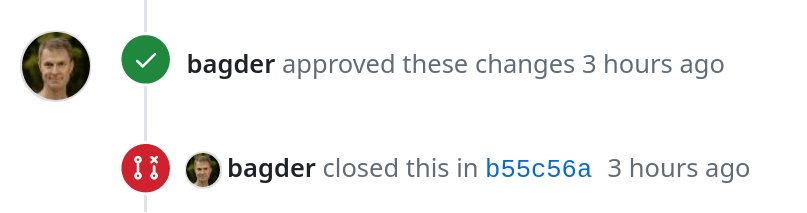
Contributors to the curl project on GitHub tend to notice the above sequence quite quickly: pull requests submitted do not generally appear as “merged” with its accompanying purple blob, instead they are said to be “closed”. This has been happening since 2015 and is probably not going to change anytime soon.

Let me explain why this happens.
I blame GitHub
GitHub’s UI does not allow us to review or comment on commit messages for pull requests. Therefore, it is hard to insist on contributors to provide the correct message, using the proper language in the correct format.
If you make a pull request based on a single commit, the initial PR message is based on the commit message but when follow-up fixes are done and perhaps force-pushed, the PR message is not updated accordingly with the commit message’s updates.
Commit messages with style
I believe having good commit messages following a fixed style and syntax helps the project. It makes the git history better and easier to browse. It allows us to write tools and scripts around git and the git history. Like how we for example generate release notes and project stat graphs based on git log basically.
We also like and use a strictly linear history in curl, meaning that all commits are rebased on the master branch. Lots of the scripting mentioned above depends on this fact.
Manual merges
In order to make sure the commit message is correct, and in fact that the entire commit looks correct, we merge pull requests manually. That means that we pull down the pull request into a local git repository, clean up the commit message to adhere to project standards.
And then we push the commit to git. One or more of the commit messages in such a push then typically contains lines like:
Fixes #[number] and Closes #[number]. Those are instructions to GitHub and we use them like this:
Fixes means that this commit fixed an issue that was reported in the GitHub issue with that id. When we push a commit with that instruction, GitHub closes that issue.
Closes means that we merged a pull request with this id. (GitHub has no way for us to tell it that we merged the pull request.) This instruction makes GitHub closes the corresponding pull request: “[committer] closed this in [commit hash]”.
We do not let GitHub dictate how we do git. We use git and expect GitHub to reflect our git activity.
We COULD but we won’t
We could in theory fix and cleanup the commits locally and manually exactly the way we do now and then force-push them to the remote branch and then use the merge button on the GitHub site and then they would appear as “merged”.
That is however a clunky, annoying and time-consuming extra-step that not only requires that we (always) push code to other people’s branches, it also triggers a whole new round of CI jobs. This, only to get a purple blob instead of a red one. Not worth it.
If GitHub would allow it, I would disable the merge button in the GitHub PR UI for curl since it basically cannot be used correctly in the project.
Squashing all the commits in the PR is also not something we want since in many cases the changes should be kept as more than one commit and they need their own dedicated and correct commit message.
What GitHub could do
GitHub could offer a Merged keyword in the exact same style as Fixed and Closes, that just tells the service that we took care of this PR and merged it as this commit. It’s on me. My responsibility. I merged it. It would help users and contributors to better understand that their closed PR was in fact merged as that commit.
It would also have saved me from having to write this blog post.
Discussion
Addendum
In some post-publish discussions I have seen people ask about credits. This method to merge commits does not break or change how the authors are credited for their work. The commit authors remain the commit authors, and the one doing the commits (which is I when I do them) is stored separately. Like git always do. Doing the pushes manually this way does in no way change this model. GitHub will even count the commits correctly for the committer – assuming they use an email address their GitHub account does (I think).