I started working for Mozilla in January 2014. Here’s some reflections from my first time as Mozilla employee.
Working from home
I’ve worked completely from home during some short periods before in my life so I had an idea what it would be like. So far, it has been even better than I had anticipated. It suits me so well it is almost scary! No commutes. No delays due to traffic. No problems ever with over-crowded trains or buses. No time wasted going to work and home again. And I’m around when my kids get home from school and it’s easy to receive deliveries all days. I don’t think I ever want to work elsewhere again… 🙂
Another effect of my work place is also that I probably have become somewhat more active on social networks and IRC. If I don’t use those means, I may spent whole days without talking to any humans.
Also, I’m the only Mozilla developer in Sweden – although we have a few more employees in Sweden. (Update: apparently this is wrong and there’s’ also a Mats here!)

The freedom
I have freedom at work. I control and decide a lot of what I do and I get to do a lot of what I want at work. I can work during the hours I want. As long as I deliver, my employer doesn’t mind. The freedom isn’t just about working hours but I also have a lot of control and saying about what I want to work on and what I think we as a team should work on going further.
The not counting hours
For the last 16 years I’ve been a consultant where my customers almost always have paid for my time. Paid by the hour I spent working for them. For the last 16 years I’ve counted every single hour I’ve worked and made sure to keep detailed logs and tracking of whatever I do so that I can present that to the customer and use that to send invoices. Counting hours has been tightly integrated in my work life for 16 years. No more. I don’t count my work time. I start work in the morning, I stop work in the evening. Unless I work longer, and sometimes I start later. And sometimes I work on the weekend or late at night. And I do meetings after regular “office hours” many times. But I don’t keep track – because I don’t have to and it would serve no purpose!
The big code base
I work with Firefox, in the networking team. Firefox has about 10 million lines C and C++ code alone. Add to that everything else that is other languages, glue logic, build files, tests and lots and lots of JavaScript.
It takes time to get acquainted with such a large and old code base, and lots of the architecture or traces of the original architecture are also designed almost 20 years ago in ways that not many people would still call good or preferable.
Mozilla is using Mercurial as the primary revision control tool, and I started out convinced I should too and really get to learn it. But darn it, it is really too similar to git and yet lots of words are intermixed and used as command but they don’t do the same as for git so it turns out really confusing and yeah, I felt I got handicapped a little bit too often. I’ve switched over to use the git mirror and I’m now a much happier person. A couple of months in, I’ve not once been forced to switch away from using git. Mostly thanks to fancy scripts and helpers from fellow colleagues who did this jump before me and already paved the road.
C++ and code standards
I’m a C guy (note the absence of “++”). I’ve primarily developed in C for the whole of my professional developer life – which is approaching 25 years. Firefox is a C++ fortress. I know my way around most C++ stuff but I’m not “at home” with C++ in any way just yet (I never was) so sometimes it takes me a little time and reading up to get all the C++-ishness correct. Templates, casting, different code styles, subtleties that isn’t in C and more. I’m slowly adapting but some things and habits are hard to “unlearn”…
The publicness and Bugzilla
I love working full time for an open source project. Everything I do during my work days are public knowledge. We work a lot with Bugzilla where all (well except the security sensitive ones) bugs are open and public. My comments, my reviews, my flaws and my patches can all be reviewed, ridiculed or improved by anyone out there who feels like doing it.
Development speed
There are several hundred developers involved in basically the same project and products. The commit frequency and speed in which changes are being crammed into the source repository is mind boggling. Several hundred commits daily. Many hundred and sometimes up to a thousand new bug reports are filed – daily.
yet slowness of moving some bugs forward
Moving a particular bug forward into actually getting it land and included in pending releases can be a lot of work and it can be tedious. It is a large project with lots of legacy, traditions and people with opinions on how things should be done. Getting something to change from an old behavior can take a whole lot of time and massaging and discussions until they can get through. Don’t get me wrong, it is a good thing, it just stands in direct conflict to my previous paragraph about the development speed.
In the public eye
I knew about Mozilla before I started here. I knew Firefox. Just about every person I’ve ever mentioned those two brands to have known about at least Firefox. This is different to what I’m used to. Of course hardly anyone still fully grasp what I’m actually doing on a day to day basis but I’ve long given up on even trying to explain that to family and friends. Unless they really insist.
Vitriol and expectations of high standards
I must say that being in the Mozilla camp when changes are made or announced has given me a less favorable view on the human race. Almost anything or any chance is received by a certain amount of users that are very aggressively against the change. All changes really. “If you’ll do that I’ll be forced to switch to Chrome” is a very common “threat” – as if that would A) work B) be a browser that would care more about such “conservative loonies” (you should consider that my personal term for such people)). I can only assume that the Chrome team also gets a fair share of that sort of threats in the other direction…
Still, it seems a lot of people out there and perhaps especially in the Free Software world seem to hold Mozilla to very high standards. This is both good and bad. This expectation of being very good also comes from people who aren’t even Firefox users – we must remain the bright light in a world that goes darker. In my (biased) view that tends to lead to unfair criticisms. The other browsers can do some of those changes without anyone raising an eyebrow but when Mozilla does similar for Firefox, a shitstorm breaks out. Lots of those people criticizing us for doing change NN already use browser Y that has been doing NN for a good while already…
Or maybe I’m just not seeing these things with clear enough eyes.
How does Mozilla make money?
Yeps. This is by far the most common question I’ve gotten from friends when I mention who I work for. In fact, that’s just about the only question I get from a lot of people… (possibly because after that we get into complicated questions such as what exactly do I do there?)
curl and IETF
I’m grateful that Mozilla allows me to spend part of my work time working on curl.
I’m also happy to now work for a company that allows me to attend to IETF/httpbis and related activities much better than ever I’ve had the opportunity to in the past. Previously I’ve pretty much had to spend spare time and my own money, which has limited my participation a great deal. The support from Mozilla has allowed me to attend to two meetings so far during the year, in London and in NYC and I suspect there will be more chances in the future.
Future
I only just started. I hope to grab on to more and bigger challenges and tasks as I get warmer and more into everything. I want to make a difference. See you in bugzilla.




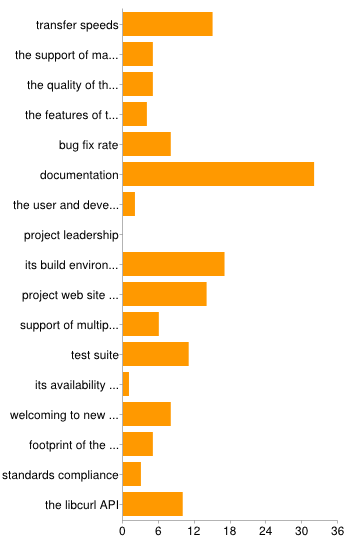

 One of the first bugs that fell into my lap when I started working for
One of the first bugs that fell into my lap when I started working for 