tldr: join in and watch/discuss the curl 2020 roadmap live on Thursday March 26, 2020. Sign up here.
The roadmap is basically a list of things that we at wolfSSL want to work on for curl to see happen this year – and some that we want to mention as possibilities.(Yes, the word “webinar” is used, don’t let it scare you!)
If you can’t join live, you will be able to enjoy a recorded version after the fact.
I shown the image below in curl presentation many times to illustrate the curl roadmap ahead:
The point being that we as a project don’t really have a set future but we know that more things will be added and fixed over time.
Daniel, wolfSSL and curl
This is a balancing act where there I have several different “hats”.
I’m the individual who works for wolfSSL. In this case I’m looking at things we at wolfSSL want to work on for curl – it may not be what other members of the team will work on. (But still things we agree are good and fit for the project.)
We in wolfSSL cannot control or decide what the other curl project members will work on as they are volunteers or employees working for other companies with other short and long term goals for their participation in the curl project.
We also want to try to communicate a few of the bigger picture things for curl that we want to see done, so that others can join in and contribute their ideas and opinions about these features, perhaps even add your preferred subjects to the list – or step up and buy commercial curl support from us and get a direct-channel to us and the ability to directly affect what I will work on next.
As a lead developer of curl, I will of course never merge anything into curl that I don’t think benefits or advances the project. Commercial interests don’t change that.
Webinar
Sign up here. The scheduled time has been picked to allow for participants from both North America and Europe. Unfortunately, this makes it hard for all friends not present on these continents. If you really want to join but can’t due to time zone issues, please contact me and let us see what we can do!
curl turns twenty-two years old today. Let’s celebrate this by looking at its development, growth and change over time from a range of different viewpoints with the help of graphs and visualizations.
This is the more-curl-graphs-than-you-need post of the year. Here are 22 pictures showing off curl in more detail than anyone needs.
I founded the project back in the day and I remain the lead developer – but I’m far from alone in this. Let me take you on a journey and give you a glimpse into the curl factory. All the graphs below are provided in hires versions if you just click on them.
Below, you will learn that we’re constantly going further, adding more and aiming higher. There’s no end in sight and curl is never done. That’s why you know that leaning on curl for Internet transfers means going with a reliable solution.
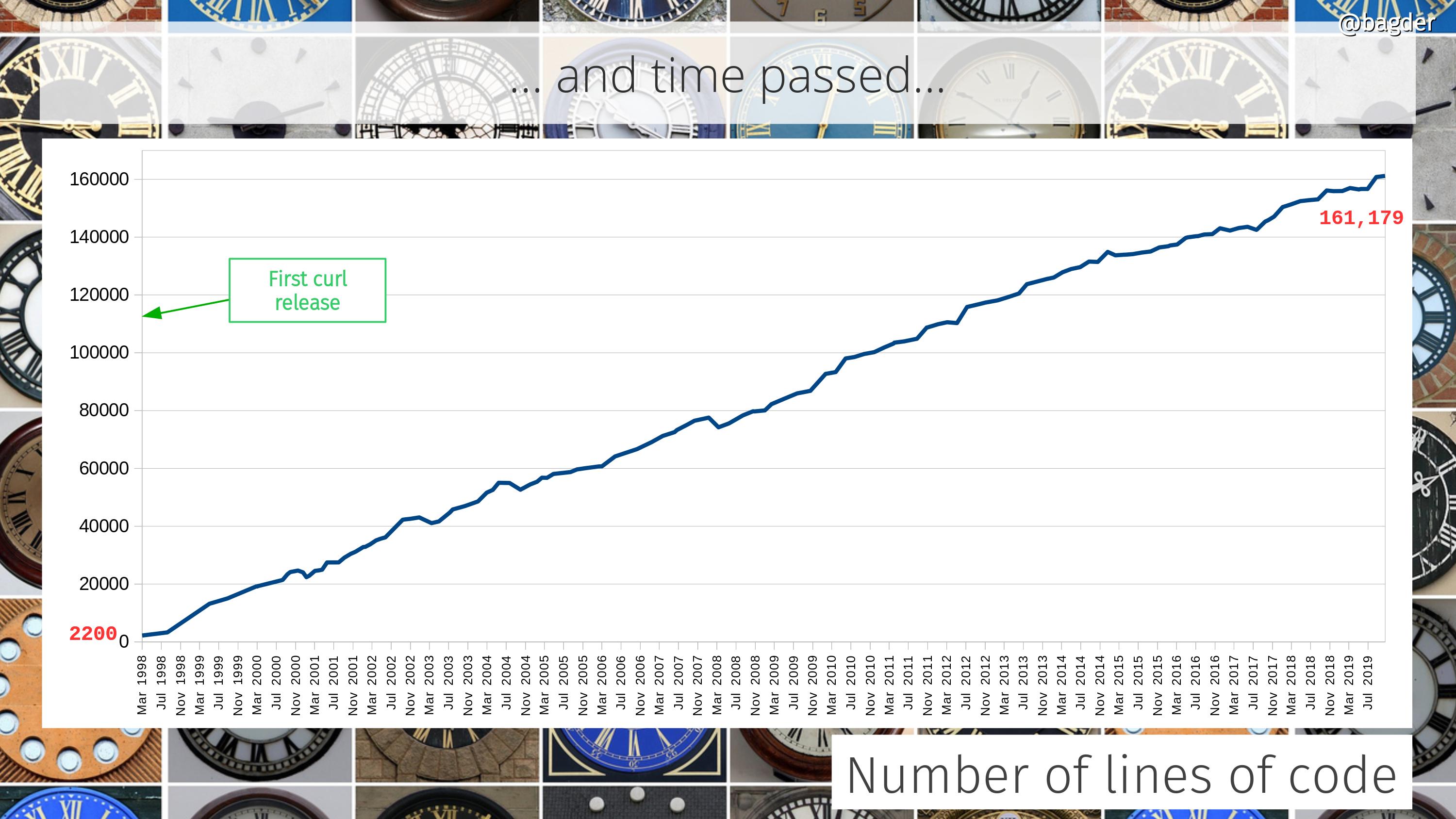
Number of lines of code
Counting only code in the tool and the library (and public headers) it still has grown 80 times since the initial release, but then again it also can do so much more.
At times people ask how a “simple HTTP tool” can be over 160,000 lines of code. That’s basically three wrong assumptions put next to each other:
curl is not simple. It features many protocols and fairly advanced APIs and super powers and it offers numerous build combinations and runs on just all imaginable operating systems
curl supports 24 transfer protocols and counting, not just HTTP(S)
curl is much more than “just” the tool. The underlying libcurl is an Internet transfer jet engine.
How much more is curl going to grow and can it really continue growing like this even for the next 22 years? I don’t know. I wouldn’t have expected it ten years ago and guessing the future is terribly hard. I think it will at least continue growing, but maybe the growth will slow down at some point?
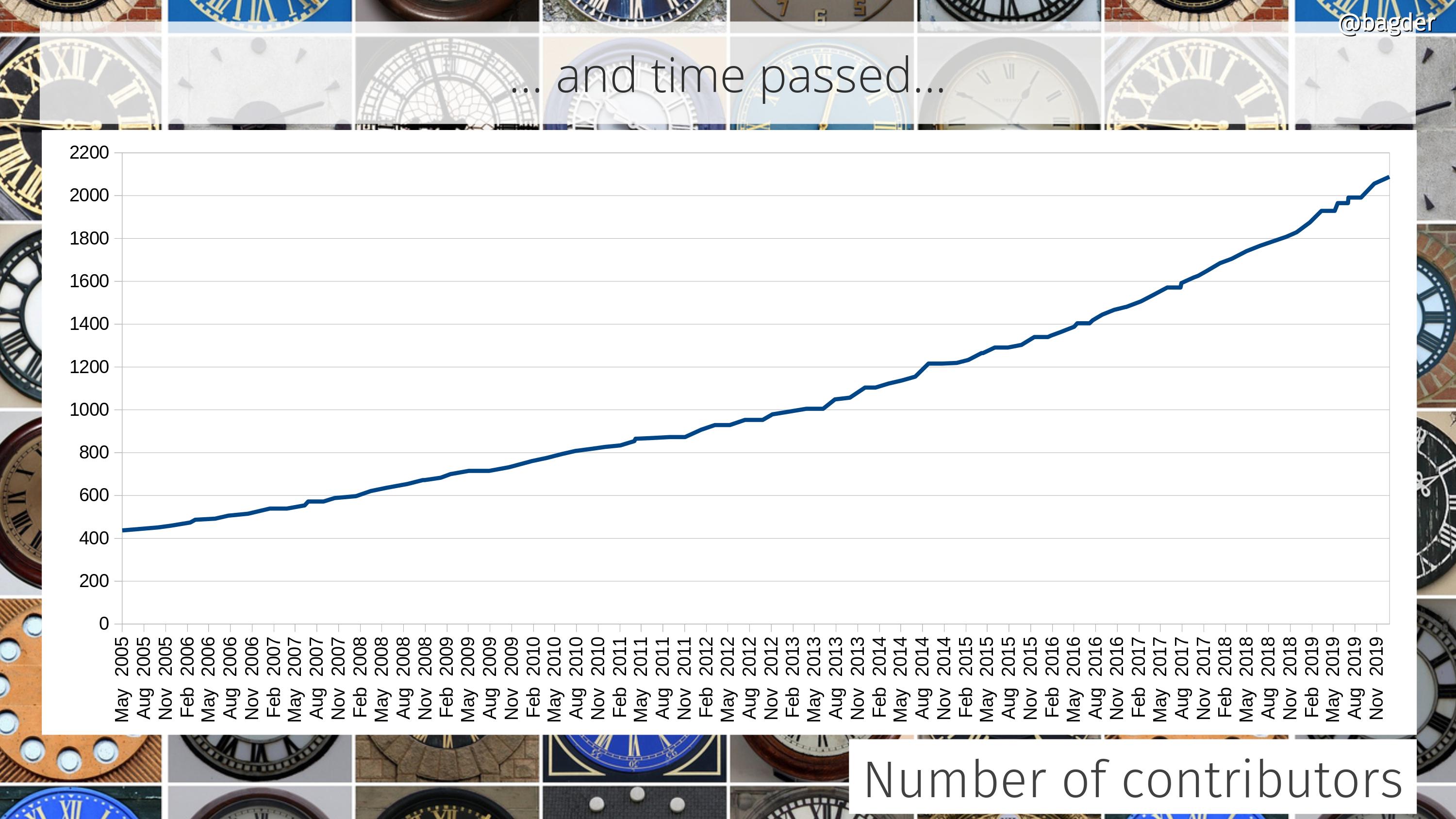
Number of contributors
Lots of people help out in the project. Everyone who reports bugs, brings code patches, improves the web site or corrects typos is a contributor. We want to thank everyone and give all helpers the credit they deserve. They’re all contributors. Here’s how fast our list of contributors is growing. We’re at over 2,130 names now.
