff the release with git in order to detect – which usually isn’t done by anyone that I know of.
But such an attacker would not only have to breach my development machine, such an infection of the release scripts would be awfully hard to pull through. Not impossible of course. I of course do my best to maintain proper login sanitation, updated operating systems and use of safe passwords and encrypted communications everywhere. But I’m also a human so I’m bound to do occasional mistakes.
Another way could be for the attacker to breach the origin download server and replace one of the tarballs there with an infected version, and hope that people skip verifying the signature when they download it or otherwise notice that the tarball has been modified. I do my best at maintaining server security to keep that risk to a minimum. Most people download the latest release, and then it’s enough if a subset checks the signature for the attack to get revealed sooner rather than later.
The further-down-the-chain method
As an attacker, get into the supply chain somewhere else: find a weaker link in the chain between the curl release tarball and the target system for your attack . If you can trick or social engineer maybe someone else along the way to get your evil curl tarball to get used there instead of the actual upstream tarball, that might be easier and give you more bang for your buck. Perhaps you target your particular distribution’s or Operating System’s release engineers and pretend to be from the curl project, make up a story and send over a tarball to help them out…
Fake a security advisory and send out a bad patch directly to someone you know build their own curl/libcurl binaries?
Better ways?
If you can think of other/better ways to get malicious code via curl code into a victim’s machine, let me know! If you find a security problem, we will reward you for it!
Similarly, if you can think of ways or practices on how we can improve the project to further increase our security I’ll be very interested. It is an ever-moving process.
Dependencies
Added after the initial post. Lots of people have mentioned that curl can get built with many dependencies and maybe one of those would be an easier or better target. Maybe they are, but they are products of their own individual projects and an attack on those projects/products would not be an attack on curl or backdoor in curl by my way of looking at it.
In the curl project we ship the source code for curl and libcurl and the users, the ones that builds the binaries from that source code will get the dependencies too.