The title of my ending keynote at FOSDEM February 1, 2026.
As the last talk of the conference, at 17:00 on the Sunday lots of people had already left, and presumably a lot of the remaining people were quite tired and ready to call it a day.
Still, the 1500 seats in Janson got occupied and there was even a group of more people outside wanting to get in that had to be refused entry.
The video recording
Thanks to the awesome FOSDEM video team, the recording was made available this quickly after the presentation.
In January 2025 I received the European Open Source Achievement Award. The physical manifestation of that prize was a trophy made of translucent acrylic (or something similar). The blog post I above has a short video where I show it off.
In the year that passed since, we have established an organization for how do the awards going forward in the European Open Source Academy and we have arranged the creation of actual medals for the awardees.
That was the medal we gave the award winners last week at the award ceremony where I handed Greg his prize.
I was however not prepared for it, but as a direct consequence I was handed a medal this year, in recognition for the award a got last year, because now there is a medal. A retroactive medal if you wish. It felt almost like getting the award again. An honor.
The boxThe backsideFront
The medal design
The medal is made in a shiny metal, roughly 50mm in diameter. In the middle of it is a modern version (with details inspired by PCB looks) of the Yggdrasil tree from old Norse mythology – the “World Tree”. A source of life, a sacred meeting place for gods.
In a circle around the tree are twelve stars, to visualize the EU and European connection.
On the backside, the year and the name are engraved above an EU flag, and the same circle of twelve stars is used there as a margin too, like on the front side.
The medal has a blue and white ribbon, to enable it to be draped over the head and hung from the neck.
The box is sturdy thing in dark blue velvet-like covering with European Open Source Academy printed on it next to the academy’s logo. The same motif is also in the inside of the top part of the box.
Many
I do feel overwhelmed and I acknowledge that I have receive many medals by now. I still want to document them and show them in detail to you, dear reader. To show appreciation; not to boast.
I had the honor and pleasure to hand over this prize to its first real laureate during the award gala on Thursday evening in Brussels, Belgium.
This annual award ceremony is one of the primary missions for the European Open Source Academy, of which I am the president since last year.
As an academy, we hand out awards and recognition to multiple excellent individuals who help make Europe the home of excellent Open Source. Fellow esteemed academy members joined me at this joyful event to perform these delightful duties.
As I stood on the stage, after a brief video about Greg was shown I introduced Greg as this year’s worthy laureate. I have included the said words below. Congratulations again Greg. We are lucky to have you.
Me introducing Greg Kroah-Hartman
There are tens of millions of open source projects in the world, and there are millions of open source maintainers. Many more would count themselves as at least occasional open source developers. These are the quiet builders of Europe’s digital world.
When we work on open source projects, we may spend most of our waking hours deep down in the weeds of code, build systems, discussing solutions, or tearing our hair out because we can’t figure out why something happens the way it does, as we would prefer it didn’t.
Open source projects can work a little like worlds on their own. You live there, you work there, you debate with the other humans who similarly spend their time on that project. You may not notice, think, or even care much about other projects that similarly have a set of dedicated people involved. And that is fine.
Working deep in the trenches this way makes you focus on your world and maybe remain unaware and oblivious to champions in other projects. The heroes who make things work in areas that need to work for our lives to operate as smoothly as they, quite frankly, usually do.
Greg Kroah-Hartman, however, our laureate of the Prize for Excellence in Open Source 2026, is a person whose work does get noticed across projects.
Our recognition of Greg honors his leading work on the Linux kernel and in the Linux community, particularly through his work on the stable branch of Linux. Greg serves as the stable kernel maintainer for Linux, a role of extraordinary importance to the entire computing world. While others push the boundaries of what Linux can do, Greg ensures that what already exists continues to work reliably. He issues weekly updates containing critical bug fixes and security patches, maintaining multiple long-term support versions simultaneously. This is work that directly protects billions of devices worldwide.
It’s impossible to overstate the importance of the work Greg has done on Linux. In software, innovation grabs headlines, but stability saves lives and livelihoods. Every Android phone, every web server, every critical system running Linux depends on Greg’s meticulous work. He ensures that when hospitals, banks, governments, and individuals rely on Linux, it doesn’t fail them. His work represents the highest form of service: unglamorous, relentless, and essential.
Without maintainers like Greg, the digital infrastructure of our world would crumble. He is, quite literally, one of the people keeping the digital infrastructure we all depend on running.
As a fellow open source maintainer, Greg and I have worked together in the open source security context. Through my interactions with him and people who know him, I learned a few things:
Greg is competent. a custodian and maintainer of many parts and subsystems of the Linux kernel tree and its development for decades.
Greg has a voice. He doesn’t bow to pressure or take the easy way out. He has integrity.
Greg is persistent. He has been around and done hard work for the community for decades.
Greg is a leader. He shares knowledge, spreads the word, and talks to crowds. In a way that is heard and appreciated. He is a mentor.
An American by origin, Greg now calls Europe his home, having lived in the Netherlands for many years. While on this side of the pond, he has taken on an important leadership role in safeguarding and advocating for the interests of the open source community. This is most evident through his work on the Cyber Resilience Act, through which he has educated and interacted with countless open source contributors and advocates whose work is affected by this legislation.
We — if I may be so bold — the Open Source community in Europe — and yes, the whole world, in fact — appreciate your work and your excellence. Thank you, Greg. Please come on stage and collect your award.
In addition to the medal, Greg was given this funky-looking award “thing” with the tree symbol of the European Open Source Academy.
Daniel to the left, Greg Kroah-Hartman on the right
The whole event
Here is the entire ceremony, from start to finish.
We are doing another curl + distro online meeting this spring in what now has become an established annual tradition. A two-hour discussion, meeting, workshop for curl developers and curl distro maintainers.
The objective for these meetings is simply to make curl better in distros. To make distros do better curl. To improve curl in all and every way we think we can, together.
A part of this process is to get to see the names and faces of the people involved and to grease the machine to improve cross-distro collaboration on curl related topics.
Anyone who feels this is a subject they care about is welcome to join. We aim for the widest possible definition of distro and we don’t attempt to define the term.
The 2026 version of this meeting is planned to take place in the early evening European time, morning west coast US time. With the hope that it covers a large enough amount of curl interested people.
The plan is to do this on March 26, and all the details, planning and discussion items are kept on the dedicated wiki page for the event.
Please add your own discussion topics that you want to know or talk about, and if you feel inclined, add yourself as an intended participant. Feel free to help make this invite reach the proper people.
We introduced curl’s -J option, also known as --remote-header-name back in February 2010. A decent amount of years ago.
The option is used in combination with -O (--remote-name) when downloading data from a HTTP(S) server and instructs curl to use the filename in the incoming Content-Disposition: header when saving the content, instead of the filename of the URL passed on the command line (if provided). That header would later be explained further in RFC 6266.
The idea is that for some URLs the server can provide a more suitable target filename than what the URL contains from the beginning. Like when you do a command similar to:
curl -O -J https://example.com/download?id=6347d
Without -J, the content would be save in the target output filename called ‘download’ – since curl strips off the query part.
With -J, curl parses the server’s response header that contains a better filename; in the example below fun.jpg.
Content-Disposition: filename="fun.jpg";
But redirects?
The above approach mentioned works pretty well, but has several limitations. One of them being that the obvious that if the site instead of providing a Content-Disposition header perhaps only redirects the client to a new URL to the download from, curl does not pick up the new name but instead keeps using the one from the originally provided URL.
This is not what most users want and not what they expect. As a consequence, we have had this potential improvement mentioned in the TODO file for many years. Until today.
We have now merged a change that makes curl with -J pick up the filename from Location: headers and it uses that filename if no Content-Disposition.
This means that if you now rerun a similar command line as mentioned above, but this one is allowed to follow redirects:
And that site redirects curl to the actual download URL for the tarball you want to download:
HTTP/1 301 redirect
Location: https://example.org/release.tar.gz
… curl now saves the contents of that transfer in a local file called release.tar.gz.
If there is both a redirect and a Content-Disposition header, the latter takes precedence.
The filename is set remotely
Since this gets the filename from the server’s response, you give up control of the name to someone else. This can of course potentially mess things up for you. curl ignores all provided directory names and only uses the filename part.
If you want to save the download in a dedicated directory other than the current one, use –output-dir.
As an additional precaution, using -J implies that curl avoids to clobber, overwrite, any existing files already present using the same filename unless you also use –clobber.
What name did it use?