When I wrote a blog post five years ago, we had 1,200 names in the list and the graph shows a small increase in growth over time…
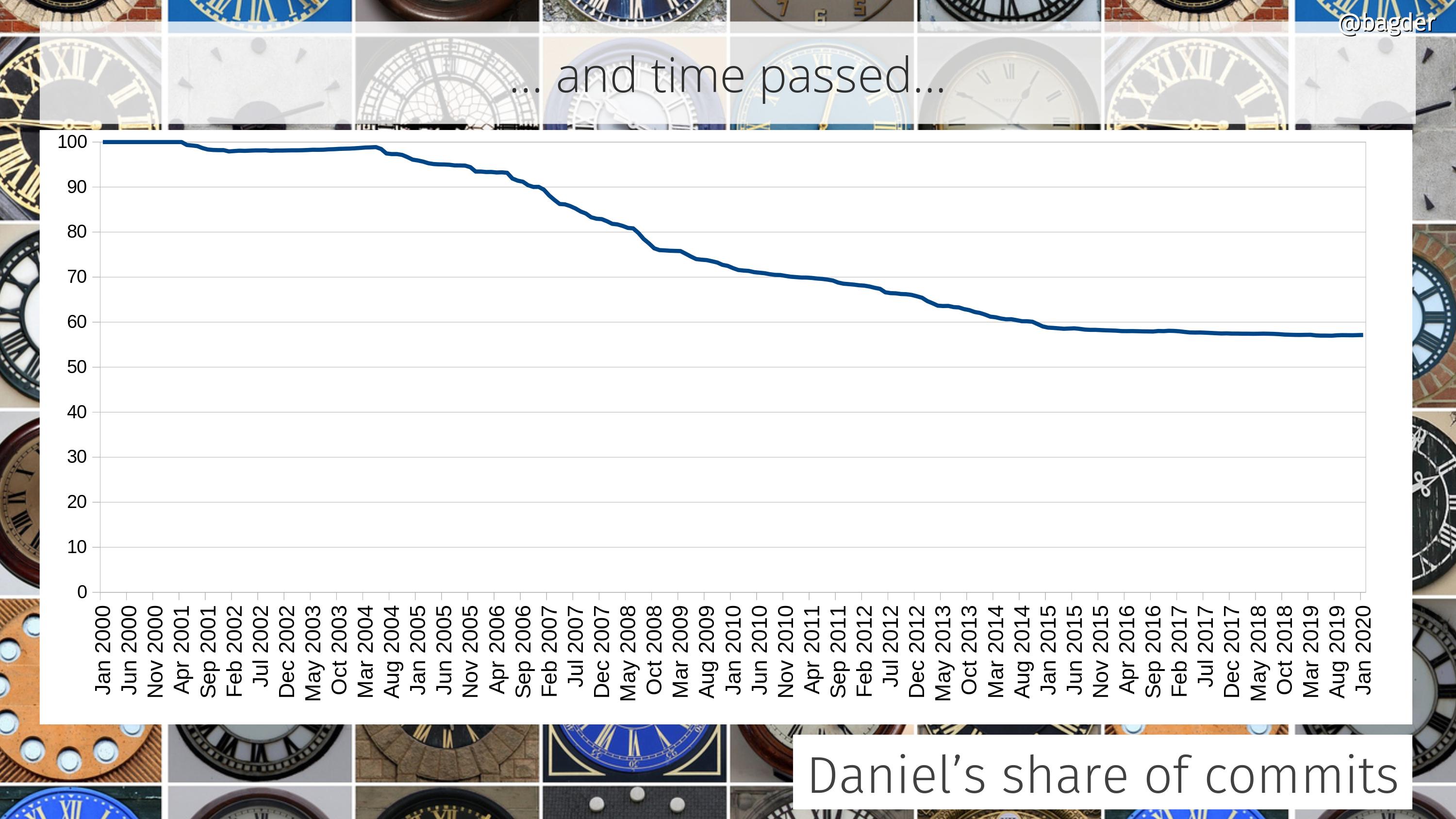
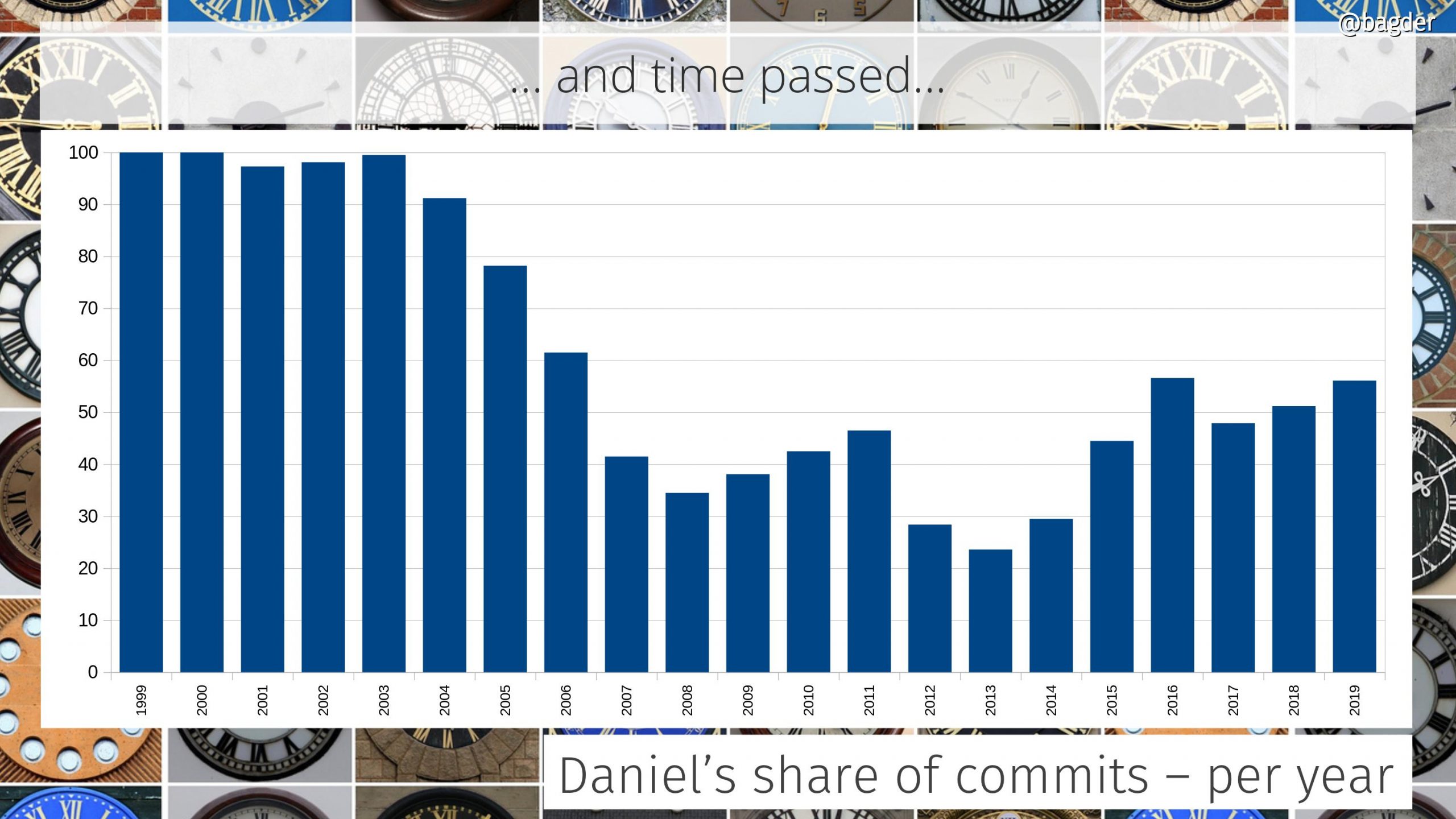
Daniel’s share of total commits
I started the project. I’m still very much involved and I spend a ridiculous amount of time and effort in driving this. We’re now over 770 commits authors and this graph shows how the share of commits I do to the project has developed over time. I’ve done about 57% of all commits in the source code repository right now.
The graph is the accumulated amount. Some individual years I actually did far less than 50% of the commits, which the following graph shows
Daniel’s share of commits per year
In the early days I was the only one who committed code. Over time a few others were “promoted” to the maintainer role and in 2010 we switched to git and the tracking of authors since then is much more accurate.
In 2014 I joined Mozilla and we can see an uptake in my personal participation level again after having been sub 50% by then for several years straight.
There’s always this argument to be had if it is a good or a bad sign for the project that my individual share is this big. Is this just because I don’t let other people in or because curl is so hard to work on and only I know my ways around the secret passages? I think the ever-growing number of commit authors at least show that it isn’t the latter.
What happens the day I grow bored or get run over by a bus? I don’t think there’s anything to worry about. Everything is free, open, provided and well documented.
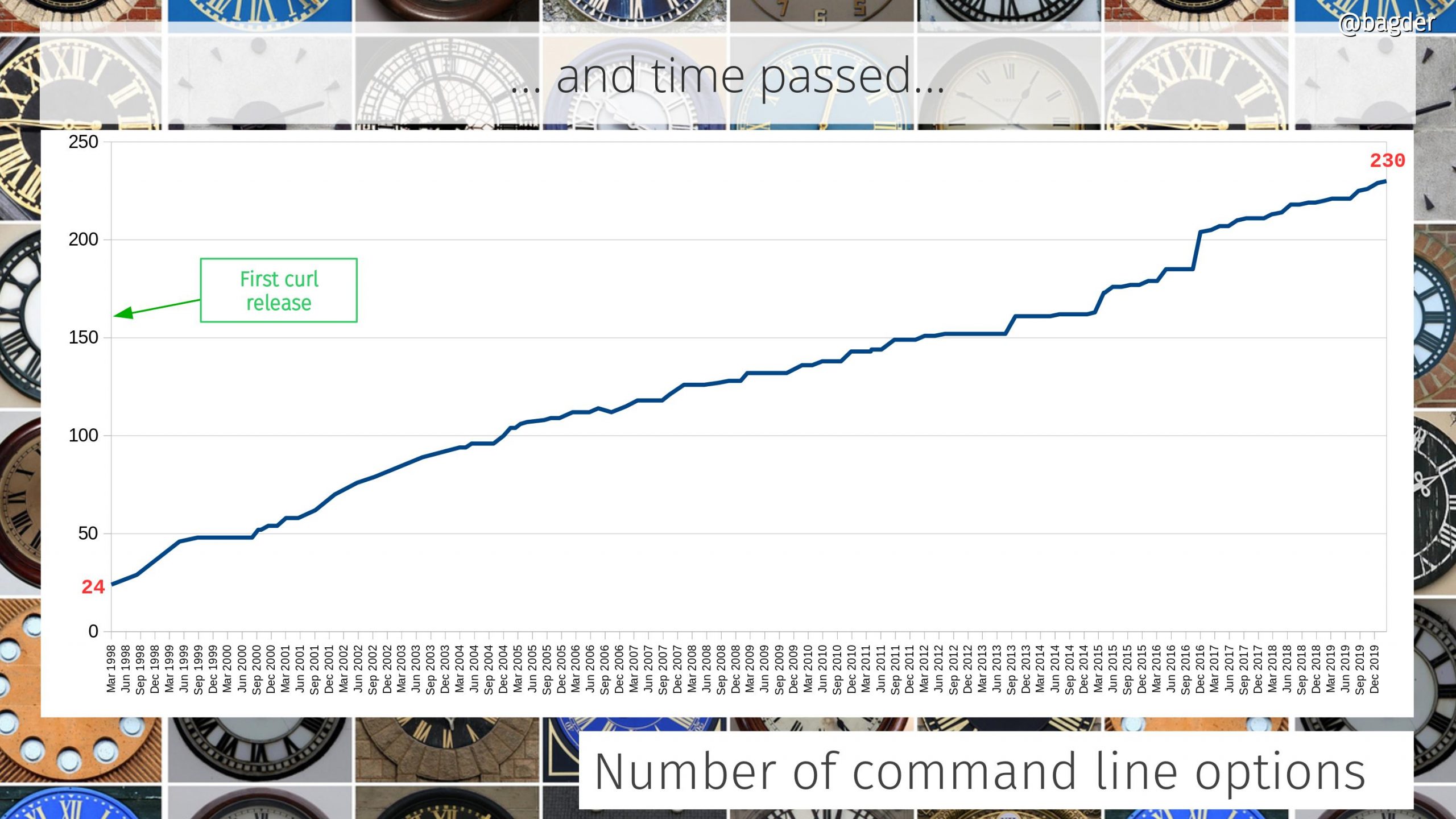
Number of command line options
The command line tool is really like a very elaborate Swiss army knife for Internet transfers and it provides many individual knobs and levers to control the powers. curl has a lot of command line options and they’ve grown in number like this.
Is curl growing too hard to use? Should we redo the “UI” ? Having this huge set of features like curl does, providing them all with a coherent and understandable interface is indeed a challenge…
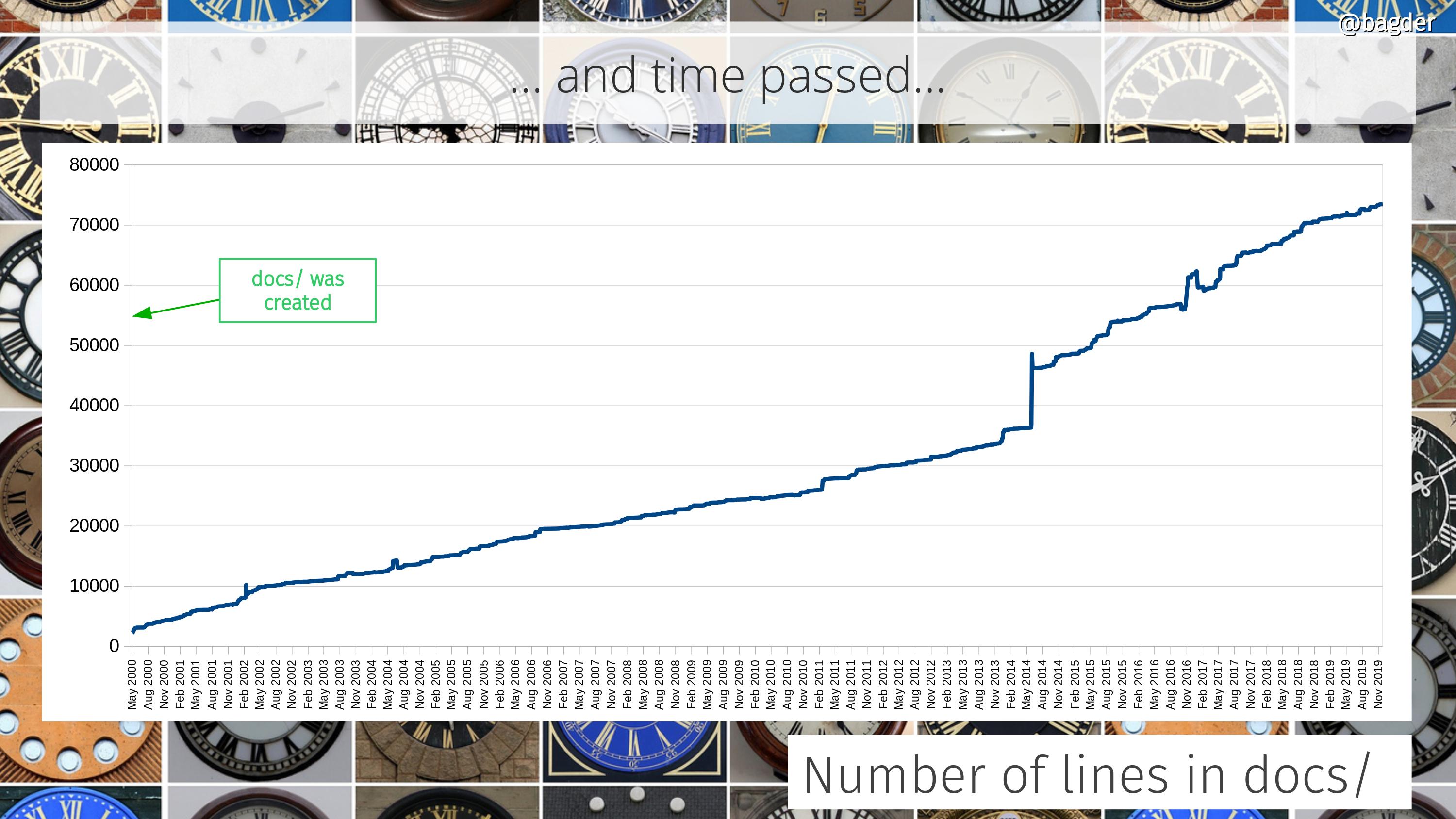
Number of lines in docs/
Documentation is crucial. It’s the foundation on which users can learn about the tool, the library and the entire project. Having plenty and good documentation is a project ambition. Unfortunately, we can’t easily measure the quality.
