As tradition dictates, I have spent many hours walking through the responses to the curl user survey of the year. I have sorted tables, rendered updated graphs and tried to wrap my head around what all these numbers might mean and what conclusions and lessons we should draw.
I present the results, the collected answers, to the survey mostly raw without a lot of analysis or decisions. This, to allow everyone who takes the time to reads through to form their own opinion and thoughts. It also gives me more time to glance over the numbers many more times before I make up my mind about possible outcomes.
Screenshot from a recent pull request merged in the curl project on GitHub
Contributors to the curl project on GitHub tend to notice the above sequence quite quickly: pull requests submitted do not generally appear as “merged” with its accompanying purple blob, instead they are said to be “closed”. This has been happening since 2015 and is probably not going to change anytime soon.
Screenshot showing how GitHub otherwise shows merges
If you make a pull request based on a single commit, the initial PR message is based on the commit message but when follow-up fixes are done and perhaps force-pushed, the PR message is not updated accordingly with the commit message’s updates.
Commit messages with style
I believe having good commit messages following a fixed style and syntax helps the project. It makes the git history better and easier to browse. It allows us to write tools and scripts around git and the git history. Like how we for example generate release notes and project stat graphs based on git log basically.
We also like and use a strictly linear history in curl, meaning that all commits are rebased on the master branch. Lots of the scripting mentioned above depends on this fact.
Manual merges
In order to make sure the commit message is correct, and in fact that the entire commit looks correct, we merge pull requests manually. That means that we pull down the pull request into a local git repository, clean up the commit message to adhere to project standards.
And then we push the commit to git. One or more of the commit messages in such a push then typically contains lines like:
Fixes #[number] and Closes #[number]. Those are instructions to GitHub and we use them like this:
Fixes means that this commit fixed an issue that was reported in the GitHub issue with that id. When we push a commit with that instruction, GitHub closes that issue.
Closes means that we merged a pull request with this id. (GitHub has no way for us to tell it that we merged the pull request.) This instruction makes GitHub closes the corresponding pull request: “[committer] closed this in [commit hash]”.
We do not let GitHub dictate how we do git. We use git and expect GitHub to reflect our git activity.
We COULD but we won’t
We could in theory fix and cleanup the commits locally and manually exactly the way we do now and then force-push them to the remote branch and then use the merge button on the GitHub site and then they would appear as “merged”.
That is however a clunky, annoying and time-consuming extra-step that not only requires that we (always) push code to other people’s branches, it also triggers a whole new round of CI jobs. This, only to get a purple blob instead of a red one. Not worth it.
If GitHub would allow it, I would disable the merge button in the GitHub PR UI for curl since it basically cannot be used correctly in the project.
Squashing all the commits in the PR is also not something we want since in many cases the changes should be kept as more than one commit and they need their own dedicated and correct commit message.
What GitHub could do
GitHub could offer a Merged keyword in the exact same style as Fixed and Closes, that just tells the service that we took care of this PR and merged it as this commit. It’s on me. My responsibility. I merged it. It would help users and contributors to better understand that their closed PR was in fact merged as that commit.
It would also have saved me from having to write this blog post.
In some post-publish discussions I have seen people ask about credits. This method to merge commits does not break or change how the authors are credited for their work. The commit authors remain the commit authors, and the one doing the commits (which is I when I do them) is stored separately. Like git always do. Doing the pushes manually this way does in no way change this model. GitHub will even count the commits correctly for the committer – assuming they use an email address their GitHub account does (I think).
Time for another checkup. Where are we right now with HTTP/3 support in curl for users?
I think curl’s situation is symptomatic for a lot of other HTTP tools and libraries. HTTP/3 has been and continues to be a much tougher deployment journey than HTTP/2 was.
curl supports four alternative HTTP/3 solutions
You can enable HTTP/3 for curl using one of these four different approaches. We provide multiple different ones to let “the market” decide and to allow different solutions to “compete” with each other so that users eventually can get the best one. The one they prefer. That saves us from the hard problem of trying to pick a winner early in the race.
More details about the four different approaches follow below.
Why is curl not using HTTP/3 already?
It already does if you build it yourself with the right set of third party libraries. Also, the curl for windows binaries provided by the curl project supports HTTP/3.
For Linux and other distributions and operating system packagers, a big challenge remains that the most widely used TLS library (OpenSSL) does not offer the widely accepted QUIC API that most other TLS libraries provide. (Remember that HTTP/3 uses QUIC which uses TLS 1.3 internally.) This lack of API prevents existing QUIC libraries to work with OpenSSL as their TLS solution forcing everyone who want to use a QUIC library to use another TLS library – because curl does not easily allows itself to get built using multiple TLS libraries . Having a separate TLS library for QUIC than for other TLS based protocols is not supported.
Debian tries an experiment to enable HTTP/3 in their shipped version of curl by switching to GnuTLS (and building with ngtcp2 + nghttp3).
