The ride is coming to an end. The experiment is done. We tried, but we admit defeat.
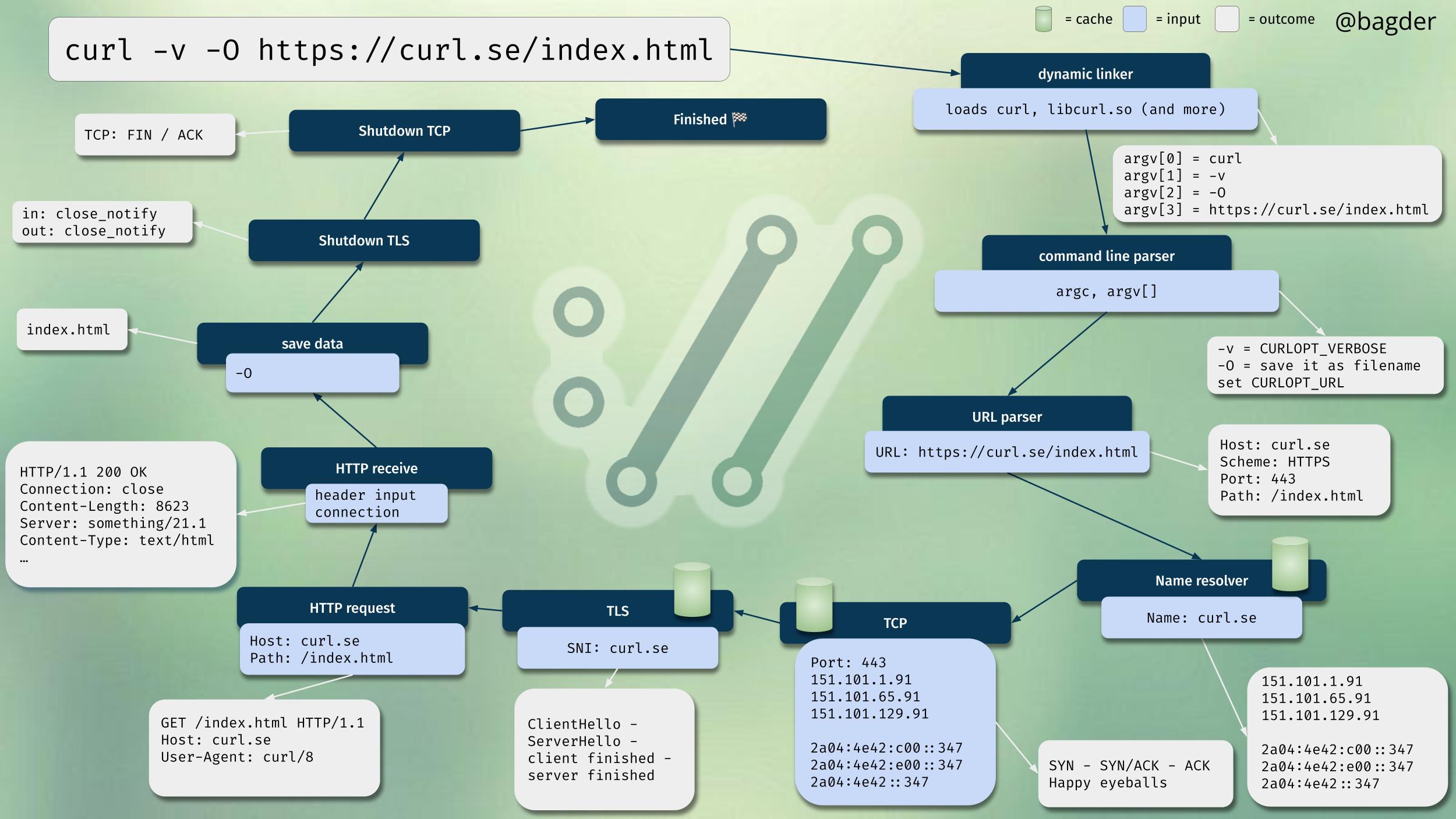
Four years ago we started adding support for an alternative HTTP backend in curl. It would use a library written in rust, called hyper. The idea was to introduce an alternative implementation of HTTP internals that you could make curl/libcurl use instead of the native implementation.
This new backend that used a library written in rust would enable users to run a product where a larger piece of the total code than otherwise would be written in a memory-safe language: rust. Memory-safety being all the rage these days.
The initial work was generously sponsored by ISRG, the organization behind such excellent efforts such as Let’s Encrypt, which believes strongly in this concept. I cooperated intensely with Sean McArthur, the lead developer of hyper. We made it work.
We have shipped hyper support in curl labeled EXPERIMENTAL for several years by now, hoping to attract attention and trigger the experimental spirit in users out there. Seeing so many people seem to want more memory-safety, surely the users would come?
95% of the work is the easy part
I mean that we took it perhaps 95% of the way and almost the entire test suite ran identically independently of which backend we built curl to use. The final few percent would however turn out to be friction enough to now eventually make us admit defeat, give up and instead yank it all out again.
There simply were no users asking for it and there were almost no developers interested or knowledgeable enough to work on it. libcurl is written in C, hyper is written in rust and there is a C binding glue layer in between. It takes someone who is interested and good at both languages to dig in, understand the architectures, the challenges and the protocols to drive this all the way through.
But with no user demand, why do it?
It seems quite clear that rust users use hyper but few of them want to work on making it work for a C project like curl, and among existing curl users there is virtually no interest in hyper. The overlap in the Venn diagram of the two universes is not big enough.
With no expectation of seeing this work completed in the short to medium length term, the cost of keeping the hyper code is simply deemed too high. We gain code agility and reduce complexity by trimming this off.
We improved
While the experiment itself is deemed a failure, I think we learned from it and improved curl in the process. We had to rethink and reassess several implementation details when we aligned HTTP behavior with hyper. libcurl parses and handles HTTP stricter now. Better.
I also believe that hyper benefited from this journey and gained experiences and input from us that led to improvements in their end and in their HTTP library. Which then by extension have benefited the hyper users.
When we started this, even rust itself was not ready and over this time rust has improved and it is today a better language and it is better prepared to offer something like this. For us or for other projects.
Backends
With this amputation we are back to no separate HTTP/1 backends. We only provide the single native implementation.
I am not against revisiting the topic and the idea of providing alternative backends for HTTP/1 in the future, but I think we should proceed a little different next time. We also have a better internal architecture now to build on than what we had in 2020 when this attempt started.
Less rust (for now?)
Before this step, we supported three different backends backed up by libraries written in rust. Now we are down to two: rustls (for TLS) and quiche (for QUIC and HTTP/3). Both of them are still marked experimental.
These two backends use better internal APIs in curl and are hooked into libcurl in a cleaner way that makes them easier to support and less of burden to maintain over time.
Of course nothing prevents us from adding support for more and other rust libraries in the future. libcurl is a protocol engine using a plethora of different backends for many different protocols and services hooked into its core. Virtually all of those backends could be provided by a rust library.
Thanks
A big thank you go to Sean and all others who helped us take it as far as we did. You are great. Nothing of this should put any shade on you.
When
The hyper backend code has been removed in git as of December 21. There will be no traces left of it in the curl 8.12.0 release coming in February 2025.