All the documentation in curl sits in the docs/ directory or sub directories in there. This shows how the amount of docs for curl and libcurl has grown through the years, in number of lines of text. The majority of the docs is in the form of man pages.
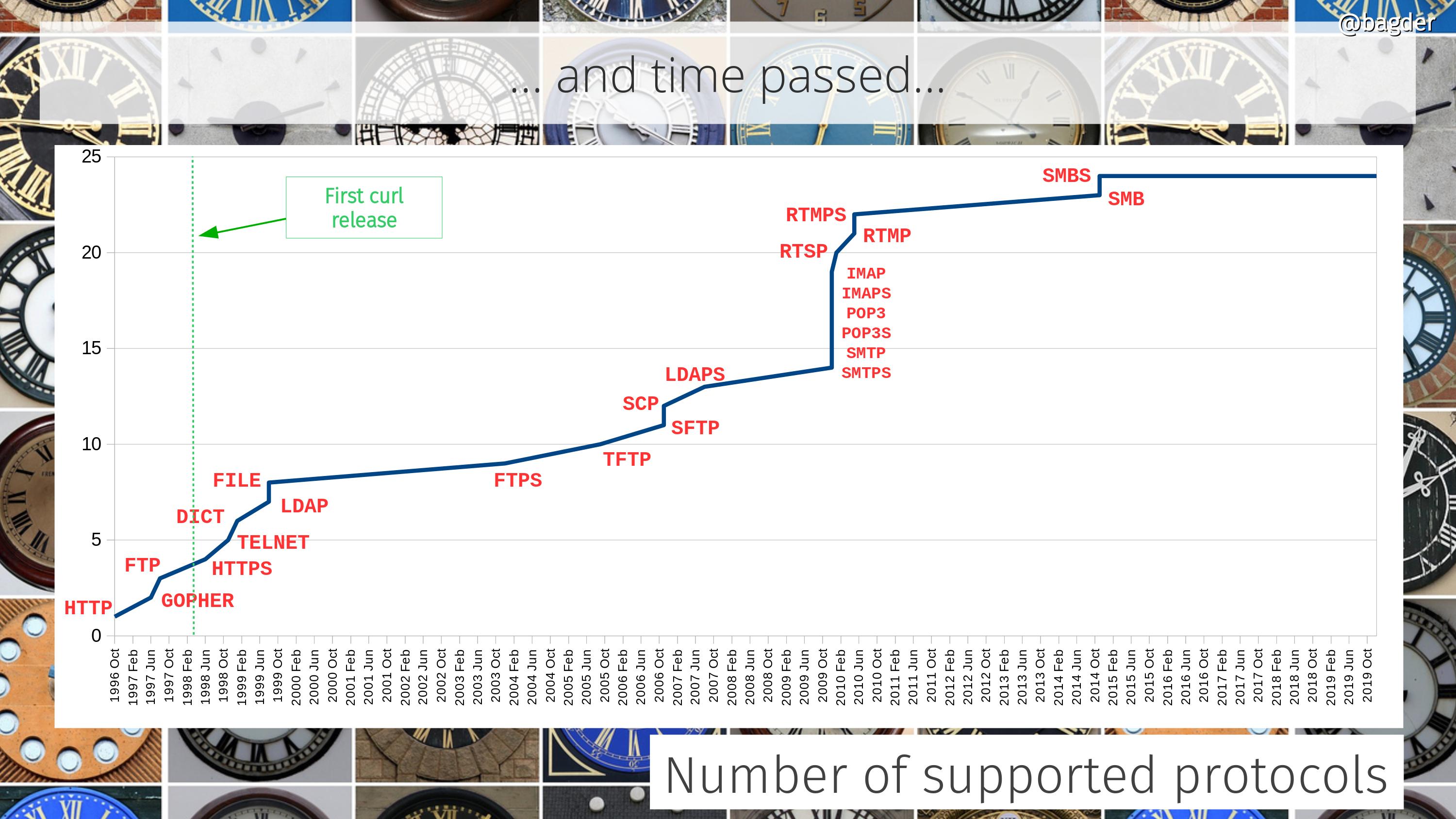
Number of supported protocols
This refers to protocols as in primary transfer protocols as in what you basically specify as a scheme in URLs (ie it doesn’t count “helper protocols” like TCP, IP, DNS, TLS etc). Did I tell you curl is much more than an HTTP client?
More protocols coming? Maybe. There are always discussions and ideas… But we want protocols to have a URL syntax and be transfer oriented to map with the curl mindset correctly.
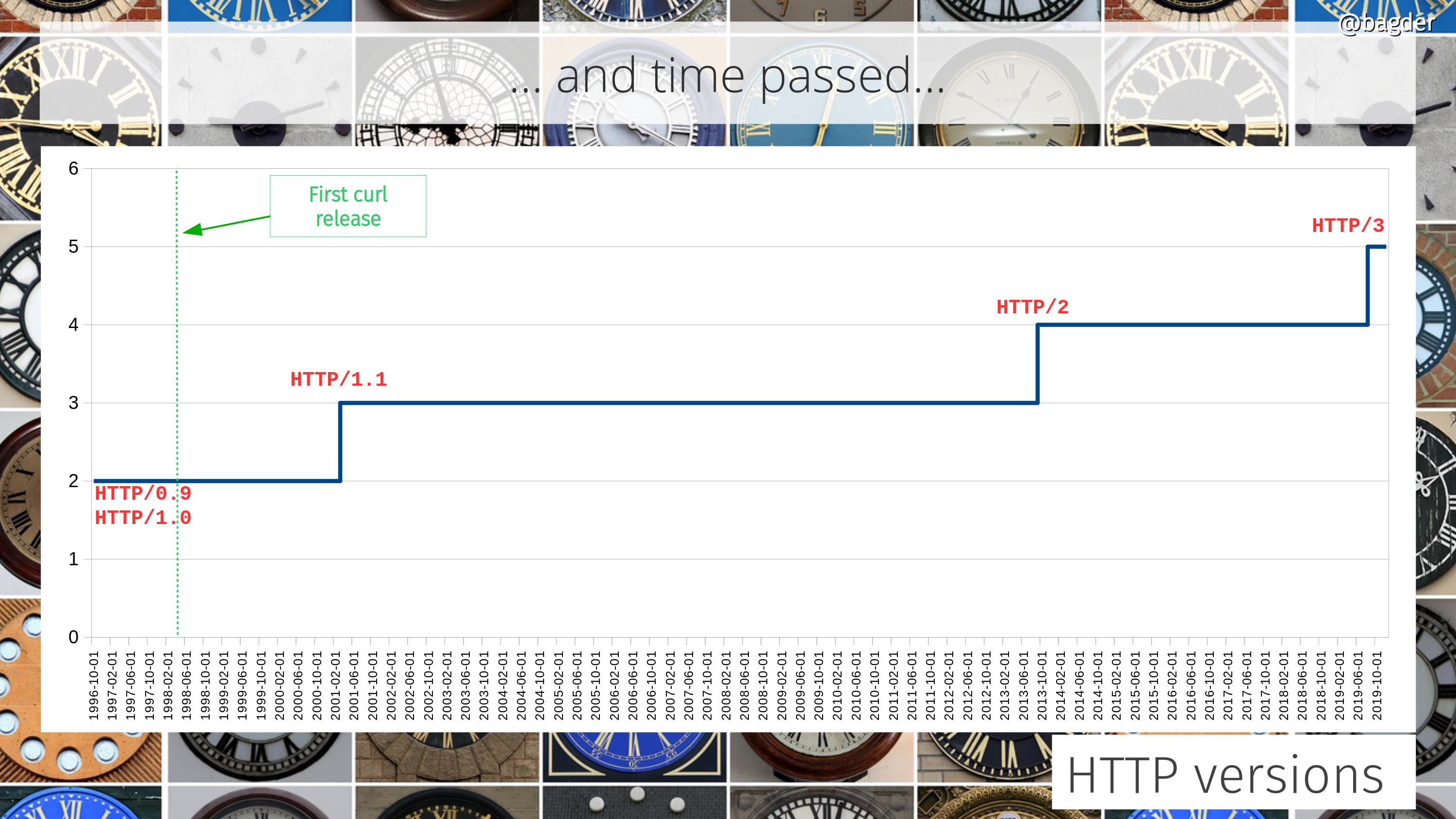
Number of HTTP versions
The support for different HTTP versions has also grown over the years. In the curl project we’re determined to support every HTTP version that is used, even if HTTP/0.9 support recently turned disabled by default and you need to use an option to ask for it.
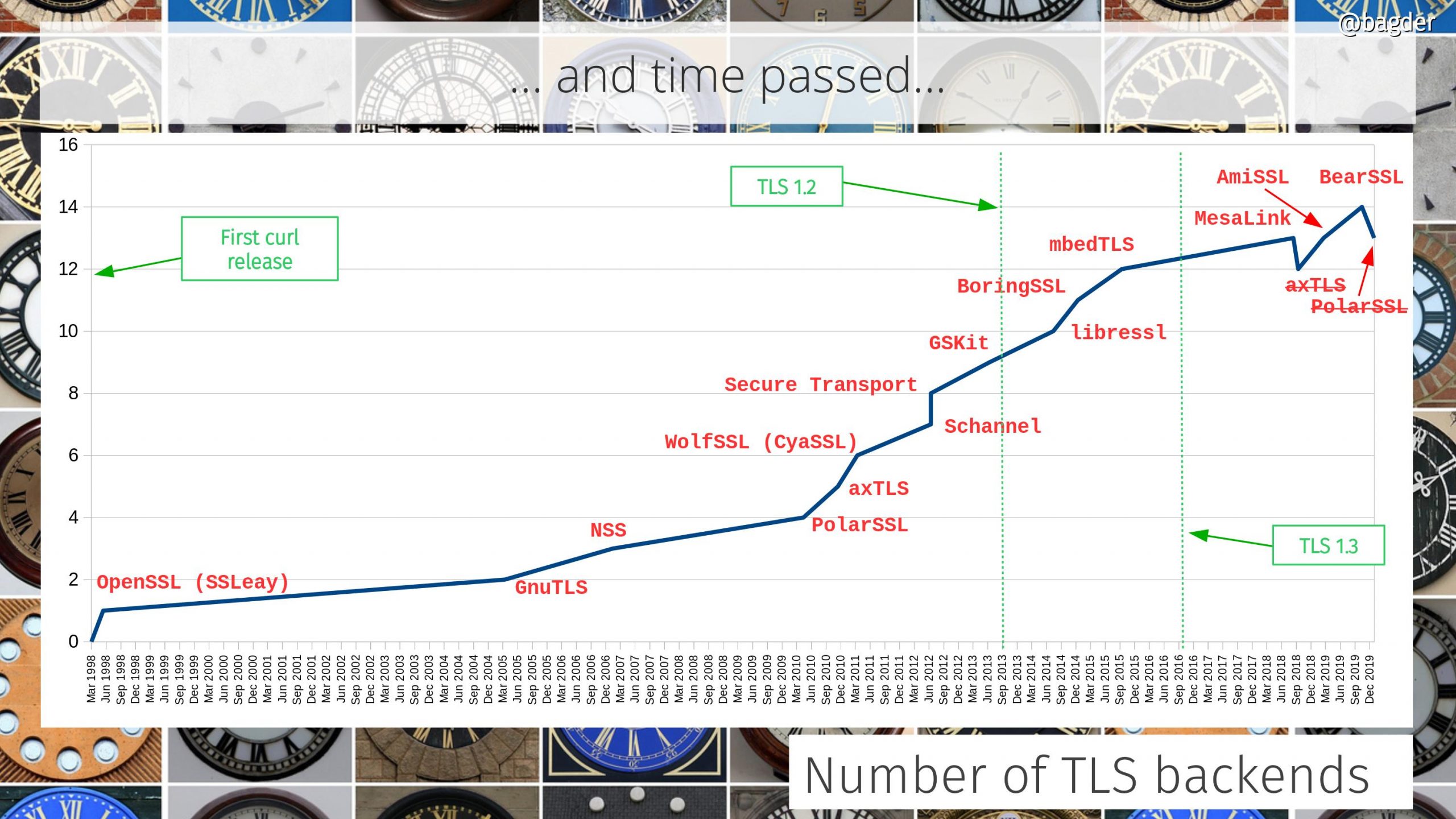
Number of TLS backends
The initial curl release didn’t even support HTTPS but since 2005 we’ve support customizable TLS backends and we’ve been adding support for many more ones since then. As we removed support for two libraries recently we’re now counting thirteen different supported TLS libraries.