HTTP/3 backends
To get curl to speak HTTP/3 there are three different components that need to be provided, apart from the adjustments in the curl code itself:
TLS 1.3 support for QUIC
A QUIC protocol library
An HTTP/3 protocol library
Illustrated
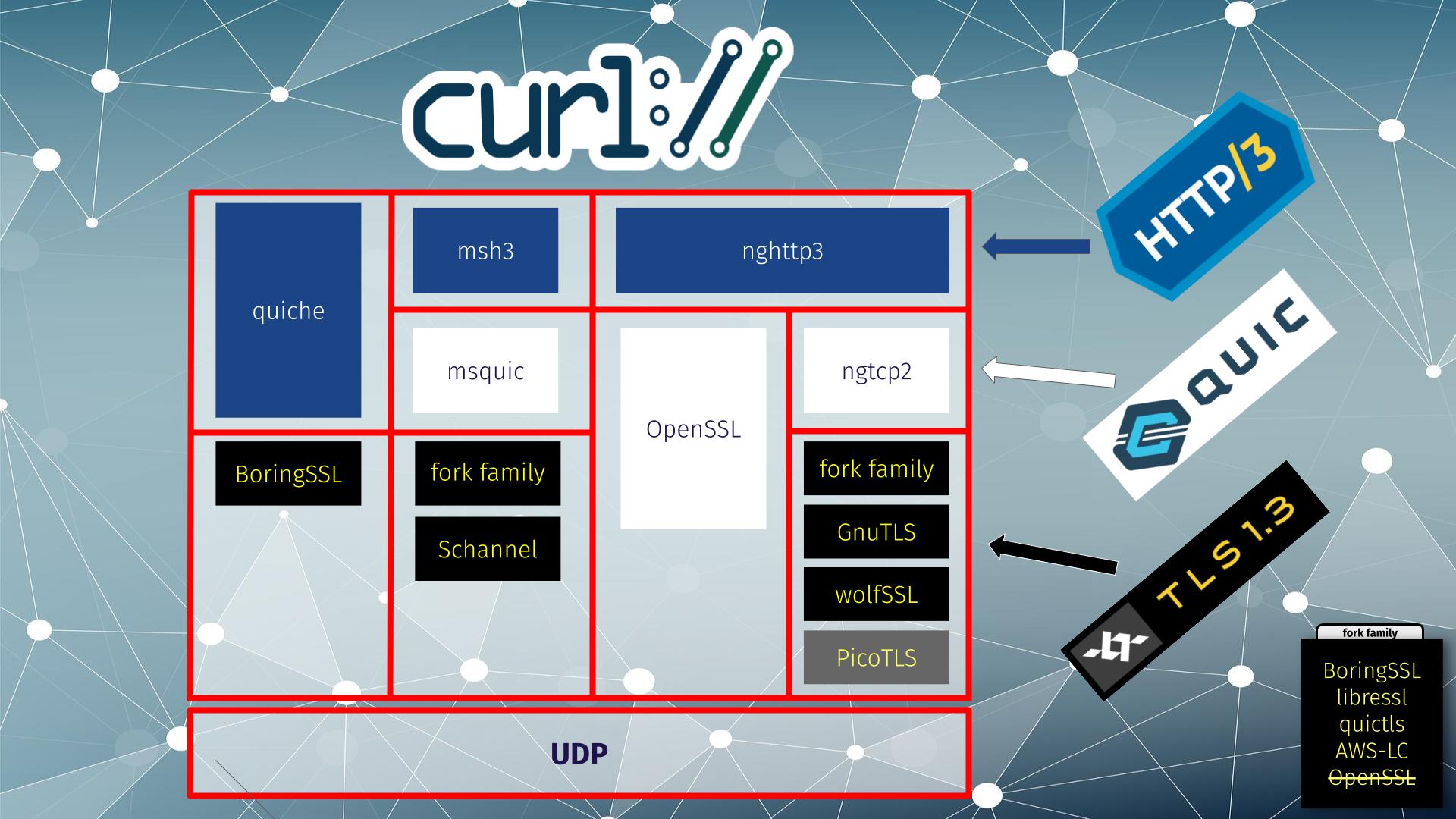
Below, you can see the four different HTTP/3 solutions supported by curl in different columns. All except the right-most solution are considered experimental.
HTTP/3 backend support in curl, June 2024
From left to right:
the quiche library does both QUIC and HTTP/3 and it works with BoringSSL for TLS
msh3 is an HTTP/3 library that uses mquic for QUIC and either a fork family or Schannel for TLS
nghttp3 is an HTTP/3 library that in this setup uses OpenSSL‘s QUIC stack, which does both QUIC and TLS
nghttp3 for HTTP/3 using ngtcp2 for QUIC can use a range of different TLS libraries: fork family, GnuTLS and wolfSSL. (picotls is supported too, but curl itself does not support picotls for other TLS use)
ngtcp2 is ahead
ngtcp2 + nghttp3 was the first QUIC and HTTP/3 combination that shipped non-beta versions that work solidly with curl, and that is the primary reason it is the solution we recommend.
The flexibility in TLS solutions in that vertical is also attractive as this allows users a wide range of different libraries to select from. Unfortunately, OpenSSL has decided to not participate in that game so this setup needs another TLS library.
OpenSSL QUIC
OpenSSL 3.2 introduced a QUIC stack implementation that is not “beta”. As the second solution curl can use. In OpenSSL 3.3 they improved it further. Since early 2024 curl can get built and use this library for HTTP/3 as explained above.
However, the API OpenSSL provide for doing transfers is lacking. It lacks vital functionality that makes it inefficient and basically forces curl to sometimes busy-loop to figure out what to do next. This fact, and perhaps additional problems, make the OpenSSL QUIC implementation significantly slower than the competition. Another reason to advise users to maybe use another solution.