Since the selected final name used for storing the data is selected based on contents of a header passed from the server, using this option in a scripting scenario introduces the challenge: what filename did curl actually use?
A user can easily extract this information with curl’s -w option. Like this:
This command line outputs the used filename to stdout.
Tweak the command line further to instead direct that name to stderr or to a specific file etc. Whatever you think works.
Remaining restrictions
The content-disposition RFC mentioned above details a way to provide a filename encoded as UTF-8 using something like the below, which includes a U+20AC Euro sign:
curl still does not support this filename* style of providing names. This limitation remains because curl cannot currently convert that provided name into a local filename using the provided characters – with certainty.
Room for future improvement!
Ships
This -J improvement ships in curl 8.19.0, coming in March 2026.
There is no longer a curl bug-bounty program. It officially stops on January 31, 2026.
After having had a few half-baked previous takes, in April 2019 we kicked off the first real curl bug-bounty with the help of Hackerone, and while it stumbled a bit at first it has been quite successful I think.
We attracted skilled researchers who reported plenty of actual vulnerabilities for which we paid fine monetary rewards. We have certainly made curl better as a direct result of this: 87 confirmed vulnerabilities and over 100,000 USD paid as rewards to researchers. I’m quite happy and proud of this accomplishment.
I would like to especially highlight the awesome Internet Bug Bounty project, which has paid the bounties for us for many years. We could not have done this without them. Also of course Hackerone, who has graciously hosted us and been our partner through these years.
Thanks!
How we got here
Looking back, I think we can say that the downfall of the bug-bounty program started slowly in the second half of 2024 but accelerated badly in 2025.
We saw an explosion in AI slop reports combined with a lower quality even in the reports that were not obvious slop – presumably because they too were actually misled by AI but with that fact just hidden better.
Maybe the first five years made it possible for researchers to find and report the low hanging fruit. Previous years we have had a rate of somewhere north of 15% of the submissions ending up confirmed vulnerabilities. Starting 2025, the confirmed-rate plummeted to below 5%. Not even one in twenty was real.
The never-ending slop submissions take a serious mental toll to manage and sometimes also a long time to debunk. Time and energy that is completely wasted while also hampering our will to live.
I have also started to get the feeling that a lot of the security reporters submit reports with a bad faith attitude. These “helpers” try too hard to twist whatever they find into something horribly bad and a critical vulnerability, but they rarely actively contribute to actually improve curl. They can go to extreme efforts to argue and insist on their specific current finding, but not to write a fix or work with the team on improving curl long-term etc. I don’t think we need more of that.
There are these three bad trends combined that makes us take this step: the mind-numbing AI slop, humans doing worse than ever and the apparent will to poke holes rather than to help.
Actions
In an attempt to do something about the sorry state of curl security reports, this is what we do:
We no longer offer any monetary rewards for security reports – no matter which severity. In an attempt to remove the incentives for submitting made up lies.
We stop using Hackerone as the recommended channel to report security problems. To make the change immediately obvious and because without a bug-bounty program we don’t need it.
We continue to immediately ban and publiclyridicule everyone who submits AI slop to the project.
Maintain curl security
We believe that we can maintain and continue to evolve curl security in spite of this change. Maybe even improve thanks to this, as hopefully this step helps prevent more people pouring sand into the machine. Ideally we reduce the amount of wasted time and effort.
I believe the best and our most valued security reporters still will tell us when they find security vulnerabilities.
Instead
If you suspect a security problem in curl going forward, we advise you to head over to GitHub and submit them there.
Alternatively, you send an email with the full report to security @ curl.se.
In both cases, the report is received and handled privately by the curl security team. But with no monetary reward offered.
Leaving Hackerone
Hackerone was good to us and they have graciously allowed us to run our program on their platform for free for many years. We thank them for that service.
As we now drop the rewards, we feel it makes a clear cut and displays a clearer message to everyone involved by also moving away from Hackerone as a platform for vulnerability reporting. It makes the change more visible.
Future disclosures
It is probably going to be harder for us to publicly disclose every incoming security report in the same way we have done it on Hackerone for the last year. We need to work out something to make sure that we can keep doing it at least imperfectly, because I believe in the goodness of such transparency.
We stay on GitHub
Let me emphasize that this change does not impact our presence and mode of operation with the curl repository and its hosting on GitHub. We hear about projects having problems with low-quality AI slop submissions on GitHub as well, in the form of issues and pull-requests, but for curl we have not (yet) seen this – and frankly I don’t think switching to a GitHub alternative saves us from that.
Other projects do better
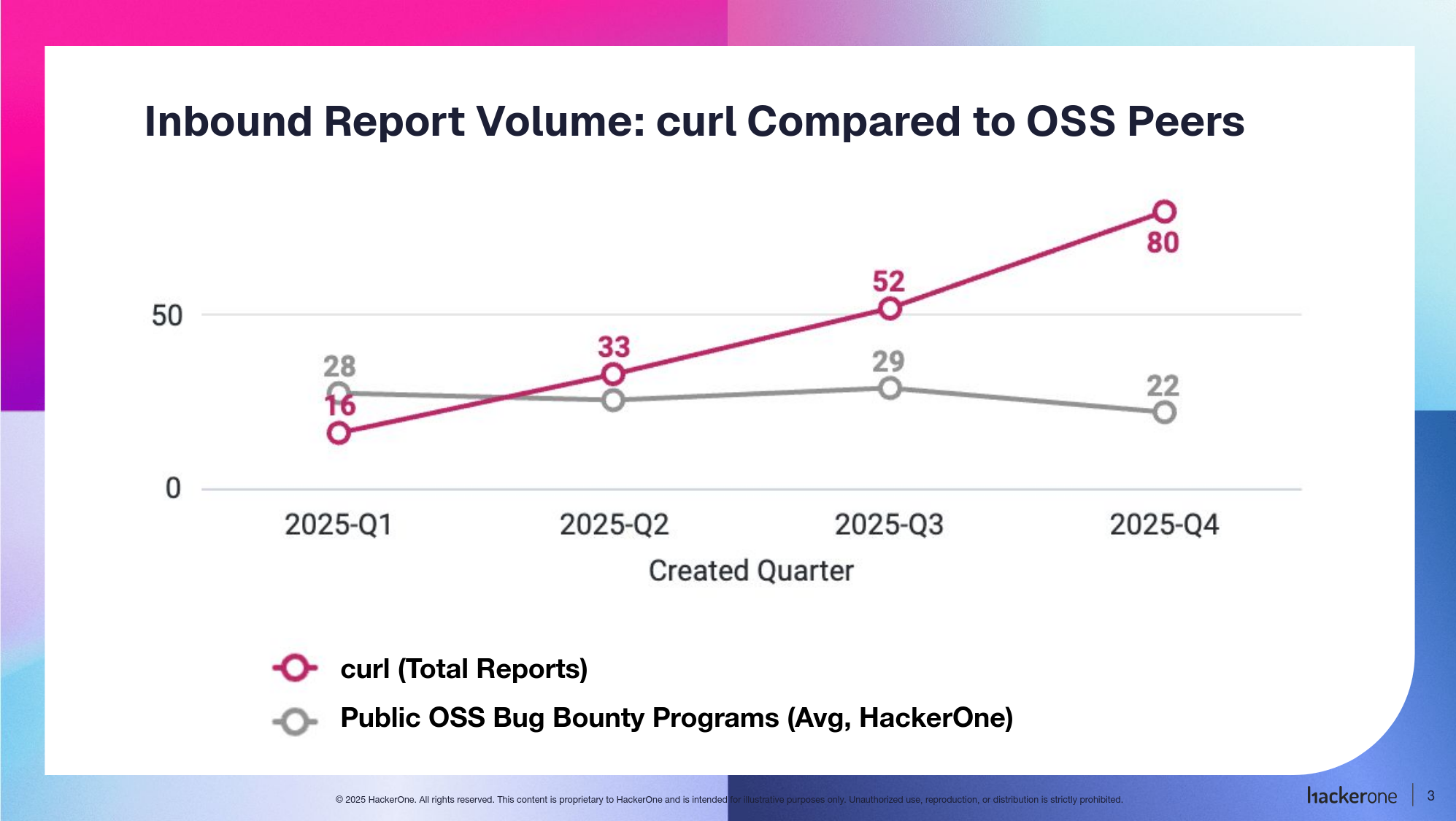
Compared to others, we seem to be affected by the sloppy security reports to a higher degree than the average Open Source project.