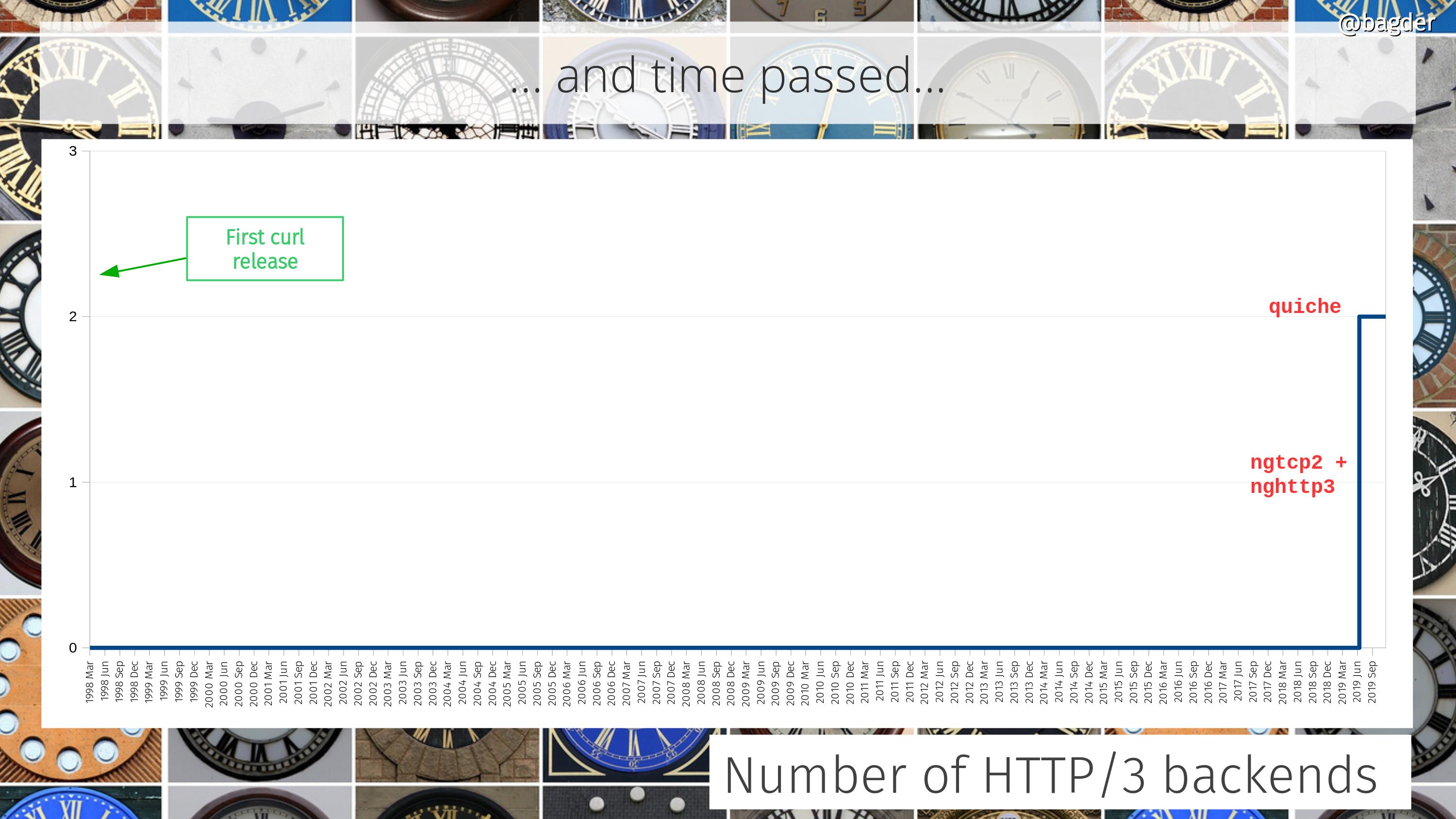
Number of HTTP/3 backends
Okay, this graph is mostly in jest but we recently added support for HTTP/3 and we instantly made that into a multi backend offering as well.
An added challenge that this graph doesn’t really show is how the choice of HTTP/3 backend is going to affect the choice of TLS backend and vice versa.
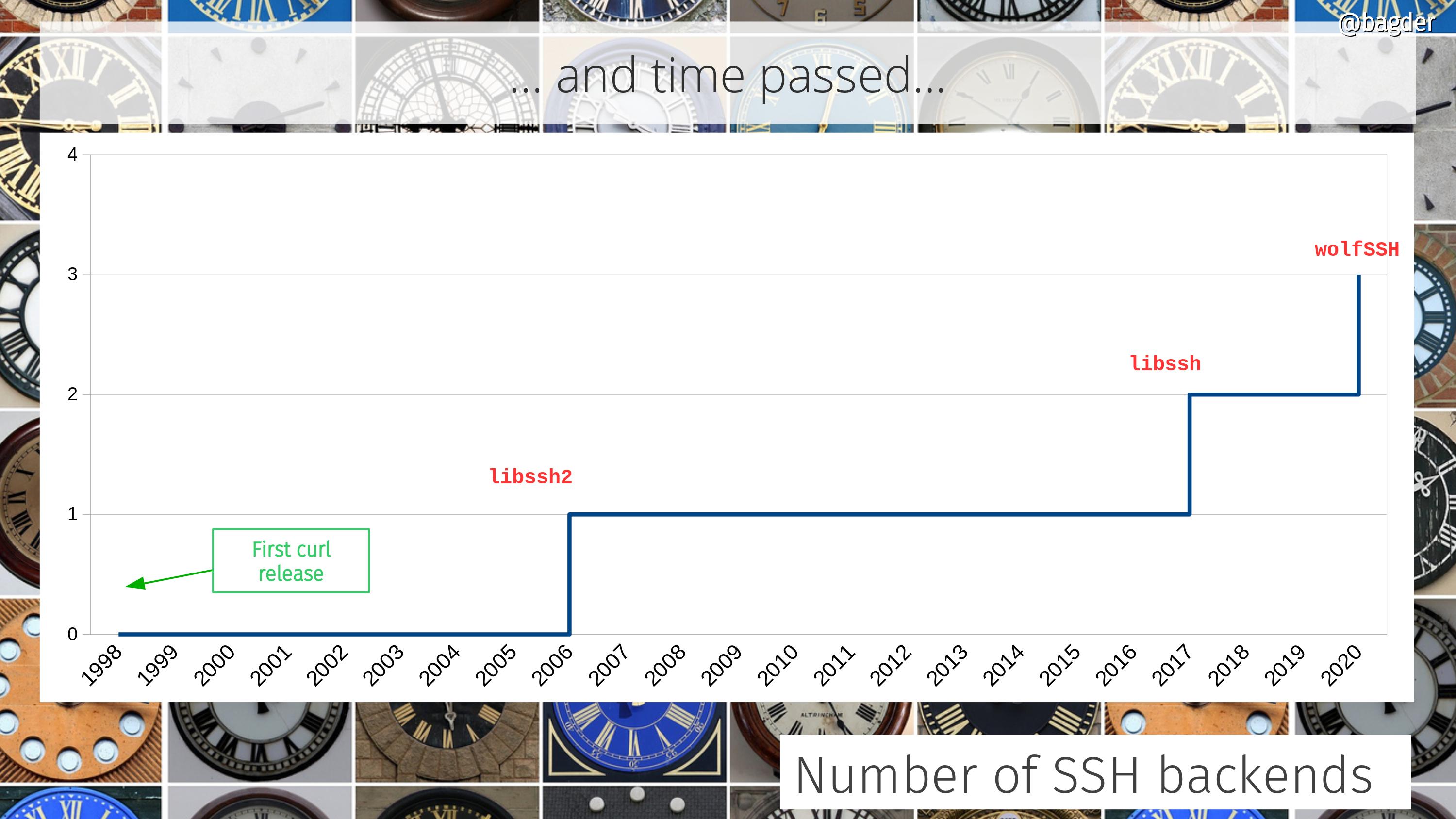
Number of SSH backends
For a long time we only supported a single SSH solution, but that was then and now we have three…
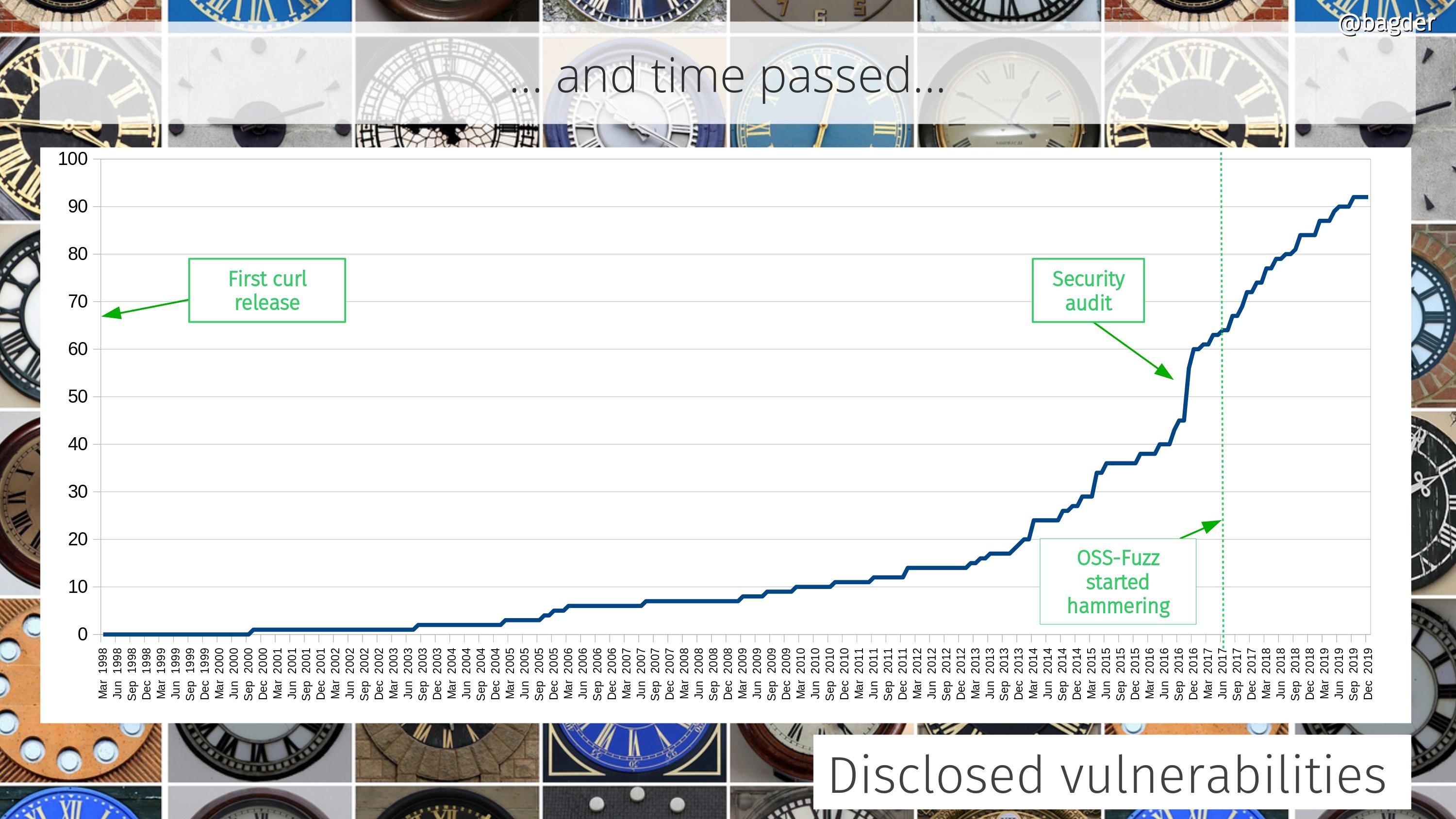
Number of disclosed vulnerabilities
We take security seriously and over time people have given us more attention and have spent more time digging deeper. These days we offer good monetary compensation for anyone who can find security flaws.
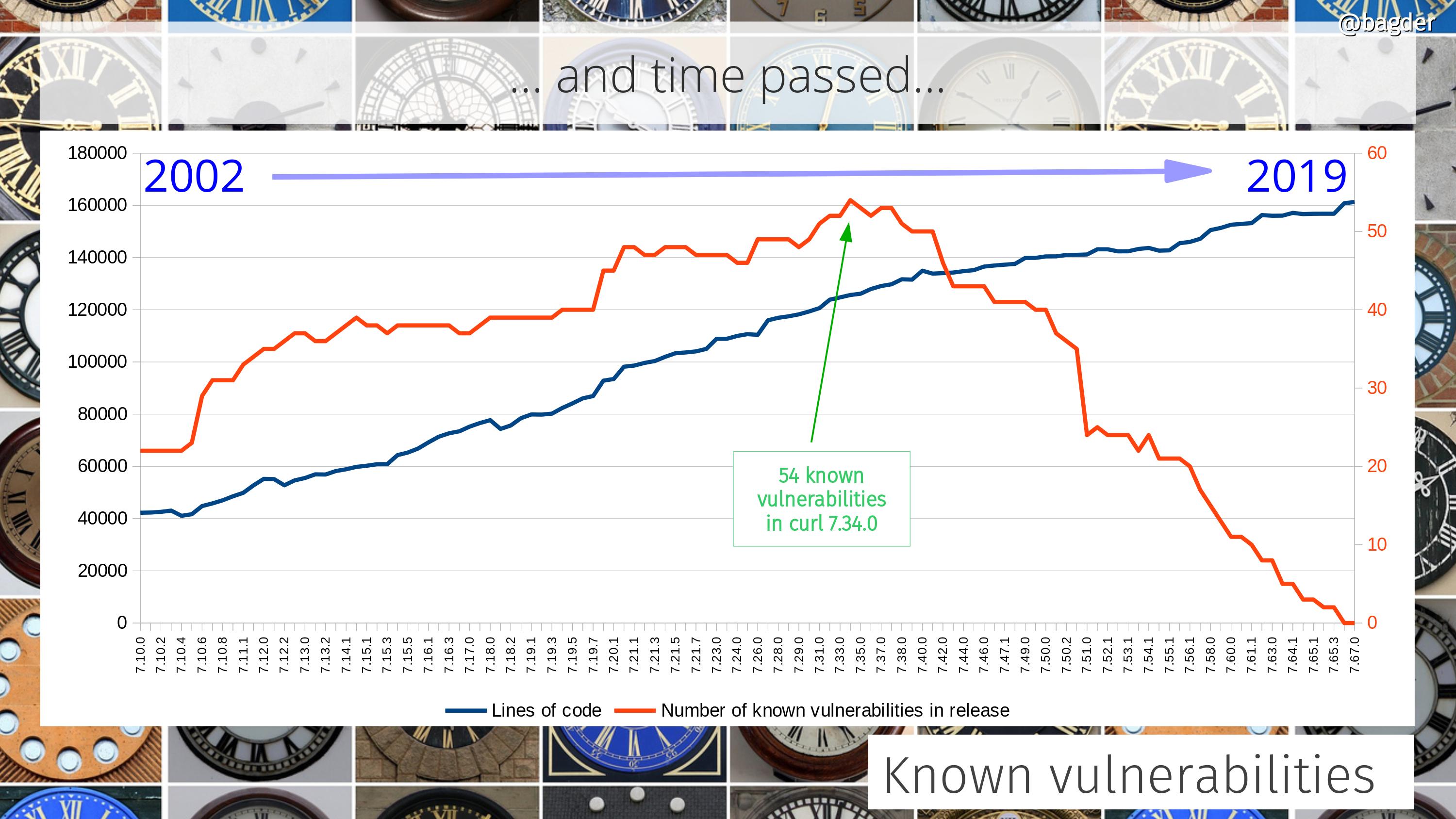
Number of known vulnerabilities
An attempt to visualize how many known vulnerabilities previous curl versions contain. Note that most of these problems are still fairly minor and some for very specific use cases or surroundings. As a reference, this graph also includes the number of lines of code in the corresponding versions.