We keep communicating with the OpenSSL team about what we think needs to happen and what they need to provide in their API so that we can do QUIC efficiently. We hope they will improve their API going forward.
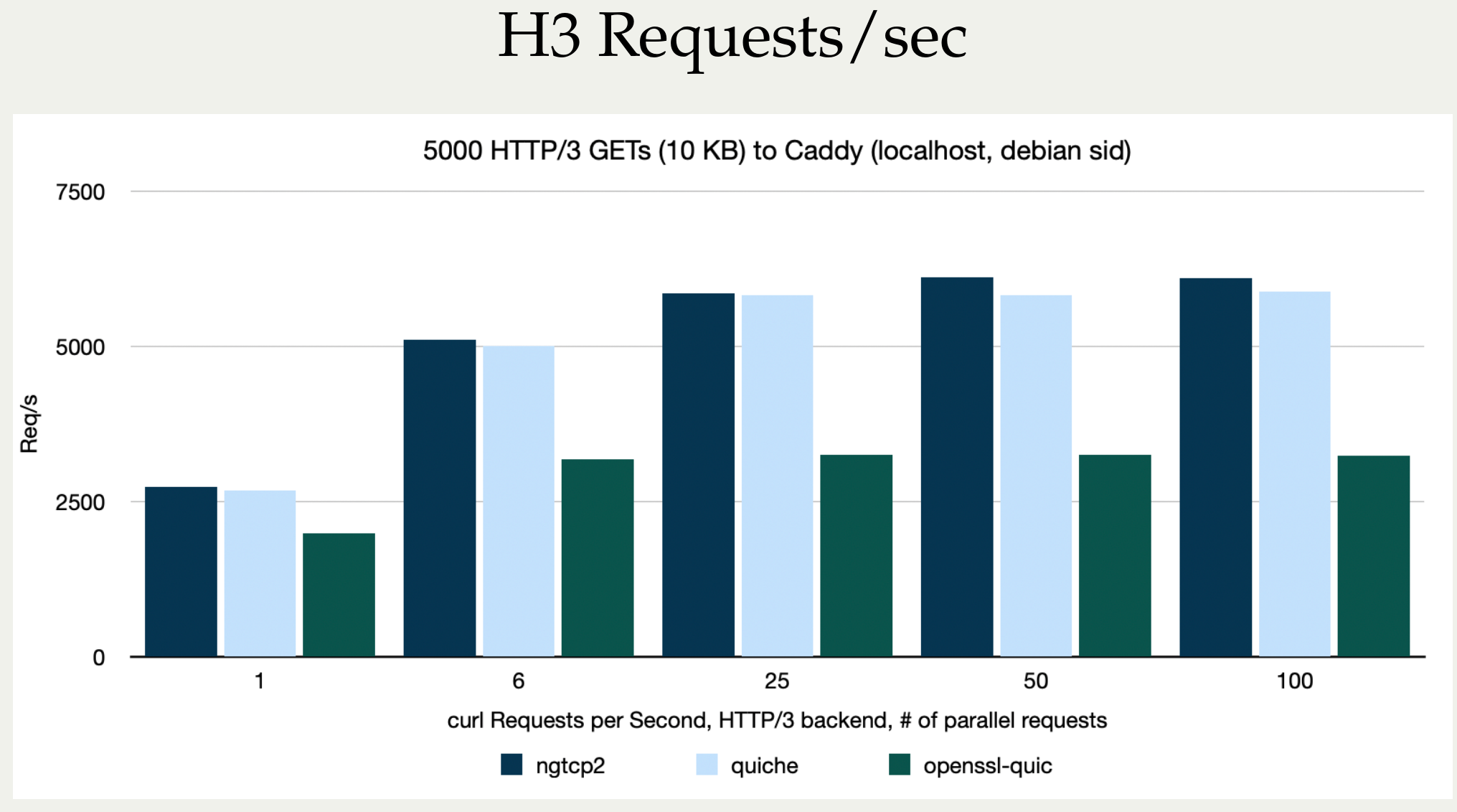
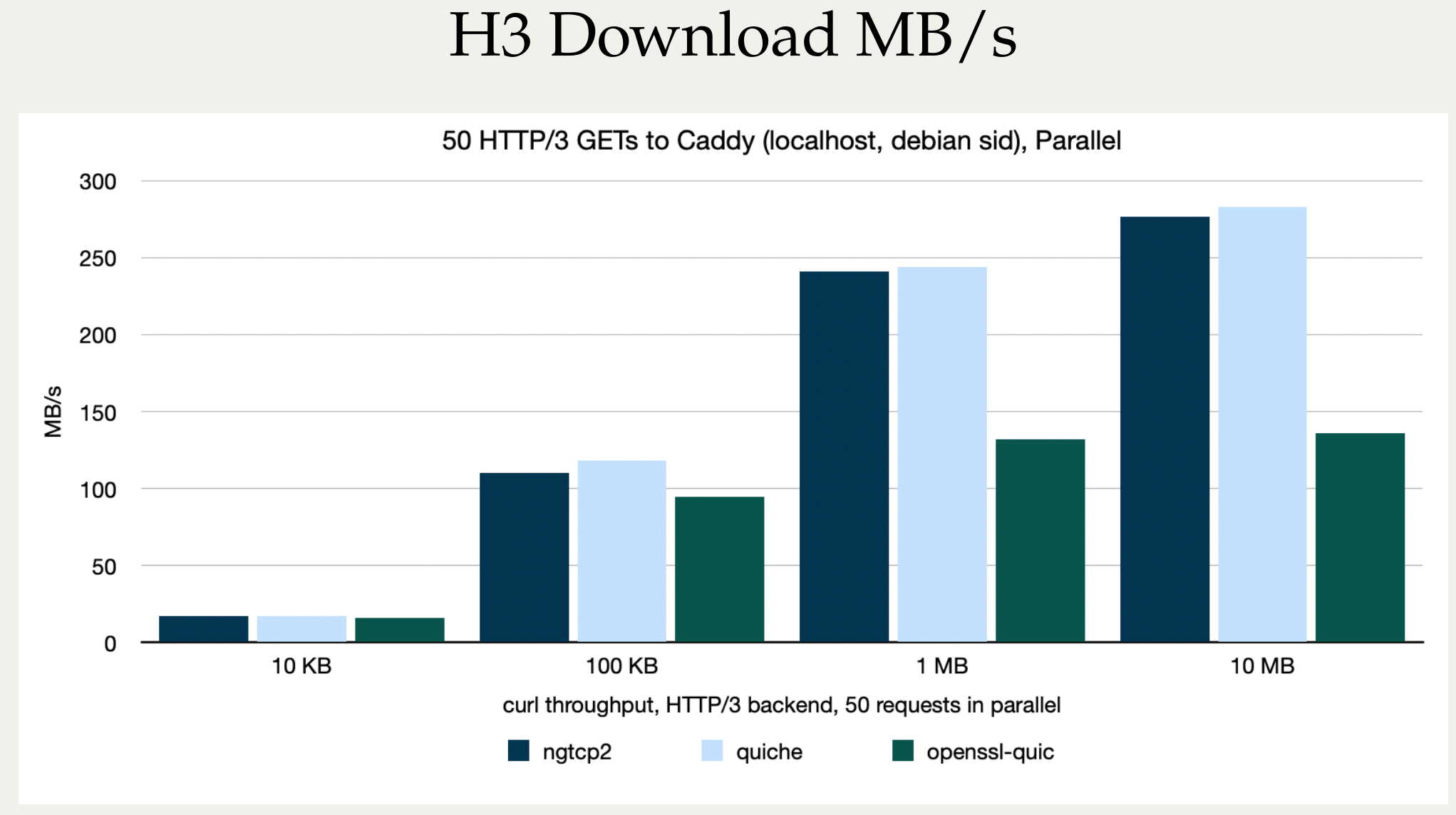
Stefan Eissing produced nice comparisons graph that I have borrowed from his Performance presentation (from curl up 2024. Stefan also blogged about h3 performance in curl earlier.). It compares three HTTP/3 curl backends against each other. (It does not include msh3 because it does not work good enough in curl.)
As you can see below, in several test setups OpenSSL is only achieving roughly half the performance of the other backends in both requests per second and raw transfer speed. This is on a localhost, so basically CPU bound transfers.
HTTP/3 backend performance in curl compared, requests/second
HTTP/3 backend performance in curl compared, megabytes/second
I believe OpenSSL needs to work on their QUIC performance in addition to providing an improved API.
quiche and msh3
quiche is still labeled beta and is only using BoringSSL which makes it harder to use in a lot of situations.
msh3 does not work at all right now in curl after a refactor a while ago.
HTTP/3 is a CPU hog
This is not news to anyone following protocol development. I have been repeating this over and over in every HTTP/3 presentation I have done – and I have done a few by now, but I think it is worth repeating and I also think Stefan’s graphs for this show the situation in a crystal clear way.
HTTP/3 is slow in terms of transfer performance when you are CPU bound. In most cases of course, users are not CPU bound because typically networks are the bottlenecks and instead the limited bandwidth to the remote site is what limits the speed on a particular transfer.
HTTP/3 is typically faster to completing a handshake, thanks to QUIC, so a HTTP/3 transfer can often get the first byte transmitted sooner than any other HTTP version (over TLS) can.