With the help of Hackerone, we got numbers of how the curl bug-bounty has compared with other programs over the last year. It turns out curl’s program has seen more volume and noise than other public open source bug bounty programs in the same cohort. Over the past four quarters, curl’s inbound report volume has risen sharply, while other bounty-paying open source programs in the cohort, such as Ruby, Node, and Rails, have not seen a meaningful increase and have remained mostly flat or declined slightly. In the chart, the pink line represents curl’s report volume, and the gray line reflects the broader cohort.
Inbound Report Volume on Hackerone: curl compared to OSS peers
We suspect the idea of getting money for it is a big part of the explanation. It brings in real reports, but makes it too easy to be annoying with little to no penalty to the user. The reputation system and available program settings were not sufficient for us to prevent sand from getting into the machine.
The exact reason why we suffer more of this abuse than others remains a subject for further speculation and research.
If the volume keeps up
There is a non-zero risk that our guesses are wrong and that the volume and security report frequency will keep up even after these changes go into effect.
If that happens, we will deal with it then and take further appropriate steps. I prefer not to overdo things or overplan already now for something that ideally does not happen.
We won’t charge
People keep suggesting that one way to deal with the report tsunami is to charge security researchers a small amount of money for the privilege of submitting a vulnerability report to us. A curl reporters security club with an entrance fee.
I think that is a less good solution than just dropping the bounty. Some of the reasons include:
Charging people money in an International context is complicated and a maintenance burden.
Dealing with charge-backs, returns and other complaints and friction add work.
It would limit who could or would submit issues. Even some who actually find legitimate issues.
Maybe we need to do this later anyway, but we stay away from it for now.
Pull requests are less of a problem
We have seen other projects and repositories see similar AI-induced problems for pull requests, but this has not been a problem for the curl project. I believe that for PRs we have much better means to sort out the weed with automatic means, since we have tools, tests and scanners to verify such contributions. We don’t need to waste any human time on pull requests until the quality is good enough to get green check-marks from 200 CI jobs.
We never say never. This is now and we might have reasons to reconsider and make a different decision in the future. If we do, we will let you know. These changes are applied now with the hope that they will have a positive effect for the project and its maintainers. If that turns out to not be the outcome, we will of course continue and apply further changes later.
Media
Since I created the pull request for updating the bug-bounty information for curl on January 14, almost two weeks before we merged it, various media picked up the news and published articles. Long before I posted this blog post.
