Starting in version 7.52.0 (due to ship December 21, 2016), curl will support HTTPS proxies when doing network transfers, and by doing this it joins the small exclusive club of HTTP user-agents consisting of Firefox, Chrome and not too many others.
Yes you read this correctly. This is different than the good old HTTP proxy.
HTTPS proxy means that the client establishes a TLS connection to the proxy and then communicates over that, which is different to the normal and traditional HTTP proxy approach where the clients speak plain HTTP to the proxy.
Talking HTTPS to your proxy is a privacy improvement as it prevents people from snooping on your proxy communication. Even when using HTTPS over a standard HTTP proxy, there’s typically a setting up phase first that leaks information about where the connection is being made, user credentials and more. Not to mention that an HTTPS proxy makes HTTP traffic “safe” to and from the proxy. HTTPS to the proxy also enables clients to speak HTTP/2 more easily with proxies. (Even though HTTP/2 to the proxy is not yet supported in curl.)
In the case where a client wants to talk HTTPS to a remote server, when using a HTTPS proxy, it sends HTTPS through HTTPS.
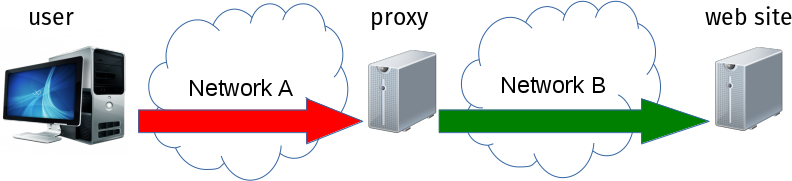
Illustrating this concept with images. When using a traditional HTTP proxy, we connect initially to the proxy with HTTP in the clear, and then from then on the HTTPS makes it safe:
 to compare with the HTTPS proxy case where the connection is safe already in the first step:
to compare with the HTTPS proxy case where the connection is safe already in the first step:
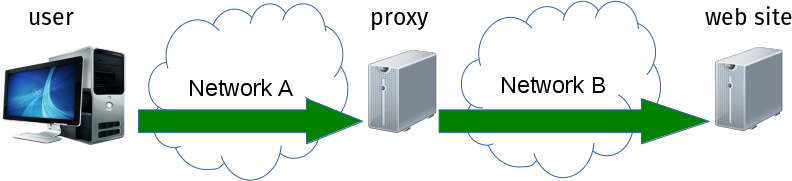 The access to the proxy is made over network A. That network has traditionally been a corporate network or within a LAN or something but we’re seeing more and more use cases where the proxy is somewhere on the Internet and then “Network A” is really huge. That includes use cases where the proxy for example compresses images or otherwise reduces bandwidth requirements.
The access to the proxy is made over network A. That network has traditionally been a corporate network or within a LAN or something but we’re seeing more and more use cases where the proxy is somewhere on the Internet and then “Network A” is really huge. That includes use cases where the proxy for example compresses images or otherwise reduces bandwidth requirements.
Actual HTTPS connections from clients to servers are still done end to end encrypted even in the HTTP proxy case. HTTP traffic to and from the user to the web site however, will still be HTTPS protected to the proxy when a HTTPS proxy is used.
A complicated pull request
This awesome work was provided by Dmitry Kurochkin, Vasy Okhin, and Alex Rousskov. It was merged into master on November 24 in this commit.
Doing this sort of major change in the TLS area in curl code is a massive undertaking, much so because of the fact that curl supports getting built with one out of 11 or 12 different TLS libraries. Several of those are also system-specific so hardly any single developer can even build all these backends on his or hers own machines.
In addition to the TLS backend maze, curl and library also offers a huge amount of different options to control the TLS connection and handling. You can switch on and off features, provide certificates, CA bundles and more. Adding another layer of TLS pretty much doubles the amount of options since now you can tweak everything both in the TLS connection to the proxy as well as the one to the remote peer.
This new feature is supported with the OpenSSL, GnuTLS and NSS backends to start with.
Consider it experimental for now
By all means, go ahead and use it and torture the code and file issues for everything bad you see, but I think we make ourselves a service by considering this new feature set to be a bit experimental in this release.
New options
There’s a whole forest of new command line and libcurl options to control all the various aspects of the new TLS connection this introduces. Since it is a totally separate connection it gets a whole set of options that are basically identical to the server connection but with a –proxy prefix instead. Here’s a list:
--proxy-cacert --proxy-capath --proxy-cert --proxy-cert-type --proxy-ciphers --proxy-crlfile --proxy-insecure --proxy-key --proxy-key-type --proxy-pass --proxy-ssl-allow-beast --proxy-sslv2 --proxy-sslv3 --proxy-tlsv1 --proxy-tlsuser --proxy-tlspassword --proxy-tlsauthtype
 shed at the end of October 2016.
shed at the end of October 2016.



 We can’t have it like that! I rolled up my imaginary sleeves (imaginary since my swag tshirt doesn’t really have sleeves) and I now offer
We can’t have it like that! I rolled up my imaginary sleeves (imaginary since my swag tshirt doesn’t really have sleeves) and I now offer