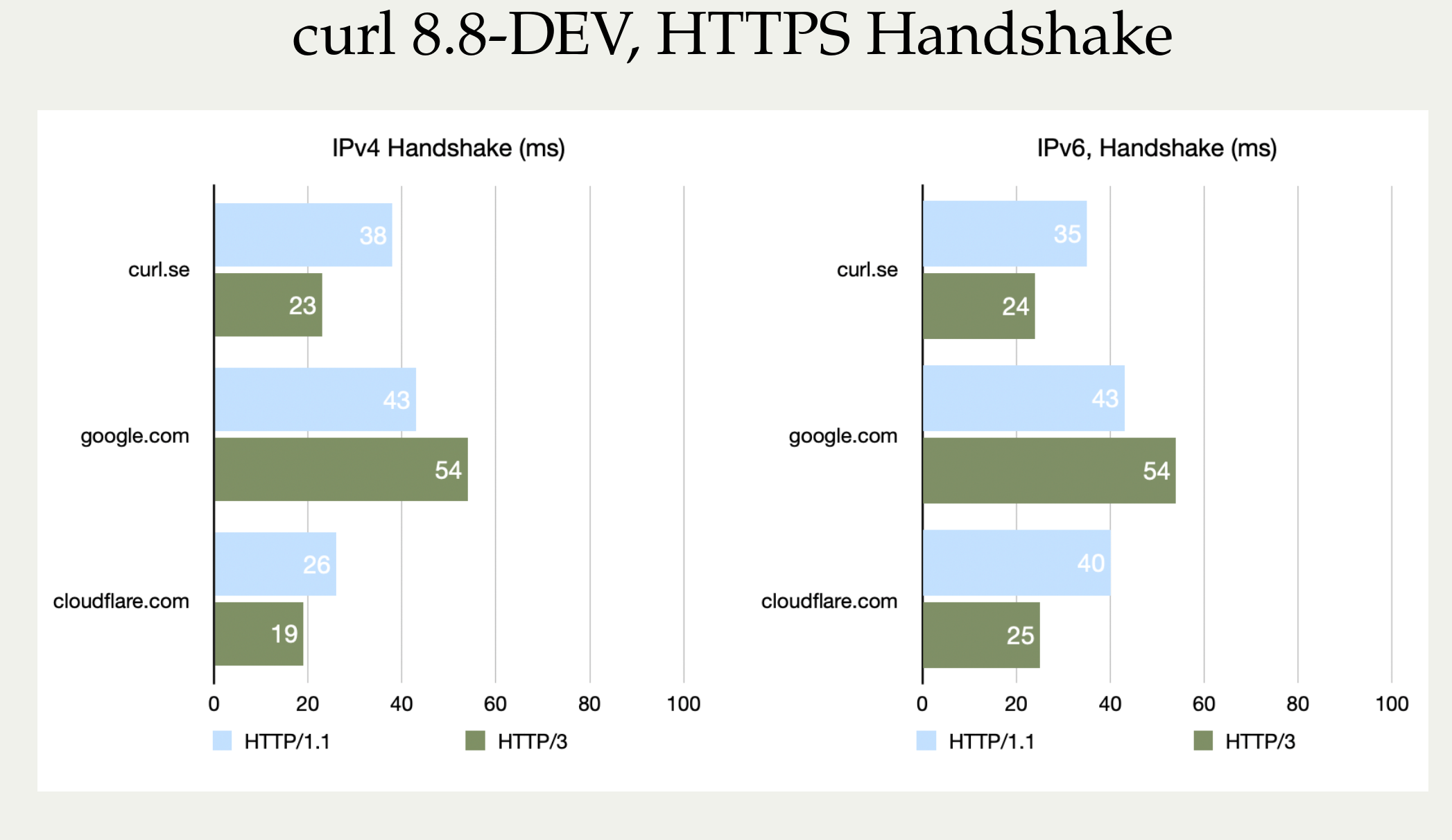
To show how this looks with more of Stefan’s pictures, let’s first show the faster handshakes from his machine somewhere in Germany. These tests were using a curl 8.8.0-DEV build, from a while before curl 8.8.0 was released.
HTTP/3 vs HTTP/1.1 handshake performance in curl compared
Nope, we cannot explain why google.com actually turned out worse with HTTP/3. It can be added that curl.se is hosted by Fastly’s CDN, so this is really comparing curl against three different CDN vendors’ implementations.
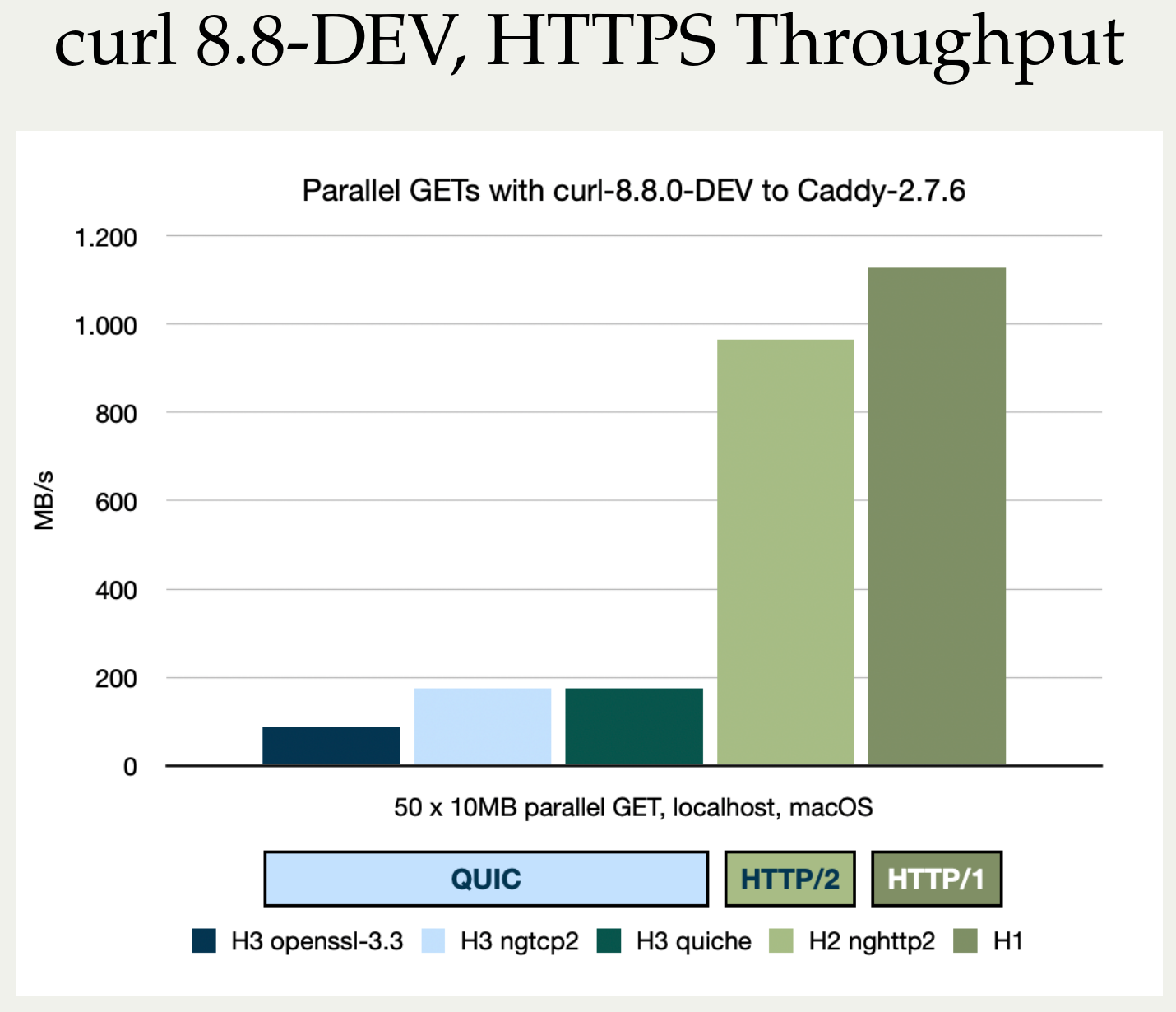
HTTP/3 vs HTTP/2 vs HTTP/1.1 throughput performance in curl compared
Again: these are CPU bound transfers so what this image really shows is the enormous amounts of extra CPU work that is required to push these transfers through. As long as you are not CPU bound, your transfers should of course run at the same speeds as they do with the older HTTP versions.