One of the trickier things in software is gradual degradation. Development that happens in the wrong direction slowly over time which never triggers any alarms or upset users. Then one day you suddenly take a closer look at it and you realize that this area that used to be so fine several years ago no longer is.
Memory use is one of those things. It is easy to gradually add more and larger allocations over time as we add features and make new cool architectural designs.
Memory use
curl and libcurl literally run in billions of installations and it is important for us that we keep memory use and allocation count to a minimum. It needs to run on small machines and it needs to be able to scale to large number of parallel connections without draining available resources.
So yes, even in 2026 it is important to keep allocations small and as few as possible.
A line in the sand
In July 2025 we added a test case to curl’s test suite (3214) that simply checks the sizes of fifteen important structs. Each struct has a fixed upper limit which they may not surpass without causing the test to fail.
Of course we can adjust the limits when we need to, as it might be entirely okay to grow them when the features and functionalities motivate that, but this check makes sure that we do not mistakenly grow the sizes simply because of a mistake or bad planning.
Do we degrade?
It’s of course a question of a balance. How much memory is a feature and added performance worth? Every libcurl user probably has their own answers to that but I decided to take a look at how we do today, and compare with data I blogged five years ago.
The point in time I decided to compare with here, curl 7.75.0, is fun to use because it was a point in time where I had given the size use in curl some focused effort and minimization work. libcurl memory use was then made smaller and more optimized than it had been for almost a decade before that.
struct sizes
The struct sizes always vary depending on which features that are enabled, but in my tests here they are “maximized”, with as many features and backends enabled as possible.
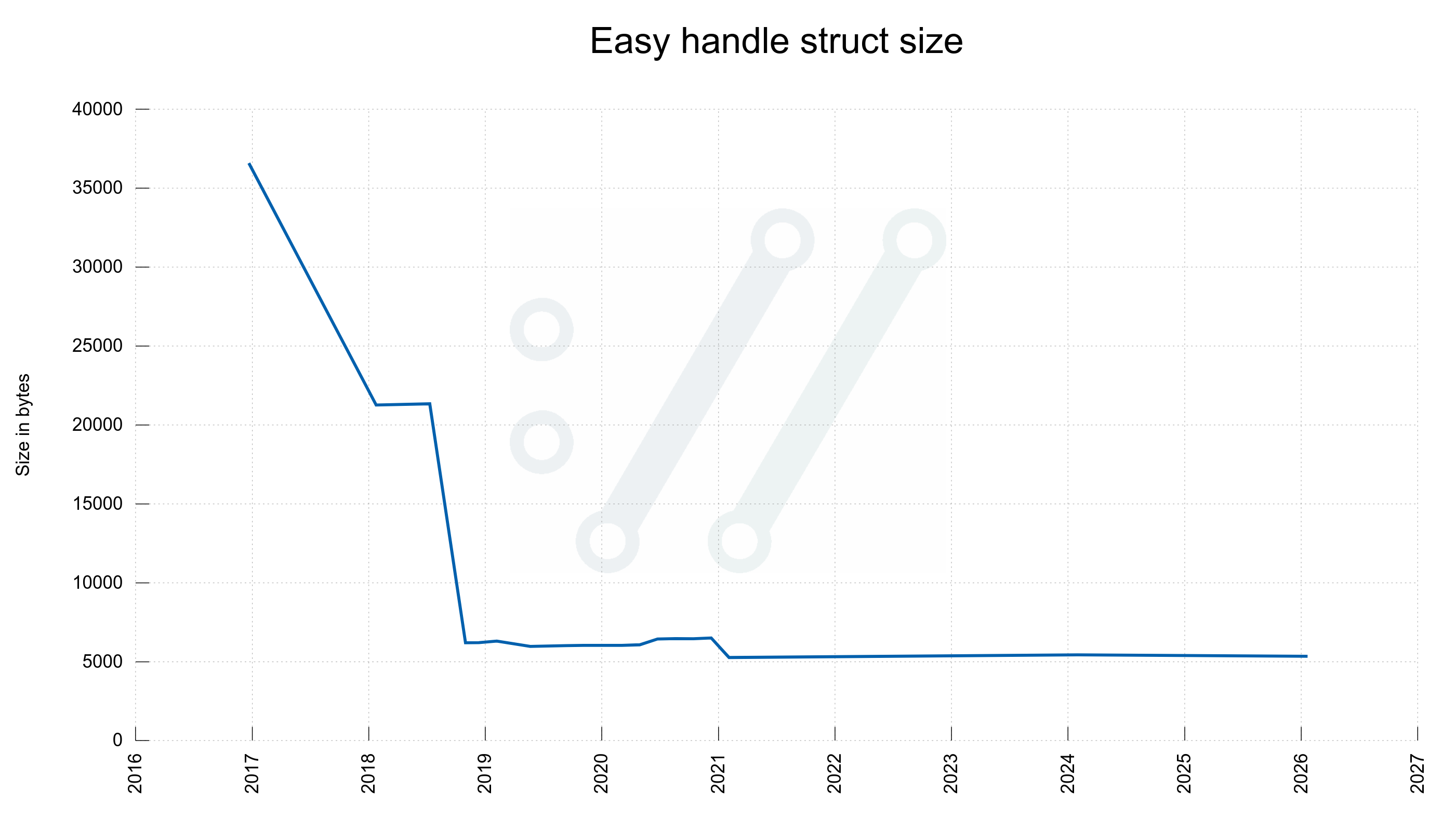
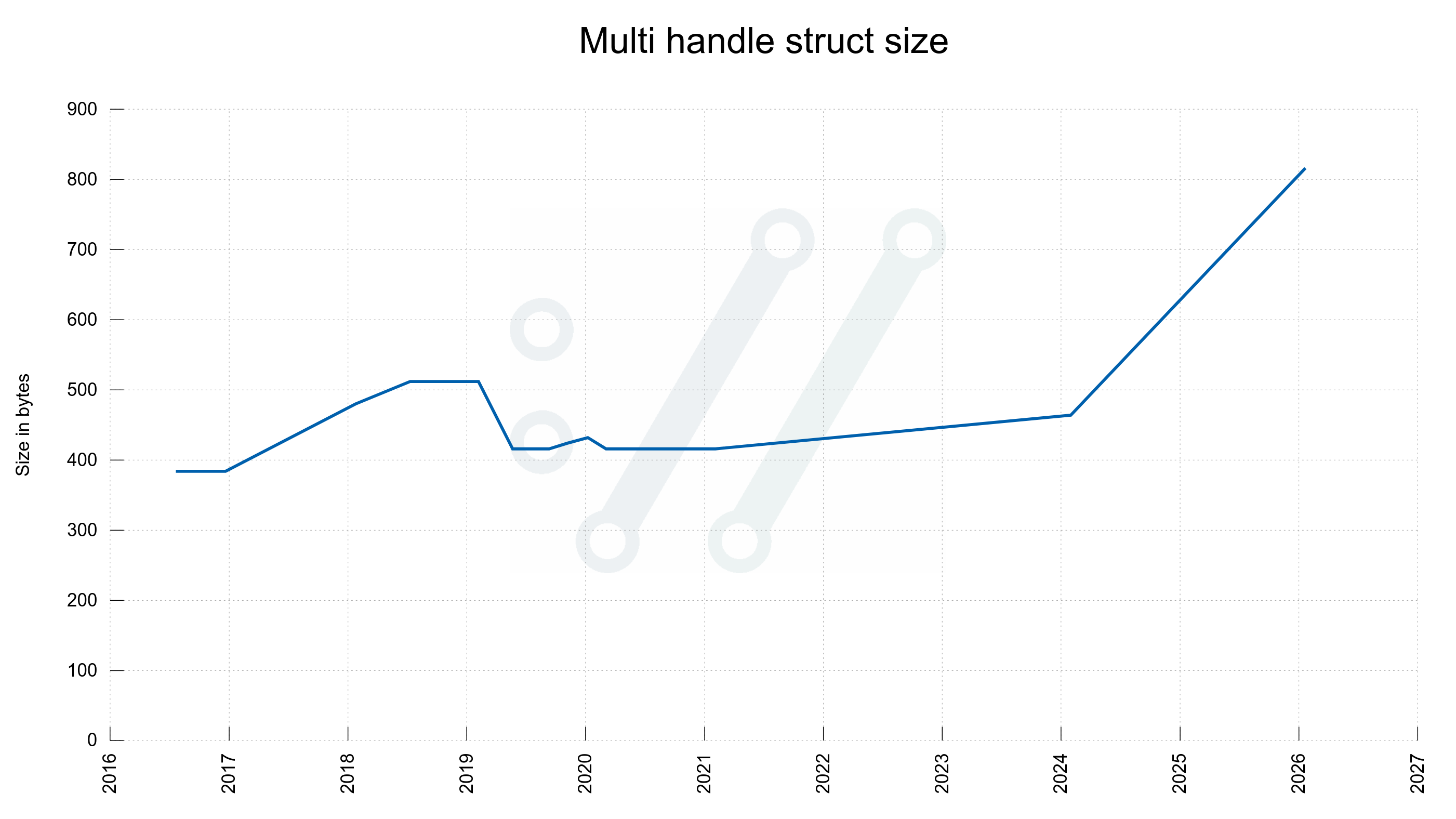
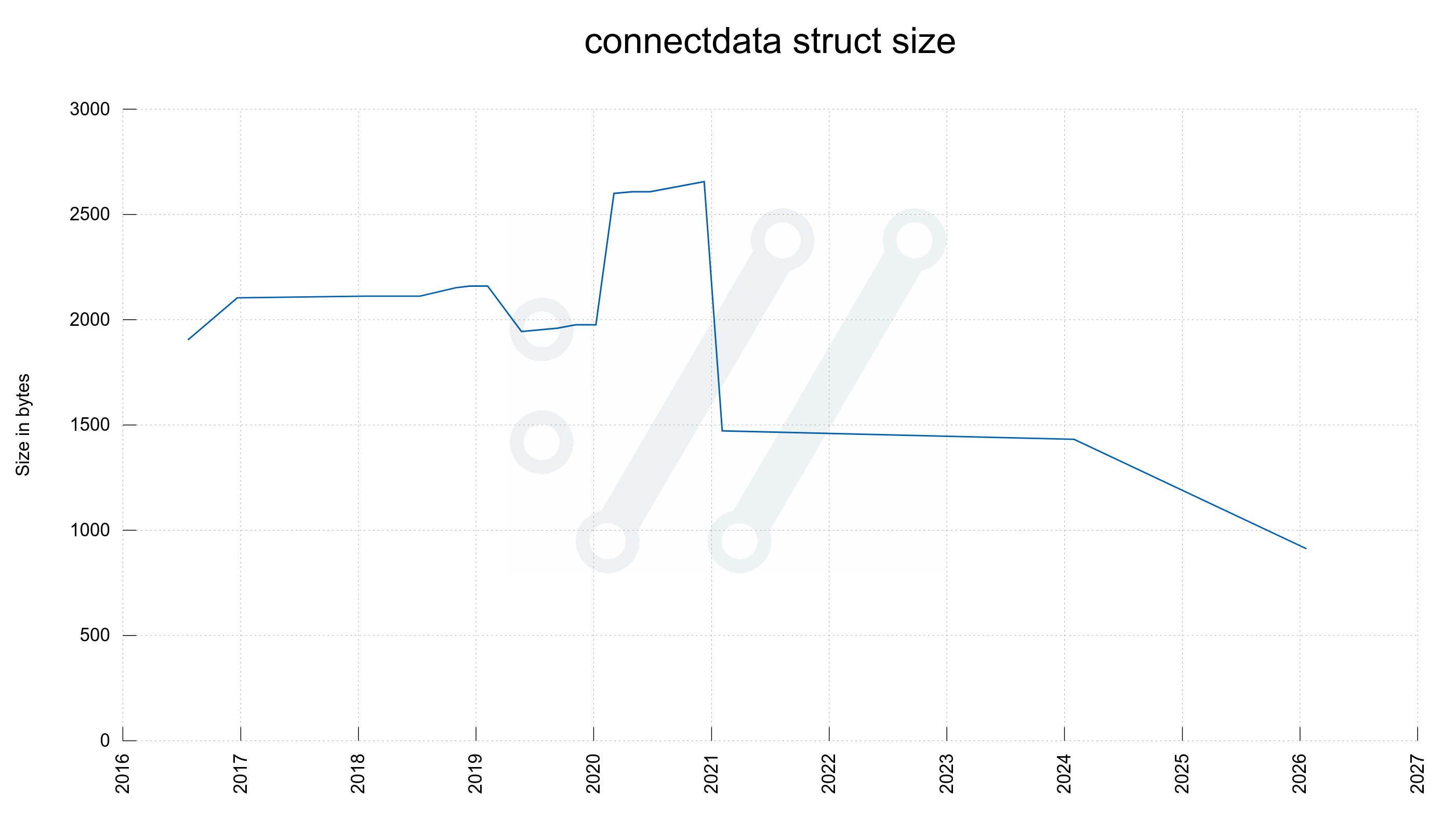
Let’s take a look at three important structs. The multi handle, the easy handle and the connectdata struct. Now compared to then, five years ago.
8.19.0-DEV (now)
7.75.0 (past)
multi
816
416
easy
5352
5272
connectdata
912
1472
As seen in the table, two of the structs have grown and one has shrunken. Let’s see what impact that might have.
If we assume a libcurl-using application doing 10 parallel transfers that have 20 concurrent connections open, libcurl five ago needed:
1472 x 20 + 5272 x 10 + 416 = 82,576 bytes for that
While libcurl in current git needs:
912 x 20 + 5352 x 10 + 816 = 72,576 bytes.
Incidentally that is exactly 10,000 bytes less, five years and many new features later.
This said, part of the reason the structs change is that we move data between them and to other structs. The few mentioned here are not the whole picture.