More recent releases have less problems partly because we have better testing in general but also of course because they’ve been around for a shorter time and thus have had less time for people to find problems in them.
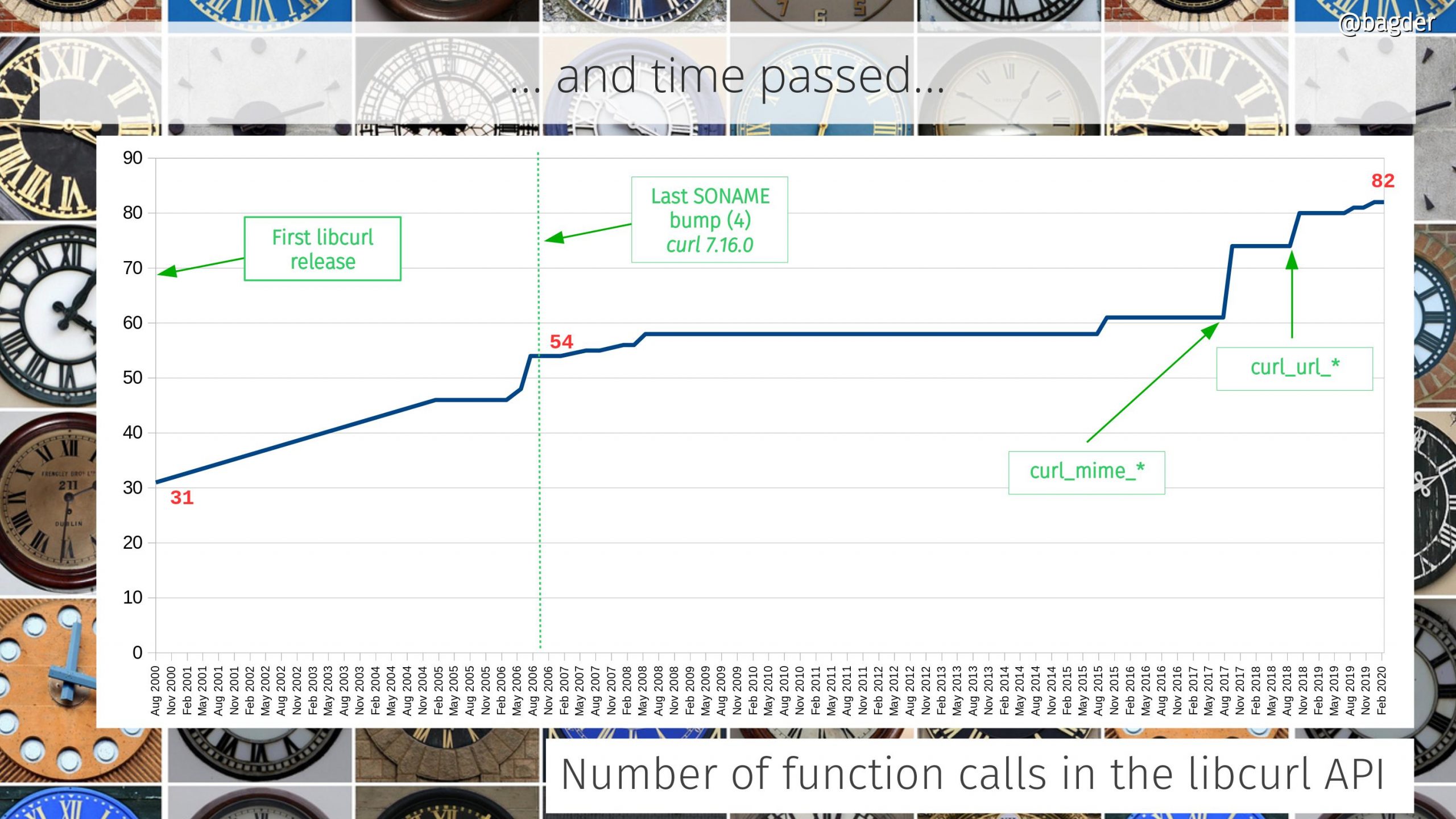
Number of function calls in the API
libcurl is an Internet transfer library and the number of provided function calls in the API has grown over time as we’ve learned what users want and need.
Anything that has been built with libcurl 7.16.0 or later you can always upgrade to a later libcurl and there should be no functionality change and the API and ABI are compatible. We put great efforts into make sure this remains true.
The largest API additions over the last few year are marked in the graph: when we added the curl_mime_* and the curl_url_* families. We now offer 82 function calls. We’ve added 27 calls over the last 14 years while maintaining the same soname (ABI version).
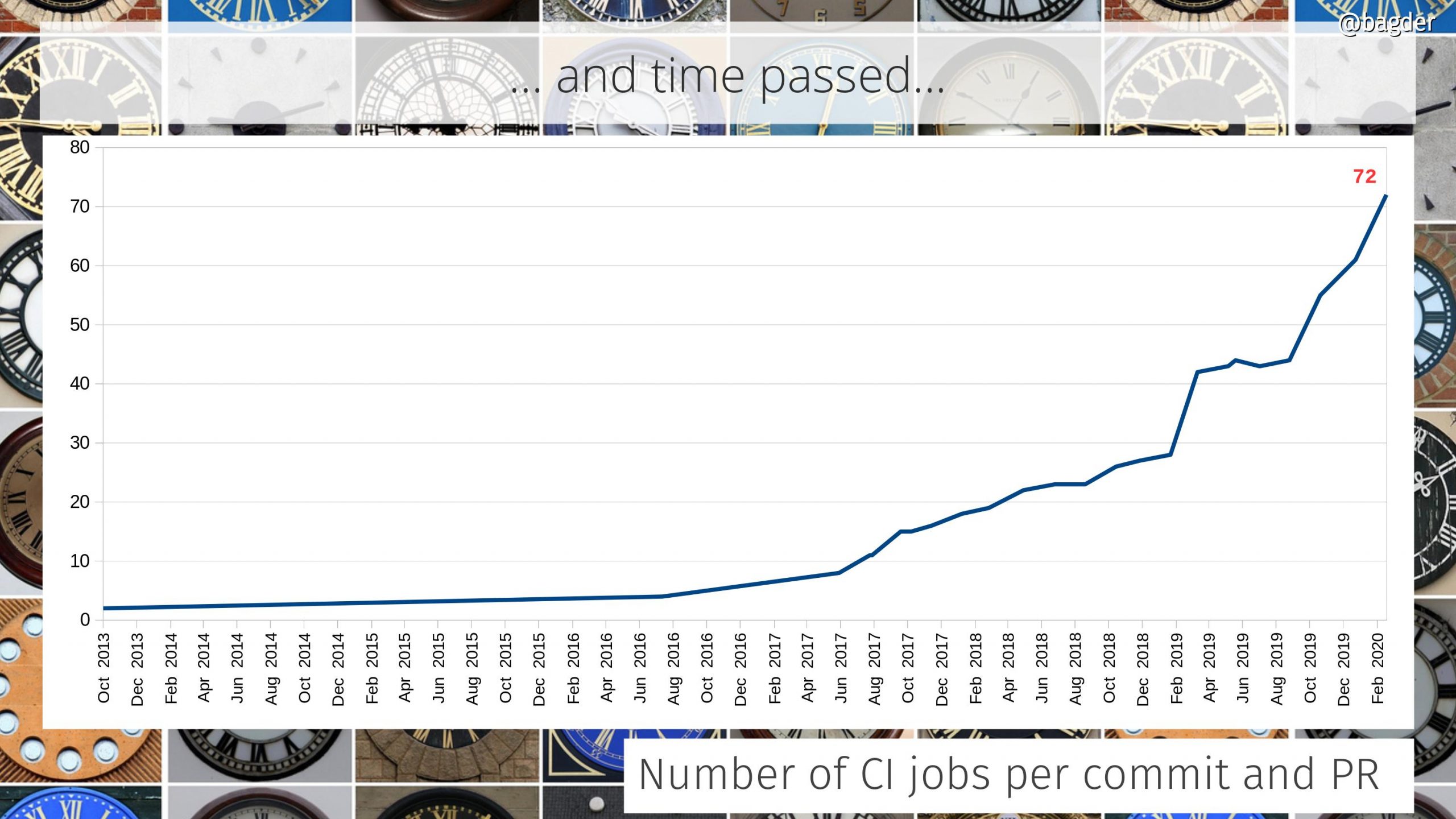
Number of CI jobs per commit and PR
We’ve had automatic testing in the curl project since the year 2000. But for many years that testing was done by volunteers who ran tests in cronjobs in their local machines a few times per day and sent the logs back to the curl web site that displayed their status.
The automatic tests are still running and they still provide value, but I think we all agree that getting the feedback up front in pull-requests is a more direct way that also better prevent bad code from ever landing.
The first CI builds were added in 2013 but it took a few more years until we really adopted the CI lifestyle and today we have 72, spread over 5 different CI services (travis CI, Appveyor, Cirrus CI, Azure Pipelines and Github actions). These builds run for every commit and all submitted pull requests on Github. (We actually have a few more that aren’t easily counted since they aren’t mentioned in files in the git repo but controlled directly from github settings.)
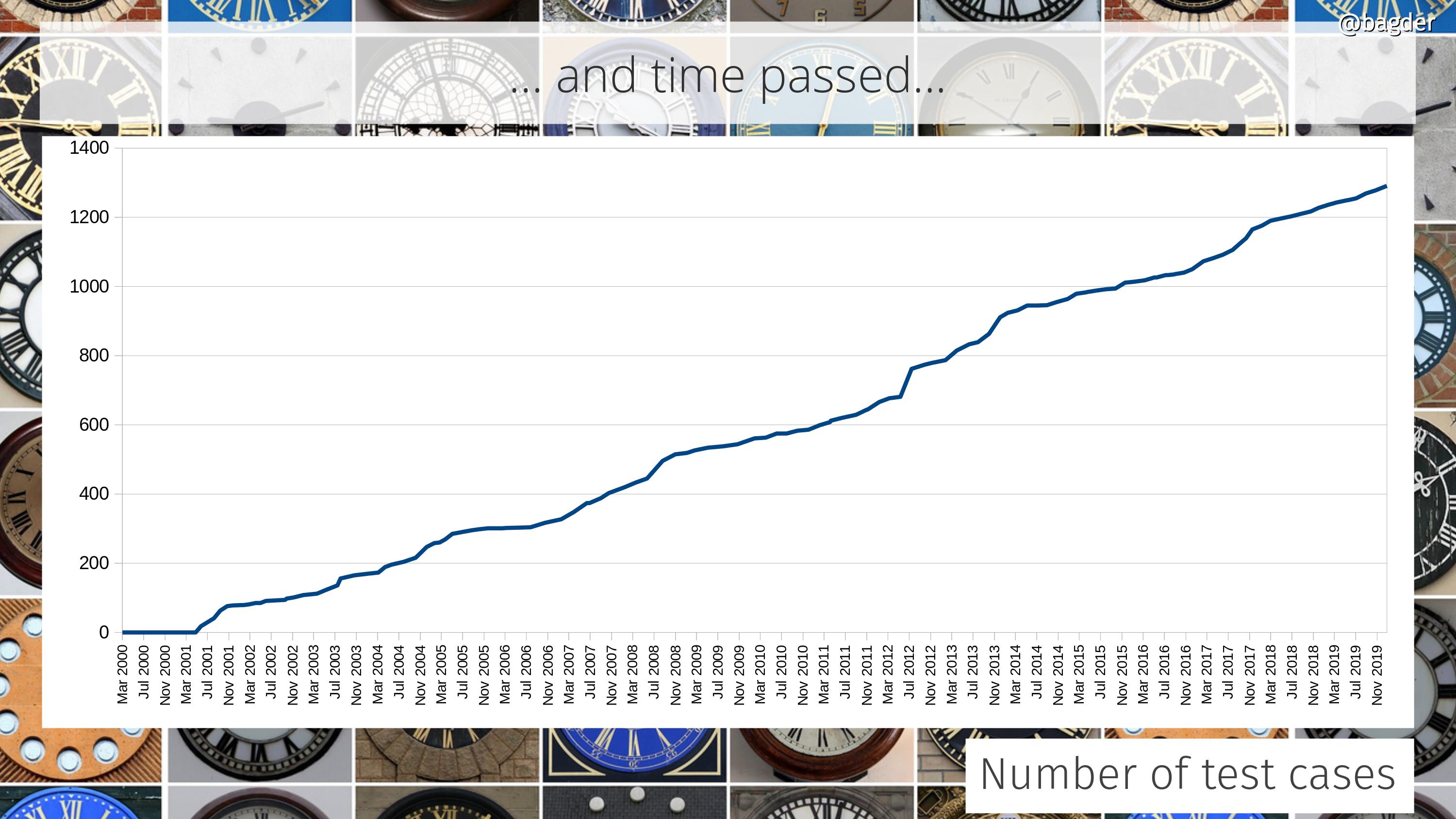
Number of test cases
A single test case can test a simple little thing or it can be a really big elaborate setup that tests a large number of functions and combinations. Counting test cases is in itself not really saying much, but taken together and looking at the change over time we can at least see that we continue to put efforts into expanding and increasing our tests. It should also be considered that this can be combined with the previous graph showing the CI builds, as most CI jobs also run all tests (that they can).