These comparisons show curl’s treatment of these protocols as they are not generic protocol comparisons (if such are even possible). We cannot rule out that curl might have some issues or weird solutions in the code that could explain part of this. I personally suspect that while we certainly always have areas for improvement remaining, I don’t think we have any significant performance blockers lurking. We cannot be sure though.
OpenSSL-QUIC stands out here as well, in the not so attractive end.
HTTP/3 deployments
w3techs, Mozilla and Cloudflare data all agree that somewhere around 28-30% of the web traffic is HTTP/3 right now. This is a higher rate than HTTP/1.1 for browser traffic.
An interesting detail about this 30% traffic share is that all the big players and CDNs (Google, Facebook, Cloudflare, Akamai, Fastly, Amazon etc) run HTTP/3, and I would guess that they combined normally have a much higher share of all the web traffic than 30%. Meaning that there is a significant amount of browser web traffic that could use HTTP/3 but still does not. Unfortunately I don’t have the means to figure out explanations for this.
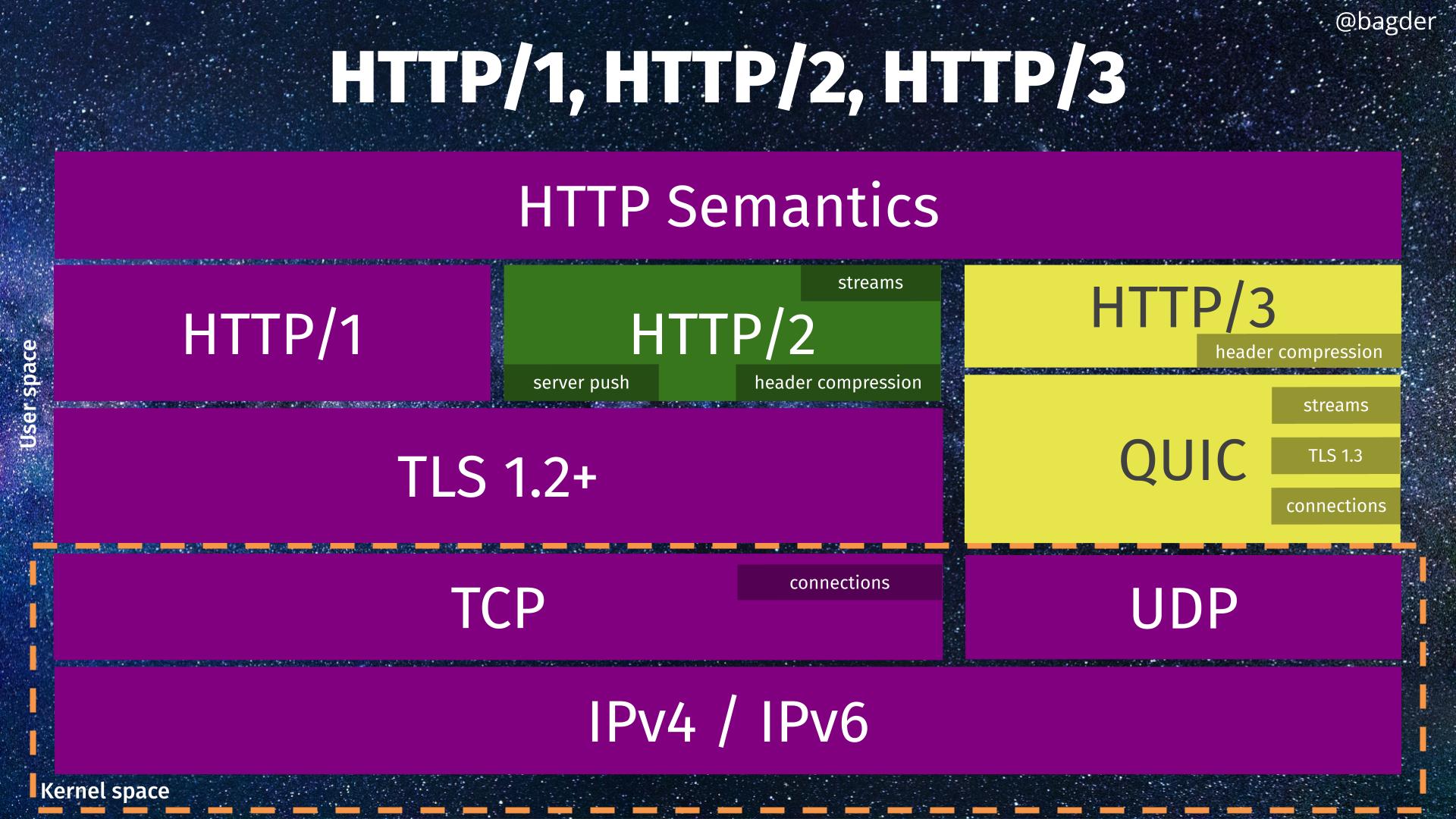
HTTPS stack overview
In case you need a reminder, here is how an HTTPS stack works.
At some point during 2003, my friend Bjørn Reese (from Dancer) and I were discussing back and forth and planning to maybe create our own asynchronous DNS/name resolver library. We felt that the synchronous APIs provided by gethostname() and getaddrinfo() were too limiting in for example curl. We could really use something that would not block the caller.