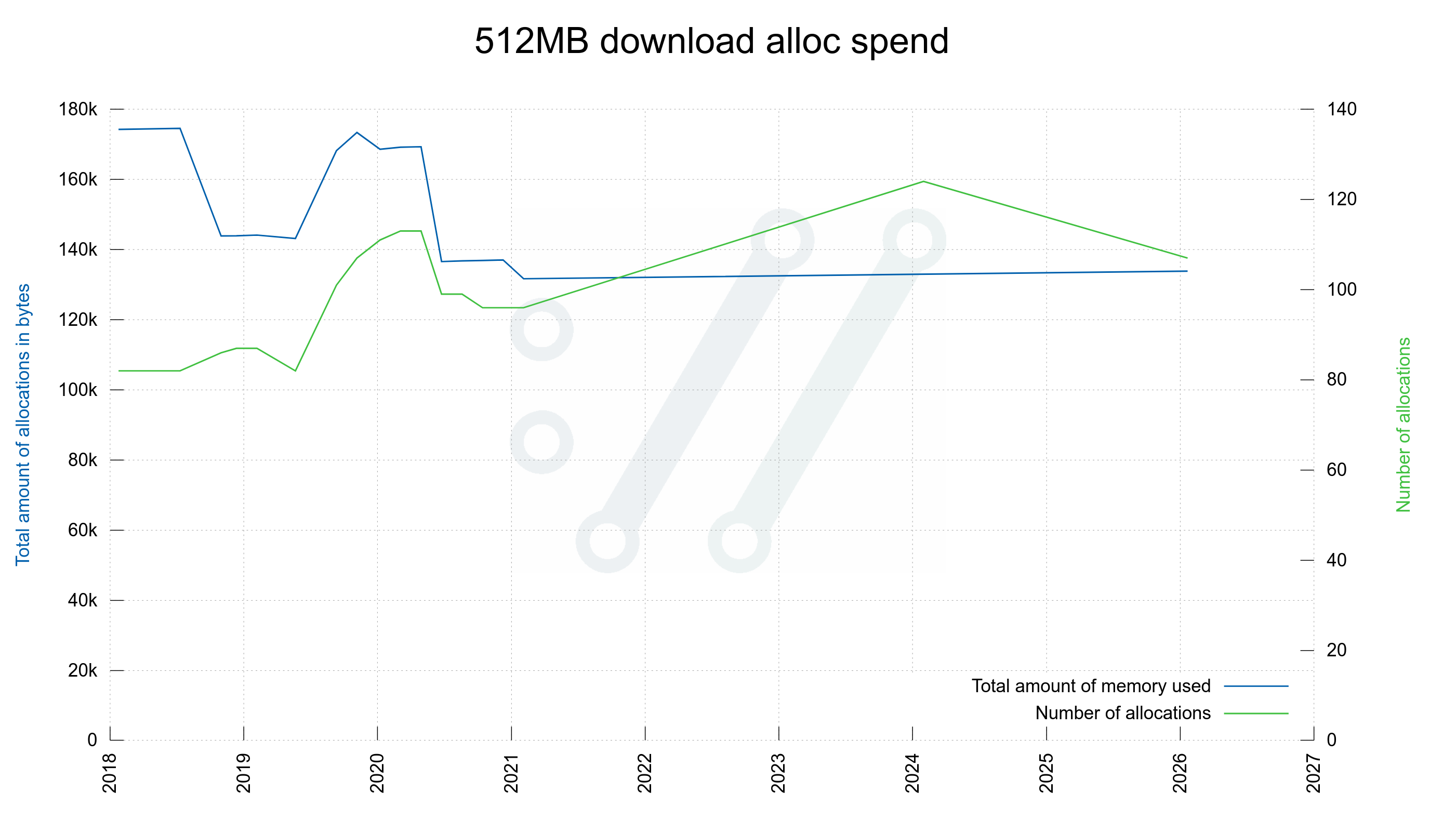
Downloading a single HTTP 512MB file
curl http://localhost/512M --out-null
Using a bleeding edge curl build, this command line on my 64 bit Linux Debian host does 107 allocations, that needs at its maximum 133,856 bytes.
Compared to five years ago, where it needed 131,680 bytes done in a mere 96 allocations.
curl now needs 1.6% more memory for this, done with 11% more allocation calls.
I believe the current amounts are still okay considering we have refactored, developed and evolved the library significantly over the same period.
As a comparison, downloading the same file twenty times in parallel over HTTP/1 using the same curl build needs 2,222 allocations but only a total of 308,613 bytes allocated at peak. Twenty times the number of allocations but only three times the maximum size, compared to the single file download.
Caveat: this measures clear text HTTP downloads. Almost everything transferred these days is using TLS and if you add TLS to this transfer, curl itself does only a few additional allocations but more importantly the TLS library involved allocates much more memory and do many more allocations. I just consider those allocations to be someone else’s optimization work.
Visualized
I generated a few graphs that illustrate memory use changes in curl over time based on what I described above.
The “easy handle” is the handle an application creates and that is associated which each individual transfer done with libcurl.
curl easy handle size changes over time
The “multi handle” is a handle that holds one or more easy handles. An application has at least one of these and adds many easy handles to it, or the easy handles has one of its own internally.
curl multi handle size changes over time
The “connectdata” is an internal struct for each existing connection libcurl knows about. A normal application that makes multiple transfers, either serially or in parallel tends to make the easy handle hold at least a few of these since libcurl uses a connection pool by default to use for subsequent transfers.
curl connectdata struct size over time
Here is data from the internal tracking of memory allocations done when the curl tool is invoked to download a 512 megabyte file from a locally hosted HTTP server. (Generally speaking though, downloading a larger size does not use more memory.)
curl downloading a 512MB file needs this much memory and allocations
Conclusion
I think we are doing alright and none of these struct sizes or memory use have gone bad. We offer more features and better performance than ever, but keep memory spend at a minimum.
When curl 8.19.0 ships in the beginning of March 2026, we have also added MQTTS; meaning MQTT done securely over TLS.
This bumps the number of supported transfer protocols to 29 not too long after the project turned 29 years old.
The 29 transfer protocols (or schemes) that curl supports in January 2026
libcurl backends as of now
What’s MQTT?
Wikipedia describes it as a lightweight, publish–subscribe, machine-to-machine network protocol for message queue/message queuing service. It is designed for connections with remote locations that have devices with resource constraints or limited network bandwidth, such as in the Internet of things (IoT). It must run over a transport protocol that provides ordered, lossless, bi-directional connections—typically, TCP/IP.
Coming protocol support reduction
If things go as planned, the number of supported protocols will decrease soon as we have RTMP scheduled for removal later in the spring of 2026.
The first kept curl git commit is dated December 29, 1999. That is the date of our source code import into SourceForge as I quite annoyingly decided to not keep the prior history. The three years of development and the commits that happened before that import date are therefore not included in this count.
These 20,000 commits have been done on 5,589 separate days, meaning 59% of all days since December 1999. It also means I have done an average of 2.1 commits per day since then.
The curl commits done before 2010 were not actually made with git, but with CVS. The curl source repository was converted to git when we switched hosting over to GitHub.