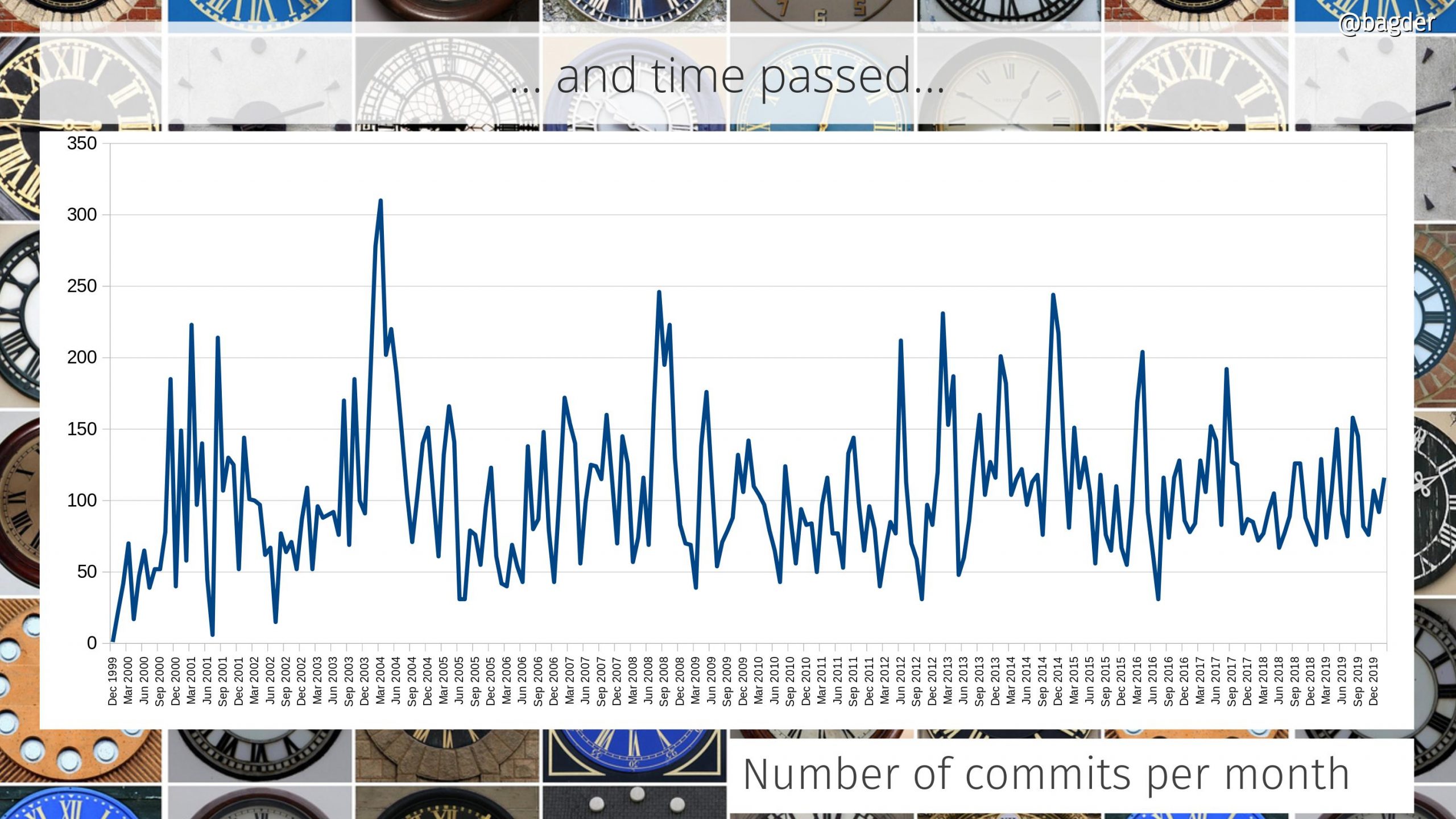
Number of commits per month
A commit can be tiny and it can be big. Counting a commit might not say a lot more than it is a sign of some sort of activity and change in the project. I find it almost strange how the number of commits per months over time hasn’t changed more than this!
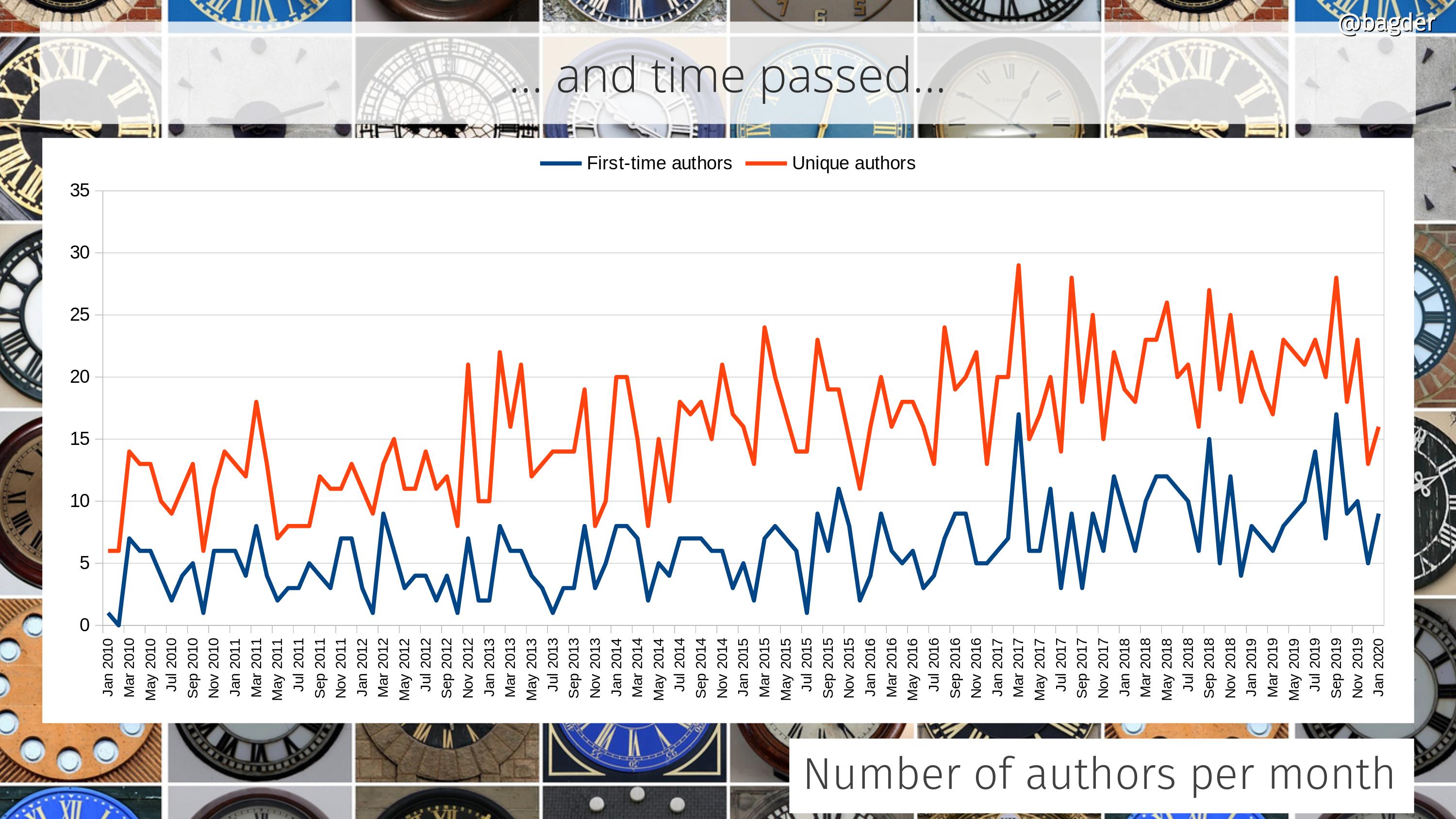
Number of authors per month
This shows number of unique authors per month (in red) together with the number of first-time authors (in blue) and how the amounts have changed over time. In the last few years we see that we are rarely below fifteen authors per month and we almost always have more than five first-time commit authors per month.
I think I’m especially happy with the retained high rate of newcomers as it is at least some indication that entering the project isn’t overly hard or complicated and that we manage to absorb these contributions. Of course, what we can’t see in here is the amount of users or efforts people have put in that never result in a merged commit. How often do we miss out on changes because of project inabilities to receive or accept them?
72 operating systems
Operating systems on which you can build and run curl for right now, or that we know people have ran curl on before. Most mortals cannot even list this many OSes off the top of their heads. If you know of any additional OS that curl has run on, please let me know!
20 CPU architectures
CPU architectures on which we know people have run curl. It basically runs on any CPU that is 32 bit or larger. If you know of any additional CPU architecture that curl has run on, please let me know!
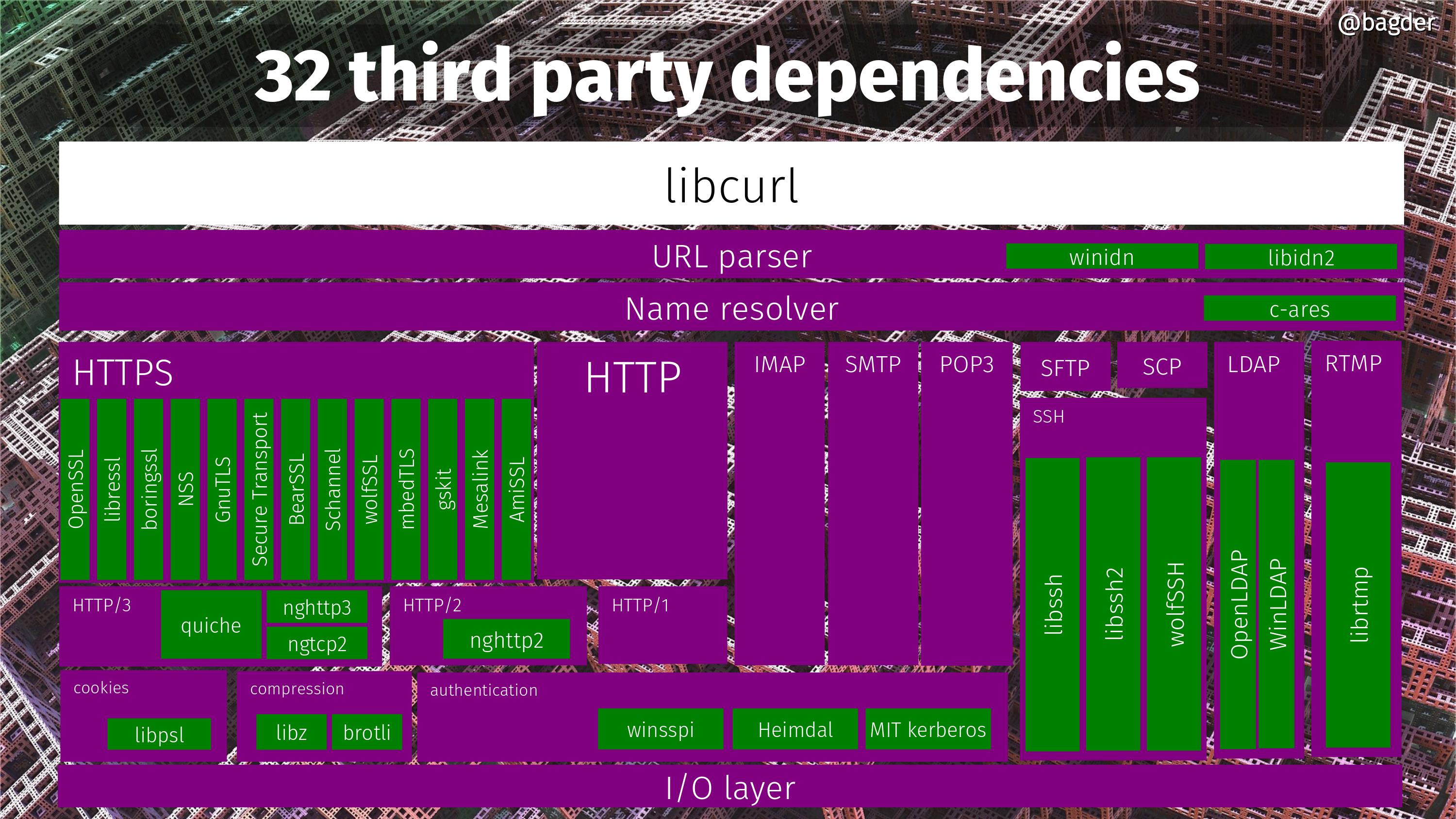
32 third party dependencies
Did I mention you can build curl in millions of combinations? That’s partly because of the multitude of different third party dependencies you can tell it to use. curl support no less than 32 different third party dependencies right now. The picture below is an attempt to some sort of block diagram and all the green boxes are third party libraries curl can potentially be built to use. Many of them can be used simultaneously, but a bunch are also mutually exclusive so no single build can actually use all 32.