While thinking about this and researching what was already out there, I found the ares library written by Greg Hudson. It was an effort that was almost exactly what we had been looking for. I decided I would not make a new library but rather join the ares project and help polish that further to perfect it – for curl and for whoever else who wants such functionality.
It was soon made clear to me that the original author of this library did not want the patches I deemed were necessary, including changes to make it more portable to Windows and beyond. I felt I had no choice but to fork the project and instead I created c-ares. It would show its roots but not be the same. The c could be for curl, but it also made it into an English word like “cares” which was enough for me.
The first c-ares release I did was called version 1.0.0, published in February 2004.
The ares project did not have a website, but I am of the opinion that a proper open source project needs one, to provide downloads and not the least its documentation etc. A home. I created a basic c-ares website and since then I have hosted it on my server on the behalf of the c-ares project.
The was available as c-ares.haxx.se for many years but was recently moved over to c-ares.org. It has never been a traffic magnet so quite easy to manage.
In the backseat
In recent years, I have not participated much in the c-ares development. I have had my hands full with curl while the c-ares project has been in a pretty good shape and has been cared for in an excellent manner by Brad House and others.
I have mostly just done the occasional website admin stuff and releases.
Transition
Starting now, the c-ares website is no longer hosted by me. A twenty years streak is over and the website is now instead hosted on GitHub. I own the domain name and I run the DNS for it, but that is all.
The plan is that Brad is also going to take over the release duty. Brad is awesome.
The thing about me being a BDFL for curl is that it has the D in there. I have the means and ability to push for or veto just about anything I like or don’t like in the project, should I decide to. In my public presentations about curl I emphasize that I truly try to be a benevolent dictator, but then I also presume quite a few dictators would say and believe so whether that is true or not to the outside world.
I think we can say with some certainty that dictatorships are not the ideal way of running a country, and it might also go for Open Source projects.
In curl we remain using this model because it works and changing it to something else is a large and complicated process which we have not wanted to get to because we have not had any strong reason. There is anecdotal evidence that this way of running the project works somewhat.
A significant difference between being a dictator for an Open Source project compared to a country is however the ease with which every citizen could just leave one day and start a new clone country, with all the same citizens and the same layout, just without the dictator. I’m easily replaceable and made into past tense if I would abuse my role.
So there is this inherent force to push me to do good for the project even if I am a “dictator”.
As a BDFL of curl…
This is what I think the curl project should focus on. What I want the curl project to be. These are the ten commandments I think should remain our guiding principles. I think this is what makes curl. My benevolent guidelines.
My ten guiding principles for curl
Be open and friendly
Ship rock-solid products
Be a leader in Open Source
Maintain a security first focus
Provide top-notch documentation
Remain independent
Respond timely
Keep up with the world
Stay on the bleeding edge
Respect feedback
This list of ten areas are perhaps things every open source projects want to focus and excel in, but I think that is irrelevant here. These are then ten key and core focus points for me when I work on curl. We should be best-in-class in each and every one of them.
Let me elaborate
1. Be open and friendly to all contributors, new and old
I think open source projects have a lot to gain by making efforts in being friendly and approachable. We were all newcomers into a project once. We gain more contributors, better, by remaining a friendly and open project.
This does not mean that we should tolerate abuse or trolling.
I try to lead this by example. I do not always succeed.
2. Ship rock-solid products for the universe to depend upon
Reviews, tests, analyzers, fuzzers, audits, bug bounty programs etc are means to make sure the code runs smoothly everywhere. Studying protocol specs and inter-operating with servers and other clients on the Internet ensure that the products we make work as expect by billions of end users. On this planet and beyond. If our products cannot carry the world on their shoulders, we fail.
Rock-solid also means we are reliable over time – we do not break users’ scripts and applications. We maintain ABI/API compatibility. The command line options the curl tool introduces are supported until the end of time.
3. Be a leader in Open Source, follow every best practice
As true believers in the powers of Open Source we lead by example. We are here to show that you not only can do all development and everything in the open and using open source practices, but that it also makes the project thrive and deliver state of the art outcomes.
4. Always keep users secure, maintain a security first focus
Provide features and functionality with user and protocol security in focus. Address security concerns and reports without delays. Document every past mistake in thorough detail. Help users do secure and safe Internet transfers – by default.
5. Provide industry-leading quality documentation
A key to successful usage of our products, to give users the means and ability to use our project fully, we need to document how it works and how to use it. Everything needs to be documented with clarity and detail enough so that users understand and are empowered.
No comparable software project, open or proprietary, can compete with the quality and amount of documentation we provide.
6. Roam free, independent from all companies and organizations
curl shall forever remain independent. curl is not part of any umbrella organization, it is not owned or controlled by any company. It makes us entirely independent and free to do what we think is best for the community, for our users and for Internet transfers in general. Its license shall remain set and it ensures that curl remains free. Copyright holders are individuals, there is no assignment or licensing of copyrights involved.
7. Respond timely on issues and questions
We shall strive to respond to issues, reports and questions sent to the project within a reasonable time. To show that we care and to help users solve their problems. We want users to solve their problems sooner rather than later.
It does not mean that we always can fix the problems or give a good answer immediately. Sometimes we just have to say that we can’t fix it for now.
8. Remain the internet transfer choice, keep up with the world
In the curl project we should keep up with protocol development, updates and changes. The way we do Internet transfers changes over time and curl needs to keep up to remain relevant.
We also need to write our protocol implementations sensibly, knowing that we are being watched and our way of doing things are often copied, referred to and relied upon by other Internet clients.
This also implies that we are never done and that we can always improve. In every aspect of the project.
9. Offer bleeding edge protocol support to aid early adopters
When new protocols or ways to do protocols are introduced to the world, curl can play a great role in providing and offering early support of such protocols. This has through the years helped countless of other implementers or even protocol authors of these protocols and with this, we help improving the world around us. It also helps us get early feedback on our implementation and thus ship better code earlier.
10. Listen to and respect community feedback
I might be a dictator, but this dictatorship would not work if I and the rest of the curl maintainers did not listen to what the users and the greater curl community have to say. We need to stay agile and have a sense of what people want our products to do and to not do. Now and in the future.
An open source project can always get forked the second it makes a bad turn and somehow gives up on, sells out or betrays its users. Me being a dictator does not protect us from that. We need to stay responsive, listening and caring. We are here for our users.
Flag?
If curl was an evil empire, I figure we would sport this flag:
It is not quite a gold medal, but it is now the fifth time I have the honor of receiving a Google Open Source Peer Bonus. I might soon start to think I have some fans over there.
There is a monetary component to this bonus. Last time it was to the amount of 500 USD. I have not seen the amount for this time as it has not been transferred to me yet. I trust it will buy me a few good beers anyway.
A while ago I wrote about how curl is verified in several ways in order to reduce the risk for unwanted or even malicious content to appear in release tarballs. Now we look deeper at exactly what needs to be done to verify a curl release – how you and everyone else can do it.