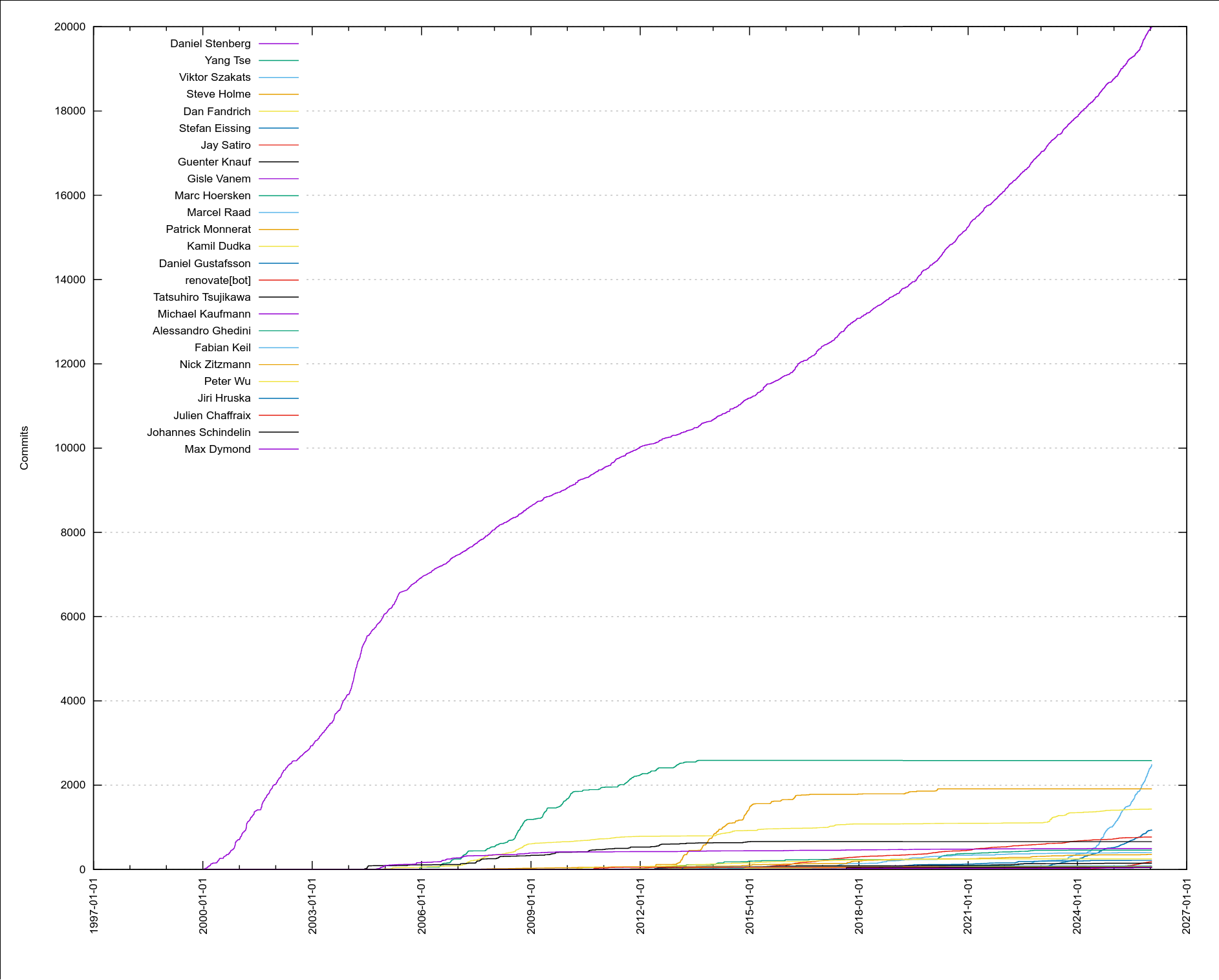
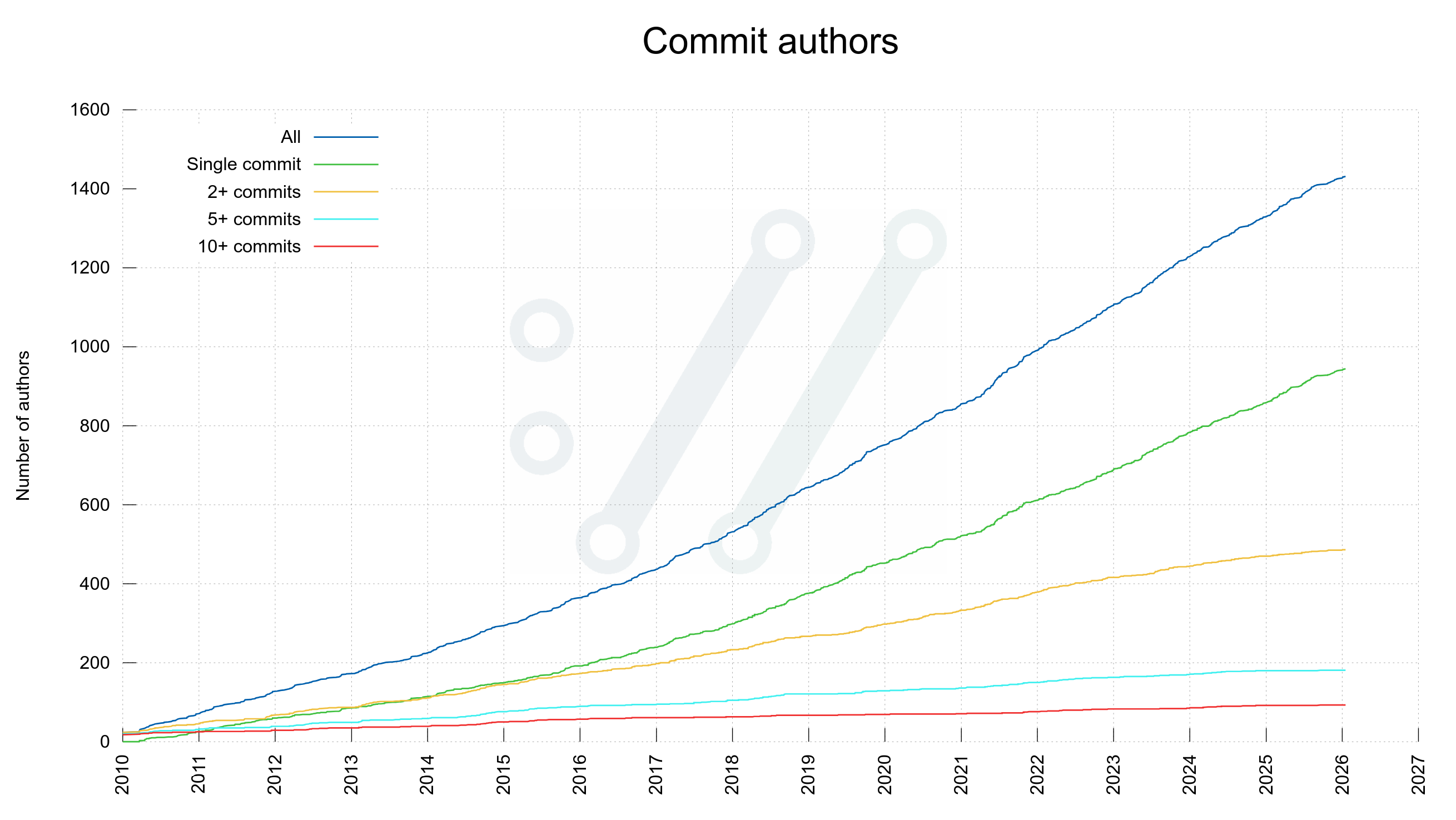
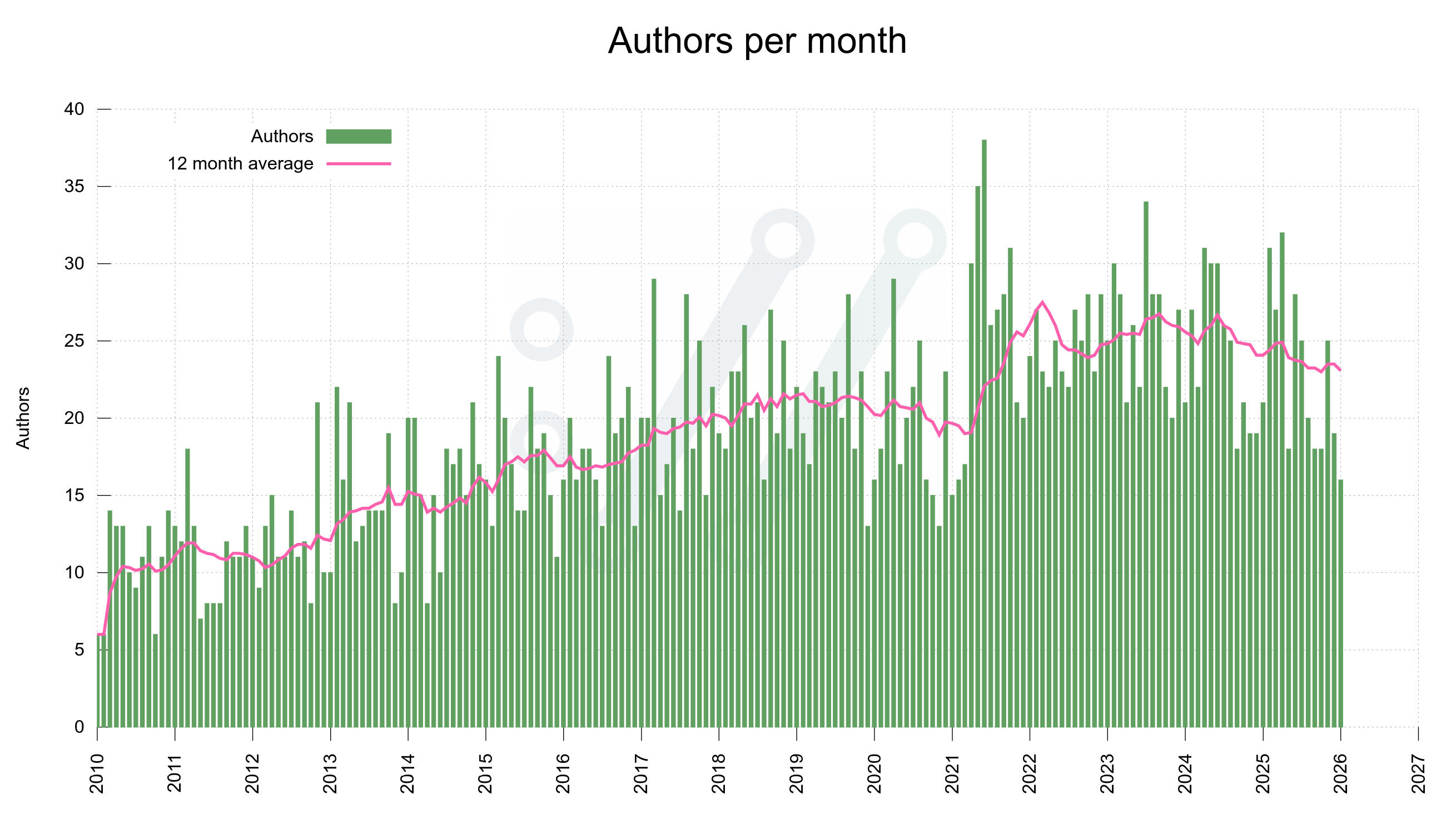
As of today, 1,431 separate individuals have authored commits merged into the curl source repository. 16 of us have made more than 100 commits. Five authors have written more than 1,000 commits. 941 of the authors only wrote a single commit (so far)!