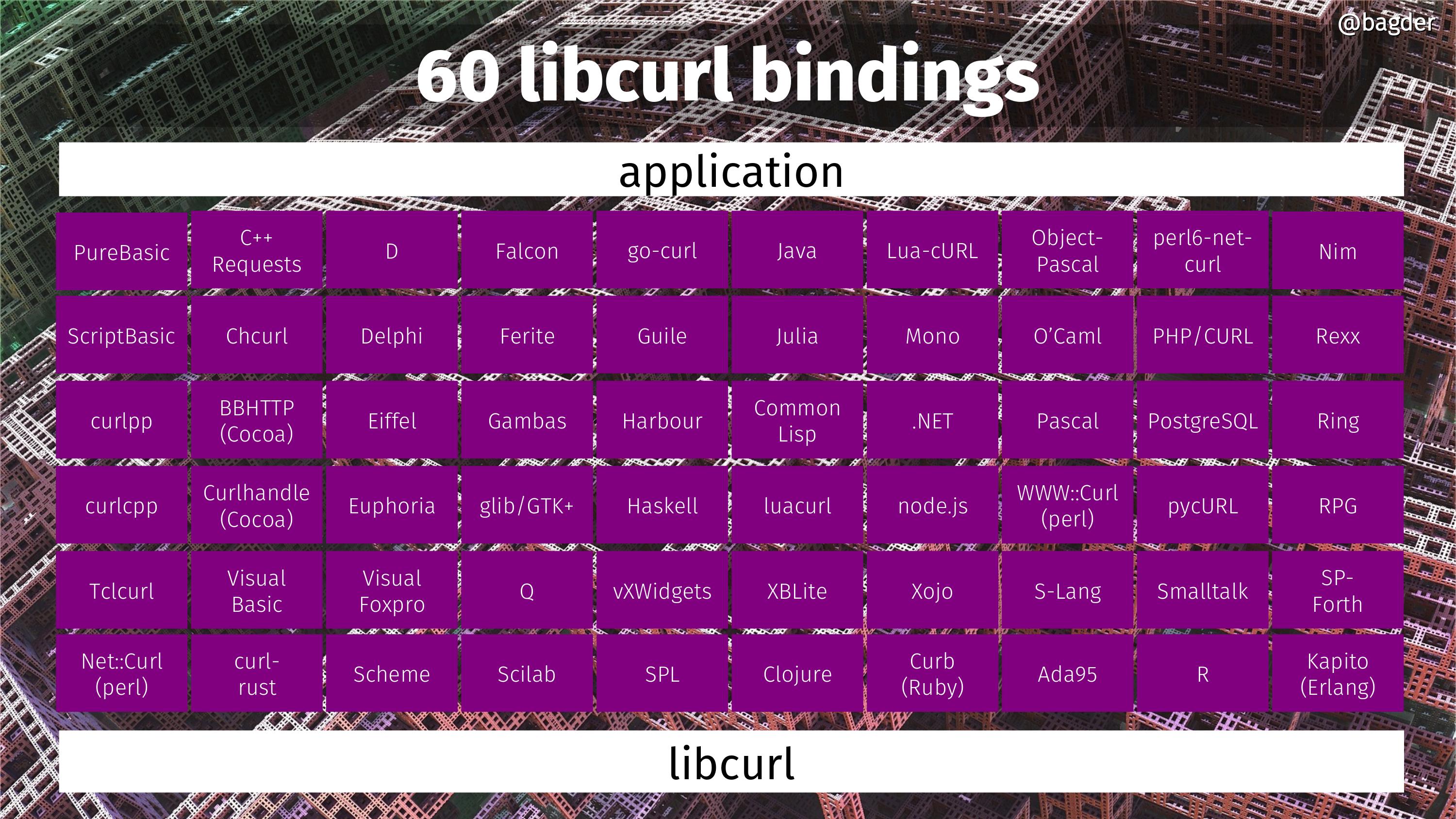
60 libcurl bindings
If you’re looking for more explanations how libcurl ends up being used in so many places, here are 60 more. Languages and environments that sport a “binding” that lets users of these languages use libcurl for Internet transfers.
Missing pictures
“number of downloads” could’ve been fun, but we don’t collect the data and most users don’t download curl from our site anyway so it wouldn’t really say a lot.
“number of users” is impossible to tell and while I’ve come up with estimates every now and then, making that as a graph would be doing too much out of my blind guesses.
“number of graphs in anniversary blog posts” was a contender, but in the end I decided against it, partly since I have too little data.
Every anniversary is an opportunity to reflect on what’s next.
In the curl project we don’t have any grand scheme or roadmap for the coming years. We work much more short-term. We stick to the scope: Internet transfers specified as URLs. The products should be rock solid and secure. The should be high performant. We should offer the features, knobs and levers our users need to keep doing internet transfers now and in the future.
curl is never done. The development pace doesn’t slow down and the list of things to work on doesn’t shrink.
This option takes a format string in which there are a number of different “variables” available that let’s a user output information from the previous transfer. For example, you can get the HTTP response code from a transfer like this:
That command line will spew some 800 bytes to the terminal and it won’t be very human readable. You will rather take care of that output with some kind of script/program, or if you want an eye pleasing version you can pipe it into jq and then it can look like this:
It always outputs the entire object and the object may of course differ over time, as I expect that we might add more fields into it in the future.
The names are the same as the write-out variables, so you can read the --write-out section in the man page to learn more.
Ships?
The feature landed in this commit. This new functionality will debut in the next pending release, likely to be called 7.70.0, scheduled to happen on April 29, 2020.
Credits
This is the result of fine coding work by Mathias Gumz.
This option was added to curl 7.59.0, March 2018 and is very rarely actually needed.
To understand this command line option, I think I should make a quick recap of what “happy eyeballs” is exactly and what timeout in there that this command line option is referring to!
Happy Eyeballs
This is the name of a standard way of connecting to a host (a server really in curl’s case) that has both IPv4 and IPv6 addresses.
When curl resolves the host name and gets a list of IP addresses back for it, it will try to connect to the host over both IPv4 and IPv6 in parallel, concurrently. The first of these connects that completes its handshake is considered the winner and the other connection attempt then gets ditched and is forgotten. To complicate matters a little more, a host name can resolve to a list of addresses of both IP versions and if a connect to one of the addresses fails, curl will attempt the next in a way so that IPv4 addresses and IPv6 addresses will be attempted, simultaneously, until one succeeds.
curl races connection attempts against each other. IPv6 vs IPv4.
Of course, if a host name only has addresses in one IP version, curl will only use that specific version.
Happy Eyeballs Timeout
For hosts having both IPv6 and IPv4 addresses, curl will first fire off the IPv6 attempt and then after a timeout, start the first IPv4 attempt. This makes curl prefer a quick IPv6 connect.
The default timeout from the moment the first IPv6 connect is issued until the first IPv4 starts, is 200 milliseconds. (The Happy Eyeballs RFC 6555 claims Firefox and Chrome both use a 300 millisecond delay, but I’m not convinced this is actually true in current versions.)
By altering this timeout, you can shift the likeliness of one or the other connect to “win”.
Example: change the happy eyeballs timeout to the same value said to be used by some browsers (300 milliseconds):
There’s a Happy Eyeballs version two, defined in RFC 8305. It takes the concept a step further and suggests that a client such as curl should start the first connection already when the first name resolve answers come in and not wait for all the responses to arrive before it starts the racing.
curl does not do that level “extreme” Happy Eyeballing because of two simple reasons:
1. there’s no portable name resolving function that gives us data in that manner. curl won’t start the actual connection procedure until the name resolution phase is completed, in its entirety.
2. getaddrinfo() returns addresses in a defined order that is hard to follow if we would side-step that function as described in RFC 8305.
Taken together, my guess is that very few internet clients today actually implement Happy Eyeballs v2, but there’s little to no reason for anyone to not implement the original algorithm.
Curios extra
curl has done Happy Eyeballs connections since 7.34.0 (December 2013) and yet we had this lingering bug in the code that made it misbehave at times, only just now fixed and not shipped in a release yet. This bug makes curl sometimes retry the same failing IPv6 address multiple times while the IPv4 connection is slow.
Related options
--connect-timeout limits how long to spend trying to connect and --max-time limits the entire curl operation to a fixed time.
The Windows operating system will automatically, and without any way for applications to disable it, try to establish a connection to another host over the network and access it (over SMB or other protocols), if only the correct file path is accessed.
When first realizing this, the curl team tried to filter out such attempts in order to protect applications for inadvertent probes of for example internal networks etc. This resulted in CVE-2019-15601 and the associated security fix.
However, we’ve since been made aware of the fact that the previous fix was far from adequate as there are several other ways to accomplish more or less the same thing: accessing a remote host over the network instead of the local file system.
The conclusion we have come to is that this is a weakness or feature in the Windows operating system itself, that we as an application and library cannot protect users against. It would just be a whack-a-mole race we don’t want to participate in. There are too many ways to do it and there’s no knob we can use to turn off the practice.
We no longer consider this to be a curl security flaw!
If you use curl or libcurl on Windows (any version), disable the use of the FILE protocol in curl or be prepared that accesses to a range of “magic paths” will potentially make your system try to access other hosts on your network. curl cannot protect you against this.
This was previously considered a curl security problem, as reported in CVE-2019-15601. We no longer consider that a security flaw and have updated that web page with information matching our new findings. I don’t expect any other CVE database to update since there’s no established mechanism for updating CVEs!
Credits
Many thanks to Tim Sedlmeyer who highlighted the extent of this issue for us.
This release comes but 7 days since the previous and is a patch release only, hence called 7.69.1.
Numbers
the 190th release 0 changes 7 days (total: 8,027) 27 bug fixes (total: 5,938) 48 commits (total: 25,405 0 new public libcurl function (total: 82) 0 new curl_easy_setopt() option (total: 270) 0 new curl command line option (total: 230) 19 contributors, 6 new (total: 2,133) 7 authors, 1 new (total: 772) 0 security fixes (total: 93) 0 USD paid in Bug Bounties
Unplanned patch release
Quite obviously this release was not shipped aligned with our standard 8-week cycle. The reason is that we had too many semi-serious or at least annoying bugs that were reported early on after the 7.69.0 release last week. They made me think our users will appreciate a quick follow-up that addresses them. See below for more details on some of those flaws.
How can this happen in a project that soon is 22 years old, that has thousands of tests, dozens of developers and 70+ CI jobs for every single commit?
The short answer is that we don’t have enough tests that cover enough use cases and transfer scenarios, or put another way: curl and libcurl are very capable tools that can deal with a nearly infinite number of different combinations of protocols, transfers and bytes over the wire. It is really hard to cover all cases.
Also, an old wisdom that we learned already many years ago is that our code is always only properly widely used and tested the moment we do a release and not before. Everything can look good in pre-releases among all the involved developers, but only once the entire world gets its hands on the new release it really gets to show what it can or cannot do.
This time, a few of the changes we had landed for 7.69.0 were not good enough. We then go back, fix issues, land updates and we try again. So here comes 7.69.1 – better patch than sorry!
Bug-fixes
As the numbers above show, we managed to land an amazing number of bug-fixes in this very short time. Here are seven of the more important ones, from my point of view! Not all of them were regressions or even reported in 7.69.0, some of them were just ripe enough to get landed in this release.
unpausing HTTP/2 transfers
When I fixed the pausing and unpausing of HTTP/2 streams for 7.69.0, the fix was inadequate for several of the more advanced use cases and unfortunately we don’t have good enough tests to detect those. At least two browsers built to use libcurl for their HTTP engines reported stalled HTTP/2 transfers due to this.
I reverted the previous change and I’ve landed a different take that seems to be a more appropriate one, based on early reports.
pause: cleanups
After I had modified the curl_easy_pause function for 7.69.0, we also got reports about crashes with uses of this function.
It made me do some additional cleanups to make it more resilient to bad uses from applications, both when called without a correct handle or when it is called to just set the same pause state it is already in
socks: connection regressions
I was so happy with my overhauled SOCKS connection code in 7.69.0 where it was made entirely non-blocking. But again it turned out that our test cases for this weren’t entirely mimicking the real world so both SOCKS4 and SOCKS5 connections where curl does the name resolving could easily break. The test cases probably worked fine there because they always resolve the host name really quick and locally.
SOCKS4 connections are now also forced to be done over IPv4 only, as that was also something that could trigger a funny error – the protocol doesn’t support IPv6, you need to go to SOCKS5 for that!
Both version 4 and 5 of the SOCKS proxy protocol have options to allow the proxy to resolve the server name or you can have the client (curl) do it. (Somewhat described in the CURLOPT_PROXY man page.) These problems were found for the cases when curl resolves the server name.
libssh: MD5 hex comparison
For application users of the libcurl CURLOPT_SSH_HOST_PUBLIC_KEY_MD5 option, which is used to verify that curl connects to the right server, this change makes sure that the libssh backend does the right thing and acts exactly like the libssh2 backend does and how the documentation says it works…
libssh2: known hosts crash
In a recent change, libcurl will try to set a preferred method for the knownhost matching libssh2 provides when connecting to a SSH server, but the code unfortunately contained an easily triggered NULL pointer dereference that no review caught and obviously no test either!
c-ares: duphandle copies DNS servers too
curl_easy_duphandle() duplicates a libcurl easy handle and is frequently used by applications. It turns out we broke a little piece of the function back in 7.63.0 as a few DNS server options haven’t been duplicated properly since then. Fixed now!
This was an out-of-schedule release but the plan is to stick to the established release schedule, which will have the effect that the coming release window will be one week shorter than usual and the full cycle will complete in 7 weeks instead of 8.
This option is called -Q in its short form, --quote in its long form. It has existed for as long as curl has existed.
Quote?
The name for this option originates from the traditional unix command ‘ftp’, as it typically has a command called exactly this: quote. The quote command for the ftp client is a way to send an exact command, as written, to the server. Very similar to what --quote does.
FTP, FTPS and SFTP
This option was originally made for supported only for FTP transfers but when we added support for FTPS, it worked there too automatically.