Don’t trust, verify!
This functionality is shipped starting with curl 8.8.0. Previous versions were much harder to reproduce because we did not provide the necessary information and tooling in this convenient and easily accessible way.
Prerequisites
This verification procedure verifies that whatever is in git ends up in the release tarball unaltered. Nothing more, nothing less. To make sure that what exists in git is fine, people need to review that content but that is not covered in this blog post.
(As a little side-point: we work hard to not have any binary blobs or other files in the git repository that could magically get converted into exploit code using the right key.)
Tarball releases
A release from the curl project is always a tarball. The tarball is provided using several (four over the recent years) different compression methods. Each tarball has the identical content but is compressed differently. Therefore each separate tarball is also separately signed.
The tarball is generated from git from a release tag. curl’s release tags are named like curl-3_4_5 for version 3.4.5. With underscores instead of dots for historic reasons.
The release making script is carefully written to make sure it makes the release tarballs the exact same way to make the exact same output when run multiple times.
Reproducing means making an identical copy
When someone can reproduce a curl release, it means creating a new set of tarballs that are binary identical copies of the ones from a previous curl release. That process requires a set of known tools and knowing the exact timestamp.
Tools for release
The tarball features a few files that don’t exist in git because they are generated at release time. To reproduce those files, you likely need more or less the exact version of the involved tools that the person who makes the release (me) had at the time the tarball was created.
To help with this, there is a markdown document called docs/RELEASE-TOOLS.md generated and shipped in recent tarballs. It contains a list of the exact versions of a few key tools that were used. The list might look something like this:
The release tools document also contains another key component: the exact time stamp at which the release was done – using integer second resolution. In order to generate a correct tarball clone, you need to also generate the new version using the old version’s timestamp. Because the modification date of all files in the produced tarball will be set to this timestamp.
Setting the old release’s time is done by setting the environment variable SOURCE_DATE_EPOCH to the timestamp mentioned in RELEASE-TOOLS.md before creating the tarball.
To reproduce a release tarball, you need to extract that SOURCE_DATE_EPOCH and use it when creating a clone.
With docker
We have created a Dockerfile for the specific purpose of making releases. Using it is easy. You make a curl 8.8.0 release clone like this.
The second argument to dmaketgz is the epoch time from the release tarball. It makes the newly generated tarball use the same timestamp as the previous one.
When dmaketgz is done, you are left with four tarballs in the curl source code tree, each named like curl-8.8.0.* with four different extensions for the different compression and archiving methods. They are bit for bit identical copies of the official curl 8.8.0 release tarballs.
If you sha256sum the new files and the official release tarballs, you see that they create identical checksums. Of course!
Without docker
Making a proper clone is harder without docker. This, because we use a Debian Linux to build releases and we use a set of tools and their exact versions as shipped by Debian. You might get slightly different outputs if you do not use the exact versions this Debian version ships. Getting a single line difference by a single tool will generate a different tarball and thus fail the reproducibility test.
This is why we provide the Dockerfile as mentioned above. Without that, you probably will have a higher success rate if you try the below steps running on a Debian Linux machine.
If you have the necessary tools installed using the versions mentioned in docs/RELEASE-TOOLS.md, do this to make a release copy. Below, we pretend 1715301052 is the timestamp from the real release.
Every single published release tarball is signed, and a reproduced tarball can in fact be verified using the release signature since they are binary clones.
No transparency logs
Several people have asked me for transparency logs for the signing of the tarballs, to reduce the risk even further that in case of a breach of my development environment, someone else could be able to produce a curl release and sign it.
While in general an idea I like, I have not taken any steps towards it at this point. And to do a fake curl release, you need more than just being able to generate my signature. You also need the magic to make the release appear on the curl website in the correct way, so there are in fact multiple steps with separate keys, passwords and authentication methods in place which should make it a tough challenge to any bad guy.
I am not saying it is perfect nor that there is no room for improvement: because of course this process can always get improved. I am sure we will have reasons to polish it further going forward.
the 257th release 8 changes 56 days (total: 9,560) 220 bug-fixes (total: 10,271) 348 commits (total: 32,280) 1 new public libcurl function (total: 94) 1 new curl_easy_setopt() option (total: 305) 1 new curl command line option (total: 259) 84 contributors, 41 new (total: 3,173) 49 authors, 20 new (total: 1,272) 0 security fixes (total: 155)
Download the new curl release from curl.se as always.
Release presentation
Security
It feels good to be able to say that this time around we do not have a single security vulnerability to announce and we in fact do not have any in the queue either.
Some of the bugfixes from this cycle that might be worth noticing:
dist and build
reproducible tarballs. I will do a separate post with details later, but now it is easy for anyone who wants to, to generate an identical copy to verify what we ship.
docs/RELEASE-TOOLS.md into the tarball. This documents the tools and versions used to generate the files included in the tarball that are not present in git.
drop MSVC project files for recent versions. If you need to generate them for more recent versions, cmake can do it for you.
configure fix HAVE_IOCTLSOCKET_FIONBIO test for gcc 14. It runs more picky by default so it would always fail the check.
add -q as first option when invoking curl for tests. To reduce the risk of people having a ~/.curlrc file that ruins things.
fix make install with configure –disable-docs
tool
make –help adapt to the terminal width. Makes it easier on the eye when the terminal is wider.
limit rate unpause for -T . uploads. Avoids busy-looping
curl output warning for leading unicode quote character. Because it seems like a fairly common mistake when people copy and paste command lines from random sources
don’t truncate the etag save file by default. A regression less.
TLS
bearssl: use common code for cipher suite lookup
mbedtls: call mbedtls_ssl_setup() after RNG callback is set. Otherwise, more recent versions of mbedTLS will just return error.
mbedtls: support TLS 1.3. If you use a new enough version.
openssl: do not set SSL_MODE_RELEASE_BUFFERS. Uses slightly more memory, but uses fewer memory allocation calls.
wolfssl: plug memory leak in wolfssl_connect_step2()
bindings
openldap: create ldap URLs correctly for IPv6 addresses, doing LDAP with IPv6 numerical IP addresses in the URL just did not work previously.
quiche: expire all active transfers on connection close
quiche: trust its timeout handling
libcurl
fix curl_global_cleanup crash in Windows. A regression coming from the introduction of the async name resolver function.
brotli and others, pass through 0-length writes
ignore duplicate chunked encoding. Apparently some sites do this and browsers let them so we need to let it slide…
CURLINFO_REQUEST_SIZE: fixed
ftp: add tracing support. Gives us better tooling to track down FTP problems.
http2: emit RST when client write fails. Previously it would just silently leave the stream there…
http: reject HTTP major version switch mid connection. This should of course never happen, but if it does, curl will error out correctly.
multi: introduce SETUP state for better timeouts. This adds a proper separation for when the existing transfer is retried or when the state machine is restarted because it make as a new transfer.
multi: timeout handles even without connection. They would previously often be exempted from checks and would linger for too long until stopped.
fix handling of paused upload on completed download
do not URL decode proxy credentials
allow setting port number zero. Remember this old post?