The second-most curl committer by number of commits (Yang Tse) has almost 2,600 commits but he stopped being active already back in 2013.
My fellow top committers
The top-20 all time curl commit authors as of now:
Daniel Stenberg (20000 commits)
Yang Tse (2587 commits)
Viktor Szakats (2496 commits)
Steve Holme (1916 commits)
Dan Fandrich (1435 commits)
Stefan Eissing (941 commits)
Jay Satiro (773 commits)
Guenter Knauf (662 commits)
Gisle Vanem (498 commits)
Marc Hoersken (461 commits)
Marcel Raad (405 commits)
Patrick Monnerat (362 commits)
Kamil Dudka (255 commits)
Daniel Gustafsson (217 commits)
renovate[bot] (183 commits)
Tatsuhiro Tsujikawa (150 commits)
Michael Kaufmann (84 commits)
Alessandro Ghedini (83 commits)
Fabian Keil (77 commits)
Nick Zitzmann (70 commits)
Graphs
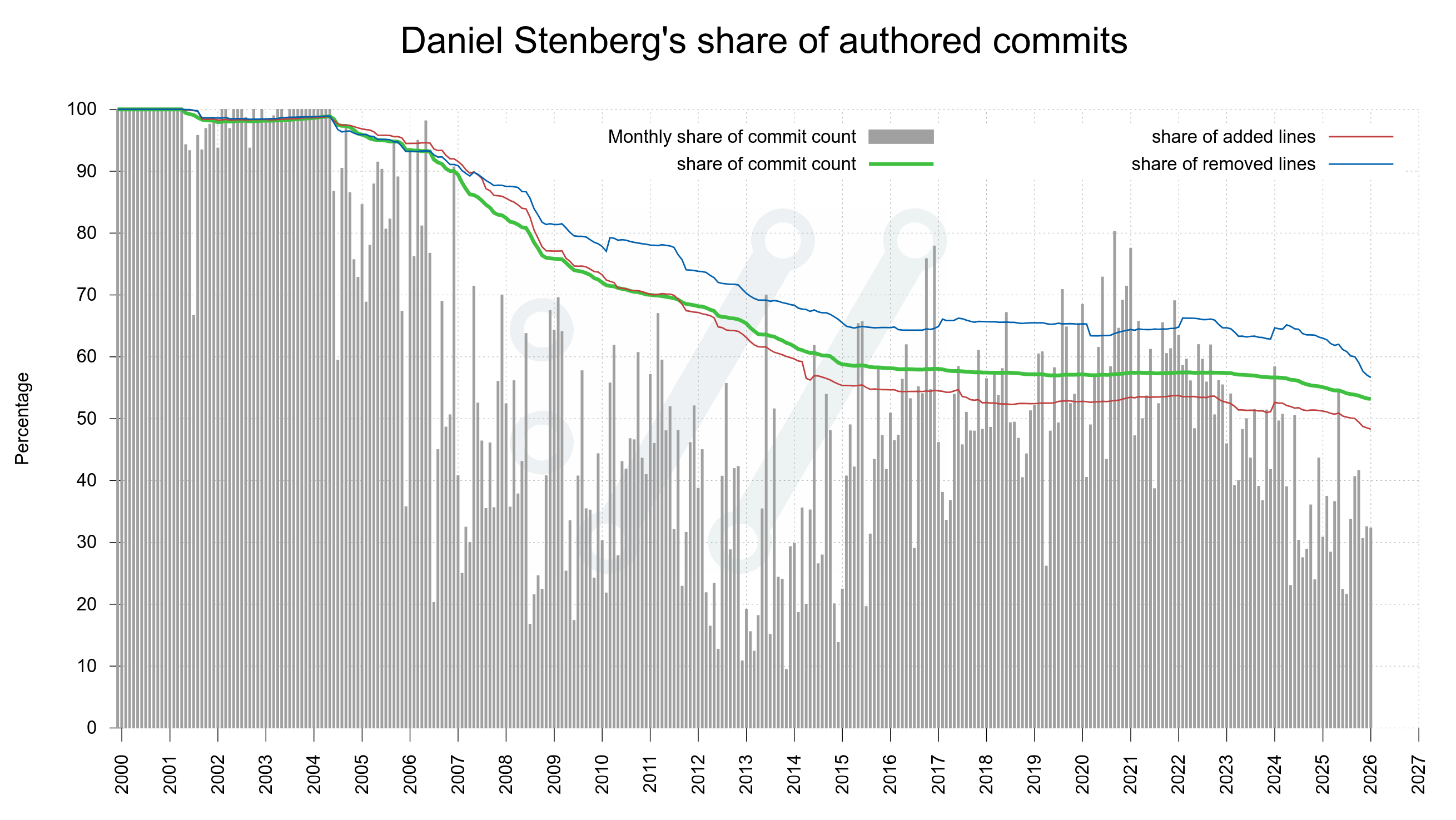
My share of the total amount of commits has been shrinking gradually since a long time and that is a good thing. It means we have awesome contributors and maintainers helping out. Not too far into the future I expect my share to go below 50%.
the number of commits done by the top-20 commit authors in curl over time
Number of commit authors in curl over time
Number of unique authors per month over time
Daniel’s share of authored commits over time
Future
These are my first 20,000 commits.
I have no plans to go anywhere. I have averaged at about 800 commits per year in the curl source code repository for the last 25 years. That would imply reaching 30,000 would take another 12.5 years, so about by mid 2038 or so. If I manage to keep up that speed. Feels distant.