When we subsequently added SFTP support, even such users occasionally have a need for this style of extra commands so we made curl support it there too. Although for SFTP we had to do it slightly differently as SFTP as a protocol can’t actually send commands verbatim to the server as we can with FTP(S). I’ll elaborate a bit more below.
Sending FTP commands
The FTP protocol is a command/response protocol for which curl needs to send a series of commands to the server in order to get the transfer done. Commands that log in, changes working directories, sets the correct transfer mode etc.
Asking curl to access a specific ftp:// URL more or less converts into a command sequence.
The --quote option provides several different ways to insert custom FTP commands into the series of commands curl will issue. If you just specify a command to the option, it will be sent to the server before the transfer takes places – even before it changes working directory.
If you prefix the command with a minus (-), the command will instead be send after a successful transfer.
If you prefix the command with a plus (+), the command will run immediately before the transfer after curl changed working directory.
As a second (!) prefix you can also opt to insert an asterisk (*) which then tells curl that it should continue even if this command would cause an error to get returned from the server.
The actually specified command is a string the user specifies and it needs to be a correct FTP command because curl won’t even try to interpret it but will just send it as-is to the server.
FTP examples
For example, remove a file from the server after it has been successfully downloaded:
Despite sounding similar, SFTP is a very different protocol than FTP(S). With SFTP the access is much more low level than FTP and there’s not really a concept of command and response. Still, we’ve created a set of command for the --quote option for SFTP that lets the users sort of pretend that it works the same way.
Since there is no sending of the quote commands verbatim in the SFTP case, like curl does for FTP, the commands must instead be supported by curl and get translated into their underlying SFTP binary protocol bits.
In order to support most of the basic use cases people have reportedly used with curl and FTP over the years, curl supports the following commands for SFTP: chgrp, chmod, chown, ln, mkdir, pwd, rename, rm, rmdir and symlink.
The minus and asterisk prefixes as described above work for SFTP too (but not the plus prefix).
Example, delete a file after a successful download over SFTP:
curl -O sftp://example/file -Q '-rm file'
Rename a file on the target server after a successful upload:
The SSH support in curl is powered by a third party SSH library. When you build curl, there are three different libraries to select from and they will have a slightly varying degree of support. The libssh2 and libssh backends are pretty much feature complete and have been around for a while, where as the wolfSSH backend is more bare bones with less features supported but at much smaller footprint.
Related options
--request changes the actual command used to invoke the transfer when listing directories with FTP.
Perhaps the best news this time is the complete lack of any reported (or fixed) security issues?
Numbers
the 189th release 3 changes 56 days (total: 8,020) 123 bug fixes (total: 5,911) 233 commits (total: 25,357) 0 new public libcurl function (total: 82) 1 new curl_easy_setopt() option (total: 270) 1 new curl command line option (total: 230) 69 contributors, 39 new (total: 2,127) 32 authors, 15 new (total: 771) 0 security fixes (total: 93) 0 USD paid in Bug Bounties
Contributors
Let me first highlight these lovely facts about the community effort that lies behind this curl release!
During the 56 days it took us to produce this particular release, 69 persons contributed to what it is. 39 friends in this crowd were first-time contributors. That’s more than one newcomer every second day. Reporting bugs and providing code or documentation are the primary ways people contribute.
We landed commits authored by 32 individual humans, and out of those 15 were first-time authors! This means that we’ve maintained an average of well over 5 first-time authors per month for the last several years.
The making of curl is a team effort. And we have a huge team!
Changes
In this release cycle we finally removed all traces of support for PolarSSL in the TLS related code. This library doesn’t get updates anymore and has effectively been superseded by its sibling mbedTLS – which we already support since years back. There’s really no reason for anyone to hang on to PolarSSL anymore. Move over to a modern library. wolfSSL, mbedTLS and BearTLS are all similar in spirit and focus. curl now supports 13 different TLS libraries.
We added support for a command line option (--mail-rcpt-allowfails) as well as a libcurl option (CURLOPT_MAIL_RCPT_ALLLOWFAILS) that allows an application to tell libcurl that recipients are fine to fail, as long as at least one is fine. This makes it much easier for applications to send mails to a series of addresses, out of which perhaps a few will fail immediately.
We landed initial support for wolfSSH as a new SSH backend in curl for SFTP transfers.
My top-11 favorite bug-fixes
As usual we’ve landed over a hundred bug-fixes, where most are minor. Here are eleven of the fixes I think stand out a little:
SOCKS connects are now non-blocking
For a very long time we’ve had this outstanding issue that libcurl did the connection phase to SOCKS proxies in a blocking fashion. This of course had unfortunate side-effects if you do many parallel transfers and maybe use slow or remote SOCKS proxies as then each such connection would starve out the others for the duration of the connect handshake.
Now that’s history and libcurl performs SOCKS connection establishment totally non-blocking!
Improved alt-svc parsing
Turns out I had misunderstood the spec a little and the parser needed to be fixed to better deal with some of the real-world Alt-Svc: response headers out there! A fine side effect of more people trying out our early HTTP/3 support, as this is the first major use case of this header in the wild.
Atomic cookie and alt-svc file saves
When saving files to disk, libcurl would previously simply open the file, write all the contents to it and then close it. This caused issues for multi-threaded libcurl users that potentially could start to try to use the saved file before it was done saving, and thus would end up reading partial file. This concerns both cookie and alt-svc usage.
Starting now, libcurl will always save these files into a temporary file with a random suffix while writing data to them, and then when everything is complete, rename the file over to the actual and proper file name. This will make the saving (appear) atomic to all consumers of such files, even in multi-threaded scenarios.
HTTP/2 stream pauses
An application using libcurl to receive a download can tell libcurl to pause the transfer at any given moment. Typically this is used by applications that for some reason consumes the incoming data slowly or has to use small local buffer for it or similar. The transfer is then typically “unpaused” again within shortly and the data can continue flowing in.
When this kind of pause was done for a HTTP/2 stream over a connection that also had other streams going, libcurl previously didn’t actually pause the transfer for real but only “faked” it to the application and instead buffered the incoming data in memory.
In 7.69.0, libcurl will now actually pause HTTP/2 streams for real, even if it might still need to buffer up to a full HTTP/2 window size of data in memory. The HTTP/2 window size is now also reduced to 32MB to at least limit the worst case buffer need to that amount. We might need to come back to this in a future to provide better means for applications to deal with the window size and buffering requirements…
Increased Expect: threshold
Previously, libcurl would add the Expect: header if more than 1024 bytes were sent in the body. Now that limit is raised to 1 MB instead.
HTTP 417 treatment
A 417 HTTP response code from a server when curl has issued a request using the Expect: header means the request should be redone without that header. Starting now, curl does so!
openssl: make CURLINFO_CERTINFO not truncate x509v3 fields
This feature that lets an application extract certificate information from a site curl communicates to had an unfortunate truncating issue that made very long fields occasionally not get returned in full!
smtp: Support UTF-8 based host names
curl SMTP support is now improved when it comes to using IDN names in the URL host name and also in the email addresses provided to some of the SMTP related options and commands.
include: remove non-curl prefixed defines
The public libcurl include files now finally define or provide not a single symbol that isn’t correctly prefixed with either curl or libcurl (in various case versions). This was a cleanup that’s been postponed much too long but a move that should make the headers less likely to ever collide or cause problems in combination with other headers or projects. Keeping within one’s naming scope is important for a good ecosystem citizen.
curl_global_init polish
We made the function assume the EINTR flag by default and we moved away the IPv6 check. Two small parts in an ongoing work to eventually make it thread-safe.
CIFuzz and more Azure jobs
We bumped the number of CI jobs per commit significantly this release cycle, up from 61 to 72.
CIFuzz is a great new addition which runs the commit/PR through the OSS-Fuzz fuzzers for a brief time to at verify that it doesn’t at least trigger a problem already then. For now we have that time limit set to 10 minutes.
A lot of Marc Hörsken’s Windows builds have been moved over from his more or less custom buildbot setup over to Azure Pipelines.
--next has the short option alternative -:. (Right, that’s dash colon as the short version!)
Working with multiple URLs
You can tell curl to send a string as a POST to a URL. And you can easily tell it to send that same data to three different URLs. Like this:
curl -d data URL1 URL2 URL2
… and you can easily ask curl to issue a HEAD request to two separate URLs, like this:
curl -I URL1 URL2
… and of course the easy, just GET four different URLs and send them all to stdout:
curl URL1 URL2 URL3 URL4
Doing many at once is beneficial
Of course you could also just invoke curl two, three or four times serially to accomplish the same thing. But if you do, you’d lose curl’s ability to use its DNS cache, its connection cache and TLS resumed sessions – as they’re all cached in memory. And if you wanted to use cookies from one transfer to the next, you’d have to store them on disk since curl can’t magically keep them in memory between separate command line invokes.
Sometimes you want to use several URLs to make curl perform better.
But what if you want to send different data in each of those three POSTs? Or what if you want to do both GET and POST requests in the same command line? --next is here for you!
--next is a separator!
Basically, --next resets the command line parser but lets curl keep all transfer related states and caches. I think it is easiest to explain with a set of examples.
Send a POST followed by a GET:
curl -d data URL1 --next URL2
Send one string to URL1 and another string to URL2, both as POST:
curl -d one URL1 --next -d another URL2
Send a GET, activate cookies and do a HEAD that then sends back matching cookies.
curl -b empty URL1 --next -I URL1
First upload a file with PUT, then download it again
curl -T file URL1 --next URL2
If you’re doing parallel transfers (with -Z), curl will do URLs in parallel only until the --next separator.
There’s no limit
As with most things curl, there’s no limit to the number of URLs you can specify on the command line and there’s no limit to the number of --next separators.
If your command line isn’t long enough to hold them all, write them in a file and point them out to curl with -K, --config.
That’s the primary message that we push and that’s important to remember. You can write a multi-threaded application that does concurrent Internet transfers with libcurl in as many threads as you like and they fly just fine.
But
But there are nuances and details of course and the devil is always in those. The main obstacle that then and again causes problems for users is the curl_global_init() function. But how come?
curl_global_init
Back in the day, libcurl developers realized that when we work with in particular a lot of third party TLS libraries, they feature init functions that need to be called first, before any other function in those libraries are called. And they typically are all marked as not thread-safe, we have to call those functions knowing that no other thread calls them. This was the case for GnuTLS (before version 3.3.0) and it was the case for OpenSSL (until they shipped version 1.1.1) etc.
In order for libcurl to adhere to those restrictions that weren’t our own inventions, we added a function to libcurl called curl_global_init() that then in itself inherited those non-thread safe characteristics. We documented the function as not thread-safe.
Time passed, and as we now had a function that is a global initialization function that is also marked not thread-safe, it was an attractive point to add more and other functionality for the library. Other global initializations that then weren’t thread-safe either – as that wasn’t any point in doing anyway since the entire thing wasn’t thread-safe to begin with.
The problems
Having the global init function not being thread-safe has caused problems to users, mostly in use cases where for example they use libcurl in a plugin-like cases where you can’t know if you’re the only user in the process.
We’ve then mostly been longing for better days and blamed the third party libraries that forced us into this corner.
Third parties shaped up, we didn’t
One day in recent times when we looked at what third party libraries a typical libcurl user uses in a modern system, we see that they’ve all fixed their init functions! OpenSSL and GnuTLS that once were part of the original reasons for this function have fixed their issues. They no longer have thread-unsafe init functions.
But libcurl still does! 🙁
While we were initially pushed into this unfortunate corner because of limitations in third party libraries, we had added our own init functions into that function that aren’t thread-safe and now, even though the third party libraries had done the right thing over time, we found ourselves no longer able to put the blame on others. Now we need to clean up our own backyard!
Fix it!
In libcurl 7.69.0 we’ve started this journey with two distinct changes. The goal is to make the function thread-safe under the condition that libcurl is built with only thread-safe dependencies, and we should make configure etc check if that’s the case.
1: EINTR handling
Since libcurl 7.30.0, we’ve provided a flag in the curl_global_init() function to let libcurl users ask for EINTR to actually abort internal loops. Starting now, that flag has no meaning and this is now default behavior. No need to store this state globally anywhere.
2: Working IPv6
At least in the past, it has been common with systems that are IPv6-capable at build-times but that can’t actually create IPv6 sockets and therefor they can’t actually use IPv6. This was previously checked for, once, in the global init and then IPv6 is disabled for everyone. Without a global state, we’ve been forced to move this check and it is now instead done for every created multi handle. A minuscule performance hit for thread safety.
Left to do until completely thread-safe
The transition isn’t completed. The low hanging fruit has been picked, here are some remaining issues to solve:
When is it thread-safe?
Since curl can be built with a number of different third party libraries, including version old versions, we need to make the configure script know what versions of what libraries that are safe so that it can tell. But how are libcurl application authors supposed to know? Can we figure how a way to tell them?
curl_version*
Both curl_version() and curl_version_info() store information in static buffers and return information pointing to that memory. They’re currently setup in the global init so they work safely from multiple threads today, but we probably need to create new, alternative versions of them, that instead allocate heap memory to return the info in. Or possibly store the info in memory associated with a handle.
Update: Patrick Monnerat made me realize that a possibly even better way to fix them is to make sure they generate the same output in a way that repeated or concurrent invokes are fine.
Reference counter
There’s a counter counting calls to curl_global_init() so that the corresponding number of calls to curl_global_cleanup() is required before things are actually cleaned up.
This is a hard nut to crack without a global context and no mutex locks. I haven’t yet figured out how to solve this. If you have ideas, I’m listening!
When?
There’s no fixed time schedule for when these remaining nits are supposed to be fixed, but I hope to work on them going forward and I will appreciate all the help I can get and if things just progress, I would imagine we can end 2020 with a libcurl with these flaws fixed!
Oh, and we also really need to make sure that we don’t simultaneously come up with or think of new thread unsafe functionality for the init function..