In the 2015 time frame I had come to the conclusion that the curl logo could use modernization and I was toying with ideas of how it could be changed. The original had served us well, but it definitely had a 1990s era feel to it.
On June 11th 2015, I posted this image in the curl IRC channel as a proof of concept for a new curl logo idea I had: since curl works with URLs and all the URLs curl supports have the colon slash slash separator. Obviously I am not a designer so it was rough. This was back in the day when we still used this logo:
Frank Gevarts had a go at it. He took it further and tried to make something out of the idea. He showed us his tweaked take.
When we met up at the following FOSDEM in the end of January 2016, we sat down together and discussed the logo idea a bit to see if we could make it work somehow. Left from that exercise is this version below. As you can see, basically the same one. It was hard to make it work.
Later that spring, I was contacted by Soft Dreams, a designer company, who offered to help us design a new logo at no cost to us. I showed them some of these rough outlines of the colon slash slash idea and we did a some back-and-forthing to see if we could make something work with it, but we could not figure out a way to get the colon slash slash sequence actually into the word curl in a way that would look good. It just kept on looking different kinds of weird. Eventually we gave that up and we ended up putting it after the word, making it look like curl is a URL scheme. It was ended up much easier and ultimately the better and right choice for us. The new curl logo was made public in May 2016. Made by Adrian Burcea.
Just months later in 2016, Mozilla announced that they were working on a revamp of their logo. They made several different skews and there was a voting process during which they would eventually pick a winner. One of the options used colon slash slash embedded in the name and during the process a number of person highlighted the fact that the curl project just recently changed logo to use the colon slash slash.
In the Mozilla all-hands meeting in Hawaii in December 2016, I was approached by the Mozilla logo design team who asked me if I (we?) would have any issues with them moving forward with the logo version using the colon slash slash.
I had no objections. I think that was the coolest of the new logo options they had and I also thought that it sort of validated our idea of using the symbols in our logo. I was perhaps a bit jealous how Mozilla is a better word to actually integrate the symbol into the name…. the way we tried so hard to do for curl, but had to give up.
You know Tor, but do you know SOCKS5? It is an old and simple protocol for setting up a connection and when using it, the client can decide to either pass on the full hostname it wants to connect to, or it can pass on the exact IP address.
(SOCKS5 is by the way a minor improvement of the SOCKS4 protocol, which did not support IPv6.)
When you use curl, you decide if you want curl or the proxy to resolve the target hostname. If you connect to a site on the public Internet it might not even matter who is resolving it as either party would in theory get the same set of IP addresses.
The .onion TLD
There is a concept of “hidden” sites within the Tor network. They are not accessible on the public Internet. They have names in the .onion top-level domain. For example. the search engine DuckDuckGo is available at https://duckduckgogg42xjoc72x3sjasowoarfbgcmvfimaftt6twagswzczad.onion/.
.onion names are used to provide access to end to end encrypted, secure, anonymized services; that is, the identity and location of the server is obscured from the client. The location of the client is obscured from the server.
To access a .onion host, you must let Tor resolve it because a normal DNS server aware of the public Internet knows nothing about it.
This is why we recommend you ask the SOCKS5 proxy to resolve the hostname when accessing Tor with curl.
The proxy connection
The SOCKS5 protocol is clear text so you must make sure you do not access the proxy over a network as then it will leak the hostname to eavesdroppers. That is why you see the examples above use localhost for the proxy.
You can also step it up and connect to the SOCKS5 proxy over unix domain sockets with recent curl versions like this:
Sites using the .onion TLD are not on the public Internet and it is pointless to ask your regular DNS server to resolve them. Even worse: if you in fact ask your normal resolver you practically advertise your intention of connection to a .onion site and you give the full name of that site to the outsider. A potentially significant privacy leak.
To combat the leakage problem, RFC 7686The “.onion” Special-Use Domain Name was published in October 2015. With the involvement and consent from people involved in the Tor project.
It only took a few months after 7686 was published until there was an accurate issue filed against curl for leaking .onion names. Back then, in the spring of 2016, no one took upon themselves to fix this and it was instead simply added to the queue of known bugs.
This RFC details (among other things) how libraries should refuse to resolve .onion host names using the regular means in order to avoid the privacy leak.
After having stewed in the known bugs lists for almost five years, it was again picked up in 2023, a pull-request was authored, and when curl 8.1.0 shipped on May 17 2023 curl refused to resolve .onion hostnames.
Tor still works remember?
Since users are expected to connect using SOCKS5 and handing over the hostname to the proxy, the above mention refusal to resolve a .onion address did not break the normal Tor use cases with curl.
Turns out there is a group of people who runs transparent proxies who automatically “catches” all local traffic and redirects it over Tor. They have a local DNS server who can resolve .onion host names and they intercept outgoing traffic to instead tunnel it through Tor.
With this setup now curl no longer works because it will not send .onion addresses to the local resolver because RFC 7686 tells us we should not,
curl of course does not know when it runs in a presumed safe and deliberate transparent proxy network or when it does not. When a leak is not a leak or when it actually is a leak.
torsocks
A separate way to access tor is to use the torsocks tool. Torsocks allows you to use most applications in a safe way with Tor. It ensures that DNS requests are handled safely and explicitly rejects any traffic other than TCP from the application you’re using.
You run it like
torsocks curl https://example.com
Because of curl’s new .onion filtering, the above command line works fine for “normal” hostnames but no longer for .onion hostnames.
Arguably, this is less of a problem because when you use curl you typically don’t need to use torsocks since curl has full SOCKS support natively.
Option to disable the filter?
In the heated discussion thread we are told repeatedly how silly we are who block .onion name resolves – exactly in the way the RFC says, the RFC that had the backing and support from the Tor project itself. There are repeated cries for us to add ways to disable the filter.
I am of course sympathetic with the users whose use cases now broke.
A few different ways to address this have been proposed, but the problem is difficult: how would curl or a user know that it is fine to leak a name or not? Adding a command line option to say it is okay to leak would just mean that some scripts would use that option and users would run it in the wrong conditions and your evil malicious neighbors who “help out” will just add that option when they convince their victims to run an innocent looking curl command line.
The fact that several of the louder voices show abusive tendencies in the discussion of course makes these waters even more challenging to maneuver.
Future
I do not yet know how or where this lands. The filter has now been in effect in curl for a year. Nothing is forever, we keep improving. We listen to feedback and we are of course eager to make sure curl remains and awesome tool and library also for content over Tor.