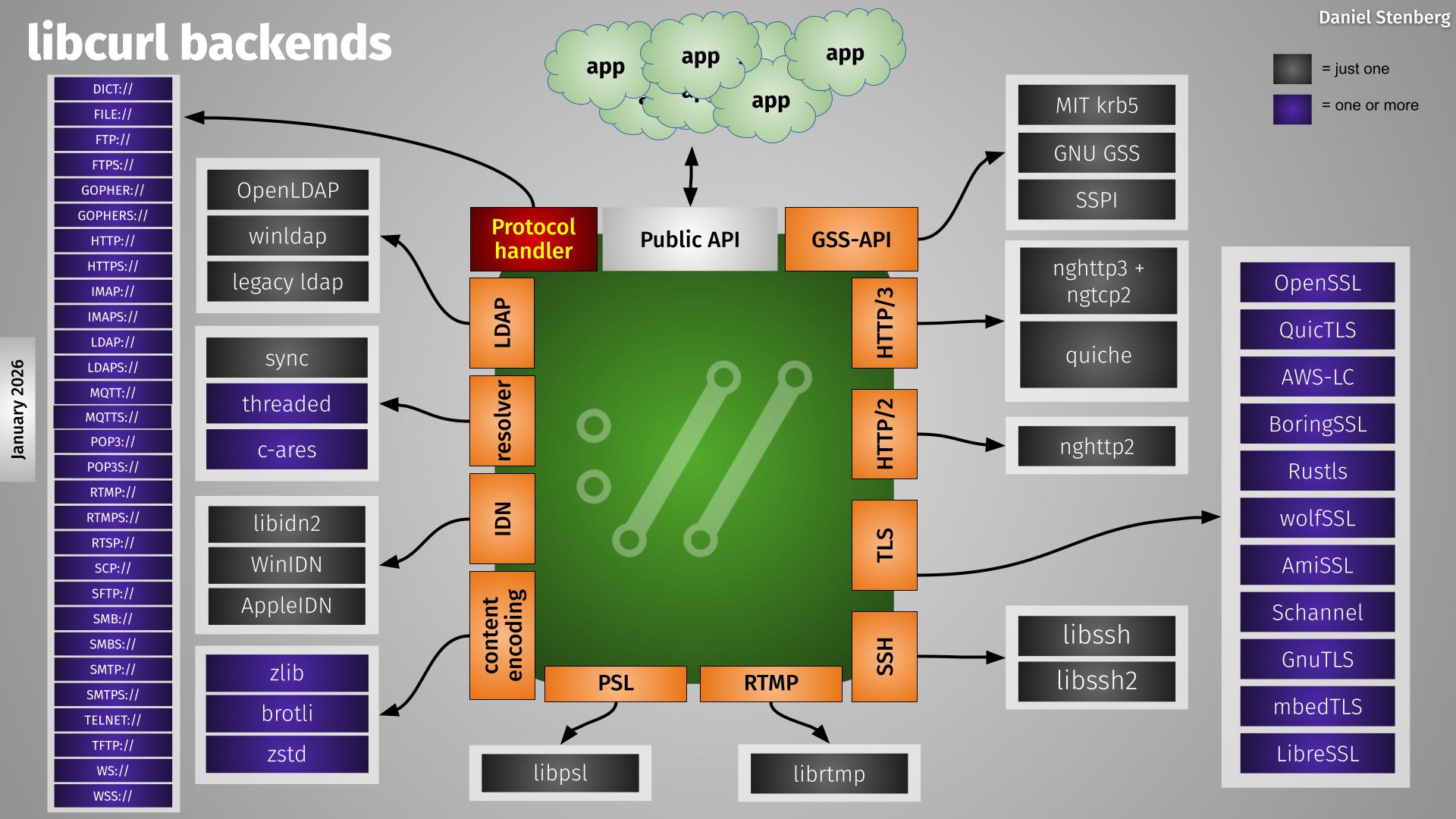
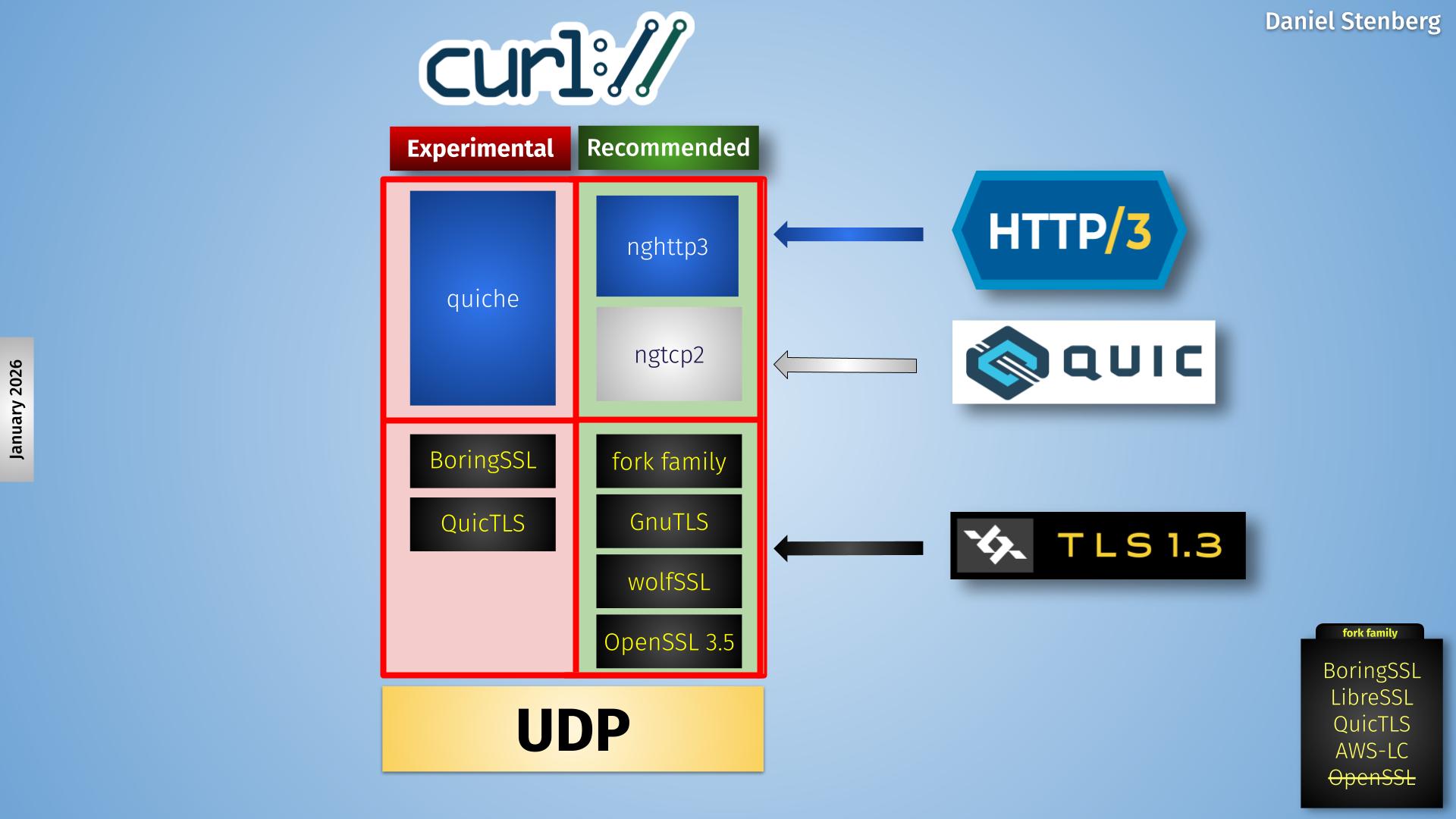
In the curl project we have a long tradition of offering multiple optional backends for specific protocols. In this spirit we have added experimental support for a number of different HTTP/3 + QUIC backends over time. A while ago we dropped one of those experiments, the msh3 backend.
Today we cleanup even more and remove support for yet another backend: the OpenSSL-QUIC stack and we are now down to only supporting two different HTTP/3 alternatives: the ngtcp2 + nghttp3 combo or quiche. And out of those two, the quiche backend is still considered experimental.
The first release shipping with this change will be curl 8.19.0.
OpenSSL-QUIC
This is the QUIC stack implemented and provided by OpenSSL. To make matters a little complicated, this is a separate thing from the QUIC API that OpenSSL also offers. The first one is a full QUIC implementation, the second one is an API that is powerful enough to allow a separate QUIC implementation use OpenSSL for its cryptographic and TLS needs.
A quick recap how history unfolded
2019 – BoringSSL introduced an API for QUIC. QUIC implementations picked it up and it worked. A pull request was made for OpenSSL to allow them to provide the same API so that QUIC stacks all over could use OpenSSL.
2021 – OpenSSL eventually denied merging the pull-request and announced they would instead implement their own QUIC stack – that nobody had asked for.
2023 – OpenSSL 3.2 shipped with support for their own QUIC stack. It was broken in many ways.
2025: OpenSSL version 3.4.1 was released and now the QUIC stack worked decently. In OpenSSL 3.5.0 they announced a QUIC API that now finally allowed independent QUIC stacks to use OpenSSL.
Experimental
Skilled contributors added support for OpenSSL-QUIC to curl primarily to allow people using OpenSSL to still be able to use HTTP/3.
OpenSSL’s own QUIC implementation only reached experimental state in curl meaning that we explicitly and strongly discourage users from using it in production and reserve ourselves the right to change functionality and more between versions.
There are three reasons why it did not graduate from experimental and they are also the reasons why we think we are better off without offering support for it:
The API is lacking. We have communicated with the OpenSSL-QUIC team since even before the API first shipped and it still does not offer the knobs and controls we would like to make it a competitive QUIC alternative. We don’t feel they care much.
The performance is bad. And by bad I mean really bad. The leading QUIC implementation alternative ngtcp2 transfers data much faster in all benchmarks and comparisons. Sometimes up to a factor three difference.
The memory use is abysmal. The amount of more memory required to do transfers with OpenSSL-QUIC compared to ngtcp2 can reach a factortwenty.
A drawing
This makes the curl backend situation simpler in the HTTP/3 and QUIC department as the image below tries to show.















{kind=link}